
Dnešní podniky jsou zaměřeny na data. Společnosti hledají způsoby, jak efektivně těžit a analyzovat data z různých zdrojů a zlepšit obchodní příjmy a zisky.
Jaké je ale nejbezpečnější místo pro ukládání a integraci dat z více zdrojů a jejich maximální využití?
Jak datová jezera, tak datové sklady jsou populární způsoby, jak spravovat obrovské množství velkých dat. Rozdíly mezi nimi spočívají v tom, jak organizace data přijímají, ukládají a používají. Čtěte dále a dozvíte se více.
Table of Contents
Co je to Data Lake?
Datové jezero označuje centrální úložiště, kde jsou data přijatá z více zdrojů – v jakémkoli formátu (strukturovaném nebo nestrukturovaném) – uložena tak, jak byla přijata. Je to jako zásobárna nezpracovaných dat, jejichž účel je zatím neznámý. Podniky obvykle ukládají data, která mohou být potenciálně užitečná pro budoucí analýzu v datovém jezeře.
Klíčové vlastnosti datového jezera:
- Obsahuje kombinaci užitečných a neužitečných dat, a proto potřebuje hodně úložného prostoru.
- Ukládá data v reálném čase i dávková data – můžete například ukládat data v reálném čase ze zařízení IoT, sociálních médií nebo cloudových aplikací a dávková data z databází nebo datových souborů.
- Má plochou architekturu.
- Protože data nejsou zpracovávána, dokud nejsou potřebná pro analýzu, je třeba je dobře řídit a udržovat; jinak se může proměnit v datové bažiny.
Jak tedy můžeme rychle získat data z tak rozsáhlého a zdánlivě chaotického úložiště? Datové jezero pro tento účel používá metadatové značky a identifikátory!
Co je to datový sklad?
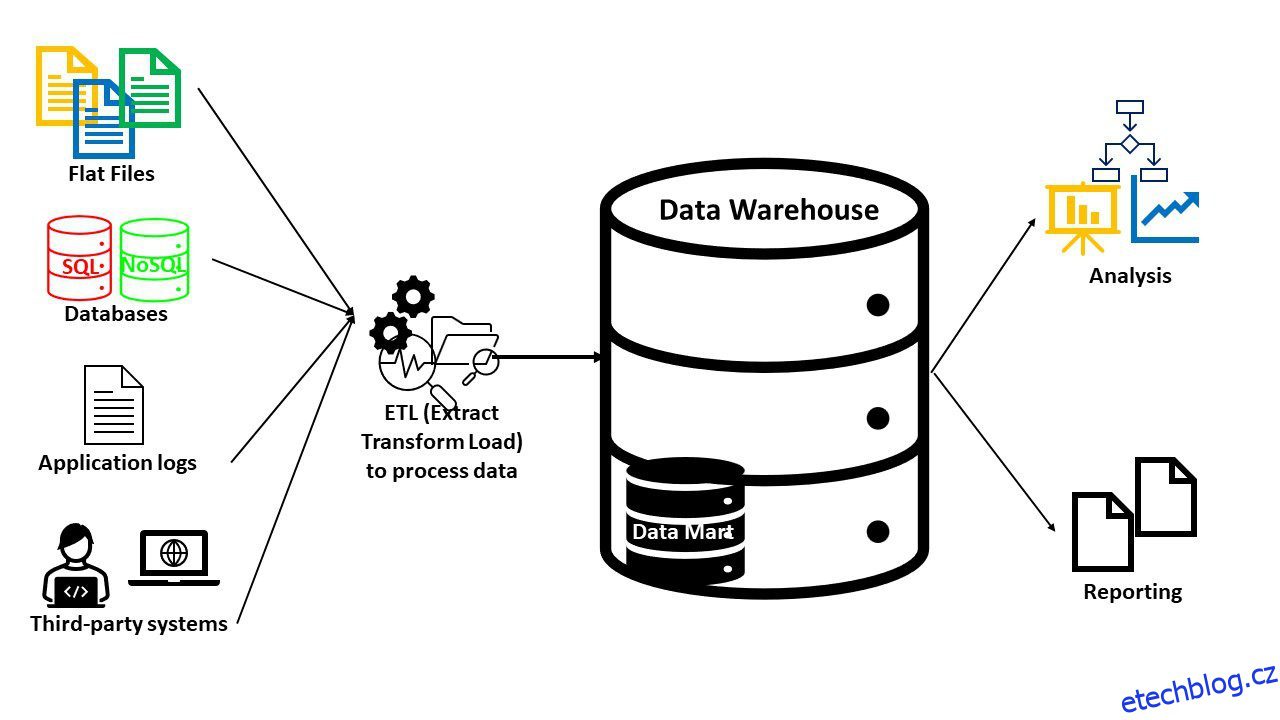
Organizovanější a strukturovanější úložiště – datový sklad obsahuje data, která jsou připravena k analýze. Strukturovaná, polostrukturovaná nebo nestrukturovaná data z více zdrojů jsou přijímána, integrována, čištěna, tříděna, transformována a přizpůsobena k použití.
