10 datových struktur Pythonu [Explained With Examples]
Chcete rozšířit možnosti svého programovacího nástroje o sofistikované datové struktury? Začněte ještě dnes a pronikněte do tajů datových struktur v Pythonu.
Při učení se novému programovacímu jazyku je klíčové porozumět základním datovým typům a vestavěným datovým strukturám, které tento jazyk nabízí. V tomto průvodci světem datových struktur v Pythonu se podíváme na:
- výhody, které datové struktury přinášejí
- základní vestavěné datové struktury Pythonu, jako jsou seznamy, n-tice, slovníky a množiny
- implementaci abstraktních datových typů, například zásobníků a front.
Pojďme se do toho pustit!
Proč jsou datové struktury tak užitečné?
Než se ponoříme do detailů jednotlivých datových struktur, podívejme se, v čem spočívá jejich přínos:
- Efektivní manipulace s daty: Správná volba datové struktury umožňuje efektivnější zpracování dat. Například, pokud potřebujete uložit kolekci prvků stejného datového typu s rychlým vyhledáváním a těsnou vazbou, pole je ideální volbou.
- Optimalizace správy paměti: V rozsáhlejších projektech může být jedna datová struktura z hlediska paměťové náročnosti výhodnější než jiná. V Pythonu lze například seznamy i n-tice použít k uložení kolekcí dat stejného i různého typu. Pokud ale víte, že danou kolekci nebudete potřebovat upravovat, n-tice bude úspornější, protože zabírá méně paměti než seznam.
- Zlepšení organizace kódu: Použití vhodné datové struktury pro daný účel zlepší organizaci vašeho kódu. Ostatní programátoři, kteří budou váš kód číst, očekávají, že budete používat specifické datové struktury v závislosti na požadované funkčnosti. Například, pokud potřebujete mapování párů klíč–hodnota s rychlým vyhledáváním a vkládáním, slovník je pro tento účel ideální.
Seznamy
Seznamy jsou v Pythonu základní datovou strukturou pro vytváření dynamických polí – ať už jde o kódovací úlohy nebo běžné programovací situace.
Seznamy v Pythonu jsou proměnlivé a dynamické kontejnery. Umožňují přidávat a odebírat prvky přímo v seznamu bez nutnosti vytvářet jeho kopii.
Při používání seznamů v Pythonu:
- Indexování do seznamu a přístup k prvku na daném indexu probíhá v konstantním čase.
- Přidání prvku na konec seznamu je také operace s konstantním časem.
- Vložení prvku na konkrétní index je operace s lineární časovou složitostí.
Python nabízí sadu metod pro efektivní provádění běžných úloh s seznamy. Následující ukázka kódu ilustruje, jak tyto operace provádět:
>>> nums = [5,4,3,2] >>> nums.append(7) >>> nums [5, 4, 3, 2, 7] >>> nums.pop() 7 >>> nums [5, 4, 3, 2] >>> nums.insert(0,9) >>> nums [9, 5, 4, 3, 2]
Seznamy v Pythonu podporují také dělení a testování přítomnosti prvků pomocí operátoru `in`:
>>> nums[1:4] [5, 4, 3] >>> 3 in nums True
Datová struktura seznamu je flexibilní, jednoduchá a umožňuje ukládat prvky různých datových typů. Python také nabízí specializovanou datovou strukturu pole pro efektivní ukládání prvků stejného datového typu, o které se dozvíme dále v tomto průvodci.
N-tice
N-tice jsou další oblíbenou vestavěnou datovou strukturou v Pythonu. Jsou podobné seznamům v tom, že k prvkům můžete přistupovat pomocí indexů v konstantním čase a můžete je dělit. N-tice jsou však neměnné, takže je nelze přímo upravovat. Následující ukázka kódu demonstruje tyto vlastnosti:
>>> nums = (5,4,3,2) >>> nums[0] 5 >>> nums[0:2] (5, 4) >>> 5 in nums True >>> nums[0] = 7 # Neplatná operace! Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'tuple' object does not support item assignment
Pokud potřebujete vytvořit neměnnou kolekci, se kterou chcete efektivně pracovat, zvažte použití n-tice. Pokud potřebujete kolekci, kterou lze měnit, je vhodnější použít seznam.
📋 Prozkoumejte více o podobnostech a rozdílech mezi seznamy a n-ticemi v Pythonu.
Pole
Pole jsou v Pythonu méně známou datovou strukturou. Podobají se seznamům v tom, jaké operace podporují, jako je přístup k prvkům pomocí indexů v konstantním čase a vkládání prvku na konkrétní index v lineárním čase.
