
Statistiky Forbesu uvádějí, že až 90 % světových organizací používá k vytváření svých investičních reportů analýzu velkých dat.
S rostoucí popularitou Big Data dochází následně k nárůstu pracovních příležitostí Hadoop více než dříve.
Proto, abychom vám pomohli získat roli odborníka na Hadoop, můžete použít tyto otázky a odpovědi na pohovor, které jsme pro vás sestavili v tomto článku, abychom vám pomohli projít pohovorem.
Možná vás znalost faktů, jako je rozsah platů, díky kterým jsou role Hadoop a Big Data lukrativní, motivuje k tomu, abyste ten pohovor absolvovali, že? 🤔
- Podle serveru really.com vydělává americký Big Data Hadoop vývojář průměrný plat 144 000 $.
- Podle itjobswatch.co.uk je průměrný plat vývojáře Big Data Hadoop 66 750 GBP.
- V Indii zdroj Actual.com uvádí, že by si vydělali průměrný plat 16 00 000 ₹.
Lukrativní, nemyslíte? Nyní se vrhneme na informace o Hadoopu.
Table of Contents
Co je Hadoop?
Hadoop je populární framework napsaný v Javě, který používá programovací modely ke zpracování, ukládání a analýze velkých sad dat.
Ve výchozím nastavení jeho design umožňuje škálování z jednotlivých serverů na více strojů, které nabízejí místní výpočet a úložiště. Navíc jeho schopnost detekovat a řešit selhání aplikační vrstvy, což má za následek vysoce dostupné služby, činí Hadoop docela spolehlivým.
Přejděme rovnou k často kladeným otázkám při pohovorech Hadoop a jejich správným odpovědím.
Otázky a odpovědi k rozhovoru Hadoop
Co je to úložná jednotka v Hadoopu?
Odpověď: Úložná jednotka Hadoop se nazývá Hadoop Distributed File System (HDFS).
Jak se síťové úložiště liší od distribuovaného souborového systému Hadoop?
Odpověď: HDFS, což je primární úložiště Hadoopu, je distribuovaný souborový systém, který ukládá masivní soubory pomocí komoditního hardwaru. Na druhou stranu je NAS server pro ukládání dat na úrovni souborů, který poskytuje heterogenním skupinám klientů přístup k datům.
Zatímco úložiště dat v NAS je na vyhrazeném hardwaru, HDFS distribuuje datové bloky na všechny počítače v clusteru Hadoop.
NAS používá špičková úložná zařízení, což je poměrně nákladné, zatímco komoditní hardware používaný v HDFS je nákladově efektivní.
NAS odděleně ukládá data z výpočtů, a proto je pro MapReduce nevhodný. Naopak design HDFS umožňuje pracovat s frameworkem MapReduce. Výpočty se přesunou do dat v rámci MapReduce namísto dat do výpočtů.
Vysvětlete MapReduce v Hadoop a Shuffling
Odpověď: MapReduce odkazuje na dva různé úkoly, které provádějí programy Hadoop, aby umožnily velkou škálovatelnost napříč stovkami až tisíci serverů v rámci clusteru Hadoop. Shuffling na druhou stranu přenese mapový výstup z Mappers do potřebného Reduceru v MapReduce.