Datový sklad obsahuje velké množství minulých a současných dat. Obvykle se data zpracovávají pro konkrétní obchodní problém (analýza). Tyto informace jsou dotazovány systémy Business Intelligence (BI) za účelem analýzy, vytváření sestav a přehledů.
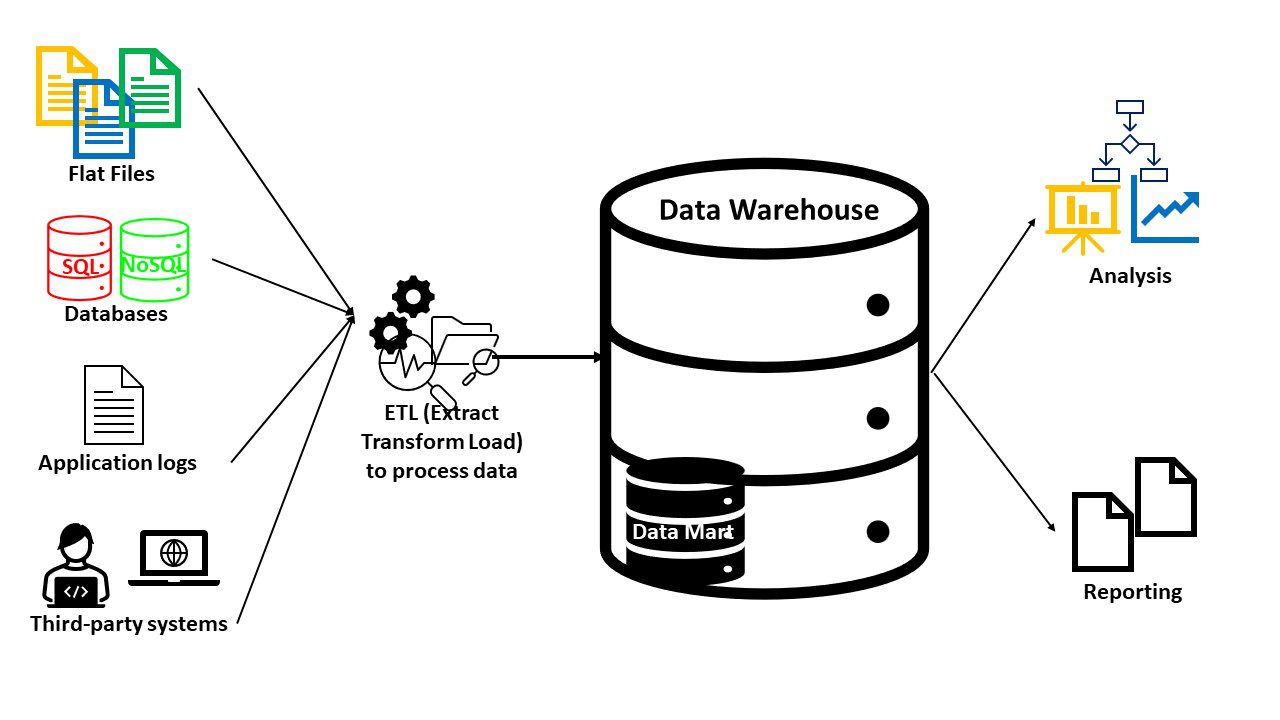
Datové sklady se obvykle skládají z:
- Databáze (SQL nebo NoSQL) pro ukládání a správu dat
- Nástroje pro transformaci a analýzu dat pro přípravu dat
- Nástroje BI pro dolování dat, statistickou analýzu, reporting a vizualizaci
Protože datové sklady slouží specifickému účelu, budete mít vždy relevantní data. Můžete také použít další nástroje v datových skladech k zajištění pokročilých funkcí, jako je umělá inteligence a prostorové nebo grafické funkce. Datové sklady vytvořené pro konkrétní doménu se nazývají datové tržiště.
