

Amazon Glue získává na popularitě, protože mnoho společností začalo využívat služby integrace spravovaných dat.
ETL je proces, který přenáší data ze zdrojové databáze do datového skladu. ETL je složitý a obtížně implementovatelný pro všechna podniková data kvůli jeho složitosti. Amazon představil AWS Glue k vyřešení tohoto problému.
Vývojáři a datoví inženýři ETL používají Glue k vytváření, sledování a spouštění pracovních postupů ETL.
Table of Contents
Co je lepidlo AWS?
AWS Glue, služba integrace dat bez serveru, usnadňuje vyhledávání, přípravu, přesun a integraci dat z více zdrojů. To je užitečné pro strojové učení (ML) a analýzu.
Dramaticky snižuje čas potřebný k přípravě dat pro analýzu. Automaticky vyhledá a vypíše data, generuje kód Scala nebo Python pro přenos dat ze zdroje a načte a transformuje úlohu podle časovaných událostí.
To umožňuje flexibilní plánování a vytváří prostředí Apache Spark, které lze škálovat pro cílené načítání dat. AWS Glue navíc poskytuje komplexní monitorování a úpravy datového toku. AWS Glue je služba bez serveru, která zjednodušuje složité operace vývoje aplikací.
Umožňuje rychlou integraci více platných dat. Také se rychle rozpadá a autorizuje data.
K čemu se používá lepidlo AWS?
Je důležité znát nejlepší místa pro použití Amazon Glue. Toto je jen několik příkladů použití lepidla AWS, které byste měli zvážit.
- Glue je nástroj, který vám umožňuje spouštět dotazy bez serveru na datových jezerech Amazon S3. Amazon Glue je skvělý nástroj, který vám pomůže začít. Zpřístupňuje všechna vaše data na jednom rozhraní a umožňuje vám je analyzovat, aniž byste je museli přesouvat.
- Amazon Glue lze použít k pochopení vašich datových aktiv. Amazon Glue vám usnadňuje vyhledávání různých souborů dat AWS pomocí katalogu dat. Můžete také ukládat data napříč více službami AWS pomocí katalogu dat a přitom mít stále konzistentní zobrazení.
- Lepidlo může být užitečné při vytváření pracovních postupů ETL řízených událostmi. Své ETL operace můžete provádět z Amazon S3 voláním úkolů Glue ETL prostřednictvím služby AWS Lambda.
- AWS Glue lze také použít k čištění, ověřování, formátování a organizování dat pro uložení v datovém jezeře nebo skladu.
Jaké jsou součásti lepidla AWS?
Níže jsou uvedeny hlavní složky lepidla AWS:
- Katalog dat: Tento katalog dat obsahuje metadata a datovou strukturu.
- Databáze: Toto je klíč k přístupu a vytváření databáze pro zdroje a cíle.
- Tabulka: Vytvořte jednu nebo několik tabulek v databázi, které jsou použitelné pro cíl i zdroj.
- Prolézací modul a klasifikátor: Prolézací modul získává data ze zdroje pomocí vestavěných nebo vlastních klasifikací. Vytváří/používá předdefinované tabulky metadat v datovém katalogu.
- Úkol: Toto je úkolem obchodní logiky provádět úkol ETL. Tato obchodní logika je napsána interně Apache Spark pomocí jazyků python a scala.
- Spouštěč: Spouštěč ETL je zařízení, které spouští provádění úlohy ETL na vyžádání nebo v určitou dobu.
- Koncový bod pro vývoj: Toto vytváří prostředí, ve kterém se testuje, vyvíjí a ladí skript úlohy ETL.
Výhody lepidla AWS
Toto jsou výhody používání na vašem pracovišti nebo v rámci organizace.
- AWS Glue skenuje všechna data dostupná pomocí prohledávače.
- Finální zpracovaná data mohou být uložena na mnoha místech (Amazon RDS a Amazon Redshift, Amazon S3 atd.
- Jedná se o cloudovou službu. Není třeba utrácet peníze za místní infrastrukturu.
- Protože se jedná o ETL bez serveru, je to cenově výhodná volba.
- Je to rychlé. Okamžitě vám poskytne Python/Scala ETL kód.
Nejlepší vlastnosti lepidla AWS?
Amazon Glue má všechny funkce, které potřebujete k integraci dat, abyste mohli získat lepší přehled a využít své znalosti k novým pokrokům během několika minut místo měsíců. Zde jsou některé funkce, které byste měli znát.
- Rozhraní Drag and Drop: Editor úloh přetažením umožňuje vytvořit proces ETL. AWS Glue okamžitě vytvoří kód potřebný k extrahování, převodu a nahrání dat.
- Automatické zjišťování schématu: Chcete-li vytvořit prolézací moduly, které se připojují k různým zdrojům dat, můžete použít službu Glue. Organizuje data a získává relevantní informace. Tato data pak lze použít k monitorování ETL procesů pomocí ETL úloh.
- Plánování úloh: Lepidlo lze použít na vyžádání nebo podle naplánovaného plánu. Plánovač lze použít k vytvoření komplexních ETL kanálů, které vytvářejí závislosti mezi úkoly.
- Generování kódu: Glue Elastic Views vám umožňuje snadno vytvářet materializované pohledy, které kombinují a replikují data z různých zdrojů dat, aniž byste museli psát jakýkoli proprietární kód.
- Vestavěné strojové učení: Glue přichází s vestavěnou funkcí strojového učení s názvem „FindMatches“. Deduplikuje záznamy, které nejsou navzájem dokonalými kopiemi.
- Vývojářské koncové body: Pokud chcete aktivně vyvíjet svůj ETL kód, Glue poskytuje vývojářské koncové body, které vám umožňují upravovat, ladit a testovat kód, který vytváří.
- Glue DataBrew: Jedná se o nástroj pro přípravu dat, který mohou využít datoví analytici a datoví vědci, aby jim pomohli vyčistit a normalizovat data. Využívá aktivní a vizuální rozhraní Glue DataBrew.
Jak funguje stanovení cen lepidla AWS?
AWS Glue účtuje hodinový poplatek, který je účtován za sekundu prohledávači (objevování dat) a ETL úlohám (zpracování a načítání dat). Za přístup a uložení metadat v katalogu AWS Glue Data Catalog je účtován jednoduchý měsíční poplatek.
Amazon Glue začíná na 0,44 dolaru. Můžete si vybrat ze čtyř plánů:
- Úlohy ETL, vývojové koncové body a další úlohy ETL jsou k dispozici za 0,44 $
- Interaktivní relace Crawlers jsou k dispozici za 0,44 USD
- Úlohy DataBrew začínají na 0,48 $
- Měsíční úložiště a požadavky na katalog dat stojí 1,00 USD
AWS nenabízí bezplatný plán lepidla. Každá hodina bude stát 0,44 USD za DPU. V průměru by vás to stálo 21 $ za den. Ceny se mohou lišit v závislosti na tom, kde bydlíte.
Kroky k nastavení lepidla AWS
Katalog dat lze použít k rychlému nalezení a prohledání více datových sad AWS, aniž byste museli data přesouvat. Poté, co byla data katalogizována, jsou okamžitě k dispozici pro dotazování a vyhledávání pomocí Amazon Athena a Amazon EMR.
 Ref: https://aws.amazon.com/glue/
Ref: https://aws.amazon.com/glue/
- Amazon Redshift, Amazon S3, Amazon RDS a databáze na Amazon EC2 – Objevte svá data, ukládejte metadata a použijte AWS Glue Data Catalog k jejich objevení
- AWS Glue Data Catalog – Spravujte data pomocí datového katalogu, který funguje jako centrální úložiště metadat
- AWS Glue ETL – Čtení a zápis metadat do vašeho datového katalogu
- Amazon Athena a Amazon Redshift, Amazon EMR, Amazon ETL – Získejte katalog dat pro ETL, analytiku a další.
