
Prometheus je open source monitorovací systém založený na metrikách. Shromažďuje data ze služeb a hostitelů odesíláním požadavků HTTP na koncové body metrik. Výsledky pak ukládá do databáze časových řad a zpřístupňuje je pro analýzu a upozornění.
Table of Contents
Proč monitorovat?
- Umožňuje upozornění, když se něco pokazí, nejlépe ještě předtím, než se pokazí. Aby se na to někdo mohl podívat.
- Poskytuje přehled umožňující analýzu, ladění a řešení problému.
- Umožňuje vám vidět trendy/změny v čase. Například kolik aktivních relací v daný čas. To pomáhá při rozhodování o návrhu a plánování kapacity.
Monitorování se obvykle týká událostí. Událost může zahrnovat přijetí požadavku HTTP, odeslání odpovědi, čtení z disku, přihlášení uživatele. Monitorování systému může zahrnovat profilování, protokolování, sledování, metriky, upozornění a vizualizaci.
Monitoring Blackbox vs. Whitebox
Monitoring spadá do dvou hlavních kategorií:
Monitoring blackboxu
Při sledování Blackbox je sledování na úrovni aplikace nebo hostitele, jak jsou pozorováni zvenčí. To může být dost omezující.
Monitoring whiteboxu
Monitoring whitebox znamená monitorování vnitřností služby. Odhalila by data o stavu a výkonu vnitřních součástí.
Čtyři zlaté signály
Podle Googlepokud můžete měřit pouze čtyři metriky svého uživatelského systému, zaměřte se na následující čtyři, nazývané čtyři zlaté signály:
#1. Latence
Doba potřebná k vyřízení požadavku – úspěšné nebo neúspěšné. Je důležité sledovat nejen úspěšné požadavky, ale i ty neúspěšné.
#2. Provoz
Míra toho, jak velká poptávka je kladena na váš systém. U webové služby jsou to obvykle požadavky HTTP za sekundu.
#3. Chyby
Míra neúspěšných žádostí.
#4. Nasycení
Jak plné jsou vaše služby. Zvýšení latence je často důležitým indikátorem saturace. Mnoho systémů degraduje výkon mnohem dříve, než dosáhnou 100% využití.
Typy metrik Prometheus
Metriky Prometheus jsou čtyř hlavních typů:
#1. Čelit
Hodnota počítadla se vždy zvýší. Nikdy se nemůže snížit, ale může být resetován na nulu. Takže pokud seškrábnutí selže, znamená to pouze zmeškaný datový bod. Kumulativní nárůst bude k dispozici při příštím čtení. Příklady:
- Celkový počet přijatých požadavků HTTP
- Počet výjimek.
#2. Měřidlo
Měřidlo je snímek v jakémkoli daném časovém okamžiku. Může se jak zvýšit, tak snížit. Pokud selže načítání dat, ztratíte vzorek; další načtení může ukázat jinou hodnotu: příklady místa na disku, využití paměti.
#3. Histogram
Histogram vzorkuje pozorování a počítá je do konfigurovatelných segmentů. Používají se pro věci, jako je trvání požadavku nebo velikosti odpovědí. Můžete například měřit dobu trvání požadavku pro konkrétní požadavek HTTP. Histogram bude mít sadu segmentů, řekněme 1 ms, 10 ms a 25 ms. Namísto ukládání každé doby trvání pro každý požadavek bude Prometheus ukládat frekvenci požadavků, které spadají do konkrétního segmentu.
#4. souhrn
Podobně jako u pozorování vzorků histogramu, obvykle vyžadují trvání nebo velikosti odezvy. Poskytne celkový počet pozorování a součet všech pozorovaných hodnot, což vám umožní vypočítat průměr pozorovaných hodnot. Například během jedné minuty jste měli tři požadavky, které trvaly 2, 3, 4 sekundy. Součet by byl 9 a počet by byl 3. Latence by byla 3 sekundy.
