Jak seškrábat data z webu pomocí Tabulek Google
Extrahování informací z webových stránek a jejich automatizovaná analýza, známé jako web scraping, je mocná technika. I když je možné provádět tuto činnost ručně, může být únavná a časově velmi náročná. Avšak, nástroje pro web scraping zrychlují a zefektivňují celý proces, a to za nižší náklady.
Zajímavé je, že Tabulky Google nabízejí potenciál stát se komplexním nástrojem pro web scraping, a to díky funkci IMPORTXML. S pomocí IMPORTXML lze snadno získávat data z webových stránek a využívat je pro různé účely, jako jsou analýzy, vytváření reportů nebo jiné úlohy založené na datech.
Funkce IMPORTXML v Tabulkách Google
Tabulky Google disponují integrovanou funkcí IMPORTXML, která umožňuje importovat data z webových formátů, jako jsou XML, HTML, RSS a CSV. Tato funkce představuje významnou pomoc pro ty, kteří chtějí získávat data z webových stránek bez nutnosti složitého kódování.
Základní syntaxe funkce IMPORTXML je následující:
=IMPORTXML(url, xpath_query)
- url: Adresa URL webové stránky, ze které se mají získávat data.
- xpath_query: Dotaz XPath, který definuje data k extrakci.
XPath (XML Path Language) je jazyk používaný pro navigaci v dokumentech XML, včetně HTML, což umožňuje specifikovat umístění dat ve struktuře HTML. Pro efektivní používání funkce IMPORTXML je důležité porozumět dotazům XPath.
Pochopení XPath
XPath nabízí různé funkce a výrazy pro navigaci a filtrování dat v dokumentu HTML. Komplexní průvodce jazykem XML a XPath přesahuje rámec tohoto článku, proto se zaměříme na několik základních konceptů:
- Výběr prvku: Prvky lze vybírat pomocí lomítek / a // k označení cest. Například /html/body/div vybere všechny prvky div v těle dokumentu.
- Výběr atributu: Pro výběr atributů se používá @. Například //@href vybere všechny atributy href na stránce.
- Predikátové filtry: Prvky lze filtrovat pomocí predikátů, které se uvádějí v hranatých závorkách [ ]. Například /div[@class="container"] vybere všechny prvky div s třídou "container".
- Funkce: XPath disponuje různými funkcemi, jako například contains(), starts-with() a text() pro provádění specifických akcí, jako je kontrola textového obsahu nebo hodnot atributů.
Nyní, když znáte syntaxi funkce IMPORTXML, máte adresu URL webové stránky a víte, který prvek chcete extrahovat, vyvstává otázka, jak získat XPath prvku?
Pro extrahování dat pomocí funkce IMPORTXML není nutné znát strukturu webové stránky nazpaměť. Každý moderní prohlížeč nabízí nástroj, který umožňuje okamžité zkopírování cesty XPath libovolného prvku.
Nástroj "Zkontrolovat prvek" (Inspect Element) umožňuje extrahovat XPath z prvků webové stránky. Postup je následující:
- V preferovaném webovém prohlížeči přejděte na webovou stránku, ze které chcete data extrahovat.
- Najděte prvek, který chcete extrahovat.
- Klikněte pravým tlačítkem myši na daný prvek.
- Z nabídky po kliknutí pravým tlačítkem vyberte možnost "Zkontrolovat prvek". Váš prohlížeč otevře panel s HTML kódem webové stránky, přičemž příslušný HTML prvek bude v kódu zvýrazněn.
- V panelu "Zkontrolovat prvek" klikněte pravým tlačítkem na zvýrazněný prvek v HTML kódu.
- Kliknutím na možnost "Kopírovat XPath" zkopírujete adresu XPath prvku do schránky.
Nyní, když máte vše potřebné, je čas vyzkoušet funkci IMPORTXML a extrahovat několik odkazů.
Jak extrahovat odkazy z webu pomocí IMPORTXML
Funkci IMPORTXML lze použít k extrahování různých dat z webových stránek, včetně odkazů, videí, obrázků a téměř jakéhokoli prvku na webu. Odkazy jsou jedním z klíčových prvků webové analýzy a analýzou stránek, na které se odkazuje, lze získat cenné informace o webu.
