
Google JAX nebo Just After Execution je rámec vyvinutý společností Google pro urychlení úloh strojového učení.
Můžete to považovat za knihovnu pro Python, která pomáhá s rychlejším prováděním úloh, vědeckými výpočty, transformacemi funkcí, hlubokým učením, neuronovými sítěmi a mnohem více.
Table of Contents
O Google JAX
Nejzákladnějším výpočetním balíčkem v Pythonu je balíček NumPy, který má všechny funkce, jako jsou agregace, vektorové operace, lineární algebra, manipulace s n-rozměrnými poli a maticemi a mnoho dalších pokročilých funkcí.
Co kdybychom mohli dále urychlit výpočty prováděné pomocí NumPy – zejména u velkých datových sad?
Máme něco, co by mohlo fungovat stejně dobře na různých typech procesorů, jako je GPU nebo TPU, bez jakýchkoli změn kódu?
Co kdyby systém mohl provádět transformace složitelných funkcí automaticky a efektivněji?
Google JAX je knihovna (nebo framework, jak říká Wikipedie), která dělá právě to a možná ještě mnohem víc. Byl vytvořen za účelem optimalizace výkonu a efektivního provádění úloh strojového učení (ML) a hlubokého učení. Google JAX poskytuje následující transformační funkce, které jej odlišují od ostatních knihoven ML a pomáhají při pokročilých vědeckých výpočtech pro hluboké učení a neuronové sítě:
- Automatická diferenciace
- Automatická vektorizace
- Automatická paralelizace
- Just-in-time (JIT) kompilace
Jedinečné funkce Google JAX
Všechny transformace využívají XLA (Accelerated Linear Algebra) pro vyšší výkon a optimalizaci paměti. XLA je doménově specifický optimalizační kompilátor, který provádí lineární algebru a zrychluje modely TensorFlow. Použití XLA nad kódem Pythonu nevyžaduje žádné významné změny kódu!
Podívejme se podrobně na každou z těchto funkcí.
Funkce Google JAX
Google JAX přichází s důležitými skládacími transformačními funkcemi pro zlepšení výkonu a efektivnější provádění úkolů hlubokého učení. Například automatická derivace pro získání gradientu funkce a nalezení derivací libovolného řádu. Podobně automatická paralelizace a JIT pro paralelní provádění více úloh. Tyto transformace jsou klíčové pro aplikace, jako je robotika, hraní her a dokonce i výzkum.
Složitelná transformační funkce je čistá funkce, která transformuje sadu dat do jiné formy. Jsou nazývány komposovatelné, protože jsou samostatné (tj. tyto funkce nemají žádnou závislost se zbytkem programu) a jsou bezstavové (tj. stejný vstup bude mít vždy stejný výstup).
Y(x) = T: (f(x))
Ve výše uvedené rovnici je f(x) původní funkcí, na kterou je aplikována transformace. Y(x) je výsledná funkce po aplikaci transformace.
Pokud máte například funkci s názvem ‚total_bill_amt‘ a chcete výsledek jako transformaci funkce, můžete jednoduše použít požadovanou transformaci, řekněme gradient (grad):
grad_total_bill = grad(total_bill_amt)
Transformací numerických funkcí pomocí funkcí jako grad() můžeme snadno získat jejich deriváty vyššího řádu, které můžeme široce využít v optimalizačních algoritmech hlubokého učení, jako je gradientní sestup, čímž se algoritmy zrychlí a zefektivní. Podobně pomocí jit() můžeme kompilovat programy Pythonu just-in-time (líně).
#1. Automatická diferenciace
Python používá funkci autograd k automatickému rozlišení NumPy a nativního kódu Pythonu. JAX používá upravenou verzi autogradu (tj. grad) a kombinuje XLA (Accelerated Linear Algebra) k provádění automatické diferenciace a hledání derivátů libovolného řádu pro GPU (Graphic Processing Units) a TPU (Tensor Processing Units).]
