
Data science je určena pro každého, kdo miluje rozplétání zamotaných věcí a objevování skrytých zázraků ve zdánlivém nepořádku.
Je to jako hledat jehly v kupkách sena; pouze datoví vědci si vůbec nepotřebují špinit ruce. Pomocí efektních nástrojů s barevnými grafy a při pohledu na hromady čísel se prostě ponoří do kupy sena a nacházejí cenné jehly v podobě postřehů s vysokou obchodní hodnotou.
Typické datový vědec sada nástrojů by měla obsahovat alespoň jednu položku z každé z těchto kategorií: relační databáze, databáze NoSQL, rámce velkých dat, vizualizační nástroje, nástroje scraping, programovací jazyky, IDE a nástroje hlubokého učení.
Table of Contents
Relační databáze
Relační databáze je kolekce dat strukturovaných do tabulek s atributy. Tabulky lze vzájemně propojovat, definovat vztahy a omezení a vytvářet to, čemu se říká datový model. Pro práci s relačními databázemi běžně používáte jazyk zvaný SQL (Structured Query Language).
Aplikace, které spravují strukturu a data v relačních databázích, se nazývají RDBMS (Relational DataBase Management Systems). Takových aplikací je spousta a ty nejrelevantnější se v poslední době začaly zaměřovat na oblast datové vědy, přidávají funkce pro práci s velkými datovými úložišti a používají techniky, jako je analýza dat a strojové učení.
SQL Server
RDBMS společnosti Microsoft, se vyvíjí již více než 20 let neustálým rozšiřováním svých podnikových funkcí. Od verze 2016 nabízí SQL Server portfolio služeb, které zahrnují podporu pro vestavěný R kód. SQL Server 2017 zvyšuje sázku přejmenováním svých R Services na Machine Language Services a přidáním podpory pro jazyk Python (více o těchto dvou jazycích níže).
S těmito důležitými doplňky se SQL Server zaměřuje na datové vědce, kteří nemusí mít zkušenosti s Transact SQL, nativním dotazovacím jazykem Microsoft SQL Server.
SQL Server zdaleka není bezplatný produkt. Můžete si zakoupit licence pro instalaci na Windows Server (cena se bude lišit podle počtu souběžných uživatelů) nebo jej použít jako placenou službu prostřednictvím cloudu Microsoft Azure. Naučit se Microsoft SQL Server je snadné.
MySQL
Na straně softwaru s otevřeným zdrojovým kódem MySQL má korunu popularity RDBMS. Ačkoli jej v současné době vlastní Oracle, je stále zdarma a open-source podle podmínek GNU General Public License. Většina webových aplikací používá MySQL jako základní datové úložiště, a to díky jeho souladu se standardem SQL.
K jeho popularitě také pomáhají jeho snadné instalační postupy, velká komunita vývojářů, spousta komplexní dokumentace a nástroje třetích stran, jako je phpMyAdmin, které zjednodušují každodenní činnosti správy. Přestože MySQL nemá žádné nativní funkce pro analýzu dat, jeho otevřenost umožňuje jeho integraci s téměř jakýmkoli nástrojem pro vizualizaci, sestavování a business intelligence, který si můžete vybrat.
PostgreSQL
Další možností open source RDBMS je PoztgreSQL. Ačkoli není PostgreSQL tak populární jako MySQL, vyniká svou flexibilitou a rozšiřitelností a podporou pro složité dotazy, které jdou nad rámec základních příkazů, jako jsou SELECT, WHERE a GROUP BY.
Tyto funkce mu umožňují získat popularitu mezi datovými vědci. Další zajímavou funkcí je podpora multi-prostředí, která umožňuje použití v cloudových a on-premise prostředích nebo v mixu obou, běžně známých jako hybridní cloudová prostředí.
PostgreSQL je schopen kombinovat online analytické zpracování (OLAP) s online zpracováním transakcí (OLTP), přičemž pracuje v režimu zvaném hybridní transakční/analytické zpracování (HTAP). Je také vhodný pro práci s velkými daty, a to díky přidání PostGIS pro geografická data a JSON-B pro dokumenty. PostgreSQL také podporuje nestrukturovaná data, což mu umožňuje být v obou kategoriích: SQL a NoSQL databáze.
