Vysvětlení regrese vs. klasifikace ve strojovém učení
Regrese a klasifikace představují dva stěžejní pilíře v oblasti strojového učení.
Rozlišení mezi regresními a klasifikačními algoritmy může být zpočátku matoucí pro ty, kdo se do strojového učení teprve noří. Avšak porozumění jejich fungování a vhodným případům použití je klíčové pro dosahování přesných predikcí a efektivních rozhodnutí.
Nejprve si objasněme, co vlastně strojové učení je.
Co je strojové učení?
Strojové učení je metodologie umožňující počítačům učit se a rozhodovat bez nutnosti explicitního programování. Spočívá v trénování počítačového modelu na základě datového souboru, což mu umožňuje odhalovat vzorce a vztahy a následně provádět predikce nebo rozhodnutí.
Existují tři hlavní druhy strojového učení: učení s učitelem, učení bez učitele a posilování.
V učení s učitelem je model trénován na označených datech, která obsahují jak vstupní data, tak i odpovídající správné výstupy. Cílem je, aby se model naučil predikovat výstup pro nová, dosud neviděná data, a to na základě vzorců, které získal z trénovacích dat.
Při učení bez učitele model nepracuje s označenými trénovacími daty. Je ponechán sám na objevování vzorců a vztahů v datech. To se využívá například k identifikaci skupin či shluků v datech nebo k odhalování anomálií a neobvyklých vzorců.
V posilování se agent učí interakcí se svým prostředím s cílem maximalizovat odměnu. Model se učí činit rozhodnutí na základě zpětné vazby, kterou dostává z okolí.
Strojové učení nachází uplatnění v mnoha oblastech, například v rozpoznávání obrazu a řeči, zpracování přirozeného jazyka, odhalování podvodů a v autonomních vozidlech. Má potenciál automatizovat velké množství úkolů a zlepšit rozhodovací procesy v různých odvětvích.
Tento článek se primárně zaměřuje na koncepty klasifikace a regrese, které spadají pod učení s učitelem. Pusťme se do toho!
Klasifikace ve strojovém učení

Klasifikace je technika strojového učení, při níž je model trénován, aby přiřadil danému vstupu štítek třídy. Jde o úlohu učení s učitelem, což znamená, že model se učí na základě označeného datového souboru, který obsahuje jak vstupní data, tak i odpovídající štítky tříd.
Cílem modelu je naučit se vztah mezi vstupními daty a štítky tříd, aby byl schopen předpovídat štítek třídy pro nová, dosud neviděná data.
Pro klasifikaci se používá celá řada algoritmů, například logistická regrese, rozhodovací stromy a podpůrné vektorové stroje. Volba algoritmu závisí na charakteristikách dat a požadované výkonnosti modelu.
Mezi běžné aplikace klasifikace patří detekce spamu, analýza sentimentu a odhalování podvodů. V těchto případech mohou vstupní data zahrnovat text, číselné hodnoty nebo kombinaci obou. Štítky tříd mohou být binární (např. spam nebo ne spam) nebo vícetřídní (např. pozitivní, neutrální, negativní sentiment).
Například u datové sady zákaznických recenzí produktu mohou vstupní data obsahovat text recenze a štítek třídy může být hodnocení (např. pozitivní, neutrální, negativní). Model by byl trénován na označené datové sadě recenzí a následně by byl schopen předpovídat hodnocení nové recenze, kterou předtím neviděl.
Typy klasifikačních algoritmů ML
V rámci strojového učení existuje několik kategorií klasifikačních algoritmů:
Logistická regrese
Jedná se o lineární model používaný pro binární klasifikaci. Slouží k předpovědi pravděpodobnosti výskytu určité události. Cílem logistické regrese je najít nejvhodnější koeficienty (váhy), které minimalizují rozdíl mezi predikovanou pravděpodobností a skutečným výsledkem.
To se provádí pomocí optimalizačního algoritmu, například gradientního sestupu, který upravuje koeficienty, dokud model co nejlépe neodpovídá trénovacím datům.