Hlavní rozdíl mezi seznamy a poli spočívá v tom, že pole ukládají prvky pouze jednoho datového typu. Díky tomu jsou pole paměťově efektivnější a mají těsnější vazbu.
Pro vytvoření pole můžeme použít konstruktor `array()` z vestavěného modulu `array`. Konstruktor `array()` přijímá řetězec, který specifikuje datový typ prvků, a samotné prvky. Následující kód vytvoří pole `nums_f` čísel s plovoucí desetinnou čárkou:
>>> from array import array
>>> nums_f = array('f',[1.5,4.5,7.5,2.5])
>>> nums_f
array('f', [1.5, 4.5, 7.5, 2.5])
K prvkům pole můžete přistupovat pomocí indexů (podobně jako u seznamů):
>>> nums_f[0] 1.5
Pole jsou měnitelné, takže je můžete upravovat:
>>> nums_f[0]=3.5
>>> nums_f
array('f', [3.5, 4.5, 7.5, 2.5])
Nelze však měnit datový typ prvku:
>>> nums_f[0]='zero' Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: must be real number, not str
Řetězce
Řetězce v Pythonu jsou neměnné kolekce znaků Unicode. Na rozdíl od programovacích jazyků jako C, Python nemá vyhrazený datový typ pro znak. Znak je tedy v Pythonu vlastně řetězec o délce jedna.
Jak již bylo zmíněno, řetězce jsou neměnné:
>>> str_1 = 'python' >>> str_1[0] = 'c' Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'str' object does not support item assignment
Řetězce v Pythonu podporují dělení a disponují sadou metod pro jejich formátování. Následuje několik příkladů:
>>> str_1[1:4] 'yth' >>> str_1.title() 'Python' >>> str_1.upper() 'PYTHON' >>> str_1.swapcase() 'PYTHON'
⚠ Nezapomeňte, že všechny výše uvedené operace vracejí kopii řetězce a nemění původní řetězec. Pokud máte zájem, podívejte se na průvodce Python Programy pro operace s řetězci.
Množiny
Množiny v Pythonu jsou kolekce unikátních, hashovatelných položek. Můžete provádět běžné množinové operace jako sjednocení, průnik a rozdíl:
>>> set_1 = {3,4,5,7}
>>> set_2 = {4,6,7}
>>> set_1.union(set_2)
{3, 4, 5, 6, 7}
>>> set_1.intersection(set_2)
{4, 7}
>>> set_1.difference(set_2)
{3, 5}
Množiny jsou ve výchozím nastavení měnitelné, takže můžete přidávat a upravovat jejich prvky:
>>> set_1.add(10)
>>> set_1
{3, 4, 5, 7, 10}
📚 Přečtěte si o množinách v Pythonu: Kompletní průvodce s ukázkami kódu
FrozenSets
Pokud potřebujete neměnnou množinu, můžete použít `frozenset`. Můžete ji vytvořit z existující množiny nebo jiného iterovatelného objektu.
>>> frozenset_1 = frozenset(set_1)
>>> frozenset_1
frozenset({3, 4, 5, 7, 10})
Protože `frozenset_1` je neměnná množina, pokus o přidání prvku (nebo jiná modifikace) způsobí chybu:
>>> frozenset_1.add(15) Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'frozenset' object has no attribute 'add'
Slovníky
Slovník v Pythonu funguje podobně jako hash mapa. Slovníky slouží k ukládání párů klíč–hodnota. Klíče slovníku musí být hashovatelné, což znamená, že hodnota hash objektu se nesmí měnit.
K hodnotám můžete přistupovat pomocí klíčů, vkládat nové položky a odstraňovat stávající položky v konstantním čase. Python nabízí metody pro provádění těchto operací.
>>> favorites = {'book':'Orlando'}
>>> favorites
{'book': 'Orlando'}
>>> favorites['author']='Virginia Woolf'
>>> favorites
{'book': 'Orlando', 'author': 'Virginia Woolf'}
>>> favorites.pop('author')
'Virginia Woolf'
>>> favorites
{'book': 'Orlando'}
OrderedDict
Ačkoli slovník v Pythonu nabízí mapování klíč–hodnota, je ze své podstaty neuspořádanou datovou strukturou. Od Pythonu 3.7 je sice zachováno pořadí vkládání prvků, pro větší přehlednost však můžete použít `OrderedDict` z modulu `collections`.
