
V průběhu let se používání pythonu pro datovou vědu neuvěřitelně rozrostlo a neustále roste každý den.
Datová věda je rozsáhlý studijní obor se spoustou dílčích oborů, z nichž analýza dat je bezpochyby jedním z nejdůležitějších ze všech těchto oborů, a bez ohledu na úroveň dovedností v datové vědě je stále důležitější porozumět nebo mít o něm alespoň základní znalosti.
Table of Contents
Co je analýza dat?
Analýza dat je čištění a transformace velkého množství nestrukturovaných nebo neorganizovaných dat s cílem generovat klíčové poznatky a informace o těchto datech, které by pomohly při přijímání informovaných rozhodnutí.
Pro analýzu dat se používají různé nástroje, Python, Microsoft Excel, Tableau, SaS atd., ale v tomto článku bychom se zaměřili na to, jak se analýza dat provádí v pythonu. Přesněji řečeno, jak se to dělá s knihovnou python s názvem pandy.
Co je to Pandas?
Pandas je open-source Python knihovna používaná pro manipulaci s daty a hádky. Je rychlý a vysoce efektivní a má nástroje pro načítání několika druhů dat do paměti. Lze jej použít k přetvoření, označení řezu, indexování nebo dokonce seskupení několika forem dat.
Datové struktury v Pandas
V Pandas jsou 3 datové struktury, jmenovitě;
Nejlepší způsob, jak rozlišit tři z nich, je vidět jeden jako obsahující několik hromádek druhého. DataFrame je tedy zásobník sérií a Panel je zásobník datových rámců.
Řada je jednorozměrné pole
Zásobník několika sérií tvoří 2-rozměrný DataFrame
Stack několika DataFrames vytváří 3-rozměrný panel
Datová struktura, se kterou bychom nejvíce pracovali, je 2-rozměrný DataFrame, který může být také výchozím prostředkem reprezentace některých datových sad, se kterými se můžeme setkat.
Analýza dat v Pandas
Pro tento článek není nutná žádná instalace. Použili bychom nástroj tzv kolaborativní vytvořený společností Google. Jedná se o online prostředí pythonu pro analýzu dat, strojové učení a AI. Je to jednoduše cloudový Jupyter Notebook, který je dodáván s předinstalovaným téměř každým balíčkem pythonu, který byste jako datový vědec potřebovali.
Teď jdi do toho https://colab.research.google.com/notebooks/intro.ipynb. Měli byste vidět níže uvedené.
V navigaci vlevo nahoře klikněte na možnost souboru a klikněte na možnost „nový zápisník“. Ve vašem prohlížeči by se načetla nová stránka poznámkového bloku Jupyter. První věc, kterou musíme udělat, je importovat pandy do našeho pracovního prostředí. Můžeme to udělat spuštěním následujícího kódu;
import pandas as pd
Pro tento článek bychom pro analýzu dat použili datový soubor o cenách bydlení. Dataset, který bychom použili, lze nalézt tady. První věc, kterou bychom chtěli udělat, je načíst tuto datovou sadu do našeho prostředí.
Můžeme to udělat pomocí následujícího kódu v nové buňce;
df = pd.read_csv('https://firebasestorage.googleapis.com/v0/b/ai6-portfolio-abeokuta.appspot.com/o/kc_house_data.csv?alt=media &token=6a5ab32c-3cac-42b3-b534-4dbd0e4bdbc0 ', sep=',')
Soubor .read_csv se používá, když chceme číst soubor CSV a předali jsme vlastnost sep, která ukazuje, že soubor CSV je oddělený čárkami.
Měli bychom také poznamenat, že náš načtený soubor CSV je uložen v proměnné df .
V Jupyter Notebooku nepotřebujeme používat funkci print(). Stačí jednoduše zadat název proměnné do naší buňky a Jupyter Notebook nám ji vytiskne.
Můžeme to vyzkoušet zadáním df do nové buňky a jejím spuštěním, vytiskne nám všechna data v naší datové sadě jako DataFrame.
