

Data se stávají stále důležitějšími pro vytváření modelů strojového učení, testování aplikací a vytváření obchodních poznatků.
Kvůli dodržení mnoha nařízení o údajích je však často uložen v trezoru a přísně chráněn. Přístup k takovým údajům může trvat měsíce, než získáte potřebné odhlášení. Alternativně mohou podniky používat syntetická data.
Table of Contents
Co jsou syntetická data?
Fotografický kredit: Twinify
Syntetická data jsou uměle generovaná data, která se statisticky podobají starému souboru dat. Může být použit se skutečnými daty k podpoře a vylepšení modelů AI nebo může být použit jako úplná náhrada.
Protože nepatří žádnému subjektu údajů a neobsahuje žádné osobní identifikační údaje ani citlivá data, jako jsou rodná čísla, lze je použít jako alternativu k ochraně soukromí ke skutečným výrobním údajům.
Rozdíly mezi skutečnými a syntetickými daty
- Nejzásadnější rozdíl je ve způsobu generování těchto dvou typů dat. Skutečná data pocházejí od skutečných subjektů, jejichž data byla shromážděna během průzkumů nebo když používali vaši aplikaci. Na druhou stranu syntetická data jsou uměle generována, ale stále se podobají původnímu souboru dat.
- Druhý rozdíl je v předpisech o ochraně údajů, které ovlivňují skutečná a syntetická data. Se skutečnými údaji by subjekty měly být schopny vědět, jaké údaje o nich jsou shromažďovány a proč jsou shromažďovány, a existují omezení, jak je lze použít. Tato nařízení se však již nevztahují na syntetická data, protože data nelze přiřadit subjektu a neobsahují osobní informace.
- Třetí rozdíl je v množství dostupných dat. Se skutečnými daty můžete mít jen tolik, kolik vám uživatelé dají. Na druhou stranu můžete generovat tolik syntetických dat, kolik chcete.
Proč byste měli zvážit použití syntetických dat
- Jeho výroba je relativně levnější, protože můžete generovat mnohem větší datové sady připomínající menší datovou sadu, kterou již máte. To znamená, že vaše modely strojového učení budou mít více dat k trénování.
- Vygenerovaná data jsou automaticky označena a vyčištěna za vás. To znamená, že nemusíte trávit čas časově náročnou prací na přípravu dat pro strojové učení nebo analýzu.
- Neexistují žádné problémy s ochranou soukromí, protože údaje neidentifikují osobně a nepatří subjektu údajů. To znamená, že jej můžete volně používat a sdílet.
- Předpojatost AI můžete překonat tím, že zajistíte dobré zastoupení menšinových tříd. To vám pomůže vybudovat spravedlivou a odpovědnou umělou inteligenci.
Jak generovat syntetická data
Zatímco proces generování se liší v závislosti na tom, který nástroj používáte, obecně proces začíná připojením generátoru k existující datové sadě. Poté identifikujete pole ve vaší datové sadě a označíte je pro vyloučení nebo zmatek.
Generátor pak začne identifikovat datové typy zbývajících sloupců a statistické vzory v těchto sloupcích. Od té doby můžete generovat tolik syntetických dat, kolik potřebujete.
Obvykle můžete porovnat vygenerovaná data s původní sadou dat, abyste viděli, jak dobře se syntetická data podobají skutečným datům.
Nyní prozkoumáme nástroje pro generování syntetických dat pro trénování modelů strojového učení.
Většinou AI

Umělá inteligence má většinou generátor syntetických dat poháněný umělou inteligencí, který se učí ze statistických vzorů původní datové sady. AI pak generuje fiktivní postavy, které odpovídají naučeným vzorům.
S většinou AI můžete generovat celé databáze s referenční integritou. Můžete syntetizovat nejrůznější data, která vám pomohou vytvářet lepší modely umělé inteligence.
Synthesized.io

Synthesized.io používají přední společnosti pro své iniciativy AI. Chcete-li použít synthesize.io, zadejte požadavky na data v konfiguračním souboru YAML.
Poté vytvoříte úlohu a spustíte ji jako součást datového kanálu. Má také velmi velkorysou bezplatnou vrstvu, která vám umožní experimentovat a zjistit, zda vyhovuje vašim datovým potřebám.
YData