Jak je vidět na příkladu, `OrderedDict` zachovává pořadí klíčů:
>>> from collections import OrderedDict
>>> od = OrderedDict()
>>> od['first']='one'
>>> od['second']='two'
>>> od['third']='three'
>>> od
OrderedDict([('first', 'one'), ('second', 'two'), ('third', 'three')])
>>> od.keys()
odict_keys(['first', 'second', 'third'])
Defaultdict
Chyby klíče jsou při práci se slovníky v Pythonu poměrně časté. Kdykoli se pokusíte přistoupit ke klíči, který nebyl do slovníku přidán, vyvolá se výjimka `KeyError`.
Modul `defaultdict` z modulu `collections` vám však umožňuje tento problém elegantně vyřešit. Když se pokusíte přistoupit ke klíči, který se ve slovníku nenachází, klíč se přidá a inicializuje s výchozí hodnotou určenou výchozí továrnou.
>>> from collections import defaultdict >>> prices = defaultdict(int) >>> prices['carrots'] 0
Zásobníky
Zásobník je datová struktura typu LIFO (last-in-first-out), tedy „poslední dovnitř, první ven“. Se zásobníkem můžeme provádět následující operace:
- Přidání prvku na vrchol zásobníku (operace push)
- Odebrání prvku z vrcholu zásobníku (operace pop)
Následující příklad ilustruje, jak operace push a pop fungují:
Jak implementovat zásobník pomocí seznamu
V Pythonu můžeme implementovat datovou strukturu zásobníku pomocí seznamu.
| Operace se zásobníkem | Ekvivalentní operace se seznamem |
| Push na vrchol zásobníku | Přidání na konec seznamu pomocí metody `append()` |
| Pop z vrcholu zásobníku | Odebrání a vrácení posledního prvku pomocí metody `pop()` |
Následující ukázka kódu ilustruje, jak můžeme napodobit chování zásobníku pomocí seznamu v Pythonu:
>>> l_stk = [] >>> l_stk.append(4) >>> l_stk.append(3) >>> l_stk.append(7) >>> l_stk.append(2) >>> l_stk.append(9) >>> l_stk [4, 3, 7, 2, 9] >>> l_stk.pop() 9
Jak implementovat zásobník pomocí Deque
Dalším způsobem implementace zásobníku je použití `deque` z modulu `collections`. `Deque` znamená oboustrannou frontu a umožňuje přidávání a odebírání prvků z obou konců.
Pro emulaci zásobníku můžeme:
- Přidávat prvky na konec `deque` pomocí `append()`.
- Odebírat naposledy přidaný prvek pomocí `pop()`.
>>> from collections import deque >>> stk = deque() >>> stk.append(4) >>> stk.append(3) >>> stk.append(7) >>> stk.append(2) >>> stk.append(9) >>> stk deque([4, 3, 7, 2,9]) >>> stk.pop() 9
Fronty
Fronta je datová struktura typu FIFO (first-in-first-out), tedy „první dovnitř, první ven“. Prvky se přidávají na konec fronty a odebírají ze začátku fronty, jak je znázorněno:
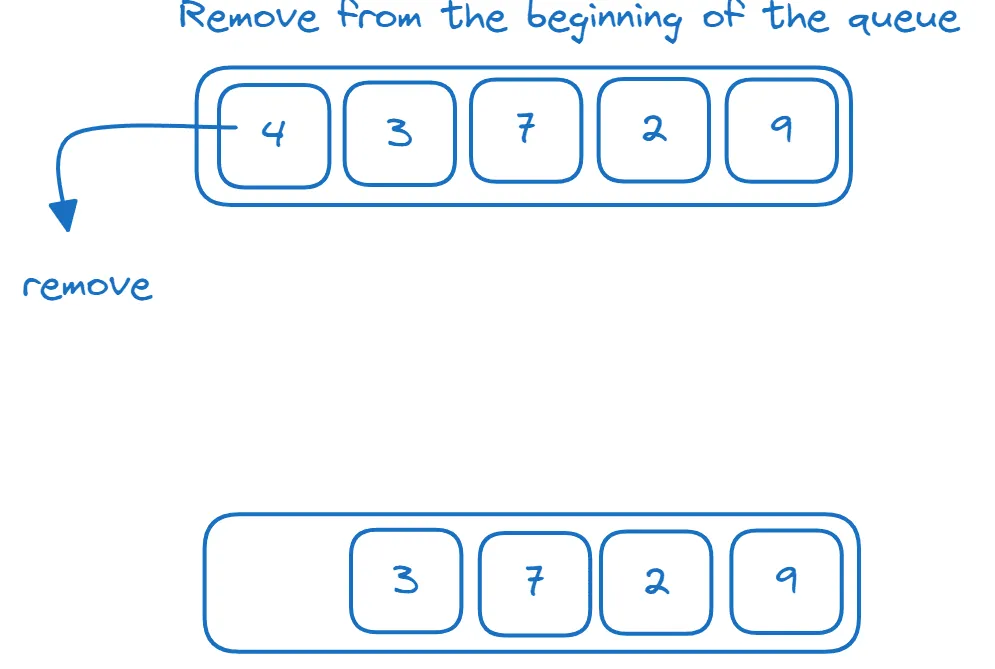
Datovou strukturu fronty můžeme implementovat pomocí `deque`:
- Přidáváme prvky na konec fronty pomocí metody `append()`.
