

MapReduce nabízí efektivní, rychlejší a nákladově efektivní způsob vytváření aplikací.
Tento model využívá pokročilé koncepty, jako je paralelní zpracování, datová lokalita atd., aby poskytl programátorům a organizacím mnoho výhod.
Na trhu je však tolik dostupných programovacích modelů a rámců, že je těžké si vybrat.
A pokud jde o Big Data, nemůžete si vybrat jen tak něco. Musíte zvolit takové technologie, které dokážou zpracovat velké kusy dat.
MapReduce je skvělé řešení.
V tomto článku se budu zabývat tím, co MapReduce skutečně je a jak může být prospěšné.
Začněme!
Table of Contents
Co je MapReduce?
MapReduce je programovací model nebo softwarový rámec v rámci Apache Hadoop. Používá se pro vytváření aplikací schopných paralelně zpracovávat masivní data na tisících uzlech (nazývaných clustery nebo gridy) s odolností proti chybám a spolehlivostí.
Toto zpracování dat probíhá v databázi nebo souborovém systému, kde jsou data uložena. MapReduce může pracovat se systémem souborů Hadoop (HDFS) pro přístup a správu velkých objemů dat.
Tento rámec byl představen v roce 2004 společností Google a je popularizován společností Apache Hadoop. Je to vrstva zpracování nebo engine v Hadoopu, na kterém běží programy MapReduce vyvinuté v různých jazycích, včetně Javy, C++, Pythonu a Ruby.
Programy MapReduce v cloud computingu běží paralelně, takže jsou vhodné pro provádění analýzy dat ve velkém měřítku.
MapReduce se zaměřuje na rozdělení úkolu na menší, více úkolů pomocí funkcí „mapa“ a „redukce“. Mapuje každou úlohu a poté ji redukuje na několik ekvivalentních úloh, což má za následek menší výpočetní výkon a režii v síti clusteru.
Příklad: Předpokládejme, že připravujete jídlo pro dům plný hostů. Pokud se tedy budete snažit připravovat všechna jídla a dělat všechny procesy sami, bude to hektické a časově náročné.
Předpokládejme však, že zapojíte některé ze svých přátel nebo kolegů (nikoli hosty), aby vám pomohli připravit jídlo tím, že rozdělíte různé procesy jiné osobě, která může provádět úkoly současně. V tom případě připravíte jídlo rychleji a snadněji, když jsou vaši hosté ještě v domě.
MapReduce pracuje podobným způsobem s distribuovanými úlohami a paralelním zpracováním, což umožňuje rychlejší a jednodušší způsob dokončení daného úkolu.
Apache Hadoop umožňuje programátorům využívat MapReduce k provádění modelů na velkých distribuovaných souborech dat a používat pokročilé strojové učení a statistické techniky k hledání vzorů, předpovědi, nalézání korelací a další.
Vlastnosti MapReduce
Některé z hlavních funkcí MapReduce jsou:
- Uživatelské rozhraní: Získáte intuitivní uživatelské rozhraní, které poskytuje přiměřené podrobnosti o každém aspektu rámce. Pomůže vám bezproblémově nakonfigurovat, aplikovat a vyladit vaše úkoly.

- Užitečná zátěž: Aplikace využívají rozhraní Mapper a Reducer k aktivaci mapy a omezení funkcí. Mapovač mapuje vstupní páry klíč–hodnota na střední páry klíč–hodnota. Reduktor se používá ke snížení přechodných párů klíč–hodnota sdílejících klíč na jiné menší hodnoty. Provádí tři funkce – třídit, míchat a redukovat.
- Partitioner: Řídí rozdělení meziklíčů pro výstup mapy.
- Reportér: Je to funkce pro hlášení průběhu, aktualizaci počítadel a nastavení stavových zpráv.
- Čítače: Představuje globální čítače, které definuje aplikace MapReduce.
- OutputCollector: Tato funkce shromažďuje výstupní data z Mapper nebo Reducer namísto mezivýstupů.
