
Extrakce dat je proces shromažďování konkrétních dat z webových stránek. Uživatelé mohou extrahovat text, obrázky, videa, recenze, produkty atd. Můžete extrahovat data pro provádění průzkumu trhu, analýzy sentimentu, analýzy konkurence a souhrnná data.
Pokud pracujete s malým množstvím dat, můžete data extrahovat ručně zkopírováním a vložením konkrétních informací z webových stránek do tabulkového procesoru nebo formátu dokumentu podle vašich představ. Pokud například jako zákazník hledáte online recenze, které vám pomohou při rozhodování o nákupu, můžete data zrušit ručně.
Na druhou stranu, pokud máte co do činění s velkými soubory dat, potřebujete techniku automatizované extrakce dat. Pro takové úlohy můžete vytvořit vlastní řešení extrakce dat nebo použít Proxy API nebo Scraping API.
Tyto techniky však mohou být méně účinné, protože některé weby, na které cílíte, mohou být chráněny pomocí captchas. Možná budete muset také spravovat roboty a proxy. Takové úkoly vám mohou zabrat hodně času a omezit povahu obsahu, který můžete extrahovat.
Table of Contents
Scraping Browser: Řešení
Všechny tyto výzvy můžete překonat pomocí prohlížeče Scraping Browser od Bright Data. Tento all-in-one prohlížeč pomáhá shromažďovat data z webů, které je těžké odstranit. Je to prohlížeč, který používá grafické uživatelské rozhraní (GUI) a je řízen rozhraním Puppeteer nebo Playwright API, díky čemuž je pro roboty nezjistitelný.
Scraping Browser má vestavěné funkce odemykání, které automaticky zpracovávají všechny bloky za vás. Prohlížeč je otevřen na serverech Bright Data, což znamená, že nepotřebujete drahou interní infrastrukturu k odstranění dat pro vaše rozsáhlé projekty.
Vlastnosti prohlížeče Bright Data Scraping Browser
- Automatické odemykání webových stránek: Nemusíte neustále obnovovat svůj prohlížeč, protože tento prohlížeč se automaticky přizpůsobí řešení CAPTCHA, novým blokům, otiskům prstů a dalším pokusům. Scraping Browser napodobuje skutečného uživatele.
- Velká síť proxy: Můžete cílit na jakoukoli zemi, protože prohlížeč Scraping má více než 72 milionů IP adres. Můžete cílit na města nebo dokonce na dopravce a těžit z nejlepších technologií ve své třídě.
- Škálovatelnost: Můžete otevřít tisíce relací současně, protože tento prohlížeč používá infrastrukturu Bright Data ke zpracování všech požadavků.
- Kompatibilní s Puppeteer a Playwright: Tento prohlížeč vám umožňuje provádět volání API a načítat libovolný počet relací prohlížeče buď pomocí Puppeteer (Python) nebo Playwright (Node.js).
- Šetří čas a zdroje: Namísto nastavování proxy se o vše na pozadí stará prohlížeč Scraping. Také nemusíte nastavovat vlastní infrastrukturu, protože tento nástroj se o vše postará na pozadí.
Jak nastavit Scraping Browser
- Přejděte na web Bright Data a klikněte na Scraping Browser na kartě „Scraping Solutions“.
- Vytvořit účet. Uvidíte dvě možnosti; „Zahájit bezplatnou zkušební verzi“ a „Začít zdarma s Googlem“. Nyní zvolíme „Zahájit bezplatnou zkušební verzi“ a přejděte k dalšímu kroku. Účet můžete vytvořit buď ručně, nebo použít svůj účet Google.
- Když je váš účet vytvořen, řídicí panel nabídne několik možností. Vyberte „Proxy & Scraping Infrastructure“.
- V novém okně, které se otevře, vyberte Scraping Browser a klikněte na „Začít“.
- Uložte a aktivujte své konfigurace.
- Aktivujte si bezplatnou zkušební verzi. První možnost vám poskytuje kredit ve výši 5 USD, který můžete použít k využití proxy. Chcete-li tento produkt vyzkoušet, klikněte na první možnost. Pokud jste však náročný uživatel, můžete kliknout na druhou možnost, která vám dá 50 $ zdarma, pokud na svůj účet nahrajete 50 $ nebo více.
- Zadejte své fakturační údaje. Nebojte se, platforma vám nebude nic účtovat. Fakturační údaje pouze ověřují, že jste nový uživatel a nehledáte výhody vytvořením více účtů.