Díky IMPORTXML lze rychle extrahovat odkazy v Tabulkách Google a následně je analyzovat pomocí různých funkcí, které Tabulky Google nabízejí.
1. Extrahování všech odkazů
Pro extrahování všech odkazů z webové stránky lze použít následující vzorec:
=IMPORTXML(url, "//a/@href")
Tento dotaz XPath vybere všechny atributy href prvků <a>, čímž efektivně extrahuje všechny odkazy na stránce.
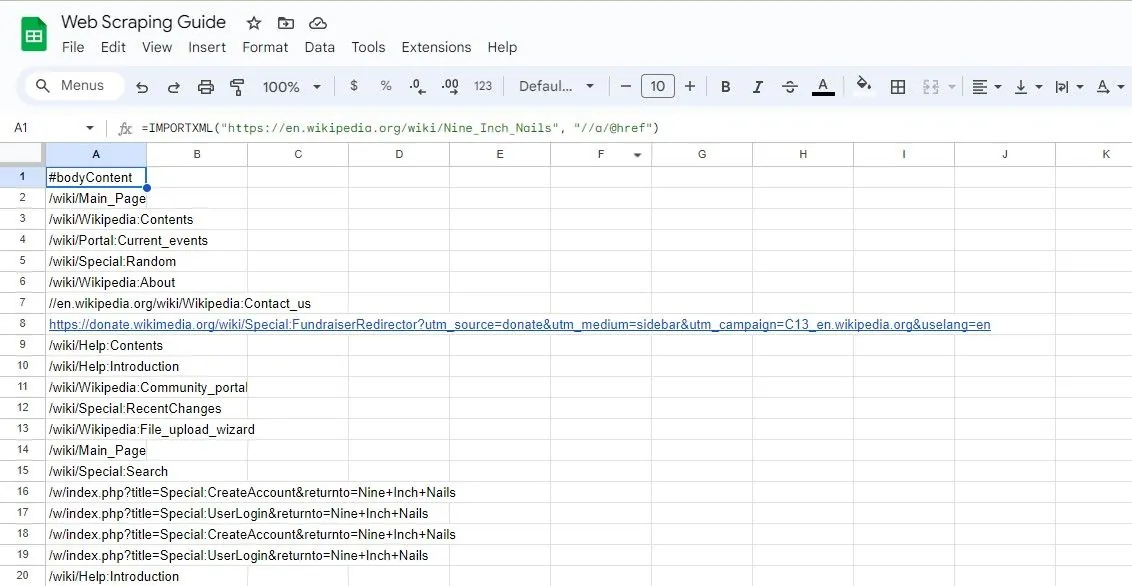
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//a/@href")
Výše uvedený vzorec extrahuje všechny odkazy z článku na Wikipedii.
Doporučuje se zadat adresu URL webové stránky do samostatné buňky a poté na tuto buňku odkazovat. Tímto způsobem se zabrání tomu, aby byl vzorec příliš dlouhý a nepraktický. Stejný postup lze použít i pro dotaz XPath.
2. Extrahování veškerého textu odkazů
Pro extrahování textu odkazů spolu s jejich adresami URL lze použít:
=IMPORTXML(url, "//a")
Tento dotaz vybere všechny prvky <a> a z výsledků je pak možné získat text odkazu i jeho adresu URL.