NoSQL databáze
Tento typ úložiště dat, známý také jako nerelační databáze, poskytuje rychlejší přístup k netabulkovým datovým strukturám. Některé příklady těchto struktur jsou grafy, dokumenty, široké sloupce, klíčové hodnoty a mnoho dalších. Datová úložiště NoSQL mohou dát stranou konzistenci dat ve prospěch jiných výhod, jako je dostupnost, rozdělení a rychlost přístupu.
Protože v datových úložištích NoSQL není žádný SQL, jediný způsob, jak se dotazovat na tento druh databáze, je použití nízkoúrovňových jazyků a neexistuje žádný takový jazyk, který by byl tak široce akceptován jako SQL. Kromě toho neexistují žádné standardní specifikace pro NoSQL. To je důvod, proč paradoxně některé databáze NoSQL začínají přidávat podporu pro SQL skripty.
MongoDB
MongoDB je oblíbený databázový systém NoSQL, který ukládá data ve formě dokumentů JSON. Zaměřuje se na škálovatelnost a flexibilitu ukládání dat nestrukturovaným způsobem. To znamená, že neexistuje žádný pevný seznam polí, který je třeba dodržovat ve všech uložených prvcích. Kromě toho se struktura dat může v průběhu času měnit, což v relační databázi znamená vysoké riziko ovlivnění běžících aplikací.

Technologie v MongoDB umožňuje indexování, ad-hoc dotazy a agregaci, které poskytují silný základ pro analýzu dat. Distribuovaná povaha databáze poskytuje vysokou dostupnost, škálování a geografickou distribuci bez potřeby sofistikovaných nástrojů.
Redis
Tento jedna je další možností v open-source, NoSQL frontě. Jde v podstatě o úložiště datových struktur, které funguje v paměti a kromě poskytování databázových služeb funguje také jako cache paměť a zprostředkovatel zpráv.

Podporuje nesčetné množství nekonvenčních datových struktur, včetně hashů, geoprostorových indexů, seznamů a tříděných sad. Dobře se hodí pro datovou vědu díky svému vysokému výkonu v úlohách náročných na data, jako je výpočet průsečíků množin, řazení dlouhých seznamů nebo generování komplexních hodnocení. Důvodem vynikajícího výkonu Redis je jeho operace v paměti. Lze jej nakonfigurovat tak, aby selektivně uchovával data.
Rámce pro velká data
Předpokládejme, že musíte analyzovat data, která uživatelé Facebooku generují během měsíce. Bavíme se o fotkách, videích, zprávách, o tom všem. Vzhledem k tomu, že každý den na sociální síť její uživatelé přidají více než 500 terabajtů dat, je těžké měřit objem, který představuje celý měsíc jejích dat.
Chcete-li efektivně manipulovat s tímto obrovským množstvím dat, potřebujete vhodný rámec schopný počítat statistiky na distribuované architektuře. Existují dva z rámců, které vedou trh: Hadoop a Spark.
hadoop
Jako velký datový rámec, hadoop se zabývá složitostmi spojenými s vyhledáváním, zpracováním a ukládáním obrovských hromad dat. Hadoop funguje v distribuovaném prostředí složeném z počítačových clusterů, které zpracovávají jednoduché algoritmy. Existuje orchestrační algoritmus nazvaný MapReduce, který rozděluje velké úkoly na malé části a poté tyto malé úkoly rozděluje mezi dostupné clustery.

Hadoop se doporučuje pro datová úložiště podnikové třídy, která vyžadují rychlý přístup a vysokou dostupnost, to vše v nízkonákladovém schématu. Ale potřebujete administrátora Linuxu s deep Znalost hadoopu udržovat a provozovat rámec.
