
Každá služba AWS zaznamenává své zpracování do souborů organizovaných pod skupinami protokolů CloudWatch. Skupiny protokolů jsou obvykle pojmenovány podle samotné služby pro snadnější identifikaci. Systémové zprávy služby nebo informace o společném stavu se ve výchozím nastavení zapisují do těchto souborů protokolu.
Můžete však přidat vlastní informace o zprávách protokolu nad výchozí. Pokud jsou takové protokoly vytvořeny moudře, mohou sloužit k vytvoření užitečných řídicích panelů CloudWatch.
S metrikami a strukturovanými informacemi, které poskytují další podrobnosti o zpracování úloh. Nejen, že mohou obsahovat standardní widgety se systémovými informacemi o službě. Můžete to rozšířit o svůj vlastní obsah agregovaný do vlastního widgetu nebo metriky.
Table of Contents
Dotaz na soubory protokolu
Zdroj: aws.amazon.com
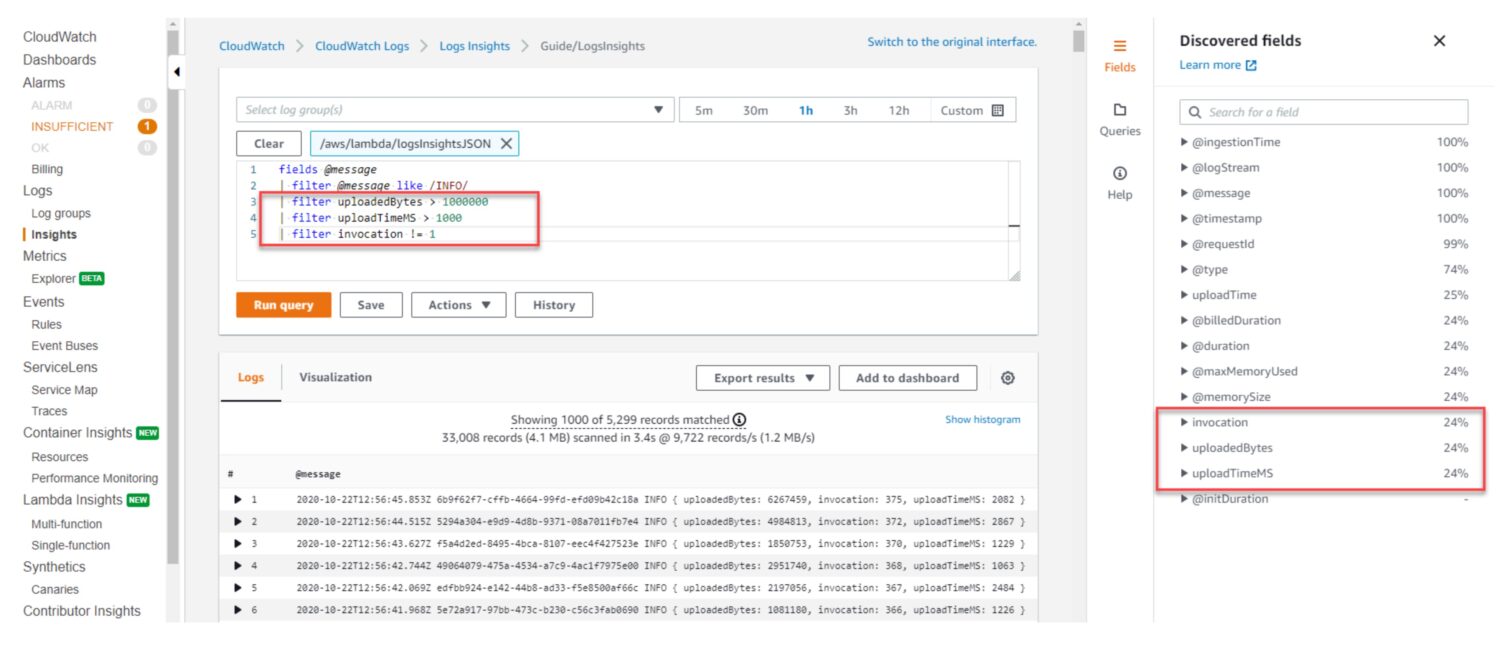
AWS CloudWatch Log Insights vám umožňuje vyhledávat a analyzovat data protokolu z vašich zdrojů AWS v reálném čase. Můžete se na to dívat jako na databázový pohled. Dotaz definujete na řídicím panelu a řídicí panel jej vybere, když jej navštívíte nebo v zadaném časovém okně v minulosti, jak jej definujete v zobrazení řídicího panelu.