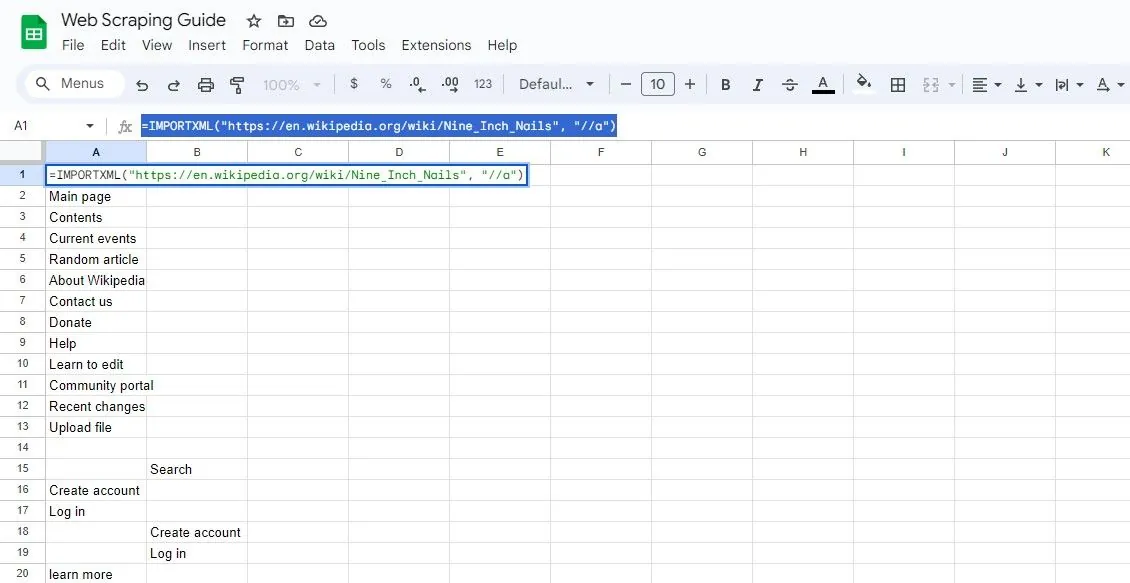
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//a")
Výše uvedený vzorec získá texty odkazů z téhož článku na Wikipedii.
Jak extrahovat konkrétní odkazy z webu pomocí IMPORTXML
Někdy může být potřeba extrahovat konkrétní odkazy na základě určitých kritérií. Například, může vás zajímat extrahování odkazů obsahujících určité klíčové slovo nebo odkazů umístěných v určité části stránky.
S dostatečnými znalostmi jazyka XPath můžete přesně specifikovat jakýkoli prvek, který hledáte.
1. Extrahování odkazů obsahujících klíčové slovo
Pro extrahování odkazů, které obsahují konkrétní klíčové slovo, lze použít funkci `contains()` jazyka XPath:
=IMPORTXML(url, "//a[contains(@href, 'keyword')]/@href")
Tento dotaz vybere atributy `href` prvků <a>, u kterých atribut `href` obsahuje zadané klíčové slovo.
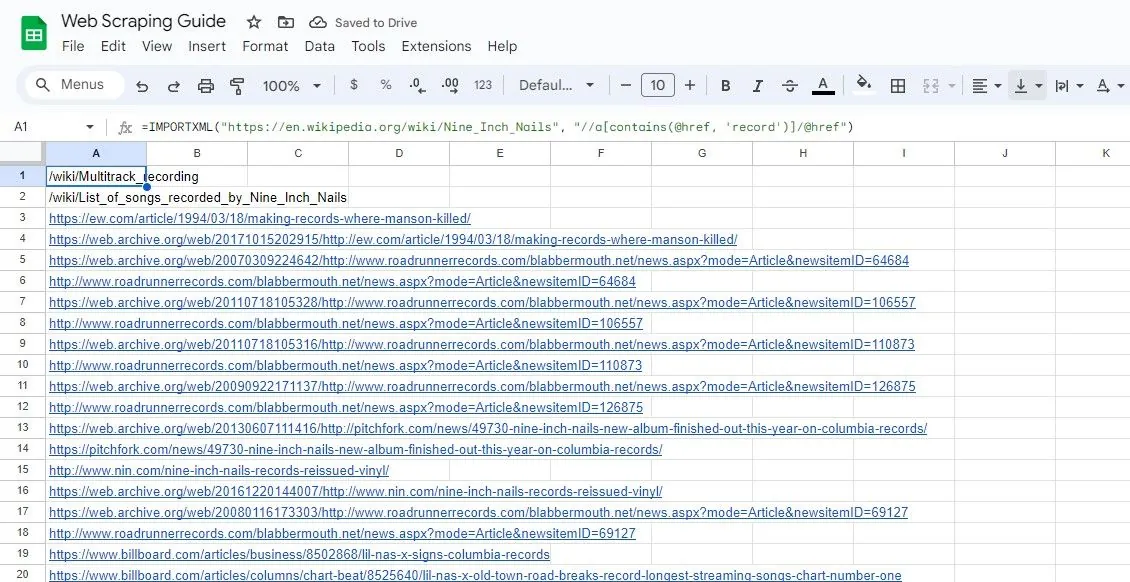
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//a[contains(@href, 'record')]/@href")
Výše uvedený vzorec extrahuje všechny odkazy, které obsahují slovo „record“ ve svém textu z vybraného článku na Wikipedii.