Jak nastavit lepidlo AWS?
Nejprve se přihlaste do konzoly pro správu AWS a otevřete konzolu IAM. Klikněte na Vytvořit roli. Poté pro typ role vyhledejte Lepidlo a vyberte Oprávnění.
Vybírám AWSGlueServiceRole pro obecná oprávnění AWS Glue Studio a AWS Glue a zásadu AmazonS3FullAccess spravovanou AWS pro přístup ke zdrojům Amazon S3.
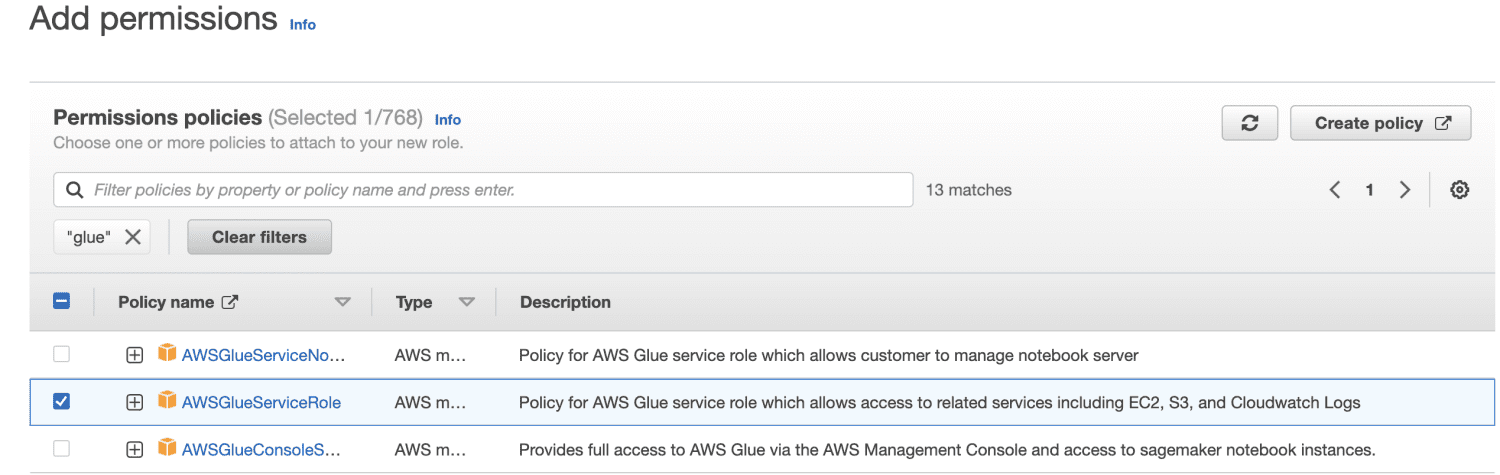
Zadejte název role.
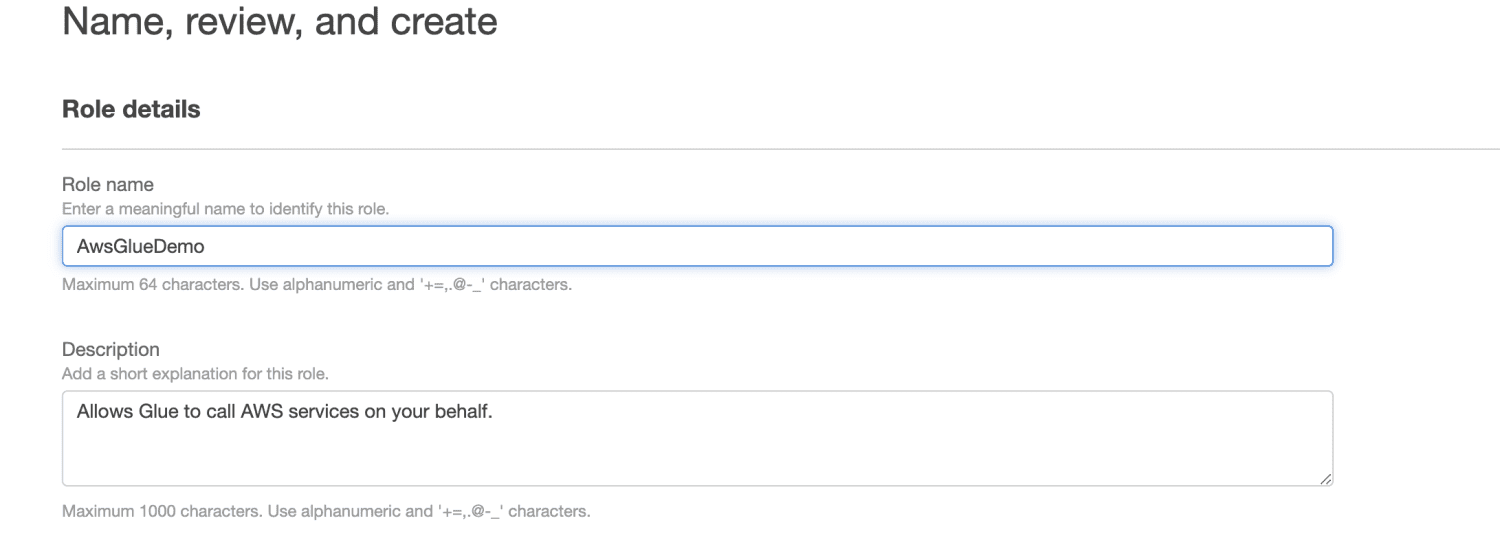
Klikněte na Vytvořit roli.
Vytvořte kbelík Amazon S3.
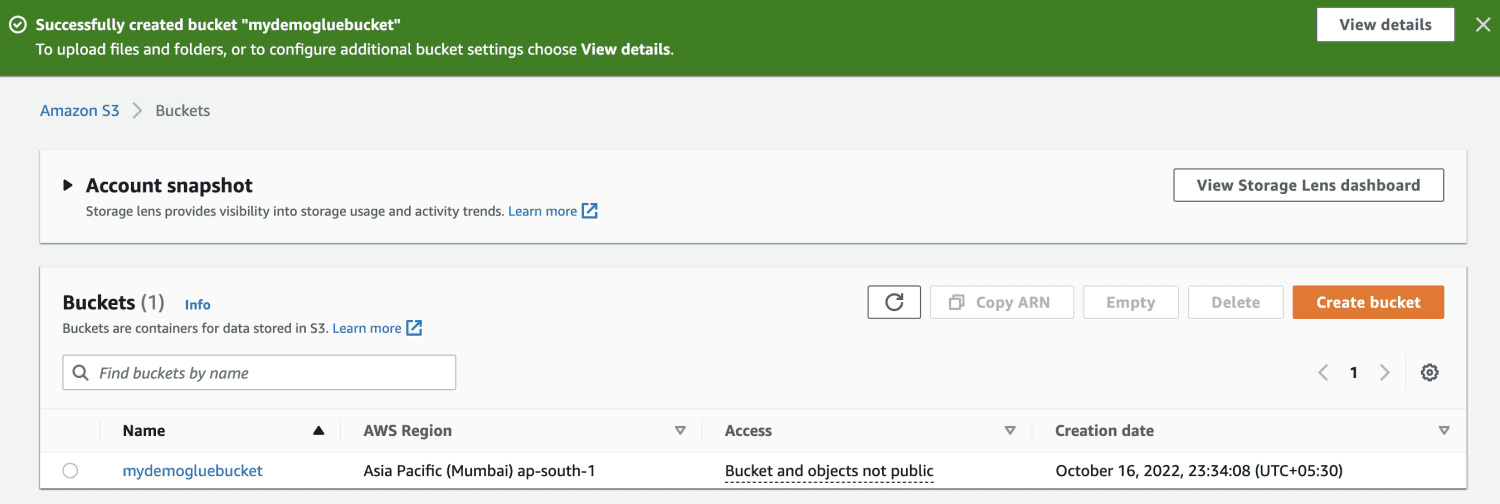
Vytvořte složku uvnitř kbelíku S3.