Nahlédněte do architektury Apache Pig
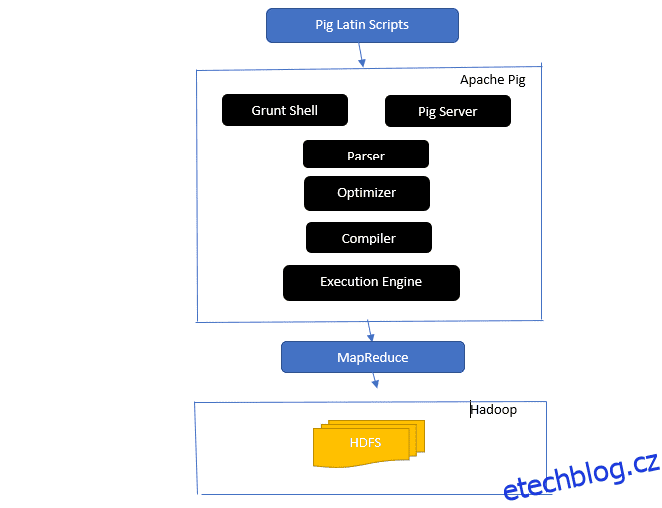
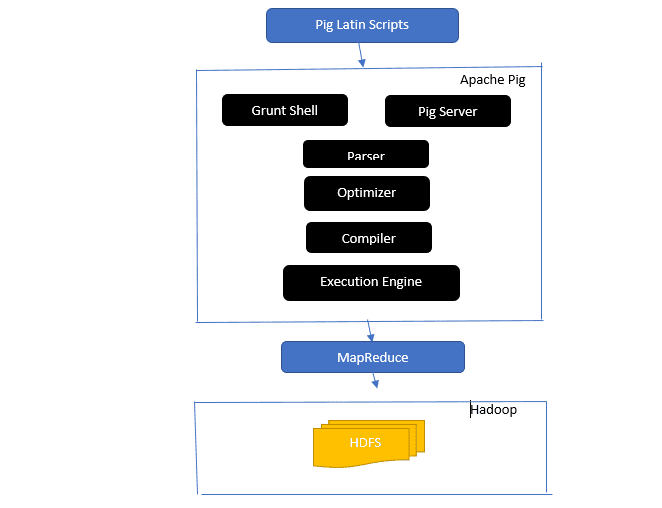 Architektura prasete Apache
Architektura prasete Apache
Odpověď: Architektura Apache Pig má interpret Pig Latin, který zpracovává a analyzuje velké datové sady pomocí skriptů Pig Latin.
Apache pig se také skládá ze sad datových sad, na kterých se provádějí datové operace, jako je spojení, načtení, filtrování, řazení a seskupování.
Jazyk Pig Latin používá spouštěcí mechanismy, jako jsou Grant shelly, UDF a vestavěné pro psaní Pig skriptů, které provádějí požadované úkoly.
Pig usnadňuje práci programátorů tím, že tyto psané skripty převádí na série úloh Map-Reduce.
Mezi komponenty architektury Apache Pig patří:
- Parser – Zpracovává prasečí skripty tím, že kontroluje syntaxi skriptu a provádí kontrolu typu. Výstup analyzátoru představuje příkazy a logické operátory Pig Latin a nazývá se DAG (directed acyclic graph).
- Optimalizátor – Optimalizátor implementuje logické optimalizace, jako je projekce a posunutí na DAG.
- Kompilátor – Kompiluje optimalizovaný logický plán z optimalizátoru do řady úloh MapReduce.
- Execution Engine – Zde dochází ke konečnému provedení úloh MapReduce do požadovaného výstupu.
- Execution Mode – Režimy provedení v Apache pig zahrnují hlavně místní a Map Reduce.
Odpověď: Služba Metastore v Local Metastore běží na stejném JVM jako Hive, ale připojuje se k databázi běžící v samostatném procesu na stejném nebo vzdáleném počítači. Na druhou stranu, Metastore ve vzdáleném Metastore běží ve svém JVM odděleně od JVM služby Hive.
Co je pět V velkých dat?
Odpověď: Těchto pět V představuje hlavní charakteristiky Big Data. Obsahují:
- Hodnota: Velká data se snaží poskytovat významné výhody z vysoké návratnosti investic (ROI) organizaci, která používá velká data ve svých datových operacích. Velká data přinášejí tuto hodnotu z objevování náhledů a rozpoznávání vzorů, což má za následek mimo jiné silnější vztahy se zákazníky a efektivnější operace.
- Rozmanitost: Představuje heterogenitu typu shromážděných datových typů. Mezi různé formáty patří CSV, videa, zvuk atd.
- Objem: Definuje významné množství a velikost dat spravovaných a analyzovaných organizací. Tato data ukazují exponenciální růst.
- Rychlost: Toto je exponenciální rychlost růstu dat.
- Pravdivost: Pravdivost se týká toho, jak „nejistá“ nebo „nepřesná“ data jsou dostupná kvůli neúplným nebo nekonzistentním datům.
Vysvětlete různé datové typy prasečí latiny.
Odpověď: Datové typy v Pig Latin zahrnují atomické datové typy a komplexní datové typy.