Pomocí YData můžete generovat tabulková data, data časových řad, transakční, vícetabulková a relační data. To vám umožní vyhnout se problémům spojeným se sběrem, sdílením a kvalitou dat.
Dodává se s AI a SDK, které lze použít k interakci s jejich platformou. Kromě toho mají velkorysou bezplatnou úroveň, kterou můžete použít k demo produktu.
Gretel AI

Gretel AI nabízí API pro generování neomezeného množství syntetických dat. Gretel má generátor dat s otevřeným zdrojovým kódem, který si můžete nainstalovat a používat.
Případně můžete použít jejich REST API nebo CLI, což bude zpoplatněno. Jejich cena je však přiměřená a závisí na velikosti podniku.
Kopule
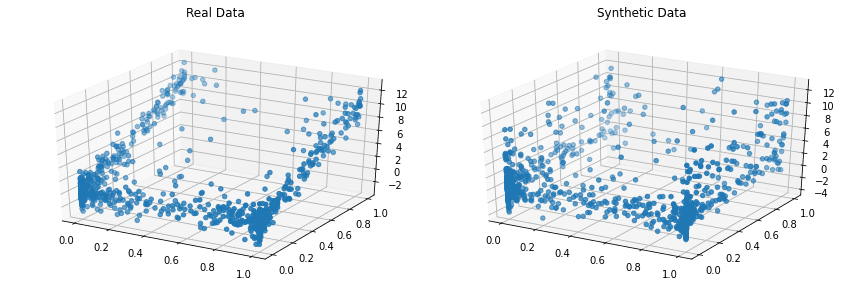
Copulas je open-source knihovna Pythonu pro modelování vícerozměrných distribucí pomocí funkcí kopule a generování syntetických dat, která mají stejné statistické vlastnosti.
Projekt začal v roce 2018 na MIT jako součást projektu Synthetic Data Vault.
CTGAN
CTGAN se skládá z generátorů, které jsou schopny se učit z jednotabulkových reálných dat a generovat syntetická data z identifikovaných vzorů.
Je implementována jako open-source Python knihovna. CTGAN je spolu s Copulas součástí projektu Synthetic Data Vault.
DoppelGANger
DoppelGANger je open-source implementace Generative Adversarial Networks pro generování syntetických dat.
DoppelGANger je užitečný pro generování dat časových řad a používají ho společnosti jako Gretel AI. Knihovna Python je k dispozici zdarma a je open source.
Synth

Synth je generátor dat s otevřeným zdrojovým kódem, který vám pomůže vytvořit realistická data podle vašich specifikací, skrýt osobně identifikovatelné informace a vyvinout testovací data pro vaše aplikace.
Synth můžete použít ke generování řad a relačních dat v reálném čase pro potřeby strojového učení. Synth je také databázový agnostik, takže jej můžete používat s databázemi SQL a NoSQL.
SDV.dev
SDV je zkratka pro Synthetic Data Vault. SDV.dev je softwarový projekt, který začal na MIT v roce 2016 a vytvořil různé nástroje pro generování syntetických dat.
Tyto nástroje zahrnují Copulas, CTGAN, DeepEcho a RDT. Tyto nástroje jsou implementovány jako open-source Python knihovny, které můžete snadno používat.
Tofu
Tofu je open-source Python knihovna pro generování syntetických dat založených na britských biobankách. Na rozdíl od výše zmíněných nástrojů, které vám pomohou generovat jakýkoli druh dat na základě vašeho stávajícího souboru dat, Tofu generuje data, která se podobají pouze těm z biobanky.
UK Biobank je studie o fenotypových a genotypových charakteristikách 500 000 dospělých ve středním věku ze Spojeného království.
Twinify
Twinify je softwarový balík používaný jako knihovna nebo nástroj příkazového řádku ke zdvojování citlivých dat vytvářením syntetických dat s identickým statistickým rozdělením.