Klíčové rozdíly mezi Data Lakes a Data Warehouses
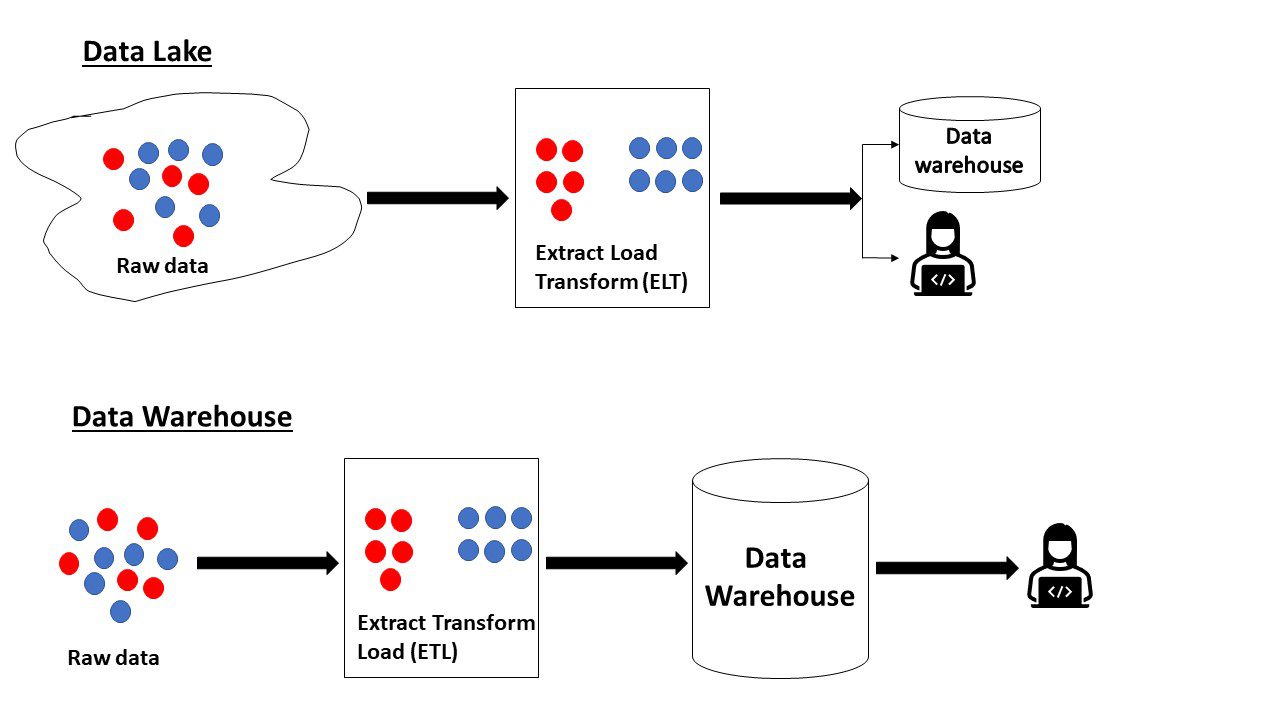
Abychom zopakovali, co jsme četli výše, datové jezero obsahuje nezpracovaná data, jejichž účel nebyl definován. Naproti tomu datový sklad obsahuje data, která jsou připravena k analýze a jsou již ve své nejlepší formě.