Rychlá poznámka k TPU, GPU a CPU: CPU nebo centrální procesorová jednotka řídí všechny operace v počítači. GPU je přídavný procesor, který zvyšuje výpočetní výkon a provozuje špičkové operace. TPU je výkonná jednotka speciálně vyvinutá pro komplexní a těžké pracovní zátěže, jako je AI a algoritmy hlubokého učení.
Stejně jako funkce autograd, která může rozlišovat pomocí smyček, rekurzí, větví atd., používá JAX funkci grad() pro gradienty v obráceném režimu (zpětné šíření). Také můžeme rozlišit funkci na jakoukoli objednávku pomocí grad:
grad(grad(grad(sin θ))) (1.0)
Automatická diferenciace vyššího řádu
Jak jsme již zmínili, grad je docela užitečný při hledání parciálních derivací funkce. Můžeme použít parciální derivaci k výpočtu gradientu sestupu nákladové funkce s ohledem na parametry neuronové sítě v hlubokém učení, abychom minimalizovali ztráty.
Výpočet parciální derivace
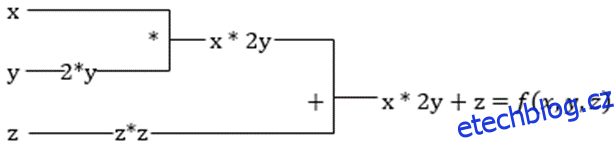
Předpokládejme, že funkce má více proměnných x, y a z. Hledání derivace jedné proměnné udržováním konstantních ostatních proměnných se nazývá parciální derivace. Předpokládejme, že máme funkci,
f(x,y,z) = x + 2y + z2
Příklad pro zobrazení parciální derivace
Parciální derivace x bude ∂f/∂x, což nám říká, jak se funkce mění pro proměnnou, když jsou ostatní konstantní. Pokud to provedeme ručně, musíme napsat program pro diferenciaci, aplikovat jej na každou proměnnou a pak vypočítat sestup gradientu. To by se stalo složitou a časově náročnou záležitostí pro více proměnných.
Automatická derivace rozloží funkci na sadu elementárních operací, jako je +, -, *, / nebo sin, cos, tan, exp atd., a poté použije pravidlo řetězce pro výpočet derivace. Můžeme to udělat v režimu vpřed i vzad.
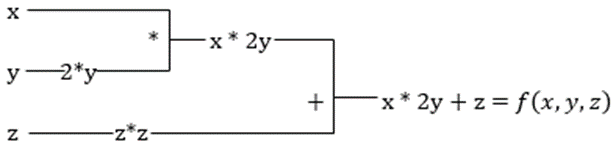
Tohle není ono! Všechny tyto výpočty probíhají tak rychle (no, přemýšlejte o milionech výpočtů podobných výše uvedeným a o čase, který to může trvat!). XLA se stará o rychlost a výkon.
#2. Zrychlená lineární algebra
Vezměme předchozí rovnici. Bez XLA bude výpočet trvat tři (nebo více) jader, kde každé jádro bude provádět menší úlohu. Například,
Jádro k1 –> x * 2y (násobení)
k2 –> x * 2y + z (sčítání)
k3 –> Snížení
Pokud stejný úkol provádí XLA, jediné jádro se postará o všechny mezioperační operace jejich sloučením. Mezivýsledky základních operací jsou streamovány místo toho, aby byly ukládány do paměti, čímž se šetří paměť a zvyšuje se rychlost.
#3. Kompilace just-in-time
JAX interně používá kompilátor XLA ke zvýšení rychlosti provádění. XLA může zvýšit rychlost CPU, GPU a TPU. To vše je možné pomocí provádění kódu JIT. Chcete-li to použít, můžeme použít jit přes import:
from jax import jit def my_function(x): …………some lines of code my_function_jit = jit(my_function)
Dalším způsobem je zdobení jit přes definici funkce:
@jit def my_function(x): …………some lines of code
Tento kód je mnohem rychlejší, protože transformace vrátí zkompilovanou verzi kódu volajícímu namísto použití interpretru Pythonu. To je zvláště užitečné pro vektorové vstupy, jako jsou pole a matice.