Chcete-li používat Twinify, poskytnete skutečná data jako soubor CSV, který se z těchto dat naučí vytvořit model, který lze použít ke generování syntetických dat. Je zcela zdarma k použití.
Datanamic
Datanamic vám pomůže vytvořit testovací data pro aplikace řízené daty a strojové učení. Generuje data na základě charakteristik sloupců, jako je e-mail, jméno a telefonní číslo.
Datanamické datové generátory jsou přizpůsobitelné a podporují většinu databází, jako je Oracle, MySQL, MySQL Server, MS Access a Postgres. Podporuje a zajišťuje referenční integritu generovaných dat.
Benerátor
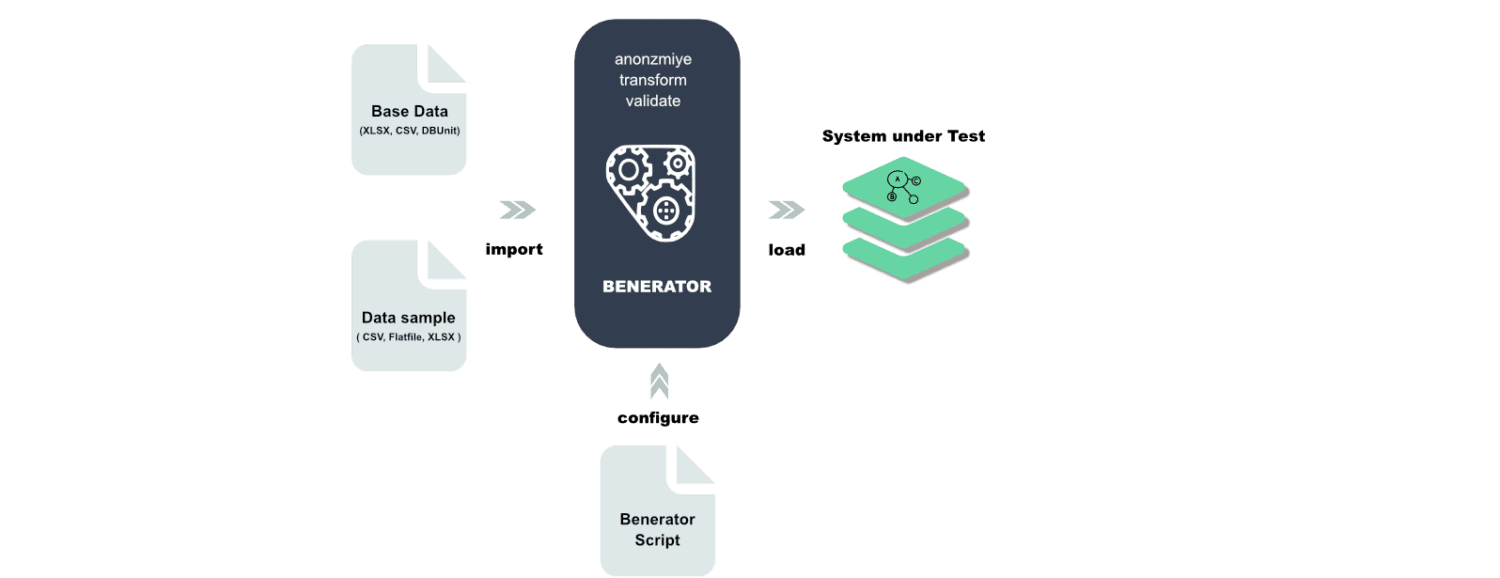
Benerator je software pro znejasňování, generování a migraci dat pro účely testování a školení. Pomocí Beneratoru popisujete data pomocí XML (Extensible Markup Language) a generujete pomocí nástroje příkazového řádku.
Je vyroben tak, aby jej mohli používat i nevývojáři, a můžete s ním generovat miliardy řádků dat. Benerator je zdarma a s otevřeným zdrojovým kódem.
Závěrečná slova
Gartner odhaduje, že do roku 2030 bude pro strojové učení používáno více syntetických dat než skutečných dat.
Není těžké pochopit, proč vzhledem k nákladům a obavám o soukromí při používání skutečných dat. Je proto nutné, aby se podniky dozvěděly o syntetických datech a různých nástrojích, které jim pomohou při jejich generování.
Dále se podívejte na syntetické monitorovací nástroje pro vaše online podnikání.