
Označování dat je důležité pro trénování modelů strojového učení, které se používají k rozhodování na základě vzorů a trendů v datech.
Podívejme se, o čem toto označování dat je a jaké jsou různé nástroje k jeho provedení.
Table of Contents
Co je označování dat?
Označování dat je proces přiřazování popisných značek nebo štítků k datům, které je pomáhají identifikovat a kategorizovat. Zahrnuje různé typy dat, jako je text, obrázky, videa, zvuk a další formy nestrukturovaných dat. Označená data se pak použijí k trénování algoritmů strojového učení k identifikaci vzorů a vytváření předpovědí.
Přesnost a kvalita značení může výrazně ovlivnit výkon modelů ML. Může to být provedeno ručně lidmi nebo pomocí automatizačních nástrojů. Hlavním účelem označování dat je transformovat nestrukturovaná data do strukturovaného formátu, který mohou stroje snadno pochopit a analyzovat.
Dobrým příkladem označování dat může být v kontextu rozpoznávání obrazu. Řekněme, že chcete trénovat model strojového učení, aby rozpoznával kočky a psy na obrázcích.
Chcete-li tak učinit, nejprve byste museli označit sadu obrázků jako „kočka“ nebo „pes“, aby se model mohl z těchto označených příkladů poučit. Proces přiřazování těchto štítků k obrázkům se nazývá označování dat.
Anotátor by si prohlédl každý obrázek a ručně mu přiřadil příslušné označení, čímž by vytvořil označenou datovou sadu, kterou lze použít k trénování modelu strojového učení.
Jak to funguje?
Provádění označování dat zahrnuje různé kroky. Patří sem:
Sběr dat
Prvním krokem v procesu označování dat je shromáždit data, která je třeba označit. To může zahrnovat různé typy dat, jako jsou obrázky, text, zvuk nebo video.
Pokyny pro označování
Jakmile jsou data shromážděna, vytvoří se pokyny pro označování, které specifikují štítky nebo štítky, které budou přiřazeny k datům. Tyto pokyny pomáhají zajistit, aby označené údaje byly relevantní pro současnou činnost v oblasti praní peněz, a zachovat konzistentnost při označování.
Anotace
Vlastní označování dat je prováděno anotátory nebo štítkovateli, kteří jsou vyškoleni k aplikaci pokynů pro označování dat. To lze provést ručně lidmi nebo prostřednictvím automatizovaných procesů pomocí předem definovaných pravidel a algoritmů.
Kontrola kvality
Jsou zavedena opatření kontroly kvality s cílem zlepšit přesnost označených údajů. To zahrnuje metriku IAA, kde několik anotátorů označuje stejná data a jejich označování je porovnáváno kvůli kontrole konzistence a zajištění kvality, aby se opravily chyby v označení.
Integrace s modely strojového učení
Jakmile jsou data označena a jsou implementována opatření kontroly kvality, mohou být označená data integrována s modely strojového učení, aby se trénovala a zlepšila jejich přesnost.
Různé přístupy k označování dat
Označování dat lze provádět různými způsoby, z nichž každý má své výhody a nevýhody. Některé běžné metody zahrnují:
#1. Ruční značení
Jedná se o tradiční techniku označování dat, ve které jednotlivci ručně anotují data. Data jsou zkontrolována anotátorem, který k nim následně v souladu se standardními postupy přidává štítky nebo štítky.
#2. Polodozorované značení
Jedná se o kombinaci ručního a automatického označování. Menší část dat je ručně kategorizována a štítky se pak používají k trénování modelu strojového učení, který dokáže automaticky označit zbývající data. Tento přístup nemusí být tak přesný jako ruční označování, ale je efektivnější.
#3. Aktivní učení
Jedná se o iterativní přístup k označování dat, kdy model strojového učení identifikuje datové body, o kterých je nejistý, a žádá člověka, aby je označil.
#4. Přenést učení
Tato metoda využívá již existující označená data z aktivity nebo domény, která souvisí s trénováním modelu pro aktuální úlohu. Pokud projekt nemá dostatek označených dat, může být tato metoda užitečná.
#5. Crowdsourcing
Zahrnuje outsourcing úkolu označování velké skupině lidí prostřednictvím online platformy. Crowdsourcing může být nákladově efektivní způsob, jak rychle označit velké množství dat, ale může být obtížné ověřit přesnost a konzistenci.
#6. Označování založené na simulaci
Tento přístup zahrnuje použití počítačových simulací ke generování označených dat pro konkrétní úkol. To může být užitečné, když je obtížné získat reálná data nebo když je potřeba rychle generovat velké množství označených dat.
Každá metoda má své silné a slabé stránky. Záleží na konkrétních požadavcích projektu a cílech úkolu označování.
Běžné typy označování dat