- Vytvořte nový proxy. Jakmile uložíte své fakturační údaje, můžete vytvořit nový proxy. Klikněte na ikonu „přidat“ a jako „Typ proxy“ vyberte možnost Scraping Browser. Klikněte na „Přidat proxy“ a přejděte k dalšímu kroku.
- Vytvořte novou „zónu“. Objeví se okno s dotazem, zda chcete vytvořit novou zónu; klikněte na „Ano“ a pokračujte.
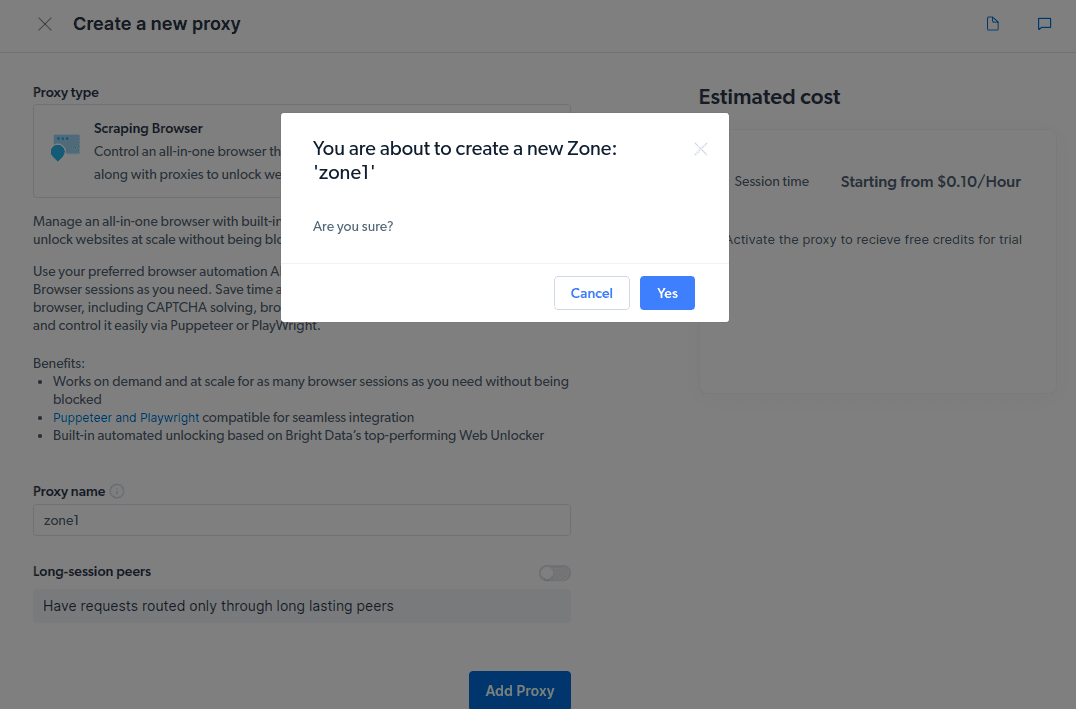
- Klikněte na „Vyzkoušet příklady kódu a integrace“. Nyní získáte příklady integrace proxy, které můžete použít k odstranění dat z vašeho cílového webu. K extrahování dat z cílového webu můžete použít Node.js nebo Python.