Rozhodovací stromy
Jedná se o stromové modely, které se rozhodují na základě hodnot funkcí. Používají se pro binární i vícetřídní klasifikaci. Rozhodovací stromy mají několik výhod, včetně jejich jednoduchosti a snadné interpretovatelnosti.
Navíc se rychle trénují i předvídají a dokážou zpracovat jak číselná, tak kategorická data. Mohou však být náchylné k přeučení, zejména pokud je strom hluboký a má mnoho větví.
Náhodná klasifikace lesa
Náhodná klasifikace lesa je souborová metoda, která kombinuje předpovědi více rozhodovacích stromů s cílem dosáhnout přesnějších a stabilnějších predikcí. Je méně náchylná k přeučení než jeden rozhodovací strom, protože předpovědi jednotlivých stromů jsou zprůměrovány, čímž se snižuje rozptyl v modelu.
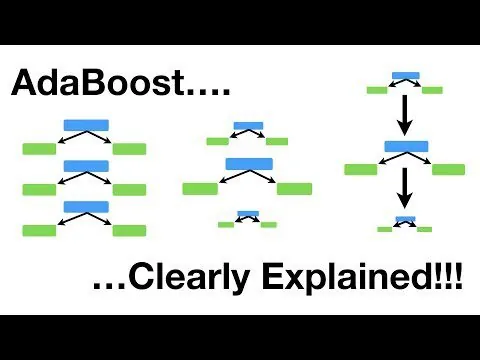
AdaBoost
Jedná se o posilovací algoritmus, který adaptivně mění váhu chybně klasifikovaných příkladů v trénovací sadě. Často se používá pro binární klasifikaci.
Naivní Bayes
Naivní Bayes vychází z Bayesovy věty, která je metodou aktualizace pravděpodobnosti události na základě nových důkazů. Jedná se o pravděpodobnostní klasifikátor často používaný pro klasifikaci textu a filtrování spamu.
K-nejbližší soused
K-Nejbližší soused (KNN) se používá pro klasifikační i regresní úlohy. Jedná se o neparametrickou metodu, která klasifikuje datový bod na základě třídy jeho nejbližších sousedů. KNN má několik výhod, včetně jeho jednoduchosti a snadné implementace. Navíc dokáže zpracovat jak číselná, tak kategorická data a nevytváří žádné předpoklady o základním rozdělení dat.
Zesílení gradientu
Jedná se o soubor slabých modelů, které jsou trénovány postupně, přičemž každý model se snaží napravit chyby předchozího modelu. Lze je použít jak pro klasifikaci, tak pro regresi.
Regrese ve strojovém učení
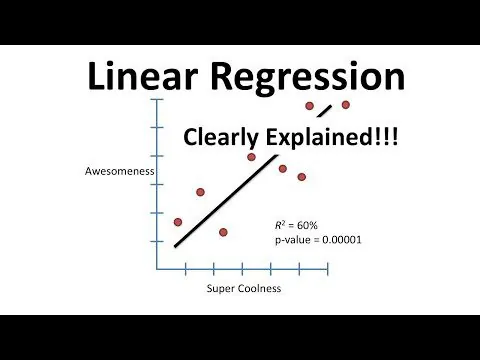
Regrese je v kontextu strojového učení typem učení s učitelem, kde je cílem předpovídat závislou proměnnou na základě jedné nebo více vstupních funkcí (také nazývaných prediktory nebo nezávislé proměnné).
Regresní algoritmy se používají k modelování vztahu mezi vstupy a výstupy a k predikcím založeným na tomto vztahu. Regresi lze použít pro spojité i kategorické závislé proměnné.
Obecně řečeno, cílem regrese je sestavit model, který dokáže přesně předpovědět výstup na základě vstupních funkcí a porozumět vztahu mezi vstupními charakteristikami a výstupem.
Regresní analýza se používá v různých oborech, například v ekonomii, financích, marketingu a psychologii, k pochopení a předpovídání vztahů mezi různými proměnnými. Je to základní nástroj v analýze dat a strojovém učení a využívá se pro predikce, identifikaci trendů a pochopení základních mechanismů, které řídí data.