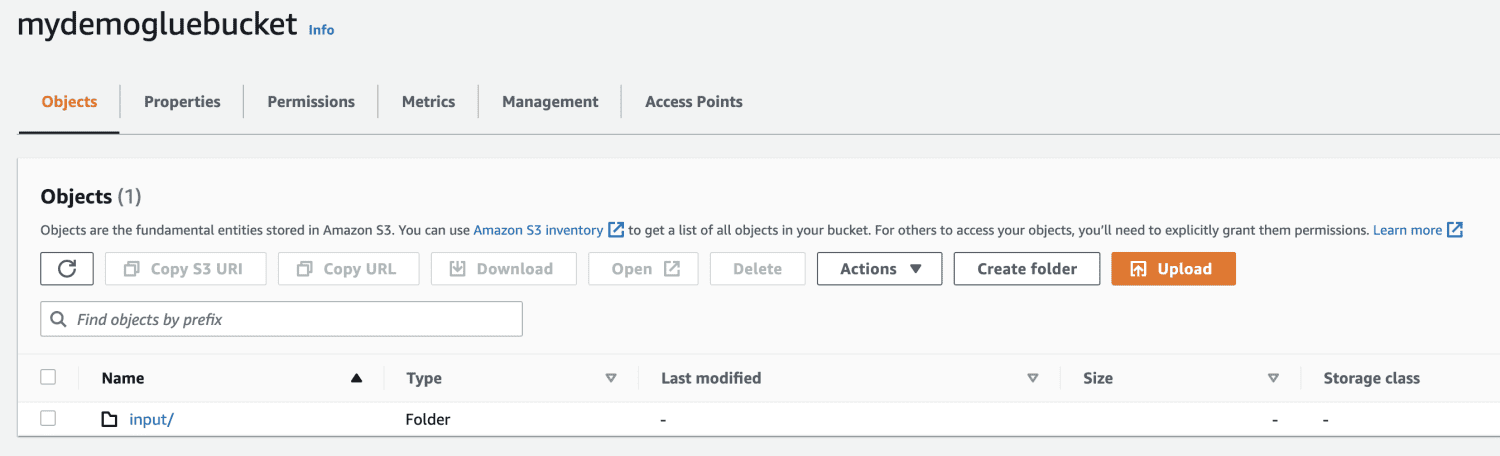
Vyberte soubor, který chcete nahrát.
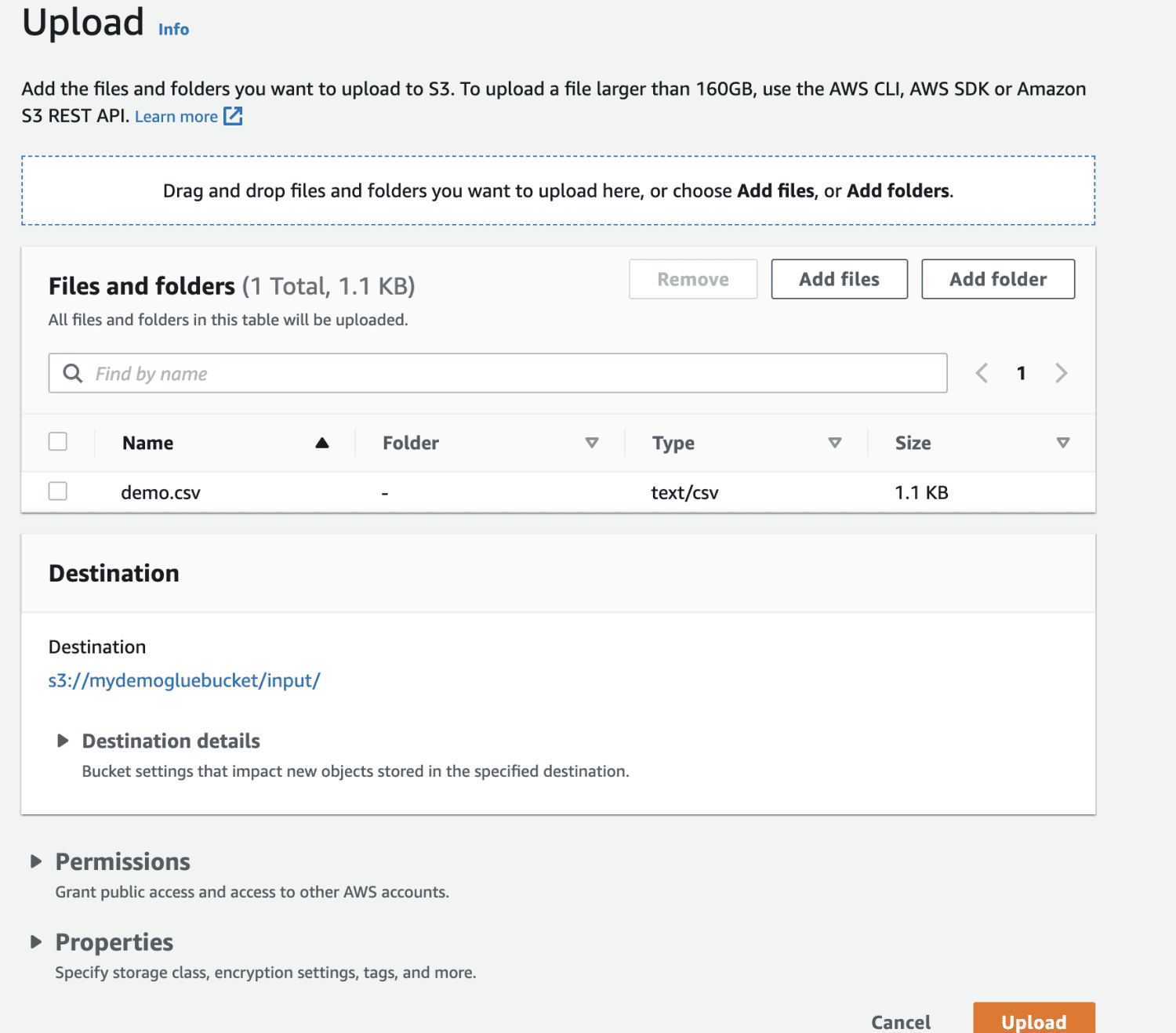
Nakonec nahrajte soubor do kbelíku.