- RecordWriter: Zapisuje výstup dat nebo páry klíč-hodnota do výstupního souboru.
- DistributedCache: Efektivně distribuuje větší soubory pouze pro čtení, které jsou specifické pro aplikaci.
- Komprese dat: Zapisovatel aplikace může komprimovat výstupy úloh i přechodné výstupy map.
- Přeskakování chybných záznamů: Během zpracování mapových vstupů můžete přeskočit několik chybných záznamů. Tuto funkci lze ovládat prostřednictvím třídy – SkipBadRecords.
- Ladění: Získáte možnost spouštět uživatelsky definované skripty a povolit ladění. Pokud úloha v MapReduce selže, můžete spustit ladicí skript a najít problémy.
Architektura MapReduce
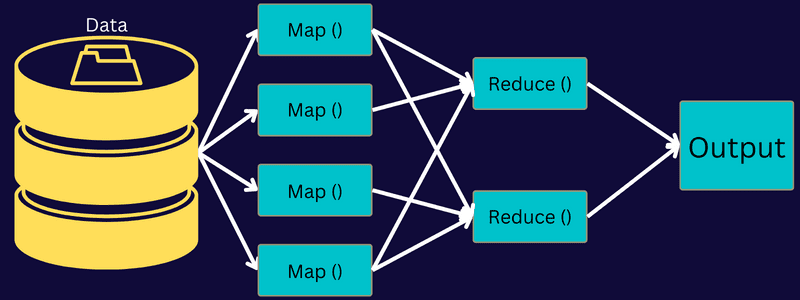
Pojďme pochopit architekturu MapReduce tím, že půjdeme hlouběji do jejích komponent:
- Úloha: Úloha v MapReduce je skutečný úkol, který chce klient MapReduce provést. Skládá se z několika menších úkolů, které se spojí do konečného úkolu.
- Server historie úloh: Je to proces démona pro ukládání a ukládání všech historických dat o aplikaci nebo úloze, jako jsou protokoly generované po nebo před provedením úlohy.
- Klient: Klient (program nebo API) přináší úlohu do MapReduce ke spuštění nebo zpracování. V MapReduce může jeden nebo více klientů nepřetržitě odesílat úlohy do Správce MapReduce ke zpracování.
- MapReduce Master: MapReduce Master rozděluje úlohu na několik menších částí a zajišťuje, že úkoly probíhají současně.
- Části úlohy: Dílčí úlohy nebo části úlohy se získají rozdělením primární úlohy. Zpracují se a nakonec se spojí, aby vznikl konečný úkol.
- Vstupní data: Jedná se o datovou sadu dodávanou do MapReduce pro zpracování úloh.
- Výstupní data: Je to konečný výsledek získaný po zpracování úlohy.
V této architektuře se tedy skutečně stane, že klient odešle úlohu MapReduce Master, který ji rozdělí na menší, stejné části. To umožňuje, aby byla úloha zpracována rychleji, protože zpracování menších úloh zabere méně času namísto větších úloh.
Zajistěte však, aby úkoly nebyly rozděleny do příliš malých úkolů, protože pokud to uděláte, možná budete muset čelit větší režii na správu rozdělení a ztrácet tím značné množství času.
Dále jsou zpřístupněny části úlohy, abyste mohli pokračovat v úlohách Map a Reduce. Úlohy Map a Reduce mají navíc vhodný program založený na případu použití, na kterém tým pracuje. Programátor vyvíjí kód založený na logice, aby splnil požadavky.
