Dlouhá léta se budování automatizovaného softwarového systému neobešlo bez nasazení mnoha serverů s přesně definovanými parametry CPU, paměti, diskového prostoru a dalších zdrojů. Následně se zformoval tým administrátorů, který tyto systémy spravoval. Až poté vývojový tým převzal infrastrukturu a začal vytvářet procesy propojující jednotlivé servery.
Tento proces může být složitý, protože vyžaduje spolupráci mnoha různých skupin, které mají společný cíl. Tyto protichůdné zájmy se mohou stát problémem.
Navíc to může být i finančně náročné. Znamená to totiž platit mzdy administrátorům a také serverům, které neustále běží a spotřebovávají zdroje i když nejsou využívány.
Pro dlouhodobé udržení optimálního výkonu je nezbytné mít řešení s automatickým škálováním, které dynamicky upravuje serverové zdroje.
Cloudové platformy nabízejí výhodu v podobě možnosti vytvořit kompletní architekturu bez nutnosti konfigurace serverového clusteru. Z pohledu správy tak není třeba nic udržovat.
To představuje nákladově efektivní řešení pro začínající firmy a pro projekty ve fázi MVP (Minimum Viable Product). Je to vhodný start, zejména pokud je obtížné předvídat budoucí zatížení a aktivitu uživatelů, kdy je těžké definovat optimální konfiguraci serverového clusteru.
Automatizace procesů prostřednictvím bezserverových cloudových služeb je silnou stránkou architektury bez serverů. Umožňuje propojovat služby a dosahovat výsledků podobných tradičním clusterovým serverům.
Následuje příklad, jak takovou architekturu vybudovat s využitím výhradně nativních služeb AWS.
Realizace bezserverového toku služeb
Představte si, že chcete vytvořit platformu pro shromažďování různých dat a obrázků (nebo fotografií) z infrastruktury specifických aktiv (může se jednat o jakékoli výrobní nebo užitkové zařízení).
- Příchozí data je nutné nejprve zpracovat, aby bylo možné provádět budoucí analýzy.
- Po aplikování obchodních pravidel back-end procedura uloží vypočítané výsledky jako normalizované informace do relační databáze.
- Front-end aplikace, která zobrazuje normalizovaná data, umožňuje uživatelům prohlížet výsledky.
Podívejme se, z jakých komponent se může tato architektura skládat.
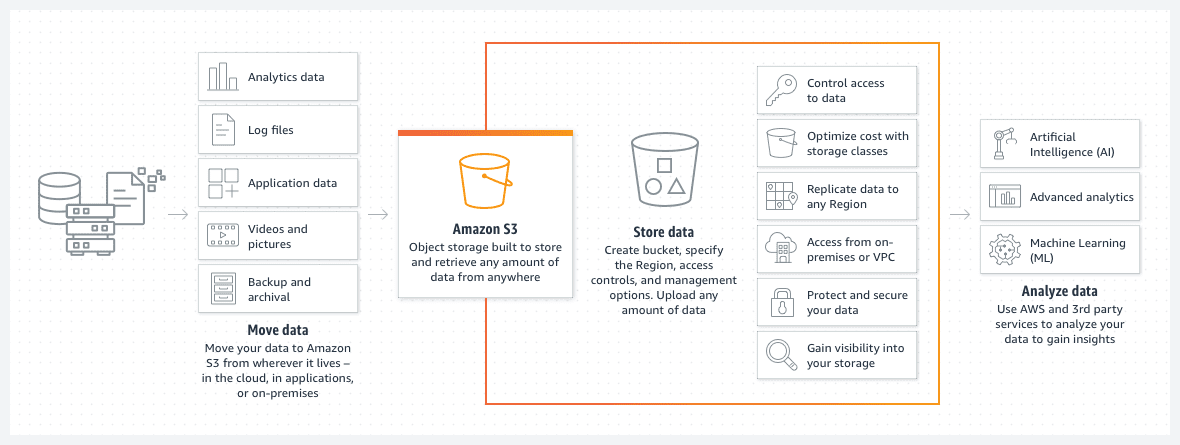
AWS S3 Buckets
 Zdroj: aws.amazon.com
Zdroj: aws.amazon.com
Amazon S3 buckety představují skvělé řešení pro ukládání souborů nebo obrázků v cloudu AWS. Cena za úložiště v S3 bucketu je velmi nízká a zavedením politik životního cyklu se dá ještě snížit.
Taková politika automaticky přesouvá starší soubory do různých tříd S3 bucketů, jako je archiv nebo deep archive. Třídy se pak liší i rychlostí přístupu, což ale u starších dat nepředstavuje problém. Slouží primárně pro přístup k archivovaným datům v případě naléhavé události, nikoliv pro standardní provoz.
- Data můžete uspořádat do podsložek.
- Měli byste nastavit příslušná omezení přístupu.
- Přidejte tagy do bucketů pro snadnou identifikaci a možné použití v rámci dynamických politik S3 bucketů.
- Bucket je navržen jako bezserverové řešení. Je to jednoduše úložný prostor pro vaše data.
S3 bucket je bezserverový již od návrhu. Je to jen úložiště pro vaše data.