Jiskra
Hadoop není jediným dostupným rámcem pro manipulaci s velkými daty. Dalším velkým jménem v této oblasti je Jiskra. Spark engine byl navržen tak, aby překonal Hadoop, pokud jde o rychlost analýzy a snadné použití. Tohoto cíle zřejmě dosáhl: některá srovnání říkají, že Spark běží až 10krát rychleji než Hadoop při práci na disku a 100krát rychleji pracuje v paměti. Ke zpracování stejného množství dat také vyžaduje menší počet strojů.

Kromě rychlosti je další výhodou Sparku jeho podpora pro zpracování streamů. Tento typ zpracování dat, nazývaný také zpracování v reálném čase, zahrnuje nepřetržitý vstup a výstup dat.
Vizualizační nástroje
Obvyklý vtip mezi datovými vědci říká, že pokud budete mučit data dostatečně dlouho, přizná vám to, co potřebujete vědět. V tomto případě „mučení“ znamená manipulovat s daty jejich transformací a filtrováním za účelem lepší vizualizace. A tam přicházejí na scénu nástroje pro vizualizaci dat. Tyto nástroje berou předem zpracovaná data z různých zdrojů a ukazují jejich odhalené pravdy v grafických, srozumitelných formách.
Existují stovky nástrojů, které spadají do této kategorie. Ať se vám to líbí nebo ne, nejpoužívanější je Microsoft Excel a jeho nástroje pro tvorbu grafů. Excelové grafy jsou přístupné každému, kdo používá Excel, ale mají omezenou funkčnost. Totéž platí pro další tabulkové aplikace, jako jsou Tabulky Google a Libre Office. Ale mluvíme zde o specifičtějších nástrojích, speciálně přizpůsobených pro business intelligence (BI) a analýzu dat.
Power BI
Není to tak dávno, co Microsoft vydal svůj Power BI vizualizační aplikace. Dokáže přebírat data z různých zdrojů, jako jsou textové soubory, databáze, tabulky a mnoho online datových služeb, včetně Facebooku a Twitteru, a používat je ke generování řídicích panelů plných grafů, tabulek, map a mnoha dalších vizualizačních objektů. Objekty dashboardu jsou interaktivní, což znamená, že můžete kliknout na datovou řadu v grafu, vybrat ji a použít ji jako filtr pro ostatní objekty na tabuli.
Power BI je kombinací desktopové aplikace pro Windows (součást sady Office 365), webové aplikace a online služby pro publikování řídicích panelů na webu a jejich sdílení s vašimi uživateli. Tato služba vám umožňuje vytvářet a spravovat oprávnění k udělení přístupu k nástěnkám pouze určitým lidem.
Živý obraz
Živý obraz je další možností, jak vytvořit interaktivní dashboardy z kombinace více zdrojů dat. Nabízí také verzi pro stolní počítače, webovou verzi a online službu pro sdílení vámi vytvořených řídicích panelů. Funguje přirozeně „s tím, jak myslíte“ (jak tvrdí), a je snadno použitelný pro netechnické lidi, což je vylepšeno množstvím tutoriálů a online videí.
Některé z nejvýraznějších funkcí Tableau jsou neomezené datové konektory, živá data a data v paměti a návrhy optimalizované pro mobily.
QlikView
QlikView nabízí čisté a přímočaré uživatelské rozhraní, které analytikům pomáhá objevovat nové poznatky ze stávajících dat prostřednictvím vizuálních prvků, které jsou snadno srozumitelné pro každého.
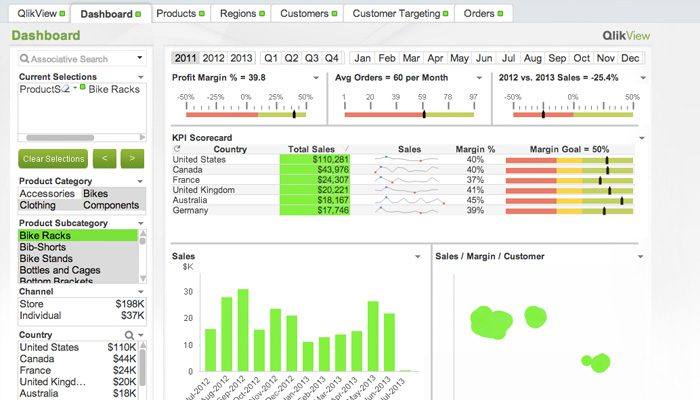
Tento nástroj je známý jako jedna z nejflexibilnějších platforem business intelligence. Poskytuje funkci nazvanou Asociativní vyhledávání, která vám pomůže zaměřit se na nejdůležitější data a ušetří vám čas, který by zabralo jejich vlastní nalezení.