Datové typy Atomic jsou základní datové typy používané v každém jiném jazyce. Patří mezi ně následující:
- Int – Tento datový typ definuje 32bitové celé číslo se znaménkem. Příklad: 13
- Long – Long definuje 64bitové celé číslo. Příklad: 10L
- Float – Definuje 32bitovou plovoucí desetinnou čárku se znaménkem. Příklad: 2,5F
- Double – Definuje 64bitovou plovoucí desetinnou čárku se znaménkem. Příklad: 23.4
- Boolean – Definuje booleovskou hodnotu. Zahrnuje: Pravda/nepravda
- Datetime – Definuje hodnotu data a času. Příklad: 1980-01-01T00:00.00.000+00:00
Mezi komplexní datové typy patří:
- Mapa-Mapa odkazuje na sadu párů klíč–hodnota. Příklad: [‘color’#’yellow’, ‘number’#3]
- Bag – Jedná se o sbírku sady n-tic a používá symbol ‚{}‘. Příklad: {(Henry, 32), (Kiti, 47)}
- N-tice – N-tice definuje uspořádanou sadu polí. Příklad : (Věk, 33)
Co jsou Apache Oozie a Apache ZooKeeper?
Odpověď: Apache Oozie je plánovač Hadoop, který má na starosti plánování a spojování úloh Hadoop dohromady jako jediné logické dílo.
Apache Zookeeper na druhé straně koordinuje s různými službami v distribuovaném prostředí. Šetří čas vývojářů tím, že jednoduše odhaluje jednoduché služby, jako je synchronizace, seskupování, údržba konfigurace a pojmenování. Apache Zookeeper také poskytuje běžnou podporu pro řazení do fronty a volbu vůdce.
Jaká je role Combineru, RecordReaderu a Partitioneru v operaci MapReduce?
Odpověď: Slučovač funguje jako mini redukce. Přijímá a zpracovává data z mapových úloh a poté předává výstup dat do fáze reduktoru.
RecordHeader komunikuje s InputSplit a převádí data na páry klíč-hodnota, aby je mapovač mohl vhodně číst.
Rozdělovač je odpovědný za rozhodování o počtu redukovaných úloh potřebných k sumarizaci dat a za potvrzení, jak jsou výstupy slučovače odesílány do reduktoru. Partitioner také řídí rozdělení klíčů mezi výstupy mapy.
Uveďte různé distribuce Hadoopu specifické pro dodavatele.
Odpověď: Různí dodavatelé, kteří rozšiřují možnosti Hadoop, zahrnují:
- Platforma IBM Open.
- Cloudera CDH Hadoop Distribuce
- Distribuce MapR Hadoop
- Amazon Elastic MapReduce
- Hortonworks Data Platform (HDP)
- Pivotal Big Data Suite
- Datastax Enterprise Analytics
- HDInsight od Microsoft Azure – Cloudová distribuce Hadoop.
Proč je HDFS odolný vůči chybám?
Odpověď: HDFS replikuje data na různých DataNode, takže je odolný vůči chybám. Ukládání dat do různých uzlů umožňuje načítání z jiných uzlů, když jeden režim selže.
Rozlišujte mezi federací a vysokou dostupností.
Odpověď: HDFS Federation nabízí odolnost proti chybám, která umožňuje nepřetržitý tok dat v jednom uzlu, když jiný selže. Na druhou stranu bude vysoká dostupnost vyžadovat dva samostatné počítače, které budou samostatně konfigurovat aktivní NameNode a sekundární NameNode na prvním a druhém počítači.
Federation může mít neomezený počet nesouvisejících NameNodes, zatímco ve vysoké dostupnosti jsou dostupné pouze dva související NameNode, aktivní a pohotovostní, které fungují nepřetržitě.
NameNodes ve federaci sdílí fond metadat, přičemž každý NameNode má svůj vyhrazený fond. V režimu High Availability se však aktivní NameNodes spouští každý jeden po druhém, zatímco pohotovostní NameNodes zůstávají nečinné a pouze příležitostně aktualizují svá metadata.
Jak zjistit stav bloků a zdraví souborového systému?
Odpověď: Ke kontrole stavu systému souborů HDFS používáte příkaz hdfs fsck / jak na úrovni uživatele root, tak na úrovni jednotlivého adresáře.