2. Extrahování odkazů v rámci sekce
Pro extrahování odkazů z určité části stránky lze specifikovat cestu XPath k této části. Například:
=IMPORTXML(url, "//div[@class="section"]//a/@href")
Tento dotaz vybere atributy `href` prvků <a>, které se nacházejí v prvcích <div> s třídou "section".
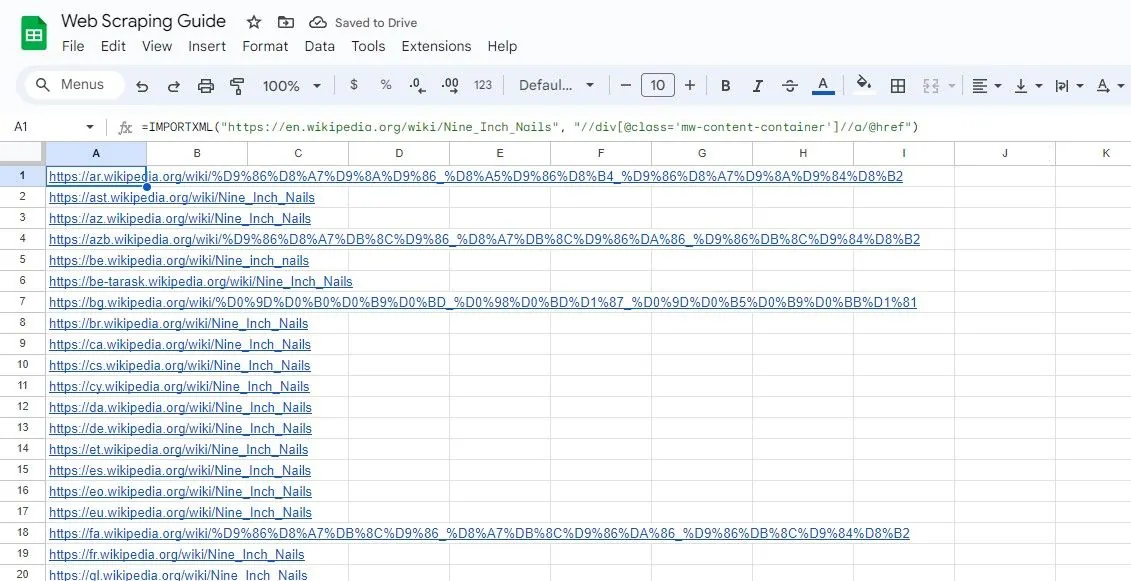
Podobně, následující vzorec vybere všechny odkazy v rámci prvků <div>, které mají třídu "mw-content-container":
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//div[@class="mw-content-container"]//a/@href")
Je důležité zmínit, že funkci IMPORTXML lze použít pro více než jen extrahování webových stránek. Lze ji také použít pro import datových tabulek z webových stránek do Tabulek Google s využitím rodiny funkcí IMPORT.
Ačkoli Tabulky Google a Excel sdílejí většinu funkcí, rodina funkcí IMPORT je unikátní pro Tabulky Google. Pro import dat z webů do Excelu je třeba zvážit jiné metody.
Zjednodušení web scrapingu s Tabulkami Google
Web scraping pomocí Tabulek Google a funkce IMPORTXML představuje univerzální a snadno přístupný způsob, jak shromažďovat data z webových stránek.
Osvojením si jazyka XPath a pochopením principů tvorby efektivních dotazů můžete odhalit plný potenciál funkce IMPORTXML a získat cenné poznatky z webových zdrojů. Pusťte se do scrapingu a posuňte vaši webovou analýzu na vyšší úroveň!