- Pro odstranění prvku ze začátku fronty používáme metodu `popleft()`.
>>> from collections import deque >>> q = deque() >>> q.append(4) >>> q.append(3) >>> q.append(7) >>> q.append(2) >>> q.append(9) >>> q.popleft() 4
Halda (Heap)
V této sekci si probereme binární haldy, konkrétněji minimální haldy.
Minimální halda je kompletní binární strom. Pojďme si vysvětlit, co znamená „kompletní binární strom“:
- Binární strom je stromová datová struktura, kde každý uzel má maximálně dva podřízené uzly, a každý uzel je menší než jeho potomci.
- Termín „kompletní“ znamená, že strom je zcela zaplněn, s možnou výjimkou poslední úrovně. Pokud je poslední úroveň částečně zaplněna, je zaplněna zleva doprava.
Protože každý uzel má maximálně dva podřízené uzly a zároveň platí, že každý uzel je menší než jeho potomci, kořen je minimálním prvkem v minimální haldě.
Zde je příklad minimální haldy:
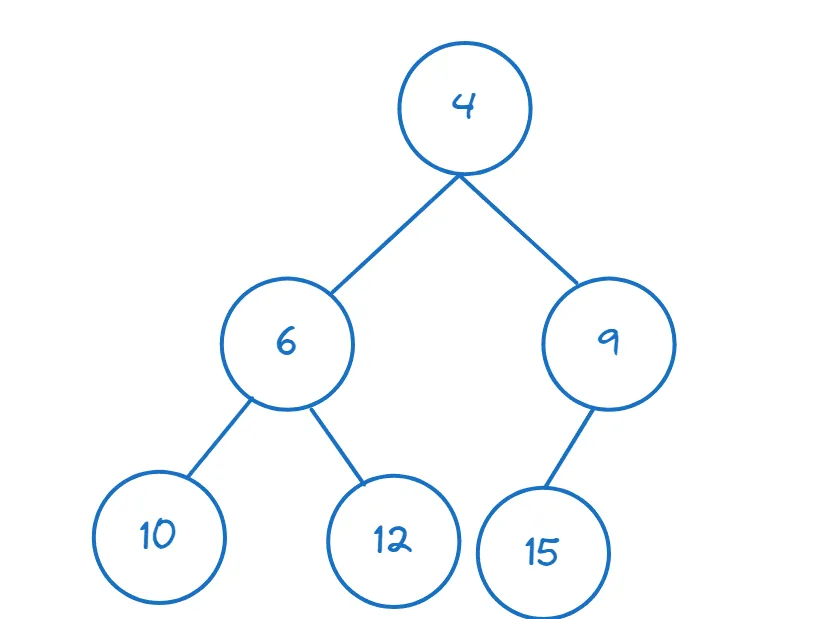
V Pythonu nám modul `heapq` umožňuje vytvářet haldy a provádět s nimi operace. Naimportujme si potřebné funkce z `heapq`:
>>> from heapq import heapify, heappush, heappop
Pokud máte seznam nebo jiný iterovatelný objekt, můžete z něj vytvořit haldu voláním `heapify()`:
>>> nums = [11,8,12,3,7,9,10] >>> heapify(nums)
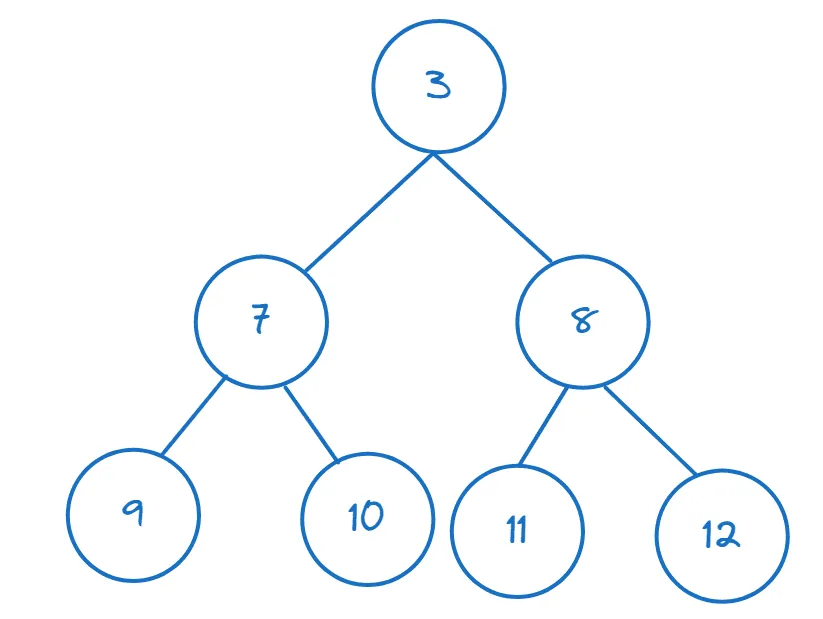
Můžete přistoupit k prvnímu prvku pomocí indexu a zkontrolovat, zda se jedná o minimální prvek:
>>> nums[0] 3
Když vložíte prvek do haldy, uzly se přeuspořádají tak, aby platila vlastnost minimální haldy:
>>> heappush(nums,1)
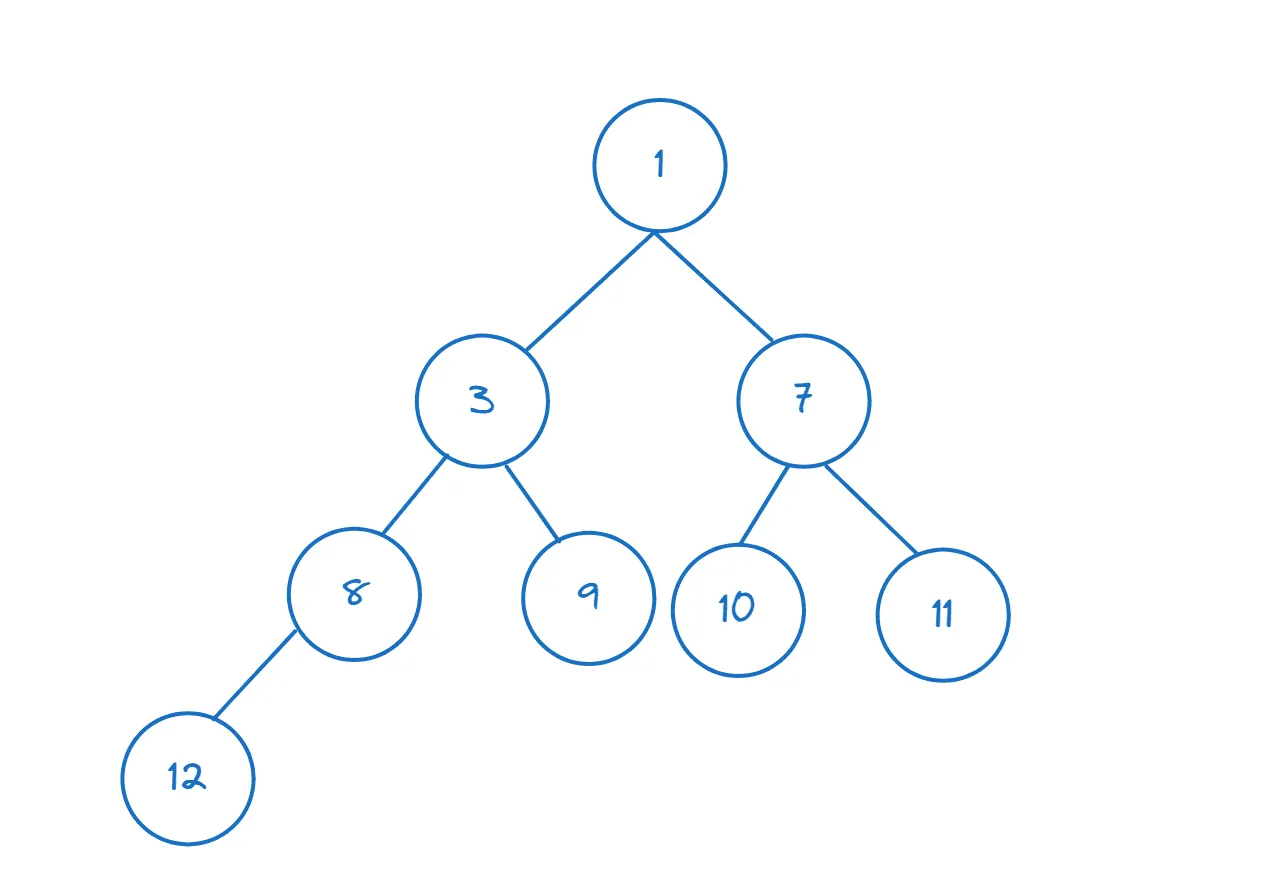
Protože jsme vložili 1 (1 < 3), vidíme, že `num[0]` vrátí 1, což je nyní minimální prvek (a kořenový uzel):
>>> nums[0] 1
Prvky z minimální haldy můžeme odebírat voláním funkce `heappop()`, jak je ukázáno níže:
>>> while nums: ... print(heappop(nums)) ...