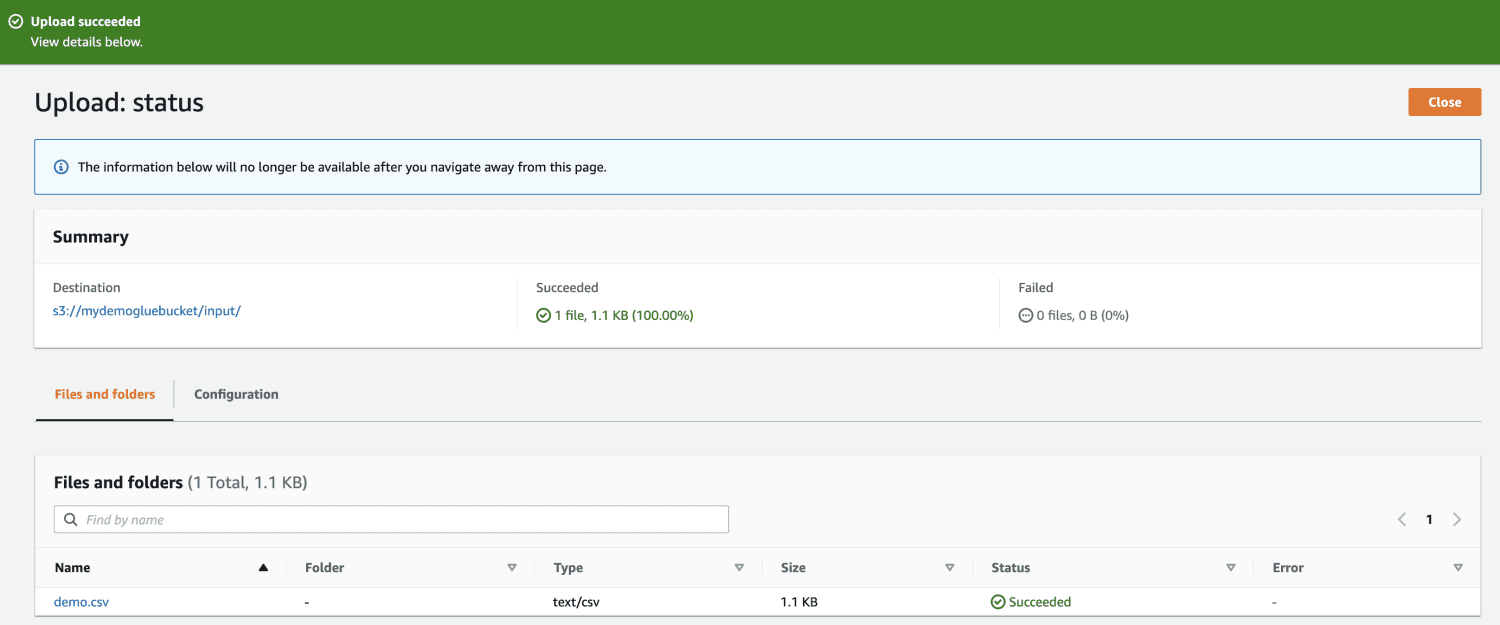
Dále otevřete AWS Glue z konzoly pro správu AWS a vytvořte databázi.
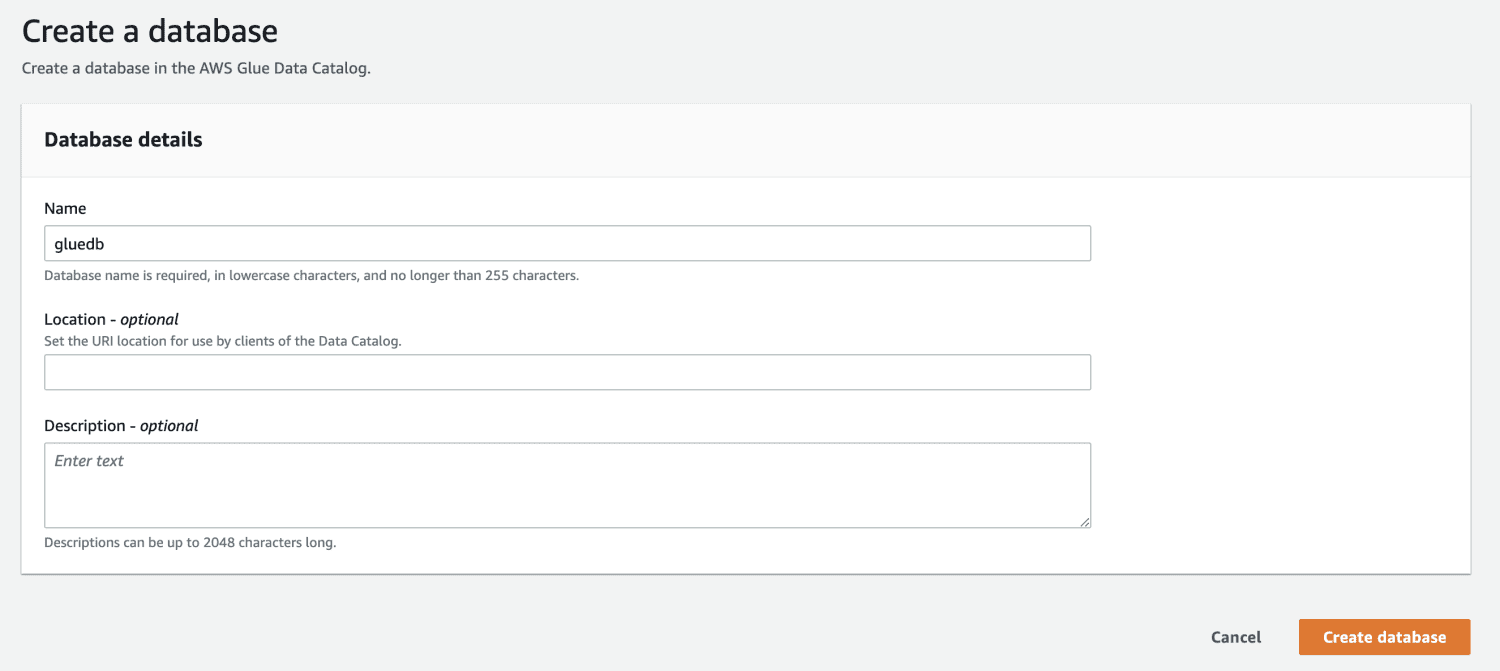
Nyní, když máte databázi v AWS Glue, vytvořte prolézací modul.
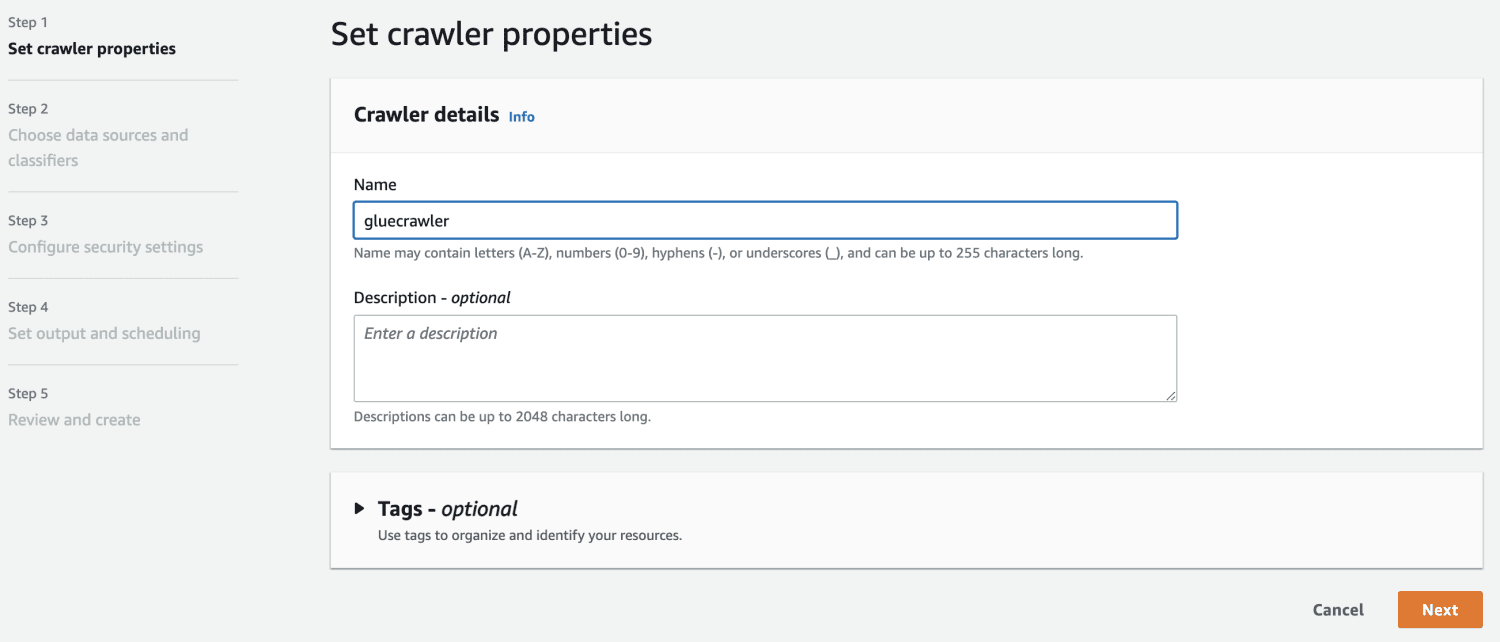
Ve zdroji dat vyberte segment S3, který jste vytvořili.