S QlikView můžete spolupracovat s partnery v reálném čase a provádět srovnávací analýzy. Všechna příslušná data lze sloučit do jedné aplikace s bezpečnostními funkcemi, které omezují přístup k datům.
Nástroje na škrábání
V dobách, kdy se internet teprve rozvíjel, webové prohledávače začaly cestovat společně se sítěmi a shromažďovaly informace, které jim stály v cestě. Jak se technologie vyvíjela, termín procházení webu se změnil na web scraping, ale stále znamená totéž: automaticky extrahovat informace z webových stránek. Chcete-li provádět web scraping, používáte automatizované procesy nebo roboty, které přeskakují z jedné webové stránky na druhou, extrahují z nich data a exportují je do různých formátů nebo je vkládají do databází pro další analýzu.
Níže shrnujeme charakteristiky tří nejpopulárnějších webových škrabek, které jsou dnes k dispozici.
Octoparse
Octoparse web scraper nabízí některé zajímavé vlastnosti, včetně vestavěných nástrojů pro získávání informací z webových stránek, které neusnadňují scrapingovým robotům jejich práci. Jedná se o desktopovou aplikaci, která nevyžaduje žádné kódování, s uživatelsky přívětivým uživatelským rozhraním, které umožňuje vizualizaci procesu extrakce prostřednictvím grafického návrháře pracovních postupů.
Spolu se samostatnou aplikací nabízí Octoparse cloudovou službu pro urychlení procesu extrakce dat. Uživatelé mohou zažít 4x až 10x zvýšení rychlosti při používání cloudové služby namísto desktopové aplikace. Pokud se budete držet desktopové verze, můžete Octoparse používat zdarma. Pokud však dáváte přednost používání cloudové služby, budete si muset vybrat jeden z jejích placených plánů.
Grabber obsahu
Pokud hledáte nástroj na škrábání s bohatými funkcemi, měli byste se po něm poohlédnout Grabber obsahu. Na rozdíl od Octoparse je pro použití Content Grabber nutné mít pokročilé programovací dovednosti. Výměnou za to získáte úpravy skriptů, ladění rozhraní a další pokročilé funkce. S Content Grabber můžete používat jazyky .Net k psaní regulárních výrazů. Tímto způsobem nemusíte generovat výrazy pomocí vestavěného nástroje.
Nástroj nabízí rozhraní API (Application Programming Interface), které můžete použít k přidání funkcí scrapingu do vašich desktopových a webových aplikací. Aby mohli vývojáři používat toto rozhraní API, potřebují získat přístup ke službě Content Grabber Windows.
ParseHub
Tato škrabka dokáže zpracovat rozsáhlý seznam různých typů obsahu, včetně fór, vnořených komentářů, kalendářů a map. Poradí si také se stránkami, které obsahují ověřování, Javascript, Ajax a další. ParseHub lze použít jako webovou aplikaci nebo desktopovou aplikaci schopnou běžet na Windows, macOS X a Linux.
Stejně jako Content Grabber se doporučuje mít určité znalosti programování, abyste mohli z ParseHubu vytěžit maximum. Má bezplatnou verzi, omezenou na 5 projektů a 200 stránek na běh.
Programovací jazyky
Stejně jako dříve zmíněný jazyk SQL je navržen speciálně pro práci s relačními databázemi, existují i jiné jazyky vytvořené s jasným zaměřením na datovou vědu. Tyto jazyky umožňují vývojářům psát programy, které se zabývají masivní analýzou dat, jako jsou statistiky a strojové učení.
SQL je také považováno za důležitou dovednost, kterou by vývojáři měli mít pro vědu o datech, ale je to proto, že většina organizací má stále mnoho dat v relačních databázích. „Opravdové“ jazyky datové vědy jsou R a Python.