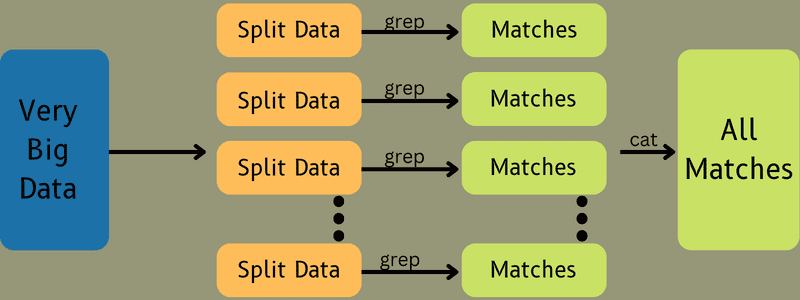
Poté jsou vstupní data přiváděna do Map Task, takže mapa může rychle generovat výstup jako pár klíč-hodnota. Místo ukládání těchto dat na HDFS se k ukládání dat používá místní disk, aby se eliminovala možnost replikace.
Jakmile je úkol dokončen, můžete výstup zahodit. Replikace se tedy stane přehnanou, když výstup uložíte na HDFS. Výstup každé mapové úlohy bude přiváděn do úlohy snížení a výstup mapy bude poskytnut počítači, na kterém běží úloha snížení.
Dále bude výstup sloučen a předán do funkce snížení definované uživatelem. Nakonec bude zmenšený výstup uložen na HDFS.
Kromě toho může mít proces několik úloh Map a Reduce pro zpracování dat v závislosti na konečném cíli. Algoritmy Map a Reduce jsou optimalizovány tak, aby časovou nebo prostorovou složitost udržely na minimu.
Vzhledem k tomu, že MapReduce primárně zahrnuje úkoly Map a Reduce, je vhodné o nich porozumět více. Pojďme si tedy probrat fáze MapReduce, abychom získali jasnou představu o těchto tématech.
Fáze MapReduce
Mapa
Vstupní data jsou v této fázi mapována na výstup nebo páry klíč–hodnota. Zde může klíč odkazovat na id adresy, zatímco hodnota může být skutečnou hodnotou této adresy.
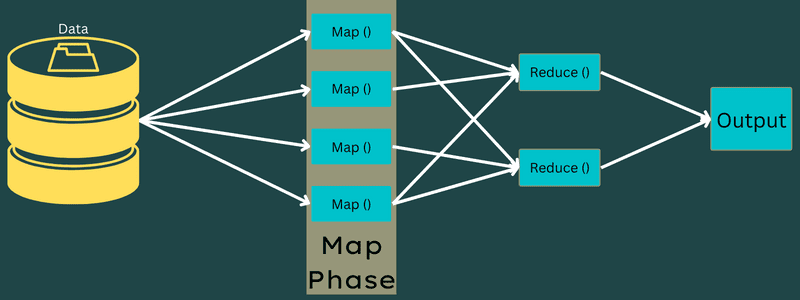
V této fázi je pouze jeden, ale dva úkoly – rozdělení a mapování. Rozdělení znamená dílčí části nebo části zakázky oddělené od hlavní zakázky. Říká se jim také vstupní rozdělení. Vstupní rozdělení lze tedy nazvat vstupním blokem spotřebovaným mapou.
Dále proběhne úloha mapování. Je to považováno za první fázi při provádění programu pro redukci mapy. Zde budou data obsažená v každém rozdělení předána mapové funkci ke zpracování a generování výstupu.
Funkce – Map() se provádí v úložišti paměti na vstupních párech klíč–hodnota a generuje mezilehlý pár klíč–hodnota. Tento nový pár klíč–hodnota bude fungovat jako vstup pro funkci Reduce() nebo Reducer.
Snížit
Mezilehlé páry klíč–hodnota získané ve fázi mapování fungují jako vstup pro funkci Reduce nebo Reducer. Podobně jako ve fázi mapování se jedná o dva úkoly – zamíchat a zredukovat.
Získané páry klíč-hodnota se tedy třídí a zamíchají, aby se přivedly do reduktoru. Dále Reducer seskupuje nebo agreguje data podle svého páru klíč–hodnota na základě algoritmu reduktoru, který napsal vývojář.
Zde jsou hodnoty z fáze míchání kombinovány, aby se vrátila výstupní hodnota. Tato fáze shrnuje celý soubor dat.
