
Reddit nabízí kanály JSON pro každý subreddit. Zde je návod, jak vytvořit Bash skript, který stáhne a analyzuje seznam příspěvků z libovolného subredditu, který se vám líbí. To je jen jedna věc, kterou můžete dělat s kanály JSON na Redditu.
Table of Contents
Instalace Curl a JQ
K načtení zdroje JSON z Redditu použijeme curl a jq k analýze dat JSON a extrahování požadovaných polí z výsledků. Nainstalujte tyto dvě závislosti pomocí apt-get na Ubuntu a dalších distribucích Linuxu založených na Debianu. V jiných distribucích Linuxu použijte místo toho nástroj pro správu balíčků vaší distribuce.
sudo apt-get install curl jq
Načtěte některá data JSON z Redditu
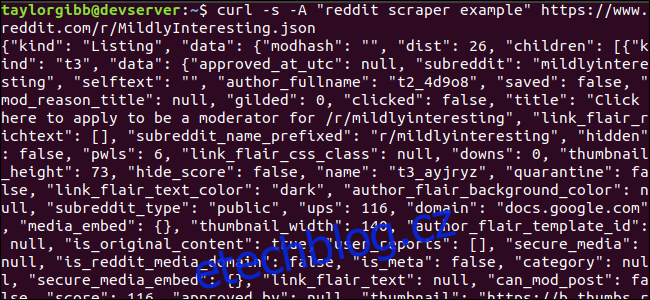
Podívejme se, jak zdroj dat vypadá. Použijte curl k načtení nejnovějších příspěvků z Mírně Zajímavé subreddit:
curl -s -A “reddit scraper example” https://www.reddit.com/r/MildlyInteresting.json
Všimněte si, jak možnosti použité před URL: -s nutí curl běžet v tichém režimu, takže nevidíme žádný výstup kromě dat ze serverů Reddit. Další možnost a parametr, který následuje, -A “reddit scraper example” , nastavuje vlastní řetězec uživatelského agenta, který pomáhá Redditu identifikovat službu přistupující k jejich datům. Servery Reddit API uplatňují limity rychlosti na základě řetězce uživatelského agenta. Nastavení vlastní hodnoty způsobí, že Reddit oddělí náš limit sazby od ostatních volajících a sníží pravděpodobnost, že dostaneme chybu HTTP 429 Rate Limit Exceeded.
Výstup by měl vyplnit okno terminálu a vypadat nějak takto:
Ve výstupních datech je spousta polí, ale jediné, co nás zajímá, jsou Název, Trvalý odkaz a URL. Úplný seznam typů a jejich polí si můžete prohlédnout na stránce dokumentace API Reddit: https://github.com/reddit-archive/reddit/wiki/JSON
Extrahování dat z výstupu JSON
Chceme extrahovat název, trvalý odkaz a adresu URL z výstupních dat a uložit je do souboru odděleného tabulátory. Můžeme použít nástroje pro zpracování textu jako sed a grep , ale máme k dispozici další nástroj, který rozumí datovým strukturám JSON, nazvaný jq . Pro náš první pokus jej použijme k pěknému vytištění a barevnému označení výstupu. Použijeme stejné volání jako předtím, ale tentokrát výstup propojíme přes jq a dáme mu pokyn, aby analyzoval a vytiskl data JSON.
curl -s -A “reddit scraper example” https://www.reddit.com/r/MildlyInteresting.json | jq .
Všimněte si období, které následuje po příkazu. Tento výraz jednoduše analyzuje vstup a vytiskne jej tak, jak je. Výstup vypadá pěkně naformátovaný a barevně odlišený:
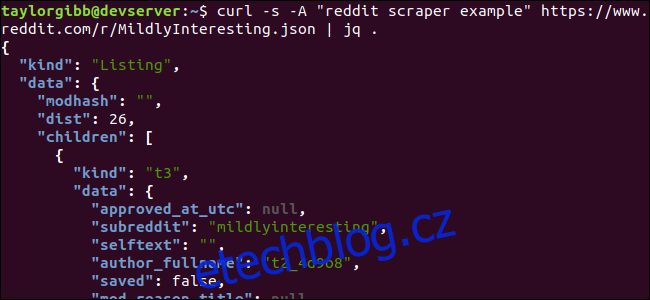
Pojďme prozkoumat strukturu dat JSON, která získáváme zpět z Redditu. Kořenový výsledek je objekt, který obsahuje dvě vlastnosti: druh a data. Ten má vlastnost zvanou děti, která zahrnuje řadu příspěvků na tento subreddit.