Například v jednoduchém lineárním regresním modelu může být cílem předpovědět cenu domu na základě jeho velikosti, umístění a dalších vlastností. Velikost domu a jeho umístění by byly nezávislé proměnné a cena domu by byla závislá proměnná.
Model by byl trénován na vstupních datech, která zahrnují velikost a polohu několika domů spolu s jejich odpovídajícími cenami. Jakmile je model trénován, lze jej použít k předpovědi ceny domu na základě jeho velikosti a umístění.
Typy ML regresních algoritmů
Regresní algoritmy existují v různých formách a použití každého algoritmu závisí na faktorech, jako je typ hodnoty atributu, vzor spojnice trendu a počet nezávislých proměnných. Mezi často používané regresní techniky patří:
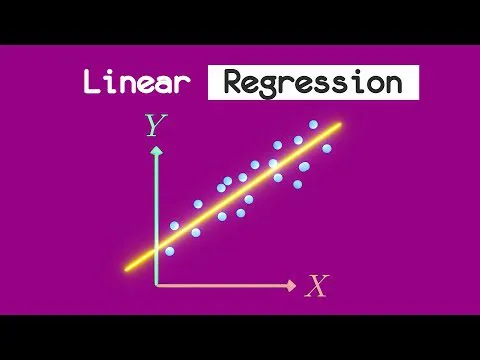
Lineární regrese
Tento jednoduchý lineární model se používá k předpovědi spojité hodnoty na základě sady vlastností. Používá se k modelování vztahu mezi prvky a cílovou proměnnou tak, že se daty proloží přímka.
Polynomiální regrese
Jedná se o nelineární model, který se používá k proložení dat křivkou. Používá se k modelování vztahů mezi prvky a cílovou proměnnou, když tento vztah není lineární. Je založena na myšlence přidání členů vyššího řádu do lineárního modelu pro zachycení nelineárních vztahů mezi závislými a nezávislými proměnnými.
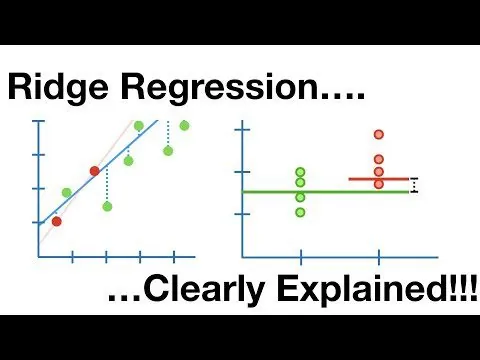
Hřebenová regrese
Jedná se o lineární model, který řeší přeučení v lineární regresi. Jde o regulovanou verzi lineární regrese, která přidává penalizační člen k nákladové funkci s cílem snížit složitost modelu.
Podpora vektorové regrese
Podobně jako SVM je i podpůrná vektorová regrese lineární model, který se snaží proložit data nalezením nadroviny, která maximalizuje rozpětí mezi závislými a nezávislými proměnnými.
Na rozdíl od SVM, které se používají pro klasifikaci, se však SVR používá pro regresní úlohy, kde je cílem spíše předpovídat spojitou hodnotu než štítek třídy.
Lasso regrese
Jedná se o další regulovaný lineární model používaný k prevenci přeučení v lineární regresi. Přidává penalizační člen k nákladové funkci na základě absolutní hodnoty koeficientů.
Bayesovská lineární regrese
Bayesovská lineární regrese je pravděpodobnostní přístup k lineární regresi založený na Bayesově větě, což je metoda aktualizace pravděpodobnosti události na základě nových důkazů.
Tento regresní model si klade za cíl odhadnout zadní rozdělení parametrů modelu na základě daných dat. To se provádí definováním předchozího rozdělení přes parametry a následným použitím Bayesovy věty k aktualizaci rozdělení na základě pozorovaných dat.