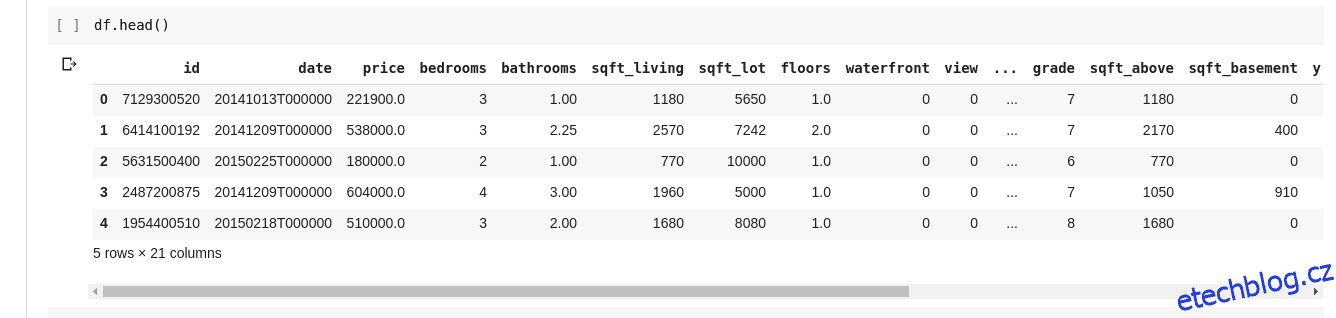
Ale nechceme vždy vidět všechna data, občas chceme vidět jen prvních pár dat a jejich názvy sloupců. Pro tisk prvních pěti sloupců můžeme použít funkci df.head() a pro tisk posledních pěti sloupců df.tail(). Výstup jednoho z těchto dvou by vypadal jako takový;
Chtěli bychom zkontrolovat vztahy mezi těmito několika řádky a sloupci dat. Funkce .describe() dělá přesně toto za nás.
Spuštěním df.describe() získáte následující výstup;
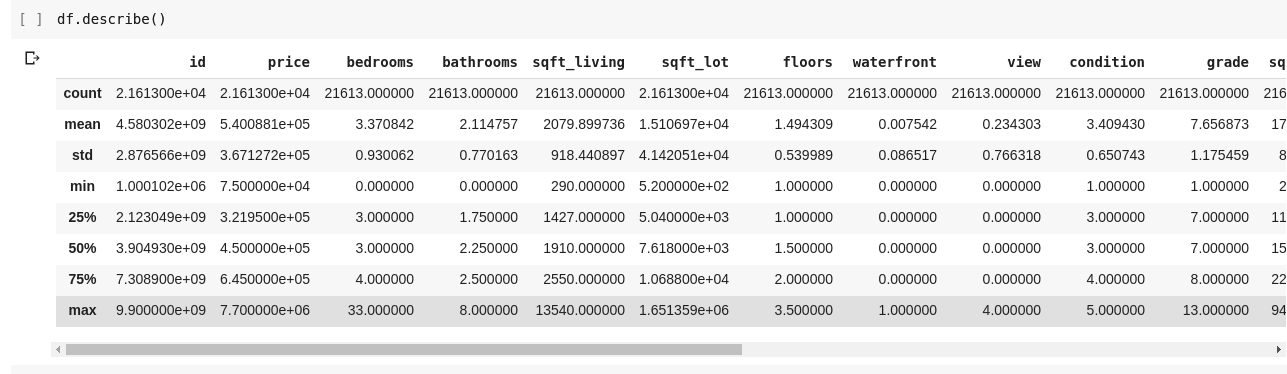
Okamžitě vidíme, že .describe() udává průměr, standardní odchylku, minimální a maximální hodnoty a percentily každého sloupce v DataFrame. To je zvláště užitečné.
Můžeme také zkontrolovat tvar našeho 2D DataFrame, abychom zjistili, kolik má řádků a sloupců. Můžeme to udělat pomocí df.shape, který vrací n-tici ve formátu (řádky, sloupce).