Krajta

Krajta je vysokoúrovňový, interpretovaný, univerzální programovací jazyk, vhodný pro rychlý vývoj aplikací. Má jednoduchou a snadno naučitelnou syntaxi, která umožňuje strmou křivku učení a snižuje náklady na údržbu programu. Existuje mnoho důvodů, proč je to preferovaný jazyk pro datovou vědu. Abychom zmínili několik: skriptovací potenciál, výřečnost, přenositelnost a výkon.
Tento jazyk je dobrým výchozím bodem pro datové vědce, kteří plánují hodně experimentovat, než se pustí do skutečné a tvrdé práce na drcení dat, a kteří chtějí vyvíjet kompletní aplikace.
R
The jazyk R se používá především pro statistické zpracování dat a grafů. Přestože není určen k vývoji plnohodnotných aplikací, jako by tomu bylo v případě Pythonu, R se v posledních letech stal velmi populární díky svému potenciálu pro dolování dat a analýzu dat.

Díky neustále rostoucí knihovně volně dostupných balíčků, které rozšiřují jeho funkčnost, je R schopen provádět všechny druhy práce s daty, včetně lineárního/nelineárního modelování, klasifikace, statistických testů atd.
Není to jednoduchý jazyk na naučení, ale jakmile se seznámíte s jeho filozofií, budete dělat statistické výpočty jako profík.
IDE
Pokud vážně uvažujete o tom, že se budete věnovat datové vědě, budete si muset pečlivě vybrat integrované vývojové prostředí (IDE), které vyhovuje vašim potřebám, protože vy a vaše IDE strávíte spoustu času spoluprací.
