Můžete s tím něco udělat?
Zásadní body
- Platformy sociálních médií prodávají data uživatelů společnostem zabývajícím se umělou inteligencí, aby vycvičily generativní modely AI, a to i přes obavy o ochranu soukromí.
- Klíčové platformy, jako jsou Meta, Reddit, Tumblr a WordPress.com, se aktivně zapojují do licenčních dohod o datech pro účely trénování umělé inteligence.
- Uživatelé mají několik možností, jak minimalizovat rizika a chránit svá data, například upravit nastavení soukromí, deaktivovat sdílení a pečlivě zvažovat, co publikují online.
Uzavírání dohod se společnostmi specializujícími se na umělou inteligenci se stalo pro platformy sociálních médií novým způsobem, jak zpeněžit uživatelská data. Otázkou zůstává, zda má běžný uživatel možnost chránit svá data a obsah?
Používání dat ze sociálních sítí k trénování generativních AI modelů vyvolalo kontroverze, ale zdá se, že to společnosti provozující sociální sítě neodrazuje od poskytování uživatelských dat.
Společnost Meta již používá data z platformy sociálních médií k trénování funkcí generativní AI, které představila na akci Meta Connect v roce 2023. To zahrnuje Meta AI a funkce, jako je generování nálepek pomocí umělé inteligence na WhatsApp.
Podle Mikea Clarka, ředitele produktového managementu společnosti Meta, v příspěvku na blogu Meta Newsroom:
"Veřejně sdílené příspěvky na Instagramu a Facebooku – včetně fotografií a textu – se staly součástí dat využívaných k trénování generativních modelů umělé inteligence, které jsou základem funkcí oznámených na Connect."
Zdá se, že trend bude pokračovat i v roce 2024. Podle agentury Reuters uzavřel Reddit dohodu se společností Google o využití obsahu sociální sítě pro trénování AI modelů.
Dokument S-1 společnosti Reddit, podaný 22. února 2024 v souvislosti s IPO, potvrzuje, že společnost zkoumá možnosti licenčních dohod. V dokumentu se uvádí:
"Data na Redditu tvoří základ pro vývoj současné technologie umělé inteligence a mnoha LLM. Jsme přesvědčeni, že rozsáhlý korpus konverzačních dat a znalostí na Redditu bude nadále hrát klíčovou roli při trénování a vylepšování LLM."
Dále se uvádí, že Reddit je "v počátečních fázích umožnění třetím stranám získat licenci pro přístup, vyhledávání, analýzu a zobrazení historických i aktuálních dat z naší platformy" pro účely trénování LLM.
I když jsou Meta a Reddit významnými jmény v oblasti sociálních sítí, nejsou jedinými platformami, které se podílejí na využívání dat ze sociálních médií pro trénování AI. Podle zprávy 404 Media se Tumblr a WordPress.com připravují na prodej uživatelských dat společnostem Midjourney a OpenAI.
Je pravděpodobné, že pokud používáte Facebook, Instagram, Reddit, Tumblr nebo WordPress.com, váš veřejně dostupný obsah již mohl být použit k trénování LLM.
Pokud použijete například nástroj pro vyhledávání Washington Post, abyste zjistili, jaké webové stránky byly zahrnuty do datové sady Google C4, která se používá při trénování Barda, zjistíte, že Reddit.com tvoří 7,9 milionu tokenů.
Na Tumblr.com připadá 1,6 milionu tokenů. Můj vlastní malý web, který využívá WordPress.com, představoval 14 000 tokenů – takže i malé osobní blogy mohly být do datové sady zahrnuty.
S probíhajícími dohodami mezi společnostmi zaměřenými na umělou inteligenci a platformami sociálních médií budou licenční smlouvy znamenat, že tato data budou aktivně prodávána, nikoli pouze stahována z webu.