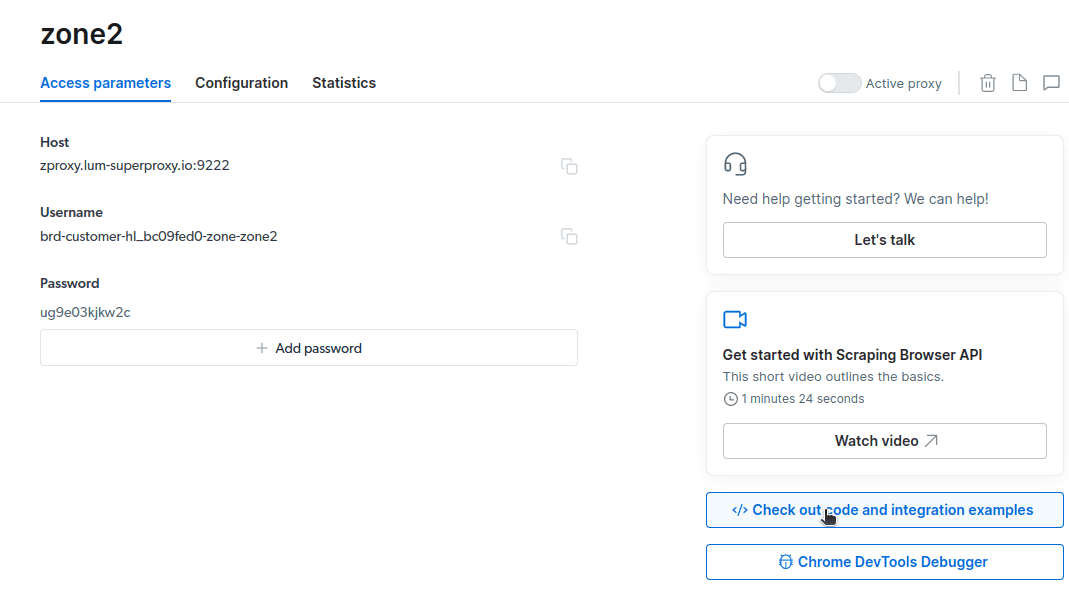
Nyní máte vše, co potřebujete k extrahování dat z webu. K demonstraci toho, jak funguje Scraping Browser, použijeme naši webovou stránku etechblog.cz.com. Pro tuto ukázku použijeme node.js. Můžete pokračovat, pokud máte nainstalovaný node.js.
Následuj tyto kroky;
const puppeteer = require('puppeteer-core');
// should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>'
const auth="USERNAME:PASSWORD";
async function run(){
let browser;
try {
browser = await puppeteer.connect({browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222`});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2*60*1000);
await page.goto('https://example.com');
const html = await page.evaluate(() => document.documentElement.outerHTML);
console.log(html);
}
catch(e) {
console.error('run failed', e);
}
finally {
await browser?.close();
}
}
if (require.main==module)
run();
Změním svůj kód na řádku 10 takto;
wait page.goto(‚https://etechblog.cz.com/authors/‚);
Můj konečný kód nyní bude;
const puppeteer = require('puppeteer-core');
// should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>'
const auth="brd-customer-hl_bc09fed0-zone-zone2:ug9e03kjkw2c";
async function run(){
let browser;
try {
browser = await puppeteer.connect({browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222`});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2*60*1000);
await page.goto('https://etechblog.cz.com/authors/');
const html = await page.evaluate(() => document.documentElement.outerHTML);
console.log(html);
}
catch(e) {
console.error('run failed', e);
}
finally {
await browser?.close();
}
}
if (require.main==module)
run();
node script.js
Něco takového budete mít na svém terminálu
Jak exportovat data
K exportu dat můžete použít několik přístupů v závislosti na tom, jak je chcete použít. Dnes můžeme exportovat data do html souboru změnou skriptu tak, aby vytvořil nový soubor s názvem data.html namísto jeho tisku na konzoli.
Obsah svého kódu můžete změnit následovně;
const puppeteer = require('puppeteer-core');
const fs = require('fs');
// should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>'
const auth="brd-customer-hl_bc09fed0-zone-zone2:ug9e03kjkw2c";
async function run() {
let browser;
try {
browser = await puppeteer.connect({ browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222` });
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2 * 60 * 1000);
await page.goto('https://etechblog.cz.com/authors/');
const html = await page.evaluate(() => document.documentElement.outerHTML);
// Write HTML content to a file
fs.writeFileSync('data.html', html);
console.log('Data export complete.');