Používá se příkaz HDFS fsck:
hdfs fsck / -files --blocks –locations> dfs-fsck.log
Popis příkazu:
- -files: Vytiskne soubory, které kontrolujete.
- –locations: Při kontrole vytiskne umístění všech bloků.
Příkaz pro kontrolu stavu bloků:
hdfs fsck <path> -files -blocks
: Zahájí kontroly od cesty, kterou zde procházíte. - – bloky: Během kontroly vytiskne bloky souboru
Kdy používáte příkazy rmadmin-refreshNodes a dfsadmin-refreshNodes?
Odpověď: Tyto dva příkazy jsou užitečné při obnovování informací o uzlu buď během uvádění do provozu, nebo po dokončení uvádění uzlu do provozu.
Příkaz dfsadmin-refreshNodes spustí klienta HDFS a aktualizuje konfiguraci uzlu NameNode. Příkaz rmadmin-refreshNodes na druhé straně provádí administrativní úlohy ResourceManager.
Co je to kontrolní bod?
Odpověď: Checkpoint je operace, která sloučí poslední změny souborového systému s nejnovějším FSImage, takže soubory protokolu úprav zůstanou dostatečně malé na urychlení procesu spouštění NameNode. Kontrolní bod se vyskytuje v sekundárním NameNode.
Proč používáme HDFS pro aplikace s velkými datovými sadami?
Odpověď: HDFS poskytuje architekturu DataNode a NameNode, která implementuje distribuovaný systém souborů.
Tyto dvě architektury poskytují vysoce výkonný přístup k datům prostřednictvím vysoce škálovatelných clusterů Hadoop. Jeho NameNode ukládá metadata systému souborů do paměti RAM, což má za následek, že množství paměti omezuje počet souborů systému souborů HDFS.
Co dělá příkaz ‚jps‘?
Odpověď: Příkaz JPS (Java Virtual Machine Process Status) kontroluje, zda jsou spuštěni konkrétní démoni Hadoop, včetně NodeManager, DataNode, NameNode a ResourceManager, či nikoli. Tento příkaz je nutné spustit z kořenového adresáře a zkontrolovat provozní uzly v hostiteli.
Co je to „spekulativní poprava“ v Hadoopu?
Odpověď: Toto je proces, kdy hlavní uzel v Hadoopu místo opravy zjištěných pomalých úloh spouští jinou instanci stejné úlohy jako úloha zálohování (spekulativní úloha) na jiném uzlu. Spekulativní provádění šetří spoustu času, zejména v prostředí s intenzivní pracovní zátěží.
Vyjmenujte tři režimy, ve kterých může Hadoop běžet.
Odpověď: Mezi tři primární uzly, na kterých Hadoop běží, patří:
- Standalone Node je výchozí režim, který spouští služby Hadoop pomocí místního systému souborů a jediného procesu Java.
- Pseudodistribuovaný uzel spouští všechny služby Hadoop pomocí jediného nasazení Hadoop.
- Plně distribuovaný uzel spouští hlavní a podřízené služby Hadoop pomocí samostatných uzlů.
Co je UDF?
Odpověď: UDF (User Defined Functions) vám umožňuje kódovat vaše vlastní funkce, které můžete použít ke zpracování hodnot sloupců během dotazu Impala.
Co je DistCp?
Odpověď: DistCp nebo zkráceně Distributed Copy je užitečný nástroj pro velké mezi- nebo intra-clusterové kopírování dat. Pomocí MapReduce DistCp efektivně implementuje distribuovanou kopii velkého množství dat, kromě jiných úkolů, jako je zpracování chyb, obnova a hlášení.
Odpověď: Hive metastore je služba, která ukládá metadata Apache Hive pro tabulky Hive v relační databázi, jako je MySQL. Poskytuje rozhraní API služby metastore, které umožňuje centový přístup k metadatům.
Definujte RDD.
Odpověď: RDD, což je zkratka pro Resilient Distributed Datasets, je datová struktura Spark a neměnná distribuovaná kolekce vašich datových prvků, která počítá na různých uzlech clusteru.
Jak mohou být do YARN Jobs zahrnuty nativní knihovny?
Odpověď: Můžete to implementovat buď pomocí -Djava.library. cesta v příkazu nebo nastavením LD+LIBRARY_PATH v souboru .bashrc v následujícím formátu:
<property> <name>mapreduce.map.env</name> <value>LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/path/to/my/libs</value> </property>
Vysvětlete ‚WAL‘ v HBase.