 Datové jezero vs. datový sklad
Datové jezero vs. datový sklad
Některé rozdíly mezi datovým jezerem a datovým skladem jsou:
Data LakeData WarehouseRaw nebo zpracovaná data v jakémkoli formátu jsou přijímána z více zdrojůData jsou získávána z více zdrojů pro analýzu a vytváření sestav. Je strukturovanéSchema se vytváří za chodu podle potřeby (schéma-on-read)Předdefinované schéma při zápisu do skladu (Schema-on-write)Nová data lze snadno přidatData jsou připravena po zpracování, takže každá nová změna vyžaduje více času a úsilí. Data je třeba aktualizovat a řídit, aby byla relevantníData jsou již ve své nejlepší formě, takže nevyžadují zvláštní údržbuSkládají se z obrovských objemů velkých dat (petabajty)Dat je obvykle menší než v datovém jezeře (terabajty). Datový sklad může obsahovat provozní data celé organizace, analytická data nebo data relevantní pro konkrétní doménu. Používají ji datoví vědci pro různé účely, jako je streamingová analytika, umělá inteligence, prediktivní analytika a mnoho případů použití. Používají ji obchodní analytici pro zpracování transakcí ( OLTP), provozní analytika (OLAP), reporting, vytváření vizualizacíData lze ukládat a archivovat po delší dobu, aby je bylo možné kdykoli analyzovat.Data je třeba často čistit, aby se do nich vešla nejnovější data.Úložiště je levné.Ukládání a zpracování jsou drahé a časově náročné – náročné, a proto by měly být plánovány uvážlivě. Vědci zabývající se daty mohou vyvinout nové problémy a řešení pohledem na data. Rozsah dat je omezen na konkrétní obchodní problém. Vzhledem k tomu, že data nejsou organizována určitým způsobem, relační i ne relační databáze lze použít k ukládání dat. Datové sklady obvykle používají relační databáze, protože data musí být v části kulární formát.
Případy použití pro Data Lake a Data Warehouse
Je snadné považovat datové jezero za pohodlnější volbu, protože je škálovatelnější, flexibilnější a přívětivější do kapsy. Datový sklad však může být skvělý nápad, když potřebujete relevantnější a strukturovanější data pro konkrétní analýzu.
Některé případy použití datového jezera jsou uvedeny níže:
#1. Dodavatelský řetězec a řízení
Obrovské množství velkých dat v datových jezerech pomáhá prediktivní analytice pro dopravu a logistiku. Pomocí historických a aktuálních dat mohou podniky hladce plánovat své každodenní operace, kontrolovat pohyb zásob v reálném čase a optimalizovat náklady.
#2. Zdravotní péče
Datové jezero má všechny minulé i současné informace o pacientech. To je užitečné při výzkumu, hledání vzorců, poskytování lepší a včasné léčby nemocí, automatizaci diagnostiky a získávání nejaktuálnějších podrobností o zdravotním stavu pacienta.
#3. Streamování dat a IoT
Datová jezera mohou nepřetržitě přijímat streamovaná data odeslaná do analytických kanálů pro nepřetržité hlášení a zjišťování jakýchkoli neobvyklých aktivit a pohybů. To je možné díky schopnosti datového jezera sbírat data (téměř) v reálném čase.
Některé případy použití datového skladu jsou:
#1. Finance
Finanční informace společnosti mohou být vhodnější pro datový sklad. Zaměstnanci mohou snadno přistupovat k organizovaným a strukturovaným informacím ve formě grafů a zpráv, aby mohli řídit finanční procesy, zvládat rizika a činit strategická rozhodnutí.