} catch (e) {
console.error('run failed', e);
} finally {
await browser?.close();
}
}
if (require.main == module) {
run();
}
Nyní můžete spustit kód pomocí tohoto příkazu;
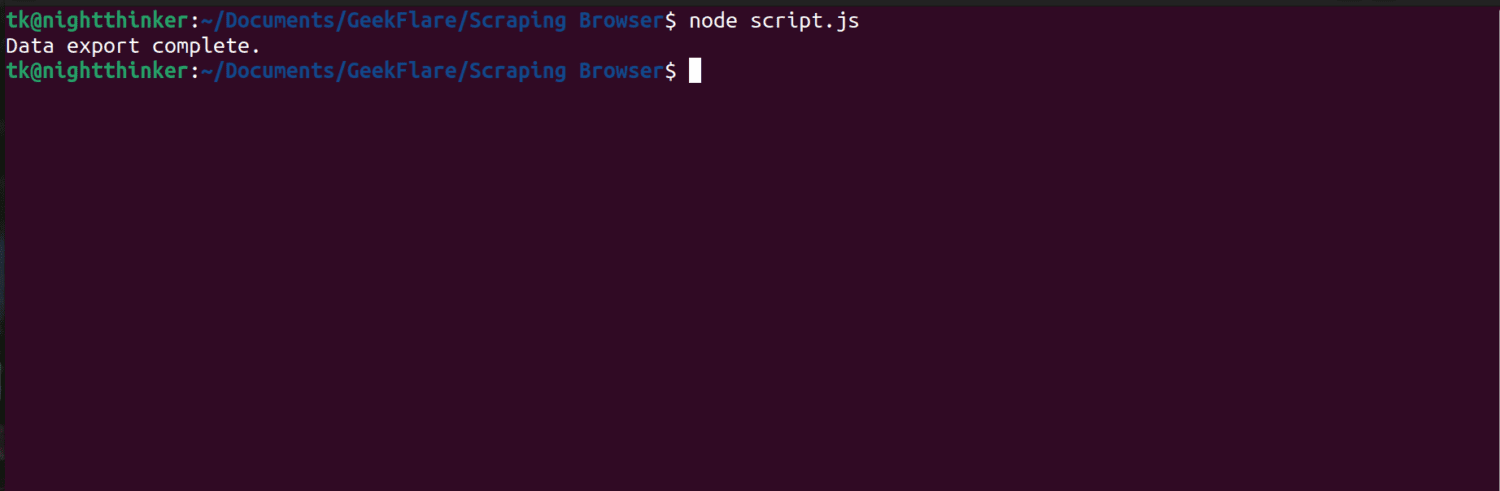
node script.js
Jak můžete vidět na následujícím snímku obrazovky, terminál zobrazí zprávu „export dat dokončen“.
Pokud zkontrolujeme naši složku projektu, můžeme nyní vidět soubor s názvem data.html s tisíci řádky kódu.
Právě jsem poškrábal povrch toho, jak extrahovat data pomocí prohlížeče Scraping. Pomocí tohoto nástroje mohu dokonce zúžit a odstranit pouze jména autorů a jejich popisy.
Pokud chcete použít Scraping Browser, identifikujte datové sady, které chcete extrahovat, a odpovídajícím způsobem upravte kód. Můžete extrahovat text, obrázky, videa, metadata a odkazy v závislosti na webu, na který cílíte, a na struktuře souboru HTML.
Nejčastější dotazy
Je extrakce dat a web scraping legální?
Web scraping je kontroverzní téma, přičemž jedna skupina tvrdí, že je nemorální, zatímco jiní se domnívají, že je to v pořádku. Zákonnost škrábání webu bude záviset na povaze škrábaného obsahu a zásadách cílové webové stránky.
Obecně je seškrabování dat s osobními údaji, jako jsou adresy a finanční údaje, považováno za nezákonné. Než vyhledáte data, zkontrolujte, zda web, na který cílíte, má nějaké pokyny. Vždy se ujistěte, že data, která nejsou veřejně dostupná, neodstraníte.
Je Scraping Browser bezplatný nástroj?
Ne. Scraping Browser je placená služba. Pokud se zaregistrujete k bezplatné zkušební verzi, nástroj vám poskytne kredit ve výši 5 $. Placené balíčky začínají od 15 USD/GB + 0,1 USD/h. Můžete se také rozhodnout pro možnost Pay As You Go, která začíná od 20 USD/GB + 0,1 USD/h.
Jaký je rozdíl mezi škrabacími prohlížeči a bezhlavými prohlížeči?
Scraping Browser je výkonný prohlížeč, což znamená, že má grafické uživatelské rozhraní (GUI). Na druhou stranu bezhlavé prohlížeče nemají grafické rozhraní. Bezhlavé prohlížeče, jako je Selenium, se používají k automatizaci webového scrapingu, ale někdy jsou omezené, protože se musí vypořádat s CAPTCHA a detekcí botů.
Zabalit se
Jak můžete vidět, Scraping Browser zjednodušuje extrahování dat z webových stránek. Scraping Browser se ve srovnání s nástroji, jako je Selenium, snadno používá. Tento prohlížeč s úžasným uživatelským rozhraním a dobrou dokumentací mohou používat i nevývojáři. Tento nástroj má odblokovací schopnosti, které nejsou k dispozici v jiných nástrojích pro šrotování, takže je účinný pro všechny, kteří chtějí takové procesy automatizovat.
Můžete také prozkoumat, jak zabránit pluginům ChatGPT ve stírání obsahu vašeho webu.