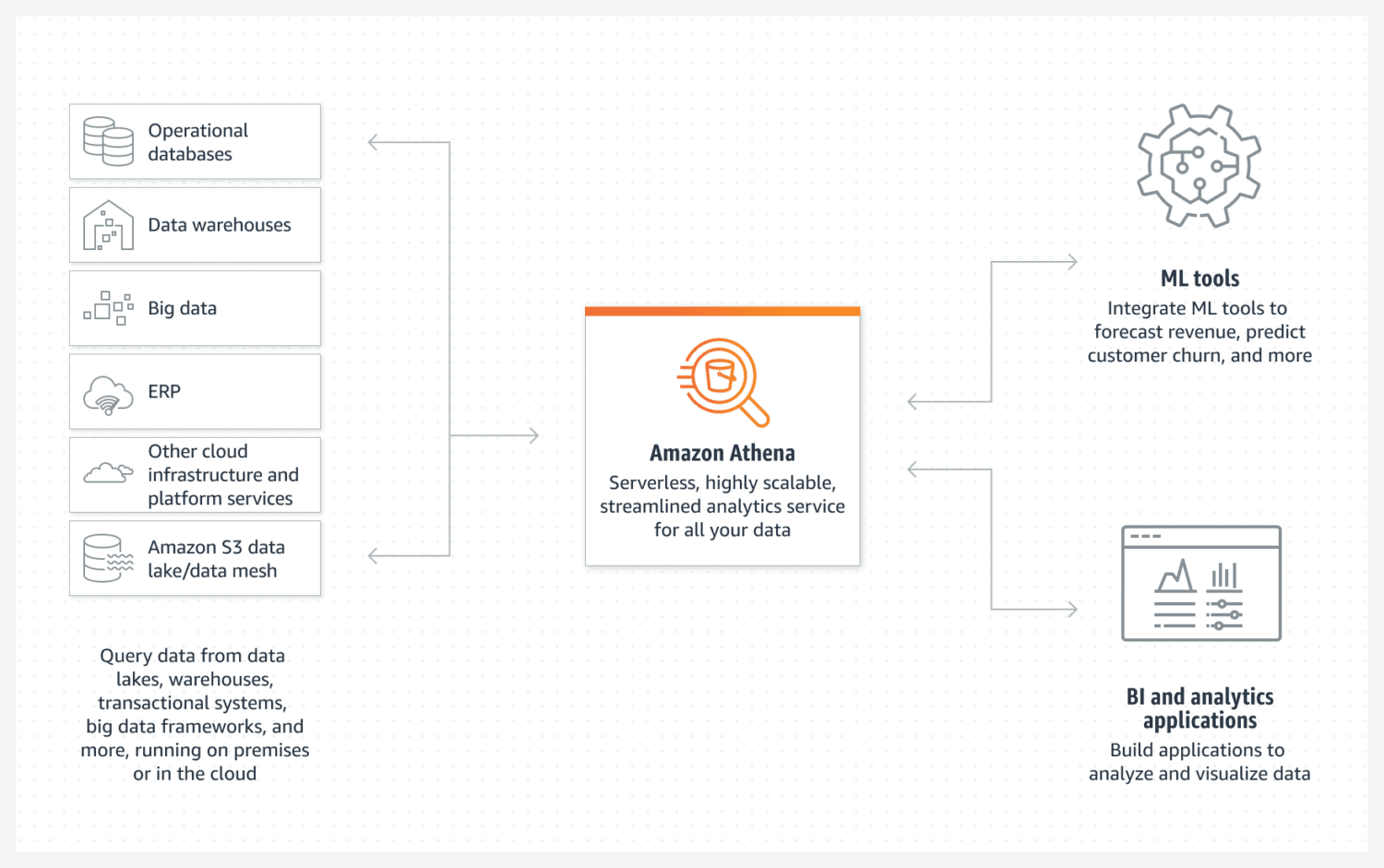
Databáze AWS Athena
 Zdroj: aws.amazon.com
Zdroj: aws.amazon.com
Athena usnadňuje vytvoření základního datového jezera AWS. Jedná se o bezserverovou databázi, která pro ukládání dat využívá S3 bucket. Data jsou organizována pomocí strukturovaných formátů souborů, jako jsou Parquet nebo CSV. S3 bucket uchovává soubory a Athena na ně odkazuje, kdykoli procesy potřebují data z databáze.
Je důležité si uvědomit, že Athena nepodporuje některé funkce, které jsou jinak považovány za standardní, například příkazy pro aktualizaci. Proto je nutné Athenu vnímat jako velmi jednoduché řešení.
Na druhou stranu ale podporuje indexování a dělení. Může se také velmi snadno horizontálně škálovat, protože to je stejně jednoduché jako přidávání nových bucketů do infrastruktury. Pro jednoduché a funkční vytvoření datového jezera to ve většině případů stačí.
Pro optimální výkon je klíčový návrh dat s ohledem na budoucí využití. Měli byste mít jasno v tom, jak chcete data vybírat. Pozdější změny struktury tabulek, když jsou už naplněny velkým množstvím dat, je obtížné.