Regrese vs. klasifikace
Regrese a klasifikace jsou dva typy učení s učitelem, což znamená, že se používají k předpovědi výstupu na základě sady vstupních funkcí. Mezi těmito dvěma však existuje několik zásadních rozdílů:
| Regrese | Klasifikace | |
| Definice | Typ učení s učitelem, který předpovídá spojitou hodnotu | Typ učení s učitelem, který předpovídá kategorickou hodnotu |
| Typ výstupu | Spojitý | Diskrétní |
| Metriky hodnocení | Střední kvadratická chyba (MSE), střední kvadratická chyba (RMSE) | Přesnost, preciznost, výtěžnost, skóre F1 |
| Příklady algoritmů | Lineární regrese, polynomiální regrese, hřebenová regrese, Lasso, SVR | Logistická regrese, SVM, Naivní Bayes, KNN, rozhodovací stromy |
| Složitost modelu | Méně složité modely | Složitější modely |
| Předpoklady | Lineární vztah mezi vlastnostmi a cílem | Žádné specifické předpoklady o vztahu mezi vlastnostmi a cílem |
| Nevyváženost tříd | Nepoužije se | Může to být problém |
| Odlehlé hodnoty | Mohou ovlivnit výkon modelu | Obvykle je to problém |
| Funkce dle důležitosti | Funkce nejsou seřazeny podle důležitosti | Funkce jsou seřazeny dle důležitosti |
| Příklady aplikací | Předvídání cen, teplot, množství | Předvídání, zda je e-mail nevyžádaný, předvídání odchodu zákazníků |
Výukové zdroje
Výběr nejvhodnějších online zdrojů pro pochopení konceptů strojového učení může být náročné. Proto jsme prozkoumali oblíbené kurzy od spolehlivých platforem a sestavili doporučení pro nejlepší ML kurzy zaměřené na regresi a klasifikaci.
#1. Bootcamp klasifikace strojového učení v Pythonu
Tento kurz je nabízen na platformě Udemy. Pokrývá celou škálu klasifikačních algoritmů a technik, včetně rozhodovacích stromů, logistické regrese a podpůrných vektorových strojů.

Dále se dozvíte o tématech jako je přeučení, kompromis mezi rozptylem a zkreslením, a vyhodnocování modelu. Kurz využívá knihovny Pythonu, jako jsou scikit-learn a pandas, k implementaci a vyhodnocení modelů strojového učení. Pro zahájení tohoto kurzu jsou tedy nutné základní znalosti Pythonu.
#2. Masterclass regrese strojového učení v Pythonu
V tomto kurzu na Udemy instruktor probírá základy a teoretický základ různých regresních algoritmů, včetně lineární regrese, polynomiální regrese a technik Lasso a hřebenové regrese.

Na konci tohoto kurzu budete schopni implementovat regresní algoritmy a vyhodnocovat výkon trénovaných modelů strojového učení pomocí různých klíčových ukazatelů výkonu.
Závěrem
Algoritmy strojového učení se mohou ukázat jako velmi užitečné v mnoha aplikacích a mohou pomoci automatizovat a zefektivnit mnoho procesů. Algoritmy ML využívají statistické techniky k učení vzorců v datech a na základě těchto vzorců činí předpovědi nebo rozhodnutí.
Lze je trénovat na velkém množství dat a lze je použít k provádění úkolů, které by pro člověka byly obtížné nebo časově náročné.
Každý algoritmus ML má své silné a slabé stránky a výběr algoritmu závisí na povaze dat a požadavcích úkolu. Je důležité zvolit vhodný algoritmus nebo kombinaci algoritmů pro konkrétní problém, který se snažíte vyřešit.
Je důležité vybrat správný typ algoritmu pro váš problém, protože použití nesprávného typu algoritmu může vést ke špatnému výkonu a nepřesným předpovědím. Pokud si nejste jisti, který algoritmus použít, může být užitečné vyzkoušet regresní i klasifikační algoritmy a porovnat jejich výkon na vaší datové sadě.
Doufám, že vám tento článek pomohl lépe pochopit regresi a klasifikaci ve strojovém učení. Možná vás budou zajímat i informace o špičkových modelech strojového učení.
