
Apache Parquet poskytuje několik výhod pro ukládání a načítání dat ve srovnání s tradičními metodami, jako je CSV.
Formát parket je určen pro rychlejší zpracování dat složitých typů. V tomto článku mluvíme o tom, jak je formát Parquet vhodný pro dnešní stále rostoucí potřeby dat.
Než se ponoříme do podrobností o formátu Parquet, pochopme, co jsou data CSV a jaké problémy představují pro ukládání dat.
Table of Contents
Co je úložiště CSV?
Všichni jsme toho hodně slyšeli o CSV (Comma Separated Values) – jednom z nejběžnějších způsobů organizace a formátování dat. Ukládání dat CSV je založené na řádcích. Soubory CSV jsou uloženy s příponou .csv. Data CSV můžeme ukládat a otevírat pomocí Excelu, Tabulek Google nebo jakéhokoli textového editoru. Data jsou snadno zobrazitelná po otevření souboru.
No, to není dobré – rozhodně ne pro databázový formát.
Dále, jak objem dat roste, je obtížné dotazovat se, spravovat a získávat.
Zde je příklad dat uložených v souboru .CSV:
EmpId,First name,Last name, Division 2012011,Sam,Butcher,IT 2013031,Mike,Johnson,Human Resource 2010052,Bill,Matthew,Architect 2010079,Jose,Brian,IT 2012120,Adam,James,Solutions
Pokud jej zobrazíme v aplikaci Excel, můžeme vidět strukturu řádků a sloupců, jak je uvedeno níže:
Výzvy s úložištěm CSV
Úložiště založená na řádcích, jako je CSV, jsou vhodná pro operace vytvoření, aktualizace a odstranění.
Co tedy Read in CRUD?
Představte si milion řádků ve výše uvedeném souboru .csv. Otevření souboru a vyhledání dat, která hledáte, by zabralo přiměřenou dobu. Ne tak cool. Většina poskytovatelů cloudu, jako je AWS, účtuje společnostem poplatky na základě množství naskenovaných nebo uložených dat – soubory CSV opět zabírají spoustu místa.
Úložiště CSV nemá exkluzivní možnost ukládat metadata, takže skenování dat je zdlouhavý úkol.
Jaké je tedy nákladově efektivní a optimální řešení pro provádění všech operací CRUD? Pojďme prozkoumat.
Co je úložiště dat parket?
Parkety je formát úložiště s otevřeným zdrojovým kódem pro ukládání dat. Je široce používán v ekosystémech Hadoop a Spark. Soubory parket jsou uloženy jako přípona .parquet.
Parkety jsou vysoce strukturovaný formát. Může být také použit k optimalizaci komplexních hrubých dat přítomných hromadně v datových jezerech. To může výrazně zkrátit dobu dotazování.
Parquet umožňuje efektivní ukládání dat a rychlejší načítání díky kombinaci řádkových a sloupcových (hybridních) formátů úložiště. V tomto formátu jsou data rozdělena horizontálně i vertikálně. Formát parket také do značné míry eliminuje režii analýzy.
Formát omezuje celkový počet I/O operací a v konečném důsledku i náklady.
Parquet také ukládá metadata, která ukládají informace o datech, jako je datové schéma, počet hodnot, umístění sloupců, minimální hodnota, maximální hodnota, počet skupin řádků, typ kódování atd. Metadata jsou v souboru uložena na různých úrovních. , což zrychluje přístup k datům.
V přístupu založeném na řádcích, jako je CSV, trvá načítání dat čas, protože dotaz musí procházet každý řádek a získat hodnoty konkrétního sloupce. S úložištěm parket lze najednou přistupovat ke všem požadovaným sloupům.
Celkem,
- Parkety jsou založeny na sloupcové struktuře pro ukládání dat
- Jedná se o optimalizovaný datový formát pro hromadné ukládání složitých dat v úložných systémech
- Parketový formát zahrnuje různé metody pro kompresi a kódování dat
- Výrazně snižuje dobu skenování dat a dobu dotazování a zabírá méně místa na disku ve srovnání s jinými formáty úložiště, jako je CSV
- Minimalizuje počet operací IO, snižuje náklady na úložiště a provádění dotazů
- Obsahuje metadata, která usnadňují vyhledávání dat
- Poskytuje podporu open source
Formát dat parket
Než přejdeme k příkladu, pochopme podrobněji, jak jsou data uložena ve formátu Parquet:
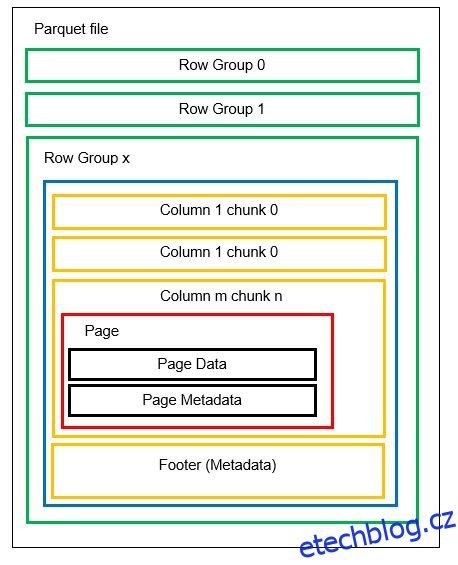
V jednom souboru můžeme mít více horizontálních oddílů známých jako skupiny řádků. V každé skupině řádků se použije vertikální rozdělení. Sloupce jsou rozděleny do několika částí. Data jsou uložena jako stránky uvnitř bloků sloupců. Každá stránka obsahuje zakódované datové hodnoty a metadata. Jak jsme již zmínili, metadata pro celý soubor jsou také uložena v zápatí souboru na úrovni skupiny řádků.