K vyhledávání a analýze dat protokolů používá dotazovací jazyk nazvaný CloudWatch Logs Insights. Dotazovací jazyk je založen na podmnožině jazyka SQL. Umožňuje vám vyhledávat a filtrovat data protokolu. Můžete vyhledávat konkrétní události protokolu, vlastní text protokolu nebo klíčová slova a filtrovat data protokolu na základě konkrétních polí. A co je nejdůležitější, agregujte data protokolu v rámci jednoho nebo více souborů protokolu, abyste mohli generovat souhrnné metriky a vizualizace.
Když spustíte dotaz, CloudWatch Log Insights prohledá data protokolu ve skupině protokolů. Poté vrátí texty ze souborů, které odpovídají kritériím vašeho dotazu.
Příklad dotazu na soubor protokolu
Pojďme se podívat na některé základní dotazy, abychom porozuměli konceptu.
Každá služba ve výchozím nastavení zaznamenává některé zásadní chyby služby. I když nevytvoříte vyhrazený vlastní protokol pro takové chybové události. Poté pomocí jednoduchého dotazu můžete spočítat počet chyb v protokolech vaší aplikace za poslední hodinu:
fields @timestamp, @message | filter @message like /ERROR/ | stats count() by bin(1h)
Nebo zde je návod, jak sledovat průměrnou dobu odezvy vašeho API za poslední den:
fields @timestamp, @message | filter @message like /API response time/ | stats avg(response_time) by bin(1d)
Vzhledem k tomu, že ve výchozím nastavení je využití CPU informacemi zaznamenanými službou do CloudWatch, můžete shromažďovat také tento typ metriky:
fields @timestamp, @message | filter @message like /CPUUtilization/ | stats avg(value) by bin(1h)
Tyto dotazy lze přizpůsobit tak, aby vyhovovaly vašemu konkrétnímu případu použití, a lze je použít k vytváření vlastních metrik a vizualizací v CloudWatch Dashboards. Způsob, jak to udělat, je umístit widget na řídicí panel a umístit kód do widgetu, aby bylo možné definovat, co vybrat.
Zde jsou některé z widgetů, které lze použít v CloudWatch Dashboards a vyplnit je obsahem z Log Insights:
- Textové widgety – Zobrazují textové informace, jako je výstup dotazu CloudWatch Insights.
- Moduly widget dotazu na protokol – Zobrazte výsledky dotazu protokolu CloudWatch Insights, jako je počet chyb v protokolech vaší aplikace.
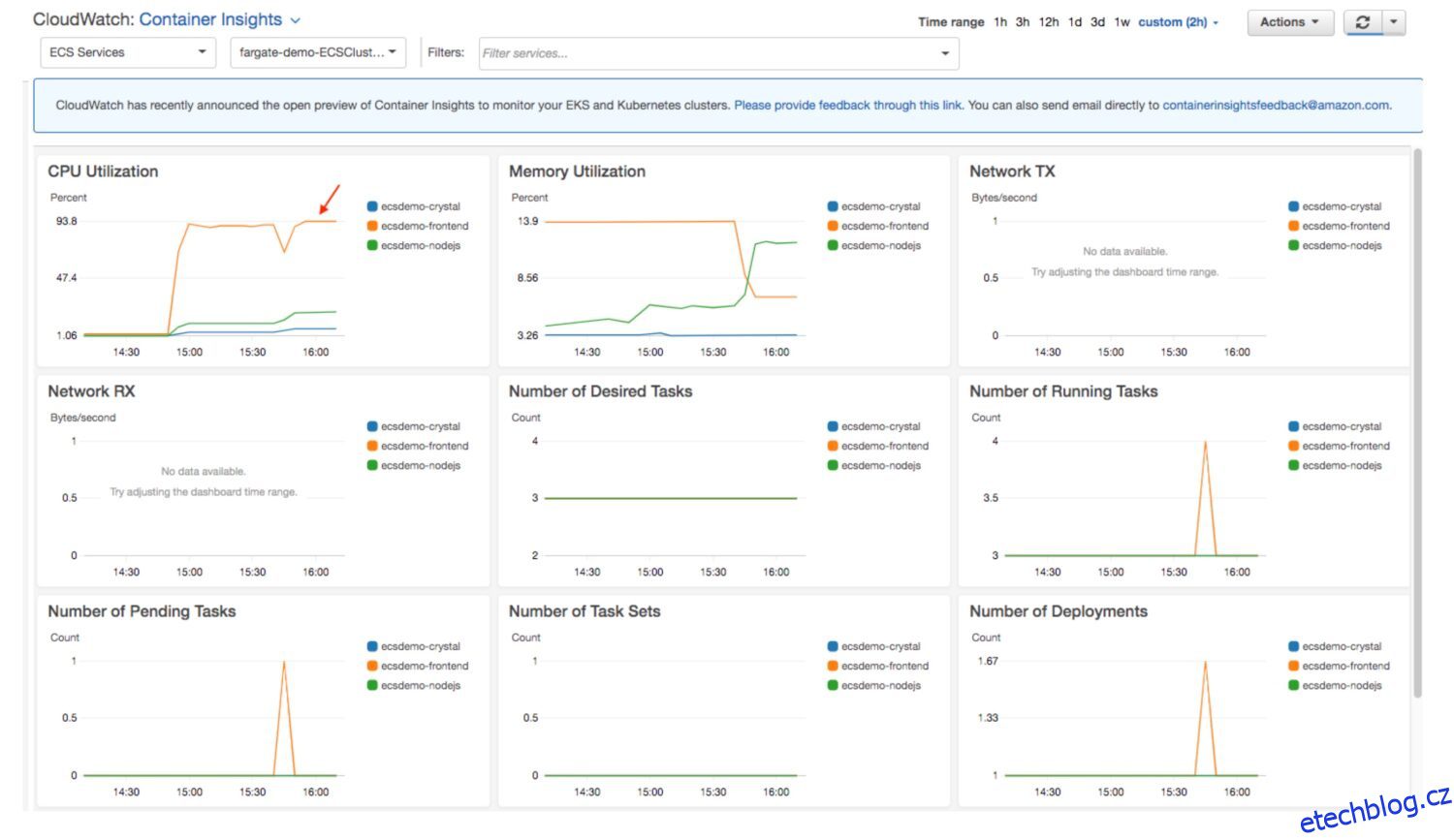
Jak vytvořit užitečné informace protokolu pro Dashboard
 Zdroj: aws.amazon.com
Zdroj: aws.amazon.com
Chcete-li efektivně využívat dotazy CloudWatch Insights v CloudWatch Dashboards, je dobré dodržovat některé osvědčené postupy při vytváření protokolů CloudWatch pro každou ze služeb, které ve svém systému používáte. Zde je několik tipů:
#1. Použijte strukturované protokolování
Musíte se držet formátu protokolování, který používá předdefinované schéma k protokolování dat ve strukturovaném formátu. To usnadňuje vyhledávání a filtrování dat protokolu pomocí dotazů CloudWatch Insights.
To v podstatě znamená standardizaci vašich protokolů napříč různými službami na platformě vaší architektury. To, že je definováno ve vývojových standardech, nesmírně pomáhá.
Můžete například definovat, že každý problém související s konkrétní databázovou tabulkou bude protokolován s počáteční zprávou jako: “[TABLE_NAME] Varování / Chyba:
Nebo můžete oddělit úlohy plných dat od úloh delta dat pomocí předpon jako „[FULL/DELTA]” pro výběr pouze zpráv souvisejících s konkrétními datovými procesy.
Můžete definovat, že při zpracování dat z konkrétního zdrojového systému bude název systému předponou každé související položky protokolu. Je mnohem snazší poté takové zprávy filtrovat ze souborů protokolu a vytvářet na nich metriky.
 Zdroj: aws.amazon.com
Zdroj: aws.amazon.com
#2. Používejte konzistentní formáty protokolů
Používejte konzistentní formáty protokolů ve všech svých zdrojích AWS, abyste si usnadnili vyhledávání a filtrování dat protokolů pomocí dotazů CloudWatch Insights.
To docela souvisí s předchozím bodem, ale faktem je, že čím standardizovanější je formát protokolu, tím snazší je použití dat protokolu. Vývojáři se pak mohou na tento formát spolehnout a používat jej dokonce intuitivně.
Krutým faktem je, že většina projektů se neobtěžuje žádnými standardy kolem těžby dřeva. A co víc, mnoho projektů dokonce nevytváří žádné vlastní protokoly. Je to šokující, ale zároveň tak běžné.
Ani nedokážu říct, kolikrát jsem se přistihl, že jsem přemýšlel, jak tady mohou lidé žít bez jakéhokoli přístupu k řešení chyb. A pokud se někdo pokusil provést nějakou výjimku zpracování chyb, udělal to špatně.
Konzistentní formát protokolu je tedy silnou výhodou. Málokdo je má.
#3. Zahrnout relevantní metadata
Zahrňte do dat protokolu metadata, jako jsou časová razítka, ID prostředků a kódy chyb, abyste usnadnili vyhledávání a filtrování dat protokolu pomocí dotazů CloudWatch Insights.
#4. Povolit rotaci protokolu
Povolte rotaci protokolů, abyste zabránili příliš velkému objemu dat protokolu a usnadnili vyhledávání a filtrování dat protokolů pomocí dotazů CloudWatch Insights.
Nemít žádná logová data je jedna věc, ale mít jich příliš mnoho bez struktury je podobně zoufalé. Pokud svá data nemůžete používat, je to jako byste neměli žádná data.