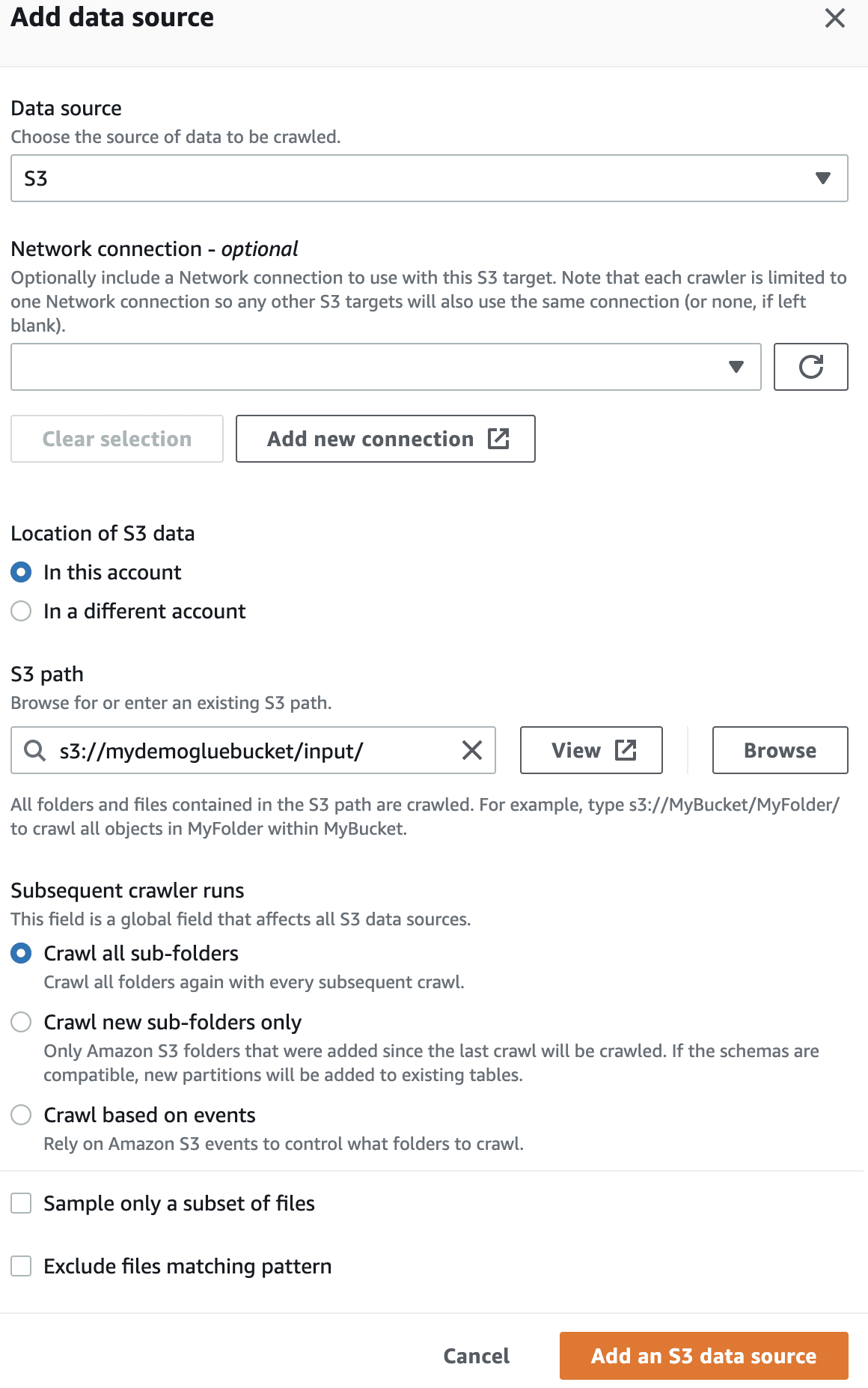
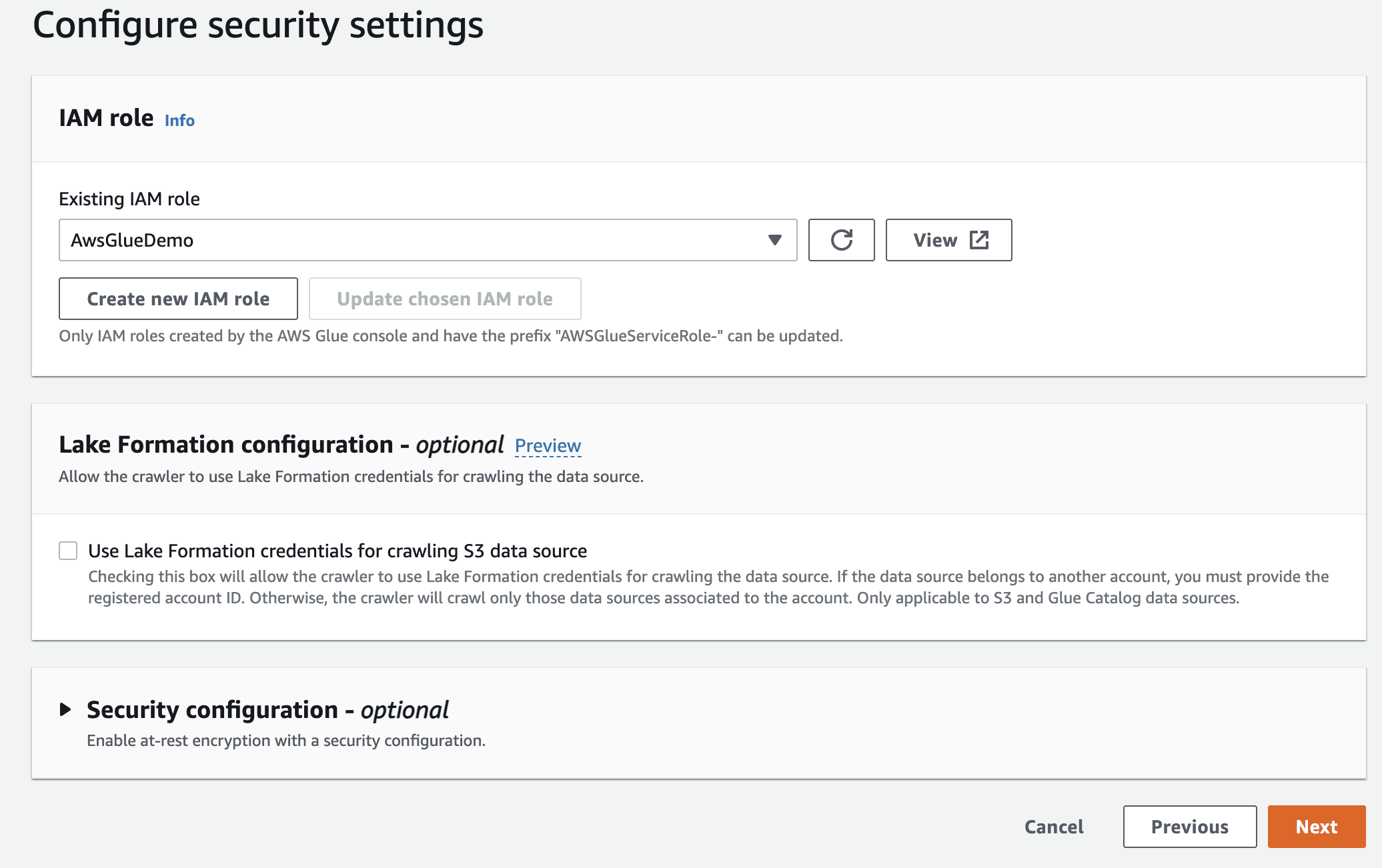
Dále vyberte roli IaM pro AWS Glue, kterou jste vytvořili na začátku.