Ideální IDE by mělo dát dohromady všechny nástroje, které potřebujete při své každodenní práci kodéra: textový editor se zvýrazňováním syntaxe a automatickým doplňováním, výkonný ladicí program, prohlížeč objektů a snadný přístup k externím nástrojům. Kromě toho musí být kompatibilní s jazykem, který preferujete, takže je dobré vybrat si své IDE poté, co víte, jaký jazyk budete používat.
Spyder
Tento generic IDE je většinou určeno pro vědce a analytiky, kteří také potřebují kódovat. Aby byly pohodlné, neomezuje se pouze na funkcionalitu IDE – poskytuje také nástroje pro průzkum/vizualizaci dat a interaktivní spouštění, jak lze nalézt na vědeckém balíčku. Editor ve Spyderu podporuje více jazyků a přidává prohlížeč tříd, rozdělování oken, skok na definici, automatické dokončování kódu a dokonce nástroj pro analýzu kódu.
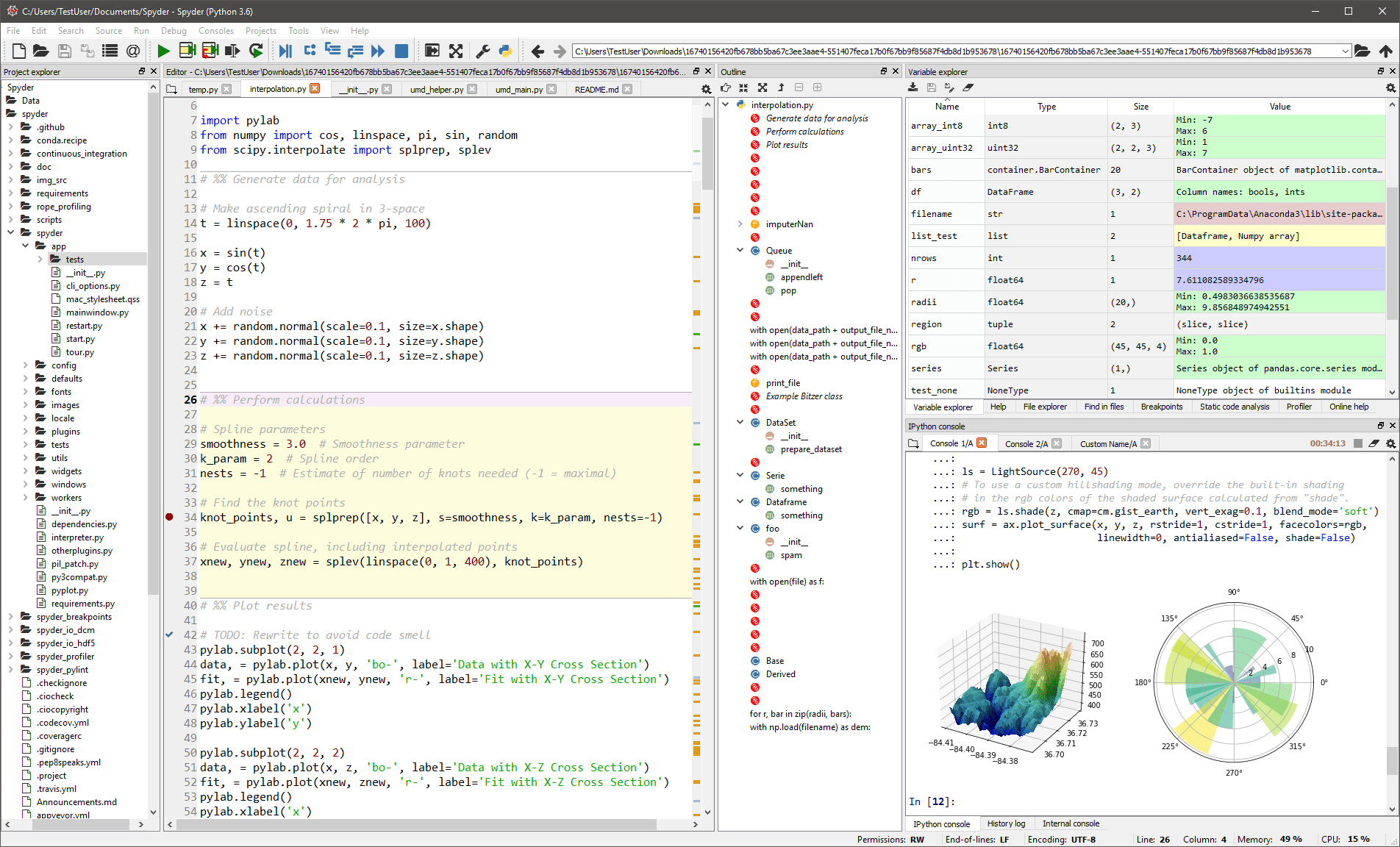
Ladicí program vám pomůže interaktivně sledovat každý řádek kódu a profiler vám pomůže najít a odstranit neefektivitu.
PyCharm
Pokud programujete v Pythonu, je pravděpodobné, že vámi zvolené IDE bude PyCharm. Má inteligentní editor kódu s inteligentním vyhledáváním, doplňováním kódu a detekcí a opravou chyb. Jediným kliknutím můžete přejít z editoru kódu do jakéhokoli kontextového okna, včetně testu, super metody, implementace, deklarace a dalších. PyCharm podporuje Anacondu a mnoho vědeckých balíčků, jako je NumPy a Matplotlib, abychom jmenovali jen dva z nich.