Můžeme také zkontrolovat názvy všech sloupců v našem DataFrame pomocí df.columns.
Co když chceme vybrat pouze jeden sloupec a vrátit všechna data v něm? To se provádí podobným způsobem jako procházení slovníkem. Zadejte následující kód do nové buňky a spusťte ji
df['price ']
Výše uvedený kód vrací sloupec ceny, můžeme jít dále uložením do nové proměnné jako takové
price = df['price']
Nyní můžeme provést každou další akci, kterou lze provést na DataFrame na naší cenové proměnné, protože je to jen podmnožina skutečného DataFrame. Můžeme dělat věci jako df.head(), df.shape atd..
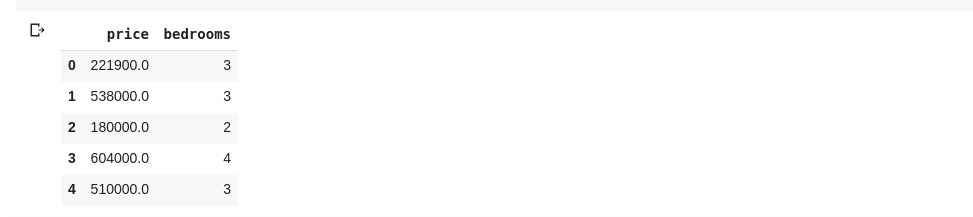
Mohli bychom také vybrat více sloupců předáním seznamu názvů sloupců do df jako takového
data = df[['price ', 'bedrooms']]
Výše uvedené vybírá sloupce s názvy ‚cena‘ a ‚ložnice‘, pokud do nové buňky zadáme data.head(), měli bychom následující
Výše uvedený způsob dělení sloupců vrací všechny prvky řádků v tomto sloupci, co když chceme vrátit podmnožinu řádků a podmnožinu sloupců z naší datové sady? To lze provést pomocí .iloc a indexuje se podobným způsobem jako seznamy python. Takže můžeme udělat něco takového
df.iloc[50: , 3]
Což vrátí 3. sloupec od 50. řádku do konce. Je to docela úhledné a stejné jako krájení seznamů v pythonu.
Nyní udělejme opravdu zajímavé věci, naše datová sada o cenách bydlení má sloupec, který nám říká cenu domu, a další sloupec nám říká počet ložnic, které konkrétní dům má. Cena bydlení je kontinuální hodnota, takže je možné, že nemáme dva domy, které mají stejnou cenu. Ale počet ložnic je poněkud diskrétní, takže můžeme mít několik domů se dvěma, třemi, čtyřmi ložnicemi atd.
Co když chceme získat všechny domy se stejným počtem ložnic a zjistit průměrnou cenu každé samostatné ložnice? U pand je to relativně snadné, lze to udělat jako takové;
df.groupby('bedrooms ')['price '].mean()
Výše uvedené nejprve seskupuje DataFrame podle datových sad s identickým číslem ložnice pomocí funkce df.groupby() a poté mu řekneme, aby nám poskytl pouze sloupec ložnice a pomocí funkce .mean() nalezl průměr každého domu v datové sadě. .