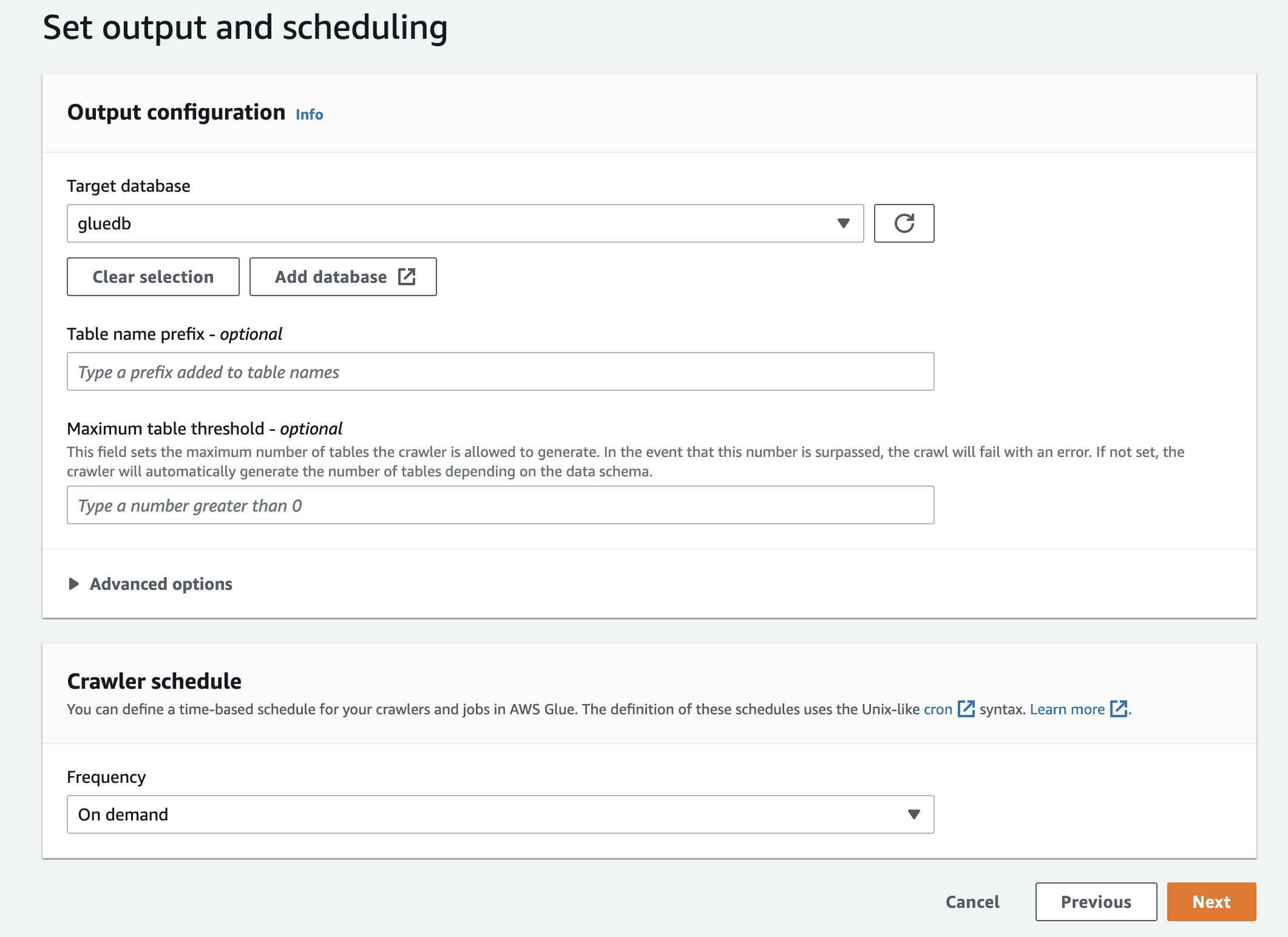
Nakonec ve výstupu vyberte lepidlo, které jste vytvořili.
Zkontrolujte všechna nastavení a vytvořte prolézací modul.