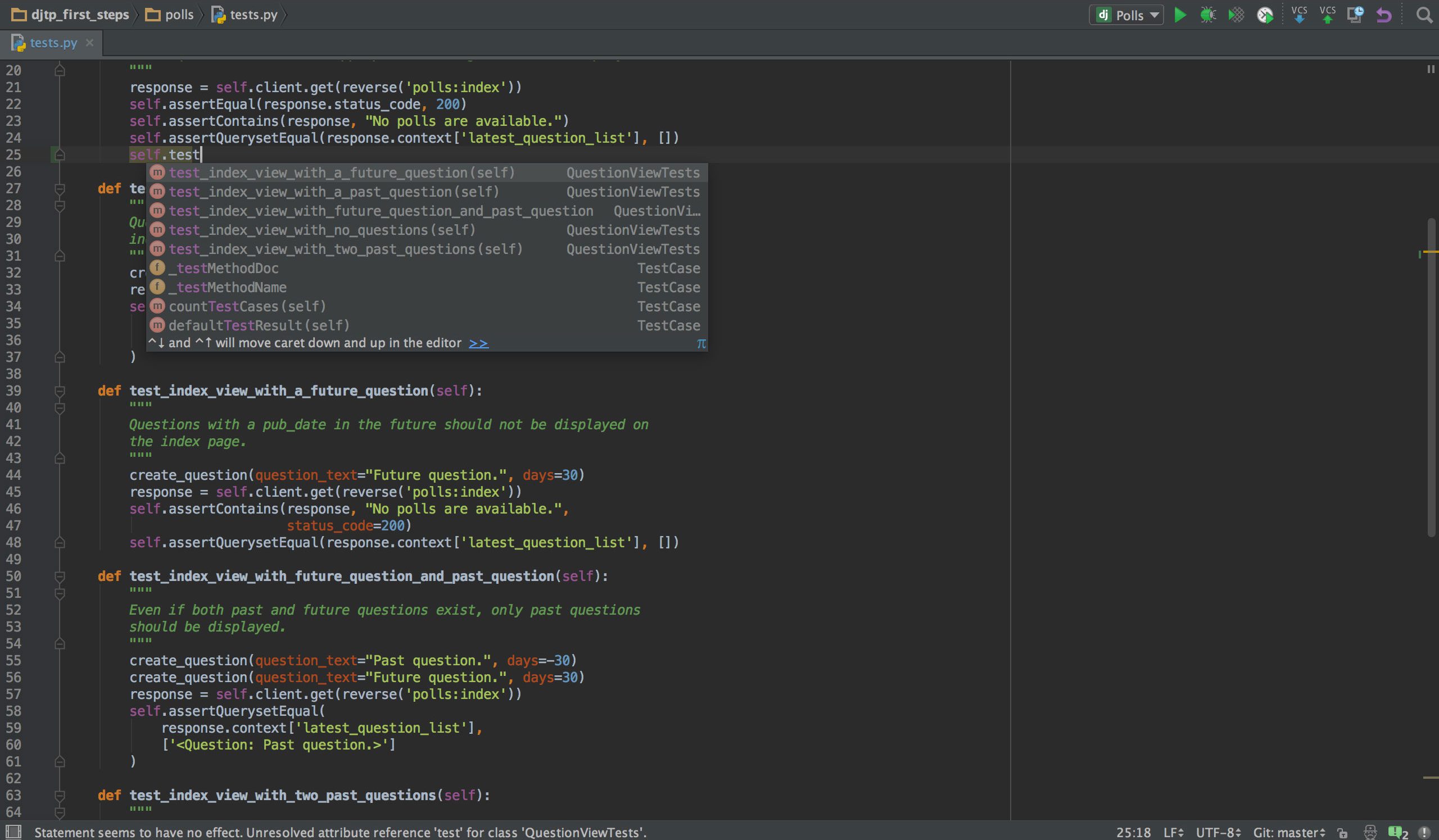
Nabízí integraci s nejdůležitějšími systémy pro správu verzí a také s testovacím programem, profilerem a debuggerem. K uzavření dohody se také integruje s Docker a Vagrant, aby zajistil vývoj a kontejnerizaci napříč platformami.
RStudio
Pro vědce zabývající se daty, kteří preferují tým R, by mělo být IDE volbou RStudio, protože má mnoho funkcí. Můžete jej nainstalovat na plochu s Windows, macOS nebo Linux, nebo jej můžete spustit z webového prohlížeče, pokud jej nechcete instalovat lokálně. Obě verze nabízejí vychytávky, jako je zvýraznění syntaxe, inteligentní odsazení a dokončování kódu. K dispozici je integrovaný prohlížeč dat, který se hodí, když potřebujete procházet tabulková data.