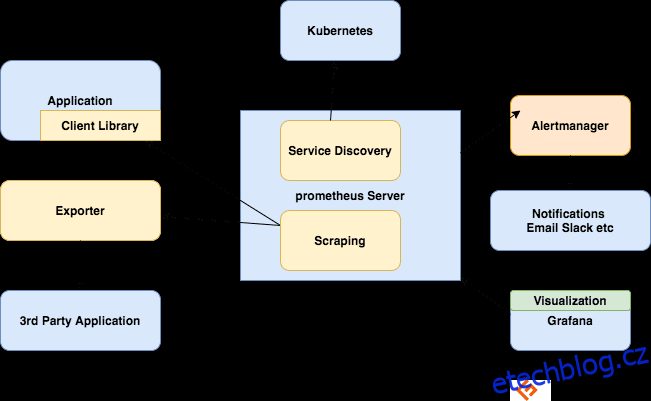
Složky ekosystému Prometheus
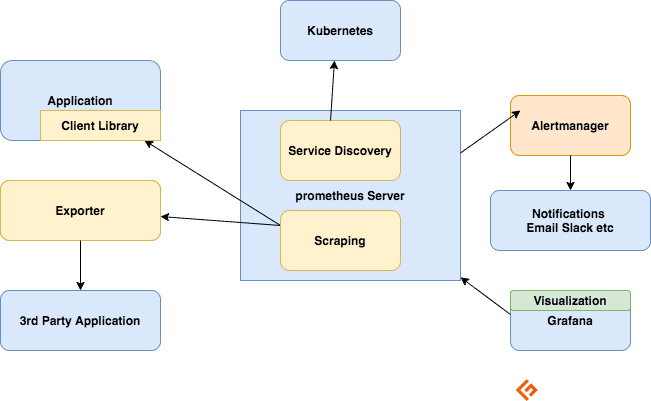
Server Prometheus
Shromažďuje metriky, ukládá je a zpřístupňuje je pro dotazování, odesílá upozornění na základě shromážděných metrik.
škrábání
Prometheus je systém založený na tahu. Pro načtení metrik odešle Prometheus požadavek HTTP nazývaný scrape. Odesílá škrábance na cíle na základě své konfigurace.
Každý cíl (staticky definovaný nebo dynamicky objevený) je v pravidelných intervalech seškrabáván (interval seškrabování). Každý scrape čte koncový bod HTTP /metrics, aby získal aktuální stav klientských metrik a uchovává hodnoty v databázi časových řad Prometheus.
Existuje více databází časových řad pro řešení monitorování, která možná budete chtít prozkoumat.
Klientské knihovny
Chcete-li sledovat službu, musíte do kódu přidat instrumentaci. K dispozici jsou klientské knihovny pro všechny oblíbené jazyky a běhové prostředí. Pomocí těchto knihoven, jakmile přidáte několik řádků kódu, váš kód může začít vydávat metriky. Toto se nazývá přímé instrumentace. Tyto knihovny vám umožňují definovat interní metriky a také je vystavit prostřednictvím koncového bodu HTTP. Když Prometheus seškrábe koncový bod HTTP metrik, klientská knihovna odešle metriky na server.
Oficiální klientské knihovny nabízí Prometheus pro Go, Java, Python a Ruby. Prometheus má otevřený ekosystém. K dispozici jsou také komunitně vytvořené klientské knihovny pro C, PHP, Node.js, C#/.NET a mnoho dalších.
Vývozci
Mnoho aplikací vystavuje metriky v jiném formátu než Prometheus. Pro tyto a pro aplikace, které nevlastníte nebo ke kterým nemáte přístup ke kódu, nemůžete přidávat instrumentaci přímo. Například server MySQL, Kafka, JMX, HAProxy a NGINX. V těchto scénářích využijete vývozci.
Exportér je nástroj, který nasazujete spolu s aplikací, ze které chcete metriky. Exportér funguje jako proxy mezi aplikací a Prometheem. Bude přijímat požadavky ze serveru Prometheus, sbírat data z přístupových protokolů, protokolů chyb aplikace, transformovat je do správného formátu a nakonec se vrátit na server Prometheus.
Někteří z oblíbených vývozců jsou:
- Okna – pro metriky serveru Windows
- Uzel – pro metriky serveru Linux
- Černá skříňka – pro metriky výkonu DNS a webových stránek
- JMX – pro metriky aplikací založených na Javě
Jakmile jsou aplikace instrumentovány nebo jsou exportéři na místě, musíte společnosti Prometheus sdělit, kde se nacházejí. To lze provést pomocí statické konfigurace. V případě dynamických prostředí to nelze provést; proto se používá zjišťování služeb.