# Output 1 3 7 8 9 10 11 12
Maximální haldy v Pythonu
Nyní, když znáte minimální haldy, dokážete odhadnout, jak můžeme implementovat maximální haldu?
Implementaci minimální haldy můžeme transformovat na maximální haldu vynásobením každého čísla -1. Negovaná čísla uspořádaná v minimální haldě jsou ekvivalentní původním číslům uspořádaným v maximální haldě.
V implementaci v Pythonu můžeme prvky vynásobit -1 při vkládání do haldy pomocí `heappush()`:
>>> maxHeap = [] >>> heappush(maxHeap,-2) >>> heappush(maxHeap,-5) >>> heappush(maxHeap,-7)
Kořenový uzel – vynásobený -1 – bude maximálním prvkem.
>>> -1*maxHeap[0] 7
Při odstraňování prvků z haldy použijte `heappop()` a vynásobte výsledek -1, abyste získali původní hodnotu:
>>> while maxHeap: ... print(-1*heappop(maxHeap)) ...
# Output 7 5 2
Prioritní fronty
Na závěr si probereme datovou strukturu prioritní fronty v Pythonu.
Jak víme, ve frontě se prvky odebírají ve stejném pořadí, v jakém do fronty přišly. Prioritní fronta však obsluhuje prvky podle jejich priority, což je užitečné například při plánování. V každém okamžiku je tedy vrácen prvek s nejvyšší prioritou.
Pro definování priority můžeme použít klíče. Zde použijeme číselné váhy pro klíče.
Jak implementovat prioritní fronty pomocí Heapq
Zde je implementace prioritní fronty pomocí `heapq` a seznamu v Pythonu:
>>> from heapq import heappush,heappop >>> pq = [] >>> heappush(pq,(2,'write')) >>> heappush(pq,(1,'read')) >>> heappush(pq,(3,'code')) >>> while pq: ... print(heappop(pq)) ...
Při odebírání prvků fronta obslouží nejprve prvek s nejvyšší prioritou (1, 'read'), následovaný (2, 'write') a poté (3, 'code').
# Output (1, 'read') (2, 'write') (3, 'code')
Jak implementovat prioritní fronty pomocí PriorityQueue
K implementaci prioritní fronty můžeme také použít třídu `PriorityQueue` z modulu `queue`. Tato třída interně také používá haldu.
Zde je ekvivalentní implementace prioritní fronty pomocí `PriorityQueue`:
>>> from queue import PriorityQueue >>> pq = PriorityQueue() >>> pq.put((2,'write')) >>> pq.put((1,'read')) >>> pq.put((3,'code')) >>> pq <queue.PriorityQueue object at 0x00BDE730> >>> while not pq.empty(): ... print(pq.get()) ...
# Output (1, 'read') (2, 'write') (3, 'code')
Shrnutí
V tomto tutoriálu jste se seznámili s různými vestavěnými datovými strukturami v Pythonu. Také jsme si prošli různé operace a vestavěné metody, které tyto datové struktury podporují.
Dále jsme se podívali na další datové struktury jako zásobníky, fronty a prioritní fronty a jejich implementace v Pythonu pomocí funkcí z modulu `collections`.
Nyní se můžete podívat na seznam projektů v Pythonu pro začátečníky.