Každá položka v poli je objekt, který také obsahuje dvě pole nazvaná druh a data. Vlastnosti, které chceme uchopit, jsou v datovém objektu. jq očekává výraz, který lze aplikovat na vstupní data, a vytváří požadovaný výstup. Musí popisovat obsah z hlediska jejich hierarchie a členství v poli a také to, jak by měla být data transformována. Spusťte celý příkaz znovu se správným výrazem:
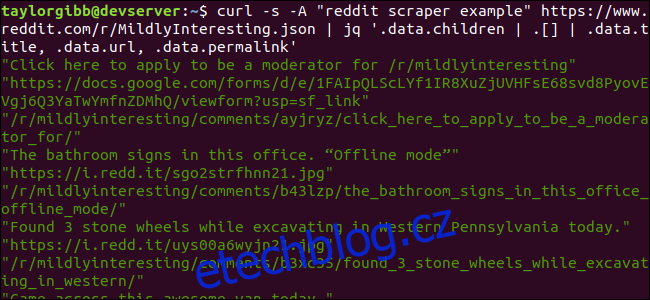
curl -s -A “reddit scraper example” https://www.reddit.com/r/MildlyInteresting.json | jq ‘.data.children | .[] | .data.title, .data.url, .data.permalink’
Výstup zobrazuje název, adresu URL a trvalý odkaz každý na svém vlastním řádku:
Pojďme se ponořit do příkazu jq, který jsme zavolali:
jq ‘.data.children | .[] | .data.title, .data.url, .data.permalink’
V tomto příkazu jsou tři výrazy oddělené dvěma symboly potrubí. Výsledky každého výrazu jsou předány dalšímu k dalšímu vyhodnocení. První výraz odfiltruje vše kromě pole záznamů na Redditu. Tento výstup je převeden do druhého výrazu a vynucen do pole. Třetí výraz působí na každý prvek v poli a extrahuje tři vlastnosti. Více informací o jq a jeho syntaxi výrazu naleznete v oficiální manuál jq.
Dát to všechno dohromady do scénáře
Pojďme dát volání API a post-processing JSON dohromady do skriptu, který vygeneruje soubor s požadovanými příspěvky. Přidáme podporu pro načítání příspěvků z libovolného subredditu, nejen /r/MildlyInteresting.
Otevřete svůj editor a zkopírujte obsah tohoto úryvku do souboru s názvem scrape-reddit.sh
#!/bin/bash
if [ -z "$1" ]
then
echo "Please specify a subreddit"
exit 1
fi
SUBREDDIT=$1
NOW=$(date +"%m_%d_%y-%H_%M")
OUTPUT_FILE="${SUBREDDIT}_${NOW}.txt"
curl -s -A "bash-scrape-topics" https://www.reddit.com/r/${SUBREDDIT}.json |
jq '.data.children | .[] | .data.title, .data.url, .data.permalink' |
while read -r TITLE; do
read -r URL
read -r PERMALINK
echo -e "${TITLE}t${URL}t${PERMALINK}" | tr --delete " >> ${OUTPUT_FILE}
done
Tento skript nejprve zkontroluje, zda uživatel zadal název subreddit. Pokud ne, ukončí se s chybovou zprávou a nenulovým návratovým kódem.
Dále uloží první argument jako název subreddit a vytvoří název souboru s datem, kam bude výstup uložen.
Akce začíná, když je zavoláno curl s vlastní hlavičkou a adresou URL subredditu, který má být scrape. Výstup je přesměrován do jq, kde je analyzován a redukován na tři pole: Title, URL a Permalink. Tyto řádky se čtou po jednom a ukládají se do proměnné pomocí příkazu read, vše uvnitř smyčky while, která bude pokračovat, dokud nebudou ke čtení žádné další řádky. Poslední řádek vnitřního bloku while odráží tři pole, která jsou oddělena znakem tabulátoru, a poté jej propojuje pomocí příkazu tr, aby bylo možné odstranit dvojité uvozovky. Výstup je pak připojen k souboru.
Než budeme moci tento skript spustit, musíme se ujistit, že mu byla udělena oprávnění ke spuštění. Pomocí příkazu chmod použijte na soubor tato oprávnění:
chmod u+x scrape-reddit.sh
A nakonec spusťte skript s názvem subreddit:
./scrape-reddit.sh MildlyInteresting
Výstupní soubor je vygenerován ve stejném adresáři a jeho obsah bude vypadat nějak takto:
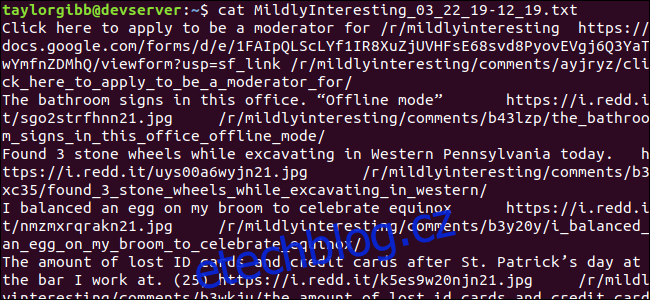
Každý řádek obsahuje tři pole, po kterých jdeme, oddělená tabulátorem.
Jít dále
Reddit je zlatý důl zajímavého obsahu a médií a vše je snadno dostupné pomocí jeho JSON API. Nyní, když máte způsob, jak získat přístup k těmto datům a zpracovat výsledky, můžete například:
Získejte nejnovější titulky z /r/WorldNews a odešlete je na plochu pomocí oznámit-odeslat
Integrujte nejlepší vtipy z /r/DadJokes do svého systému Message-Of-The-Day
Získejte nejlepší obrázek dneška z /r/aww a vytvořte si z něj pozadí plochy
To vše je možné pomocí poskytnutých dat a nástrojů, které máte ve svém systému. Šťastné hackování!