- Označení obrázku
- Označování videa
- Zvukové značení
- Textové označení
- Označení snímače
- 3D značení
Pro různé typy dat a úkolů se používají různé typy označení dat.
Například popisování obrázků se běžně používá pro detekci objektů, zatímco popisování textu se používá pro úlohy zpracování přirozeného jazyka.
Zvukové značení lze použít pro rozpoznávání řeči nebo detekci emocí a značení senzorů lze použít pro aplikace internetu věcí (IoT).
3D označování se využívá pro úkoly, jako je vývoj autonomních vozidel nebo aplikace virtuální reality.
Osvědčené postupy pro označování dat

#1. Definujte jasné pokyny
Měly by být stanoveny jasné pokyny pro označování údajů. Tyto pokyny by měly obsahovat definice štítků, příklady použití štítků a pokyny, jak řešit nejednoznačné případy.
#2. Použijte více anotátorů
Přesnost lze zlepšit, když různí anotátoři označí stejná data. Metriky shody mezi anotátory (IAA) lze použít k posouzení úrovně shody mezi různými anotátory.
#3. Použijte standardizovaný proces
Pro označování dat by měl být dodržován definovaný proces, aby byla zajištěna konzistence mezi různými anotátory a úkoly označování. Tento proces by měl zahrnovat proces přezkoumání ke kontrole kvality označených údajů.
#4. Kontrola kvality
Opatření kontroly kvality, jako jsou pravidelné kontroly, křížové kontroly a vzorkování údajů, jsou zásadní pro zajištění přesnosti a spolehlivosti označených údajů.
#5. Označte různá data
Při výběru dat k označení je důležité zvolit různorodý vzorek, který představuje celou škálu dat, se kterými bude model pracovat. To může zahrnovat data z různých zdrojů s různými charakteristikami a pokrývající širokou škálu scénářů.
#6. Monitorujte a aktualizujte štítky
Jak se model strojového učení zlepšuje, může být nutné aktualizovat a upřesnit označená data. Je důležité sledovat jeho výkon a podle potřeby aktualizovat štítky.
Případy užití
Označování dat je kritickým krokem v projektech strojového učení a analýzy dat. Zde jsou některé běžné případy použití označování dat:
- Rozpoznávání obrazu a videa
- Zpracování přirozeného jazyka
- Autonomní vozidla
- Odhalování podvodů
- Analýza sentimentu
- Lékařská diagnóza
Toto je jen několik příkladů použití pro označování dat. Jakákoli aplikace strojového učení nebo analýzy dat, která zahrnuje klasifikaci nebo predikci, může mít prospěch z použití označených dat.
Na internetu je k dispozici mnoho nástrojů pro označování dat, z nichž každý má vlastní sadu funkcí a možností. A zde jsme shrnuli seznam nejlepších nástrojů pro označování dat.
Label Studio
Label Studio je open-source nástroj pro označování dat vyvinutý společností Heartex, který poskytuje řadu anotačních rozhraní pro textová, obrazová, zvuková a video data. Tento nástroj je známý pro svou flexibilitu a snadné použití.
Je navržen tak, aby byl rychle instalovatelný a lze jej použít k vytváření vlastních uživatelských rozhraní nebo předem vytvořených šablon štítků. To uživatelům usnadňuje vytváření vlastních úloh a pracovních postupů anotací pomocí rozhraní přetahování.

Label Studio také poskytuje řadu možností integrace, včetně webhooků, sady Python SDK a rozhraní API, což uživatelům umožňuje hladce integrovat nástroj do jejich kanálů ML/AI.
Vychází ve dvou edicích – Community a Enterprise.
Komunitní edice je zdarma ke stažení a může ji používat kdokoli. Má základní funkce a podporuje omezený počet uživatelů a projektů. Zatímco Enterprise Edition je placená verze, která podporuje větší týmy a složitější případy použití.
Krabice se štítky
Label box je cloudová platforma pro označování dat, která poskytuje výkonnou sadu nástrojů pro správu dat, označování dat a strojové učení. Jednou z klíčových výhod Labelboxu jsou jeho možnosti označování pomocí AI, které pomáhají urychlit proces označování dat a zlepšit přesnost označování.