Co když si chceme výše uvedené vizualizovat? Chtěli bychom být schopni zkontrolovat, jak se liší průměrná cena každého jednotlivého čísla ložnice? Potřebujeme pouze zřetězit předchozí kód s funkcí .plot() jako takovou;
df.groupby('bedrooms ')['price '].mean().plot()
Budeme mít výstup, který tak vypadá;
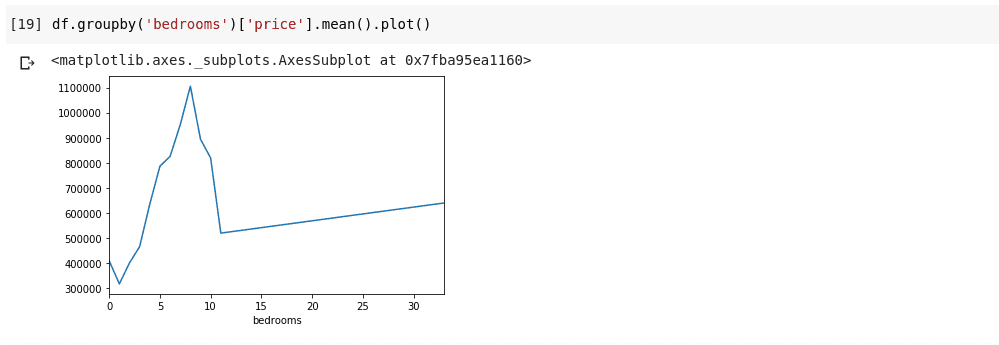
Výše uvedené nám ukazuje některé trendy v datech. Na vodorovné ose máme zřetelný počet ložnic (všimněte si, že více než jeden dům může mít X ložnic), na svislé ose máme průměr cen vzhledem k odpovídajícímu počtu ložnic na vodorovné osa. Nyní si můžeme okamžitě všimnout, že domy, které mají 5 až 10 pokojů, stojí mnohem více než domy se 3 ložnicemi. Bude také zřejmé, že domy, které mají asi 7 nebo 8 pokojů, stojí mnohem více než domy s 15, 20 nebo dokonce 30 pokoji.
Informace, jako jsou výše uvedené, jsou důvodem, proč je analýza dat velmi důležitá, z dat jsme schopni vytěžit užitečné poznatky, kterých si bez analýzy nelze okamžitě nebo zcela všimnout.
Chybějící data
Předpokládejme, že dělám průzkum, který se skládá ze série otázek. Sdílím odkaz na průzkum s tisíci lidmi, aby mohli poskytnout zpětnou vazbu. Mým konečným cílem je provést analýzu dat na těchto datech, abych z nich mohl získat některé klíčové poznatky.
Teď se může hodně pokazit, někteří zeměměřiči se mohou cítit nepohodlně odpovídat na některé mé otázky a nechat to prázdné. Mnoho lidí by totéž mohlo udělat pro několik částí mých otázek v průzkumu. To nemusí být považováno za problém, ale představte si, že bych ve svém průzkumu sbíral číselná data a část analýzy by vyžadovala, abych získal buď součet, průměr nebo nějakou jinou aritmetickou operaci. Několik chybějících hodnot by vedlo k mnoha nepřesnostem v mé analýze, musím vymyslet způsob, jak tyto chybějící hodnoty najít a nahradit nějakými hodnotami, které by je mohly být blízkou náhradou.
Pandy nám poskytují funkci k nalezení chybějících hodnot v DataFrame s názvem isnull().
Funkci isnull() lze použít jako takovou;
df.isnull()
To vrátí DataFrame booleanů, které nám sdělují, zda zde původně přítomná data skutečně chyběla nebo chybně chyběla. Výstup by tak vypadal;
Potřebujeme způsob, jak všechny tyto chybějící hodnoty nahradit, nejčastěji lze volbu chybějících hodnot brát jako nulovou. Někdy to může být považováno za průměr všech ostatních dat nebo možná průměr dat kolem nich, v závislosti na datovém vědci a případu použití analyzovaných dat.
K vyplnění všech chybějících hodnot v DataFrame používáme funkci .fillna() používanou jako takovou;
df.fillna(0)
Ve výše uvedeném vyplňujeme všechna prázdná data hodnotou nula. Může to být i jakékoli jiné číslo, které určíme.
Důležitost dat nemůže být přehnaně zdůrazňována, pomáhá nám získat odpovědi přímo z našich dat samotných!. Analýza dat je podle nich nová ropa pro digitální ekonomiky.
Všechny příklady v tomto článku naleznete tady.
Chcete-li se dozvědět více do hloubky, podívejte se Online kurz Analýza dat s Pythonem a Pandas.