Totéž platí pro všechny existující funkce pythonu. Například funkce z balíčku NumPy. V tomto případě bychom měli importovat jax.numpy jako jnp spíše než NumPy:
import jax import jax.numpy as jnp x = jnp.array([[1,2,3,4], [5,6,7,8]])
Jakmile to uděláte, základní objekt pole JAX s názvem DeviceArray nahradí standardní pole NumPy. DeviceArray je líný – hodnoty jsou uchovávány v akcelerátoru, dokud nejsou potřeba. To také znamená, že program JAX nečeká, až se výsledky vrátí volajícímu (Python) programu, takže následuje asynchronní odeslání.
#4. Automatická vektorizace (vmap)
V typickém světě strojového učení máme datové sady s milionem nebo více datovými body. S největší pravděpodobností bychom provedli nějaké výpočty nebo manipulace s každým nebo většinou těchto datových bodů – což je velmi časově a paměťově náročný úkol! Pokud například chcete najít druhou mocninu každého z datových bodů v datové sadě, první věc, která vás napadne, je vytvořit smyčku a brát čtverec jeden po druhém – argh!
Pokud vytvoříme tyto body jako vektory, mohli bychom udělat všechny čtverce najednou provedením vektorových nebo maticových manipulací s datovými body pomocí našeho oblíbeného NumPy. A pokud by to váš program uměl automaticky – můžete požádat o něco víc? To je přesně to, co JAX dělá! Dokáže automaticky vektorizovat všechny vaše datové body, takže s nimi můžete snadno provádět jakékoli operace – vaše algoritmy jsou tak mnohem rychlejší a efektivnější.
JAX používá pro automatickou vektorizaci funkci vmap. Zvažte následující pole:
x = jnp.array([1,2,3,4,5,6,7,8,9,10]) y = jnp.square(x)
Provedením výše uvedeného se metoda čtverce spustí pro každý bod v poli. Ale pokud uděláte následující:
vmap(jnp.square(x))
Čtverec metody se provede pouze jednou, protože datové body jsou nyní před provedením funkce automaticky vektorizovány pomocí metody vmap a smyčkování je posunuto dolů na základní úroveň operace – výsledkem je násobení matice spíše než skalární násobení, což poskytuje lepší výkon. .
#5. SPMD programování (pmap)
SPMD – neboli Single Program Multiple Data programování je zásadní v kontextu hlubokého učení – často byste použili stejné funkce na různé sady dat umístěných na více GPU nebo TPU. JAX má funkci s názvem pump, která umožňuje paralelní programování na více GPU nebo libovolném akcelerátoru. Stejně jako JIT budou programy používající pmap kompilovány pomocí XLA a spouštěny současně napříč systémy. Tato automatická paralelizace funguje pro dopředné i zpětné výpočty.