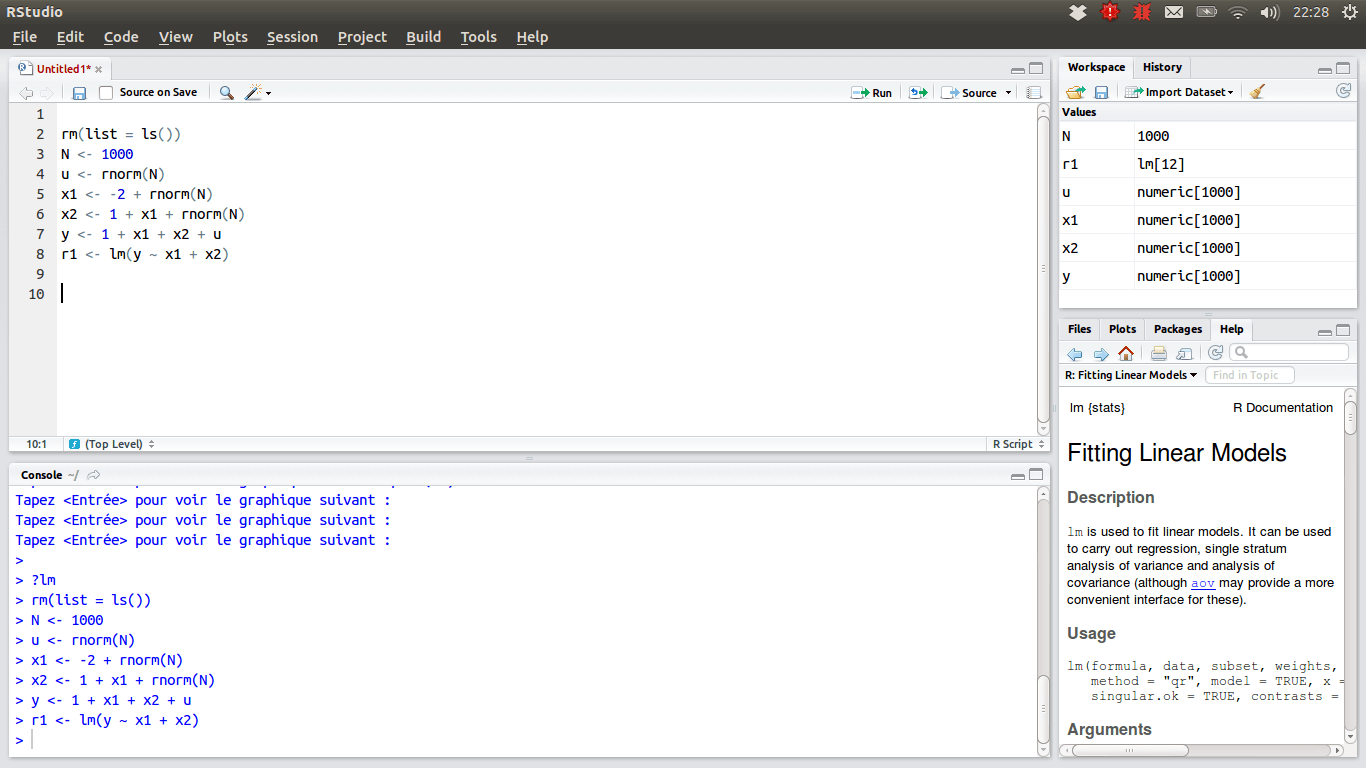
Režim ladění umožňuje sledovat, jak se data dynamicky aktualizují při provádění programu nebo skriptu krok za krokem. Pro správu verzí RStudio integruje podporu pro SVN a Git. Příjemným plusem je možnost vytvářet interaktivní grafiku s knihovnami Shiny a dá.
Vaše osobní sada nástrojů
V tomto okamžiku byste měli mít úplný přehled o nástrojích, které byste měli znát, abyste vynikli v datové vědě. Doufáme také, že jsme vám poskytli dostatek informací, abyste se mohli rozhodnout, která možnost je v každé kategorii nástrojů nejvhodnější. Teď je to na vás. Datová věda je vzkvétající obor rozvíjet kariéru. Ale pokud to chcete udělat, musíte držet krok se změnami v trendech a technologiích, protože k nim dochází téměř denně.