#2. Marketing a segmentace zákazníků
Datový sklad vytváří jediný zdroj „pravd“ nebo správných dat o zákaznících shromážděných z více zdrojů. Společnosti mohou tato data analyzovat, aby pochopily chování zákazníků, nabídly přizpůsobené slevy, segmentovaly zákazníky na základě jejich preferencí a generovaly více potenciálních zákazníků.
#3. Firemní panely a zprávy
Mnoho podniků používá datové sklady CRM a ERP k získávání dat o externích a interních zákaznících. Data jsou vždy relevantní a lze jim důvěřovat pro vytváření jakéhokoli typu sestavy a vizualizace.
#4. Migrace dat ze starších systémů
Pomocí možností ETL datových skladů mohou společnosti snadno transformovat starší systémová data do použitelnějšího formátu, který mohou nové systémy analyzovat. To organizacím pomůže získat přehled o historických trendech a činit přesná obchodní rozhodnutí.
Příklady nástrojů Data Lake
Někteří špičkoví poskytovatelé datových jezer jsou:
- Microsoft Azure – Azure může ukládat a analyzovat petabajty dat. Azure usnadňuje snadné ladění a optimalizaci programů pro velká data.
- Google Cloud – Google cloud nabízí nákladově efektivní příjem, ukládání a analýzu obrovských objemů velkých dat jakéhokoli typu. Integruje se také s analytickými nástroji, jako jsou Apache Spark, BigQuery a další analytické akcelerátory.
- Atlas MongoDB – Atlas data lake je plně spravované úložiště datových jezer. Poskytuje nákladově efektivní způsoby ukládání rozsáhlých dat a může spouštět vysoce výkonné dotazy, které využívají méně výpočetního výkonu, čímž šetří čas a náklady.
- Amazon S3 – Cloud AWS poskytuje potřebné nástroje k vybudování flexibilního, bezpečného a nákladově efektivního datového jezera. Má interaktivní konzolu pro správu uživatelů datového jezera a řízení přístupu k uživatelům.
Příklady nástrojů Data Warehouse
Někteří z předních poskytovatelů řešení datových skladů jsou:
- MÍZA – Datový sklad SAP umožňuje uživatelům sémanticky přistupovat k bohatým datům z více zdrojů. Podniky mohou bezpečně sdílet poznatky a modely, urychlit rozhodování a bezpečně kombinovat externí a interní data.
- ClicData – Inteligentní a integrovaný datový sklad ClicData zajišťuje integritu dat, kvalitu a snadné vykazování. ClicData nabízí jak plánovací systémy, tak rozhraní API v reálném čase, takže můžete kdykoli získat aktualizovaná data.
- Amazon Redshift – Jeden z nejpoužívanějších datových skladů, Redshift používá SQL k analýze všech typů dat přítomných v různých databázích, jezerech nebo jiných skladech. Nabízí skvělou rovnováhu mezi cenou a výkonem.
- sklad IBM Db2 – IBM poskytuje interní, cloudová a integrovaná řešení pro datové sklady. Integruje také nástroje strojového učení a umělé inteligence pro hlubší analýzu dat a sdílí společný SQL engine pro zefektivnění dotazů.
- Datový sklad Oracle Cloud – Oracle používá in-memory databázi a nabízí grafické, strojové učení a prostorové možnosti k hlubokému ponoru do dat pro rychlejší, ale bohatší analýzu dat.
Závěrečná slova
Jak datová jezera, tak datové sklady mají své výhody a ideální případy použití. Zatímco datová jezera jsou škálovatelnější a flexibilnější, datové sklady mají vždy spolehlivé a strukturované informace. Implementace Data Lake je relativně nová, zatímco datový sklad je zavedeným konceptem používaným mnoha organizacemi pro efektivní správu svých interních a externích dat.