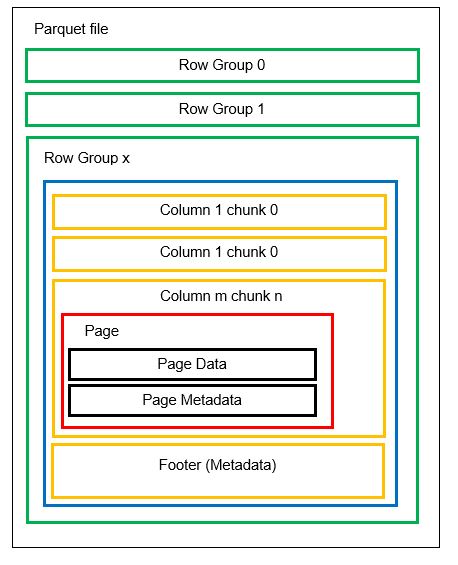
Protože jsou data rozdělena na části sloupců, je také snadné přidat nová data zakódováním nových hodnot do nového bloku a souboru. Metadata se poté aktualizují pro dotčené soubory a skupiny řádků. Můžeme tedy říci, že parkety jsou flexibilní formát.
Parquet nativně podporuje kompresi dat pomocí technik komprese stránek a slovníkového kódování. Podívejme se na jednoduchý příklad komprese slovníku:
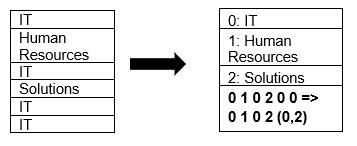
Všimněte si, že ve výše uvedeném příkladu vidíme oddělení IT 4krát. Takže při ukládání do slovníku formát zakóduje data další snadno uložitelnou hodnotou (0,1,2…) spolu s počtem opakování nepřetržitě – IT, IT se změní na 0,2 pro uložení více místa. Dotazování na komprimovaná data trvá méně času.
Vzájemné srovnání
Nyní, když máme reálnou představu o tom, jak formáty CSV a Parquet vypadají, je čas na statistiku, která oba formáty porovná:
CSV
Parkety
Formát úložiště založený na řádcích.
Kříženec řádkových a sloupcových formátů úložiště.
Zabírá hodně místa, protože není k dispozici žádná výchozí možnost komprese. Například 1TB soubor zabere stejné místo, když je uložen na Amazon S3 nebo jiném cloudu.
Při ukládání komprimuje data, čímž spotřebovává méně místa. Soubor o velikosti 1 TB uložený ve formátu Parquet zabere pouze 130 GB místa.
Doba běhu dotazu je pomalá kvůli hledání na základě řádků. Pro každý sloupec je třeba načíst každý řádek dat.
Doba dotazování je asi 34krát rychlejší kvůli ukládání založenému na sloupcích a přítomnosti metadat.
Na jeden dotaz je třeba naskenovat více dat.
Pro provedení dotazu se skenuje o 99 % méně dat, čímž se optimalizuje výkon.
Většina úložných zařízení se účtuje podle úložného prostoru, takže formát CSV znamená vysoké náklady na úložiště.
Nižší náklady na úložiště, protože data jsou uložena v komprimovaném zakódovaném formátu.
Schéma souboru je třeba buď odvodit (což vede k chybám) nebo dodat (zdlouhavé).
Schéma souboru je uloženo v metadatech.
Formát je vhodný pro jednoduché datové typy.
Parkety jsou vhodné i pro složité typy, jako jsou vnořená schémata, pole, slovníky.
Závěr 👩💻
Na příkladech jsme viděli, že parkety jsou efektivnější než CSV z hlediska nákladů, flexibility a výkonu. Je to účinný mechanismus pro ukládání a získávání dat, zvláště když celý svět směřuje k cloudovému úložišti a optimalizaci prostoru. Všechny hlavní platformy jako Azure, AWS a BigQuery podporují formát Parquet.