Upozornění
Upozornění s Prometheem se skládá ze dvou částí –
Pravidla upozornění odesílají upozornění do Správce upozornění.
Správce výstrah pak tyto výstrahy spravuje. Odesílá upozornění pomocí mnoha předdefinovaných integrací, jako je e-mail, Slack, Hipchat a PagerDuty. Správce výstrah může také provádět ztišení nebo agregaci, aby se snížil počet oznámení.
Zde je průvodce monitorováním linuxového serveru pomocí Prometheus a Dashboard.
Vizualizace pomocí řídicích panelů
Prometheus má řadu rozhraní API, pomocí kterých mohou dotazy PromQL produkovat nezpracovaná data pro vizualizace.
Přestože Prometheus obsahuje prohlížeč výrazů, který lze použít pro dotazy ad-hoc, nejlepší dostupný nástroj je Grafana. Grafana se plně integruje s Prometheus a může vyrábět širokou škálu dashboardů.
Budete muset nakonfigurovat Prometheus jako zdroj dat pro Grafana.
Panely můžete přidat takto:
- Import panelů vytvořených komunitou
- Budování vlastního
- Pomocí předdefinovaného řídicího panelu.
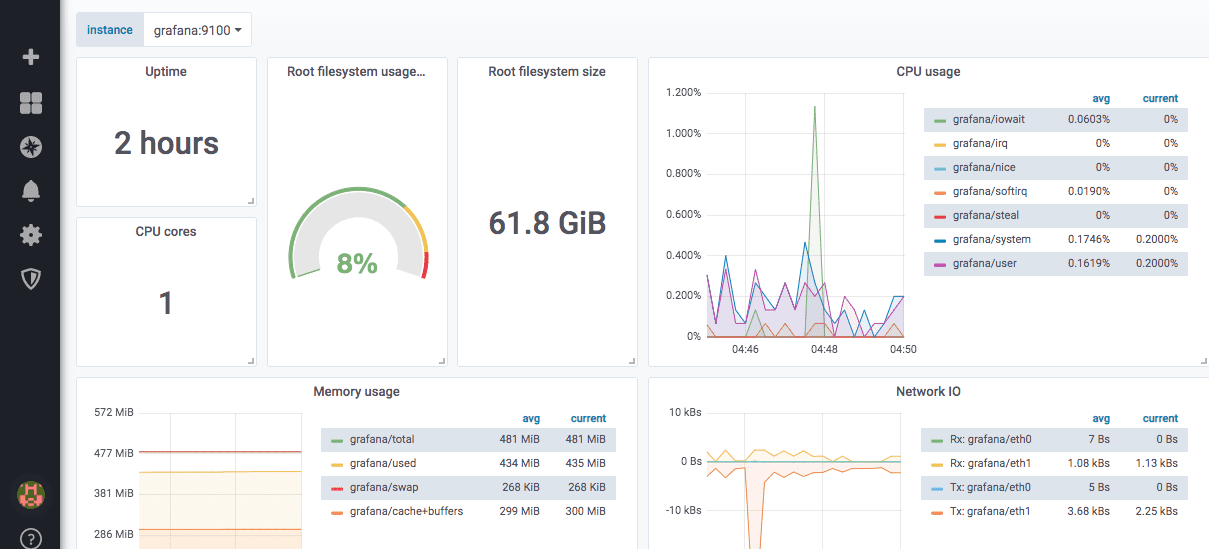
Takto vypadá předdefinovaný řídicí panel exportéru uzlů:
Grafana má modul worldPing, který vám umožňuje sledovat metriky výkonu webu a DNS po celém světě.
souhrn
Prometheus má velmi málo požadavků. Spuštění může být docela jednoduché, protože se jedná o jeden binární soubor s konfiguračním souborem. Dokáže zpracovat tisíce cílů a pohltit miliony vzorků za sekundu. Prometheus je navržen tak, aby sledoval celkový systém, zdraví a chování systému.
Grafana je nejlepší dostupný nástroj pro vizualizaci metrik a bez problémů se s ním integruje Prometheus.