#5. Použijte CloudWatch Logs Agents
Pokud si nemůžete pomoct a prostě odmítáte sestavit svůj přizpůsobený log systém, použijte alespoň agenty CloudWatch Logs. Automaticky odesílají data protokolu z vašich zdrojů AWS do CloudWatch Logs. To usnadňuje vyhledávání a filtrování dat protokolu pomocí dotazů CloudWatch Insights.
Složitější příklady dotazů Insights
Dotaz CloudWatch Insights může být složitější než jen dvouřádkový příkaz.
fields @timestamp, @message | filter @message like /ERROR/ | filter @message not like /404/ | parse @message /.*[(?<timestamp>[^]]+)].*"(?<method>[^s]+)s+(?<path>[^s]+).*" (?<status>d+) (?<response_time>d+)/ | stats avg(response_time) as avg_response_time, count() as count by bin(1h), method, path, status | sort count desc | limit 20
Tento dotaz dělá následující:
Tento dotaz identifikuje nejčastější chyby ve vaší aplikaci a sleduje průměrnou dobu odezvy pro každou kombinaci metody HTTP, cesty a stavového kódu. Výsledky můžete použít k vytvoření vlastních metrik a vizualizací v CloudWatch Dashboards pro sledování výkonu vaší webové aplikace a odstraňování problémů.
Další příklad dotazování na zprávy služby Amazon S3:
fields @timestamp, @message | filter @message like /REST.API.REQUEST/ | parse @message /.*"(?<method>[^s]+)s+(?<path>[^s]+).*" (?<status>d+) (?<response_time>d+)/ | stats avg(response_time) as avg_response_time, count() as count by bin(1h), method, path, status | sort count desc | limit 20
- Dotaz vybere události protokolu, které obsahují řetězec „REST.API.REQUEST“.
- Poté analyzuje zprávu protokolu a extrahuje metodu HTTP, cestu, stavový kód a dobu odezvy.
- Vypočítá průměrnou dobu odezvy a počet událostí protokolu pro každou kombinaci metody HTTP, cesty a stavového kódu a seřadí výsledky podle počtu v sestupném pořadí.
- Omezí výstup na 20 nejlepších výsledků.
Výstup tohoto dotazu můžete použít k vytvoření spojnicového grafu v CloudWatch Dashboard, který ukazuje průměrnou dobu odezvy pro každou kombinaci metody HTTP, cesty a stavového kódu v průběhu času.
Sestavení Dashboardu
Chcete-li vyplnit metriky a vizualizace v CloudWatch Dashboards z výstupu dotazů protokolu CloudWatch Insights, můžete přejít do konzoly CloudWatch a podle průvodce Dashboard vytvořit svůj obsah.
Poté takto vypadá kód CloudWatch Dashboard a obsahuje metriky vyplněné daty CloudWatch Insights Query:
{
"widgets": [
{
"type": "metric",
"x": 0,
"y": 0,
"width": 12,
"height": 6,
"properties": {
"metrics": [
[
"AWS/EC2",
"CPUUtilization",
"InstanceId",
"i-0123456789abcdef0",
{
"label": "CPU Utilization",
"stat": "Average",
"period": 300
}
]
],
"view": "timeSeries",
"stacked": false,
"region": "us-east-1",
"title": "EC2 CPU Utilization"
}
},
{
"type": "log",
"x": 0,
"y": 6,
"width": 12,
"height": 6,
"properties": {
"query": "fields @timestamp, @message
| filter @message like /ERROR/
| stats count() by bin(1h)
",
"region": "us-east-1",
"title": "Application Errors"
}
}
]
}
Tento CloudWatch Dashboard obsahuje dva widgety:
Je to soubor ve formátu JSON s definicí řídicího panelu a metrikami uvnitř. Obsahuje (jako vlastnost) i samotný insight dotaz.
Můžete vzít kód a nasadit jej na jakýkoli účet AWS, který potřebujete. Za předpokladu, že služby a zprávy protokolu jsou konzistentní ve všech vašich účtech a fázích AWS, bude řídicí panel fungovat na všech účtech bez nutnosti měnit zdrojový kód řídicího panelu.
Závěrečná slova
Vybudování pevné logovací struktury bylo vždy dobrou investicí do budoucnosti spolehlivosti systému. Nyní může sloužit ještě většímu účelu. Jako vedlejší efekt můžete mít užitečné řídicí panely s metrikami a vizualizacemi.
Vývojový tým, testovací tým a produkční uživatelé mohou mít prospěch ze stejného řešení, protože je nutné provést pouze jednou a s trochou práce navíc.
Dále se podívejte na nejlepší monitorovací nástroje AWS.