Odpověď: Write Ahead Log (WAL) je protokol obnovy, který zaznamenává změny dat MemStore v HBase do souborového úložiště. WAL obnoví tato data, pokud dojde k selhání RegionalServeru nebo před vyprázdněním MemStore.
Je YARN náhradou za Hadoop MapReduce?
Odpověď: Ne, YARN není náhrada Hadoop MapReduce. Místo toho výkonná technologie nazvaná Hadoop 2.0 nebo MapReduce 2 podporuje MapReduce.
Jaký je rozdíl mezi ORDER BY a SORT BY v HIVE?
Odpověď: Zatímco oba příkazy načítají data v Hive seřazeným způsobem, výsledky z použití SORT BY mohou být seřazeny pouze částečně.
Navíc SORT BY vyžaduje reduktor pro řazení řádků. Tyto redukce potřebné pro konečný výstup mohou být také vícenásobné. V tomto případě může být finální výstup částečně objednán.
Na druhou stranu, ORDER BY vyžaduje pouze jeden reduktor pro celkovou objednávku na výstupu. Můžete také použít klíčové slovo LIMIT, které zkracuje celkovou dobu třídění.
Jaký je rozdíl mezi Sparkem a Hadoopem?
Odpověď: Zatímco Hadoop i Spark jsou frameworky pro distribuované zpracování, jejich klíčovým rozdílem je jejich zpracování. Kde je Hadoop efektivní pro dávkové zpracování, Spark je efektivní pro zpracování dat v reálném čase.
Hadoop navíc čte a zapisuje soubory do HDFS, zatímco Spark používá koncept Resilient Distributed Dataset ke zpracování dat v RAM.
Na základě jejich latence je Hadoop výpočetní rámec s vysokou latencí bez interaktivního režimu pro zpracování dat, zatímco Spark je výpočetní rámec s nízkou latencí, který zpracovává data interaktivně.
Porovnejte Sqoop a Flume.
Odpověď: Sqoop a Flume jsou nástroje Hadoop, které shromažďují data shromážděná z různých zdrojů a načítají data do HDFS.
- Sqoop (SQL-to-Hadoop) extrahuje strukturovaná data z databází, včetně Teradata, MySQL, Oracle atd., zatímco Flume je užitečný pro extrahování nestrukturovaných dat z databázových zdrojů a jejich načítání do HDFS.
- Pokud jde o řízené události, Flume je řízen událostmi, zatímco Sqoop není řízen událostmi.
- Sqoop používá architekturu založenou na konektorech, kde konektory vědí, jak se připojit k jinému zdroji dat. Flume používá architekturu založenou na agentech, přičemž zapsaný kód je agentem odpovědným za načítání dat.
- Díky distribuované povaze Flume může snadno shromažďovat a agregovat data. Sqoop je užitečný pro paralelní přenos dat, což má za následek, že výstup je ve více souborech.
Vysvětlete BloomMapFile.
Odpověď: BloomMapFile je třída rozšiřující třídu MapFile a používá dynamické filtry květů, které poskytují rychlý test členství pro klíče.
Uveďte rozdíl mezi HiveQL a PigLatin.
Odpověď: Zatímco HiveQL je deklarativní jazyk podobný SQL, PigLatin je vysokoúrovňový procedurální jazyk toku dat.
Co je čištění dat?
Odpověď: Čištění dat je zásadní proces, jak se zbavit nebo opravit identifikované chyby dat, které zahrnují nesprávná, neúplná, poškozená, duplicitní a nesprávně formátovaná data v datové sadě.
Tento proces má za cíl zlepšit kvalitu dat a poskytovat přesnější, konzistentnější a spolehlivější informace nezbytné pro efektivní rozhodování v rámci organizace.
Závěr 💃
Se současným nárůstem pracovních příležitostí v oblasti Big data a Hadoop možná budete chtít zvýšit své šance na to, abyste se dostali dovnitř. Otázky a odpovědi na pohovor v Hadoop v tomto článku vám pomohou zvládnout nadcházející pohovor.
Dále se můžete podívat na dobré zdroje, abyste se naučili Big Data a Hadoop.
Hodně štěstí! 👍