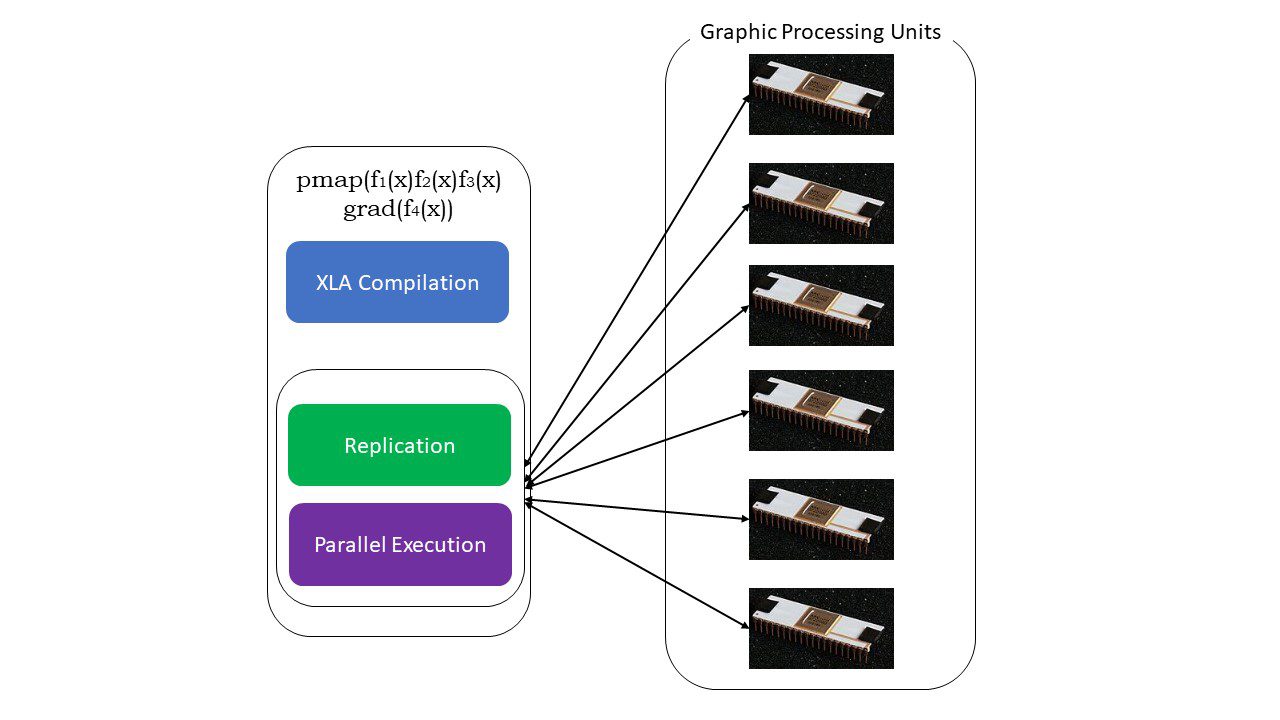 Jak funguje pmap
Jak funguje pmap
Můžeme také použít více transformací najednou v libovolném pořadí na jakoukoli funkci jako:
pmap(vmap(jit(grad (f(x)))))
Vícenásobné skládací transformace
Omezení Google JAX
Vývojáři Google JAX se dobře zamysleli nad urychlením algoritmů hlubokého učení a zároveň představili všechny tyto úžasné transformace. Vědecké výpočetní funkce a balíčky jsou na úrovni NumPy, takže se nemusíte starat o křivku učení. JAX má však následující omezení:
- Google JAX je stále v raných fázích vývoje, a přestože jeho hlavním účelem je optimalizace výkonu, neposkytuje příliš výhod pro výpočetní procesory. Zdá se, že NumPy funguje lépe a použití JAX může pouze zvýšit režii.
- JAX je stále ve fázi výzkumu nebo v rané fázi a potřebuje více doladění, aby dosáhl infrastrukturních standardů rámců, jako je TensorFlow, které jsou zavedenější a mají více předdefinovaných modelů, open source projektů a výukových materiálů.
- Od této chvíle JAX nepodporuje operační systém Windows – k jeho fungování byste potřebovali virtuální stroj.
- JAX funguje pouze na čistých funkcích – těch, které nemají žádné vedlejší účinky. Pro funkce s vedlejšími účinky nemusí být JAX dobrou volbou.
Jak nainstalovat JAX ve vašem prostředí Pythonu
Pokud máte na svém systému nastaven python a chcete spustit JAX na místním počítači (CPU), použijte následující příkazy:
pip install --upgrade pip pip install --upgrade "jax[cpu]"
Pokud chcete spustit Google JAX na GPU nebo TPU, postupujte podle pokynů uvedených na GitHub JAX strana. Chcete-li nastavit Python, navštivte stránku python oficiální stahování strana.
Závěr
Google JAX je skvělý pro psaní efektivních algoritmů hlubokého učení, robotiky a výzkumu. Navzdory omezením je široce používán s jinými frameworky, jako je Haiku, Flax a mnoho dalších. Budete schopni ocenit, co JAX dělá, když spouštíte programy, a uvidíte časové rozdíly při provádění kódu s a bez JAX. Můžete začít čtením oficiální dokumentace Google JAXkterá je poměrně obsáhlá.