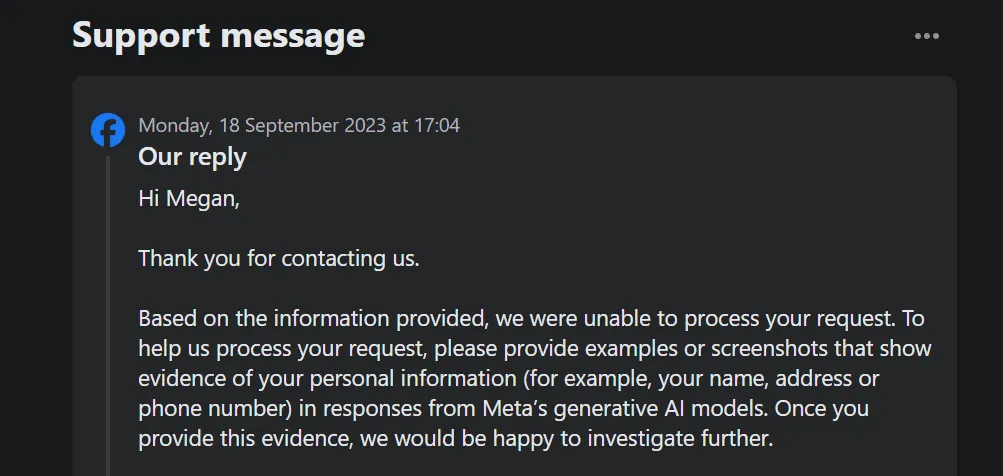
Co s tím však můžete dělat, pokud jde o budoucí zpracování? Společnost Meta zavedla formulář pro generativní práva subjektu údajů AI, který vám umožňuje vznést námitku nebo omezit zpracování vašich osobních údajů třetími stranami pro trénování generativních modelů AI společnosti Meta.
Je třeba poznamenat, že tato možnost vám neumožňuje vznést námitky proti vlastnímu zpracování vašich dat společností Meta pro trénování generativní AI. Když jsem navíc odeslal formulář s námitkou proti použití svých osobních údajů, žádal mě tým podpory o důkaz, že se mé osobní údaje již objevují ve výsledcích generativní AI společnosti Meta.
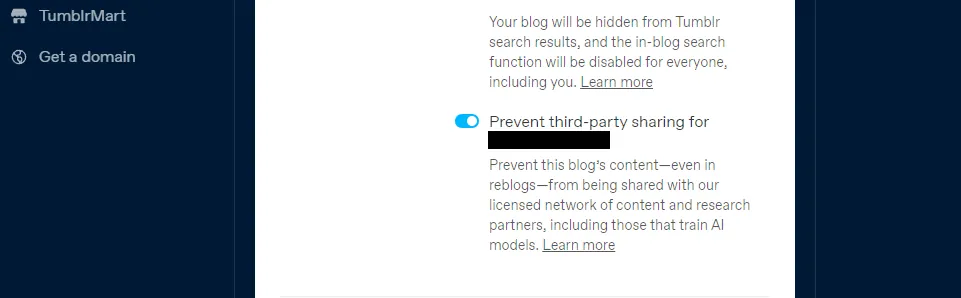
Tumblr také zavedl možnost deaktivovat sdílení obsahu vašich veřejných blogů s třetími stranami v nastavení blogu. Najdete jej v nastavení po kliknutí na váš blog a posunutí dolů do nastavení viditelnosti. Poté vyberte možnost Zakázat sdílení blogu s třetími stranami.
V případě platforem, jako je Instagram, můžete zkusit přepnout svůj účet na soukromý, abyste omezili použití vašich dat. To nezaručuje, že vaše data nebudou použita, ale jelikož se zdá, že shromažďování dat pro LLM se zaměřuje na veřejná data, může to být určitá ochrana.
Stejně tak můžete nastavit svůj účet X (Twitter) jako soukromý, ale i zde jde pouze o potenciální ochranu a není jisté, že vaše data zůstanou v soukromí.
Společné prohlášení různých národních komisařů pro informace a odborníků z celého světa navrhuje několik opatření pro jednotlivce, kteří chtějí minimalizovat riziko ochrany osobních údajů spojené s automatizovaným stahováním dat společnostmi AI. Mezi doporučení patří:
- Přečtěte si podmínky a zásady ochrany osobních údajů webových stránek, abyste zjistili, jak sdílí vaše osobní údaje.
- Omezte množství informací, které publikujete online, zejména citlivé informace.
- Spravujte nastavení ochrany soukromí.
- Přemýšlejte z dlouhodobého hlediska o informacích, které sdílíte online.
- Pokud se domníváte, že vaše data byla neoprávněně získána, obraťte se na společnost nebo web sociálních médií. Pokud nejste spokojeni s jejich odpovědí, podejte stížnost příslušnému úřadu pro ochranu osobních údajů.
Můžete také smazat určité informace online, pokud vám vadí, že k nim mají třetí strany přístup, ačkoli veřejně dostupné informace z vašich profilů již mohly být zkopírovány.
Bohužel, my jako běžní uživatelé nemáme příliš mnoho možností, jak chránit svá data před společnostmi zabývajícími se umělou inteligencí. Skutečnou kontrolu nad těmito informacemi pravděpodobně získáme až za pomoci regulačních orgánů.