Nabízí přizpůsobitelný datový engine, který je navržen tak, aby pomáhal týmům pro datovou vědu rychle a efektivně vytvářet vysoce kvalitní tréninková data pro modely strojového učení.
Klíčové laboratoře
Keylabs je další vynikající platforma pro označování dat, která nabízí pokročilé funkce a systémy správy pro poskytování vysoce kvalitních anotačních služeb. Keylabs lze nastavit a podporovat lokálně a ke každému jednotlivému projektu nebo přístupu k platformě lze obecně přiřadit uživatelské role a oprávnění.
Má zkušenosti s manipulací s velkými datovými soubory, aniž by byla ohrožena účinnost nebo přesnost. Podporuje různé funkce anotací, jako je pořadí vykreslování, vztahy rodič/dítě, časové osy objektů, jedinečná vizuální identita a vytváření metadat.
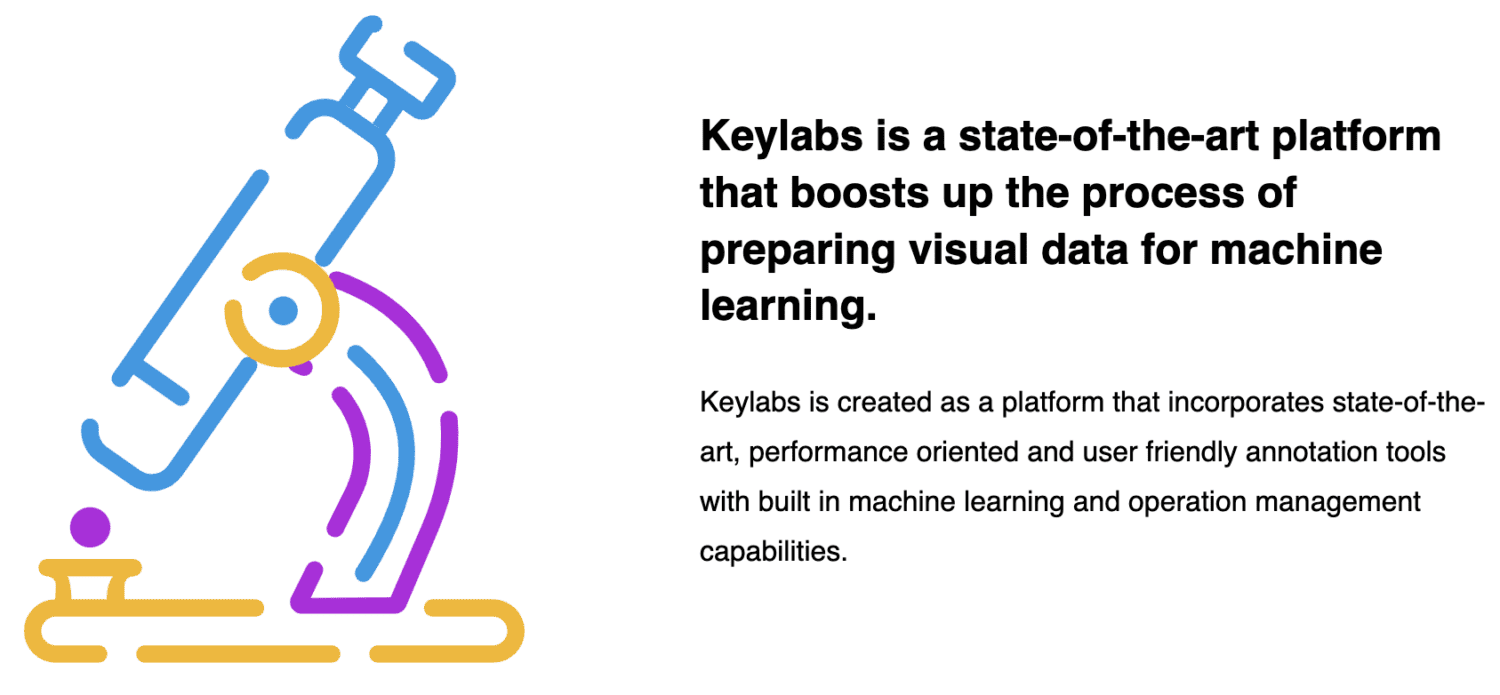
Další klíčovou vlastností KeyLabs je podpora pro týmové řízení a spolupráci. Nabízí řízení přístupu na základě rolí, monitorování aktivity v reálném čase a vestavěné nástroje pro zasílání zpráv a zpětnou vazbu, které pomáhají týmům efektivněji spolupracovat.
Na platformu lze také nahrát stávající anotace. Keylabs je ideální pro jednotlivce a výzkumníky, kteří hledají rychlý, efektivní a flexibilní nástroj pro označování dat.
Amazon SageMaker Ground Truth
Amazon SageMaker Ground Truth je plně spravovaná služba označování dat poskytovaná službou Amazon Web Services (AWS), která pomáhá organizacím vytvářet vysoce přesné školicí datové sady pro modely strojového učení.
Nabízí řadu funkcí, jako je automatické označování dat, vestavěné pracovní postupy a řízení pracovní síly v reálném čase, aby byl proces označování rychlejší a efektivnější.

Jednou z klíčových funkcí SageMakeru je schopnost vytvářet vlastní pracovní postupy, které lze přizpůsobit konkrétním úkolům štítkování. To může pomoci snížit čas a náklady potřebné k označení velkého množství dat.
Kromě toho nabízí vestavěný systém řízení pracovní síly, který uživatelům umožňuje snadno spravovat a škálovat jejich úkoly v oblasti štítkování. Je navržen tak, aby byl škálovatelný a přizpůsobitelný, což z něj dělá oblíbenou volbu pro datové vědce a inženýry strojového učení.
Závěr
Doufám, že vám tento článek pomohl při učení se o označování dat a jeho nástrojích. Možná vás také bude zajímat informace o zjišťování dat, abyste našli cenné a skryté vzorce v datech.