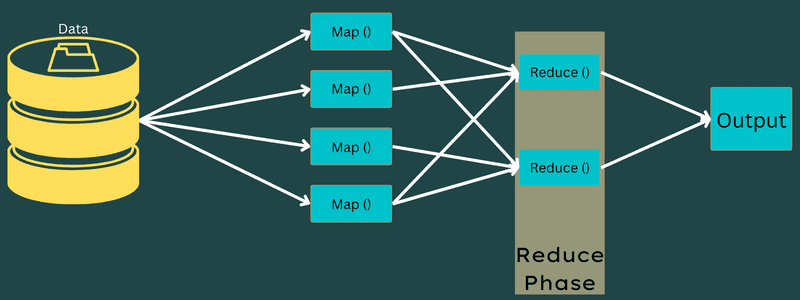
Nyní je celý proces provádění úloh Map and Reduce řízen některými entitami. Tyto jsou:
- Job Tracker: Jednoduše řečeno, job tracker funguje jako hlavní, který je zodpovědný za úplné provedení odeslané úlohy. Nástroj pro sledování úloh spravuje všechny úlohy a prostředky v rámci clusteru. Kromě toho nástroj pro sledování úloh naplánuje každou mapu přidanou do nástroje Task Tracker, která běží na konkrétním datovém uzlu.
- Multiple task trackers: Jednoduše řečeno, multi task trackery fungují jako otroci provádějící úkol podle pokynů Job Tracker. Sledování úloh je nasazeno na každý uzel samostatně v clusteru, který provádí úlohy Map a Reduce.
Funguje to, protože úloha bude rozdělena do několika úloh, které poběží na různých datových uzlech z clusteru. Job Tracker je zodpovědný za koordinaci úlohy tím, že naplánuje úlohy a spouští je na více datových uzlech. Dále nástroj Task Tracker umístěný na každém datovém uzlu provádí části úlohy a stará se o každou úlohu.
Kromě toho sledovače úkolů odesílají zprávy o postupu do sledovače úloh. Nástroj Task Tracker také pravidelně vysílá signál „srdce“ do nástroje Job Tracker a informuje ho o stavu systému. V případě jakéhokoli selhání je nástroj pro sledování úloh schopen přeplánovat úlohu na jiném nástroji pro sledování úloh.
Výstupní fáze: Když dosáhnete této fáze, necháte si z Reduceru vygenerovat poslední páry klíč-hodnota. K překladu párů klíč-hodnota a jejich zápisu do souboru pomocí zapisovače záznamů můžete použít výstupní formátovač.
Proč používat MapReduce?
Zde jsou některé z výhod MapReduce, které vysvětlují důvody, proč ji musíte používat ve svých aplikacích pro velká data:
Paralelní zpracování
Úlohu můžete rozdělit do různých uzlů, kde každý uzel současně zpracovává část této úlohy v MapReduce. Takže rozdělení větších úkolů na menší snižuje složitost. Vzhledem k tomu, že různé úlohy běží paralelně na různých strojích místo na jednom stroji, trvá zpracování dat výrazně méně času.
Lokalita dat
V MapReduce můžete přesunout procesní jednotku na data, nikoli naopak.
Tradičními způsoby byla data přenesena do zpracovatelské jednotky ke zpracování. S rychlým nárůstem dat však tento proces začal představovat mnoho výzev. Některé z nich byly vyšší náklady, časově náročnější, zatížení hlavního uzlu, časté poruchy a snížený výkon sítě.
MapReduce však pomáhá překonat tyto problémy tím, že se řídí obráceným přístupem – přivedením procesorové jednotky k datům. Tímto způsobem jsou data distribuována mezi různé uzly, kde každý uzel může zpracovat část uložených dat.
V důsledku toho nabízí nákladovou efektivitu a zkracuje dobu zpracování, protože každý uzel pracuje paralelně s odpovídající datovou částí. Navíc, protože každý uzel zpracovává část těchto dat, žádný uzel nebude přetížen.