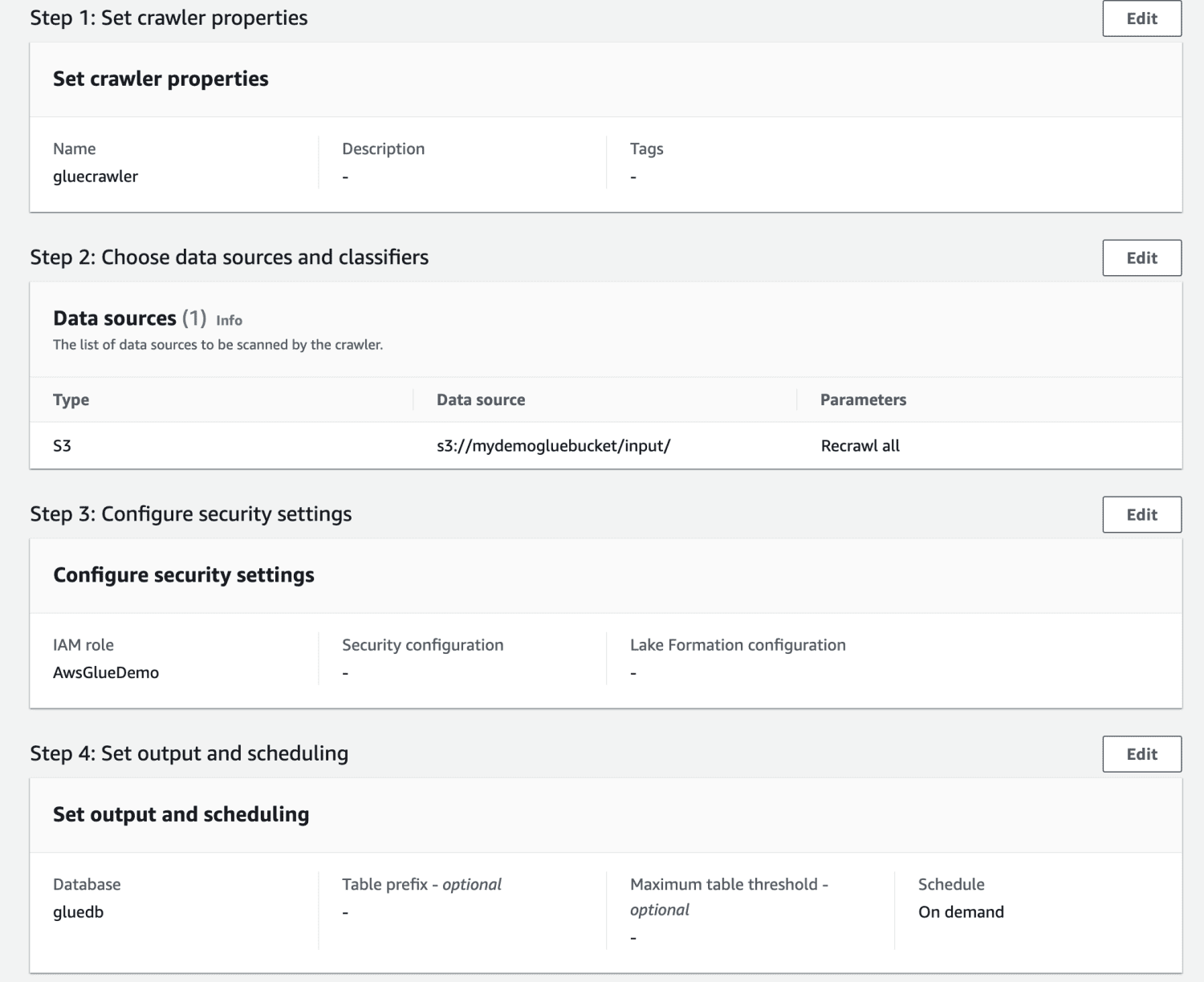
Jakmile je prohledávač vytvořen, vyberte jej a klikněte na Spustit. Po nějaké době budete mít stav připravený.
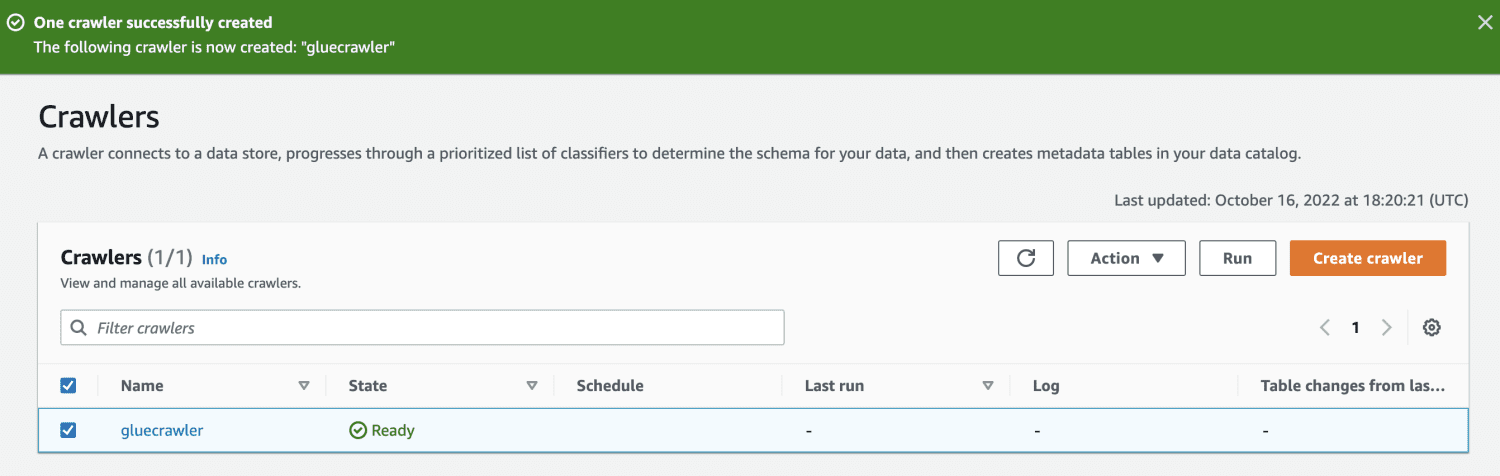
Spuštěním prolézacího modulu získá databáze tabulku se všemi daty ze souboru CSV.
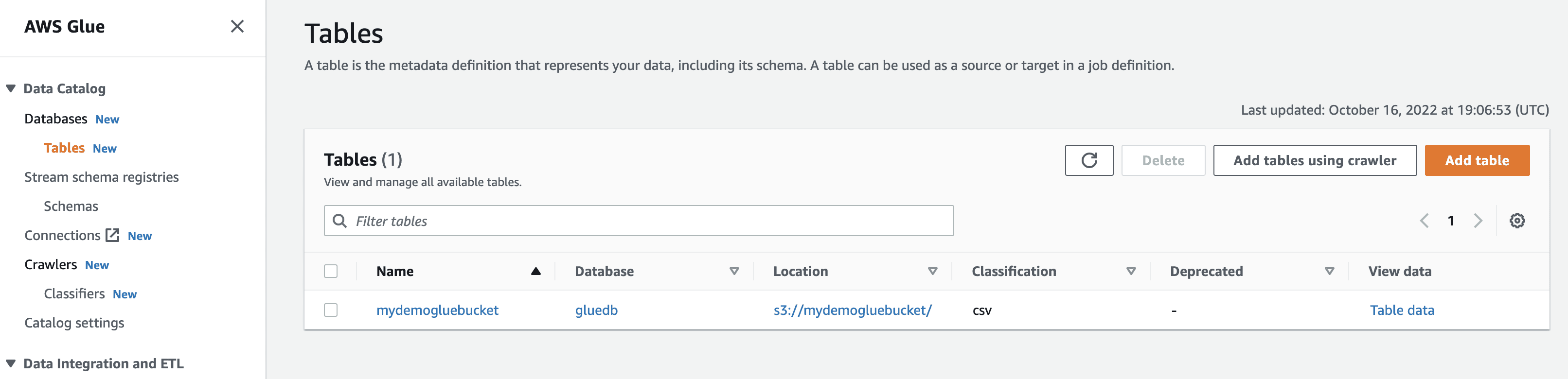
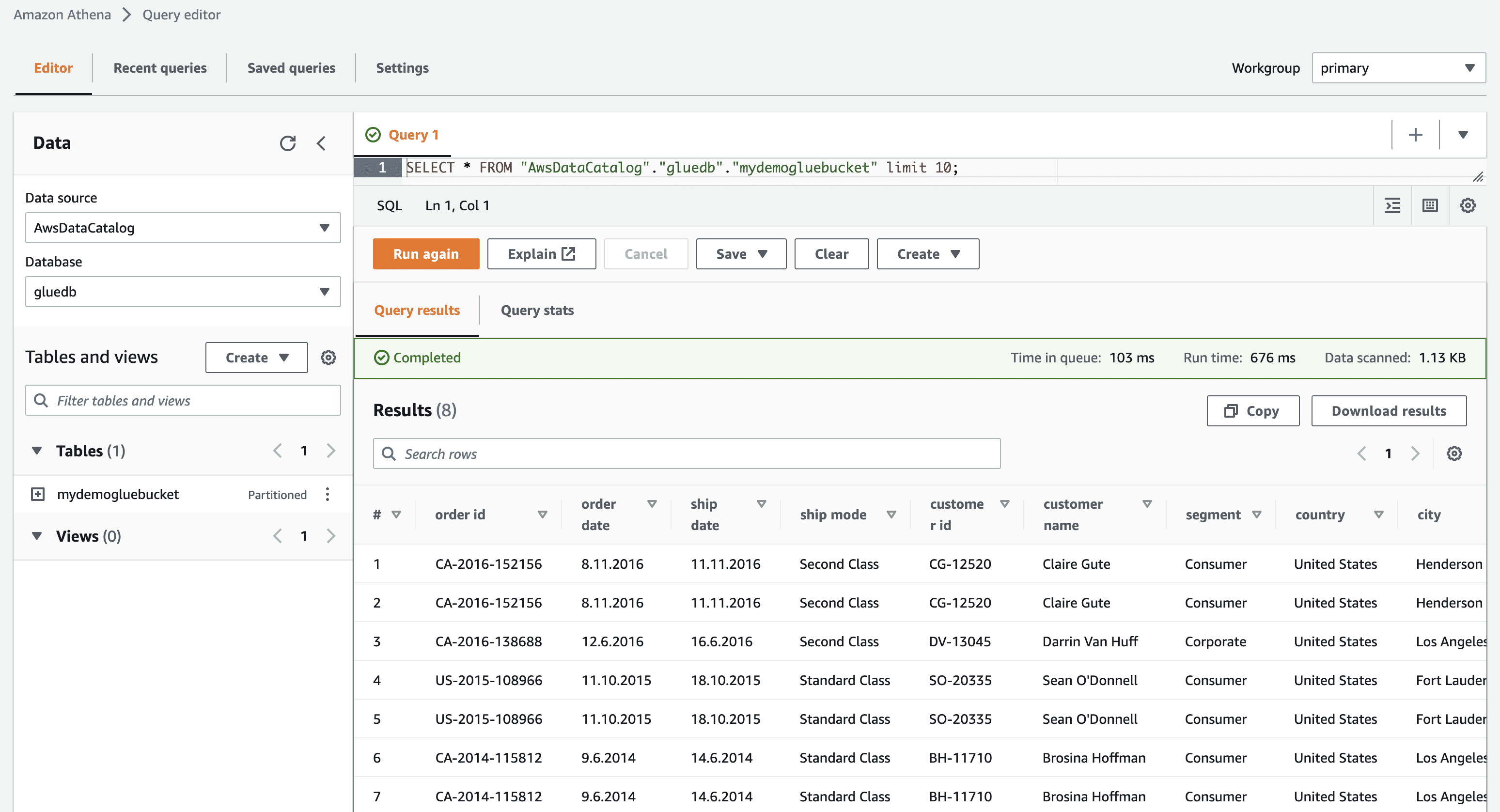
Když kliknete na zobrazit data, budete přesměrováni na Amazon Athena (editor dotazů). Když spustíte dotaz, můžete vidět data tabulky.
Nyní můžete tento prolézací modul AWS Glue úspěšně používat v jakékoli úloze ETL.
Co je AWS Glue Databrew?
AWS Glue DataBrew umožňuje uživatelům normalizovat a čistit data bez psaní jakéhokoli kódu. DataBrew dokáže zkrátit čas potřebný k přípravě dat pro strojové učení a analytiku až o 80 procent ve srovnání s vlastní přípravou dat.
Existuje více než 250 předem připravených transformací dat, které lze použít k automatizaci úloh přípravy dat, jako je filtrování anomálií, oprava neplatných hodnot a převod dat do standardních formátů.
DataBrew usnadňuje datovým vědcům, obchodním analytikům a inženýrům spolupráci na získávání poznatků z nezpracovaných dat. DataBrew je bez serverů, takže nemusíte spravovat infrastrukturu ani vytvářet clustery, abyste mohli prozkoumat a transformovat nezpracovaná data v hodnotě terabajtů.
Funkce DataBrew pro podniky
Příprava vizualizovaných dat
DataBrew je jiný způsob, jak zobrazit data, která se obvykle zobrazují ve sloupcových databázích jako alfanumerická čísla. DataBrew vizualizuje všechny načtené zdroje dat, aby vám pomohl porozumět datovým vztahům a hierarchii.
250+ automatizací přípravy dat
Očekává se, že datoví vědci budou jako součást své práce sledovat různé opakovatelné izolované pracovní postupy. Tyto pracovní postupy a procesy byly modelovány AWS jako jazykové a datově agnostické modulové moduly. Tato knihovna obsahuje akce, které mohou používat koncoví uživatelé.
Data Lineage
Podobně jako protokoly auditu, které se používají ke sledování aktivity zákazníků v IT síti IT sítě, vám datová linie umožňuje sledovat aktivity transformace dat v rámci AWS DataBrew. Tyto informace zahrnují zdroj dat, použité transformace a výstup dat, včetně cílového umístění.
Mapování dat
Databrew vám umožňuje najít odpovídající pole ve dvou zdrojích dat. Jakmile jsou odpovídající pole identifikována, lze je načíst do schématu.