Bezpečnostní

Model MapReduce nabízí vyšší bezpečnost. Pomáhá chránit vaši aplikaci před neoprávněnými daty a zároveň zvyšuje zabezpečení clusteru.
Škálovatelnost a flexibilita
MapReduce je vysoce škálovatelný rámec. Umožňuje spouštět aplikace z několika strojů s využitím dat s tisíci terabajty. Nabízí také flexibilitu zpracování dat, která mohou být strukturovaná, polostrukturovaná nebo nestrukturovaná a v jakémkoli formátu nebo velikosti.
Jednoduchost
Programy MapReduce můžete psát v jakémkoli programovacím jazyce, jako je Java, R, Perl, Python a další. Proto je pro každého snadné naučit se a psát programy a zároveň zajistit, aby byly splněny jeho požadavky na zpracování dat.
Případy použití MapReduce
- Fulltextové indexování: MapReduce se používá k provádění fulltextového indexování. Jeho Mapper může mapovat každé slovo nebo frázi v jediném dokumentu. A Reducer se používá k zápisu všech mapovaných prvků do indexu.
- Výpočet Pagerank: Google používá MapReduce pro výpočet Pagerank.
- Analýza protokolů: MapReduce může analyzovat soubory protokolu. Může rozdělit velký soubor protokolu na různé části nebo rozdělit, zatímco mapovač hledá přístupné webové stránky.
Pokud je v protokolu spatřena webová stránka, bude reduktoru předán pár klíč-hodnota. Zde bude klíčem webová stránka a hodnotou bude index „1“. Po předání páru klíč–hodnota Reduceru budou různé webové stránky agregovány. Konečným výstupem je celkový počet přístupů pro každou webovou stránku.

- Reverse Web-Link Graph: Rámec také najde využití v Reverse Web-Link Graph. Zde Map() poskytne cíl URL a zdroj a převezme vstup ze zdroje nebo webové stránky.
Dále funkce Reduce() agreguje seznam všech zdrojových adres URL spojených s cílovou adresou URL. Nakonec vypíše zdroje a cíl.
- Počítání slov: MapReduce se používá k počítání, kolikrát se slovo vyskytuje v daném dokumentu.
- Globální oteplování: Organizace, vlády a společnosti mohou používat MapReduce k řešení problémů globálního oteplování.
Můžete například chtít vědět o zvýšené teplotě oceánu v důsledku globálního oteplování. Za tímto účelem můžete shromáždit tisíce dat po celém světě. Data mohou být vysoká teplota, nízká teplota, zeměpisná šířka, délka, datum, čas atd. To zabere několik map a sníží počet úkolů pro výpočet výstupu pomocí MapReduce.
- Drogové studie: Tradičně datoví vědci a matematici spolupracovali na vytvoření nového léku, který může bojovat s nemocí. Díky šíření algoritmů a MapReduce mohou IT oddělení v organizacích snadno řešit problémy, které řešily pouze Superpočítače, Ph.D. vědci atd. Nyní můžete zkontrolovat účinnost léku pro skupinu pacientů.
- Další aplikace: MapReduce dokáže zpracovat i rozsáhlá data, která se jinak nevejdou do relační databáze. Využívá také nástroje datové vědy a umožňuje je spouštět přes různé distribuované datové sady, což bylo dříve možné pouze na jediném počítači.
Díky robustnosti a jednoduchosti MapReduce nachází uplatnění v armádě, obchodu, vědě atd.
Závěr
MapReduce se může ukázat jako průlom v technologii. Je to nejen rychlejší a jednodušší proces, ale také nákladově efektivní a méně časově náročný. Vzhledem k jeho výhodám a rostoucímu využití je pravděpodobné, že bude svědkem vyššího přijetí napříč odvětvími a organizacemi.
Můžete také prozkoumat některé nejlepší zdroje, jak se naučit Big Data a Hadoop.