AWS Glue DataBrew: Výhody
Níže jsou uvedeny funkce AWS Glue DataBrew:
- Nižší bariéra vstupu pro přípravu dat
- Automatické generování datového profilu
- Automatizujte více než 250 procesů přípravy dat
- Inteligentní předpisové návrhy
Alternativy k lepidlu AWS
Proud vzduchu
Airflow patří do sekce Workflow Manager technologického zásobníku. Je to nástroj s otevřeným zdrojovým kódem, který podporuje hvězdy GitHubu, vidlice GitHubu a další funkce. Proud vzduchu umožňuje vytvářet pracovní postupy pomocí směrovaných acyklických diagramů (DAG). Plánovač proudění vzduchu provádí vaše úkoly pomocí řady pracovníků a podle zadaných závislostí.
Matillion

Matillion ETL, nástroj ETL/ELT, byl navržen výslovně pro platformy cloudových databází, jako je Amazon Redshift a Google BigQuery. Jedná se o moderní uživatelské rozhraní založené na prohlížeči s výkonnými funkcemi ETL/ELT. Díky rychlému nastavení můžete být v provozu během několika minut.
Steh
Stitch je open-source ETL služba, která propojuje více zdrojů dat a replikuje data do preferovaných cílů. Použití je velmi snadné, protože k přesunu dat mezi zdroji a cíli v Stitch nepotřebujete žádné znalosti kódování. Snadno se používá, má přátelské GUI a je rychlý.
Stitch vám na rozdíl od jiných ETL nástrojů neumožňuje vybrat si předem připravený dashboard. Místo toho musíte svá data integrovat do otevřených datových skladů, které vyberete jako cíl. Může být obtížné orientovat se v zásobách.
Alteryx

Alteryx je analytická automatizační platforma, která pomáhá s přípravou a prolínáním sběru dat. Tato data lze použít k urychlení procesů a poskytnutí obchodního náhledu. Protože se jedná o nástroj přetahování, nepotřebujete žádné znalosti programování. Alteryx je skvělé místo, kam se obrátit pro rady a odpovědi od profesionálů z oboru.
Závěr
Takže to bylo vše o AWS Glue, což je cloudové řešení, které vám umožňuje pracovat s ETL potrubími. Stručně řečeno, proces interakce uživatele AWS Glue se skládá ze tří fází. Chcete-li vytvořit katalog dat, nejprve použijte prolézací moduly dat. Dále vytvoříte ETL kód vyžadovaný datovým kanálem AWS. Nakonec se vytvoří rozvrh ETL. Doufám, že vám tento blog poskytl dobrý přehled o Amazon Glue.
Můžete také prozkoumat nejlepší tipy pro zabezpečení úložiště AWS S3.