Athena DB je skvělou volbou a ideálně se hodí pro váš cíl, pokud chcete vytvořit jednoduchý a neměnný datový fond, který je možné snadno horizontálně škálovat.
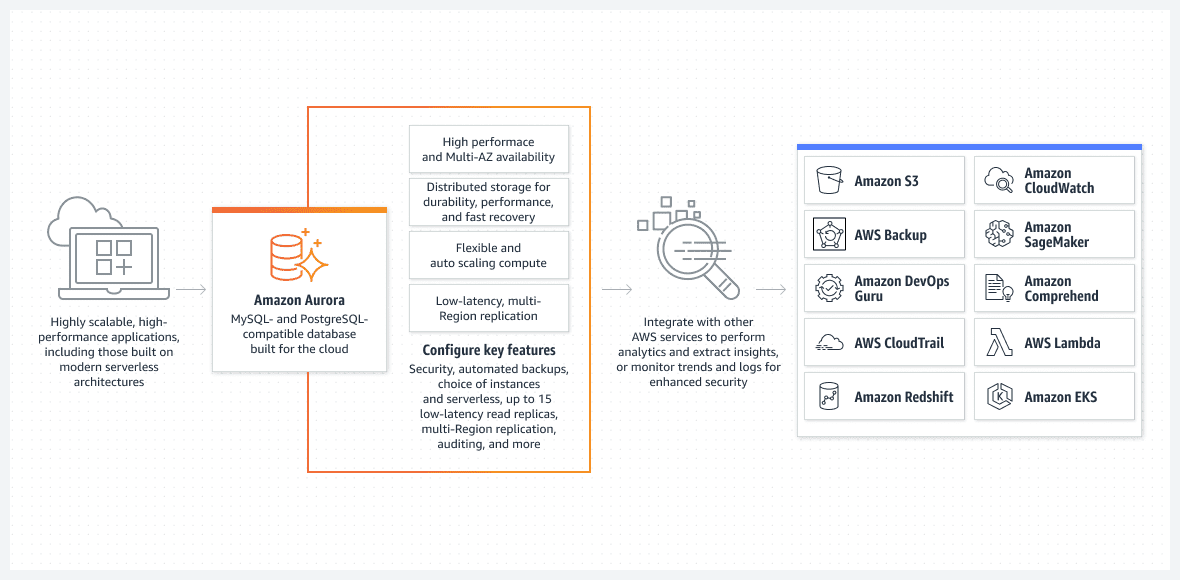
Databáze AWS Aurora
 Zdroj: aws.amazon.com
Zdroj: aws.amazon.com
Athena DB se specializuje na ukládání nespravovaných dat. Tímto způsobem chcete ukládat originální obsah, abyste maximalizovali jeho budoucí opětovné využití. Nicméně, poskytování vybraných výsledků front-endové aplikaci je pomalé.
Jednou z nejlepších možností, hlavně z pohledu snadného nastavení, je databáze Aurora běžící v bezserverovém režimu.
Aurora není základní databáze. Jde o jedno z nejpokročilejších řešení nativních relačních databází v AWS. Je to také vysoce komplexní řešení, které se s každou verzí zlepšuje.
Aurora je unikátní tím, že může běžet v bezserverovém režimu, což ji odlišuje od ostatních relačních služeb. Režim funguje takto:
- Pro konfiguraci clusteru Aurora použijte konzoli AWS. Budete muset zadat standardní hodnoty CPU a RAM a také maximální interval automatického škálování. To ovlivní výkon, který může cluster Aurora dynamicky přidávat nebo odebírat. AWS se na základě aktuálního využití databáze rozhodne, zda navýšit, nebo snížit zdroje.
- Cluster Aurora se nespustí, dokud uživatel nebo proces neodešle skutečný požadavek. Například při spuštění plánovaného dávkového zpracování, nebo když aplikace provede back-end API volání pro načtení dat z databáze. Databáze se automaticky spustí a zůstane aktivní po předem určenou dobu po dokončení požadavku.
- Pokud v databázi nejsou žádné další procesy, cluster Aurora se automaticky vypne.
Ještě jednou zdůrazním, že bezserverová Aurora DB běží pouze tehdy, když musí provádět skutečnou práci. Automaticky spuštěný cluster se opět vypne, pokud neprobíhá žádné zpracování. Platíte pouze za skutečnou práci a ne za čas, kdy je databáze neaktivní.
Bezserverová Aurora je plně spravována AWS a nevyžaduje administrátora.
AWS Amplify
Amplify nabízí bezserverovou platformu pro rychlé nasazení front-end aplikací vytvořených pomocí knihoven JavaScript a React. Není potřeba nastavovat clusterové servery. Kód můžete nasadit přímo z konzole AWS, nebo použít automatizovaný kanál DevOps.
Data uložená v databázích můžete získávat pomocí back-end API volání. Tato volání umožňují přístup ke skutečným datům ve front-end aplikaci. Tým by měl optimalizovat výkon back-endu. Možnost pomalé odezvy v uživatelském rozhraní můžete ještě více omezit, pokud navrhnete efektivní příkazy pro výběr přímo ve voláních API.
AWS Step Functions
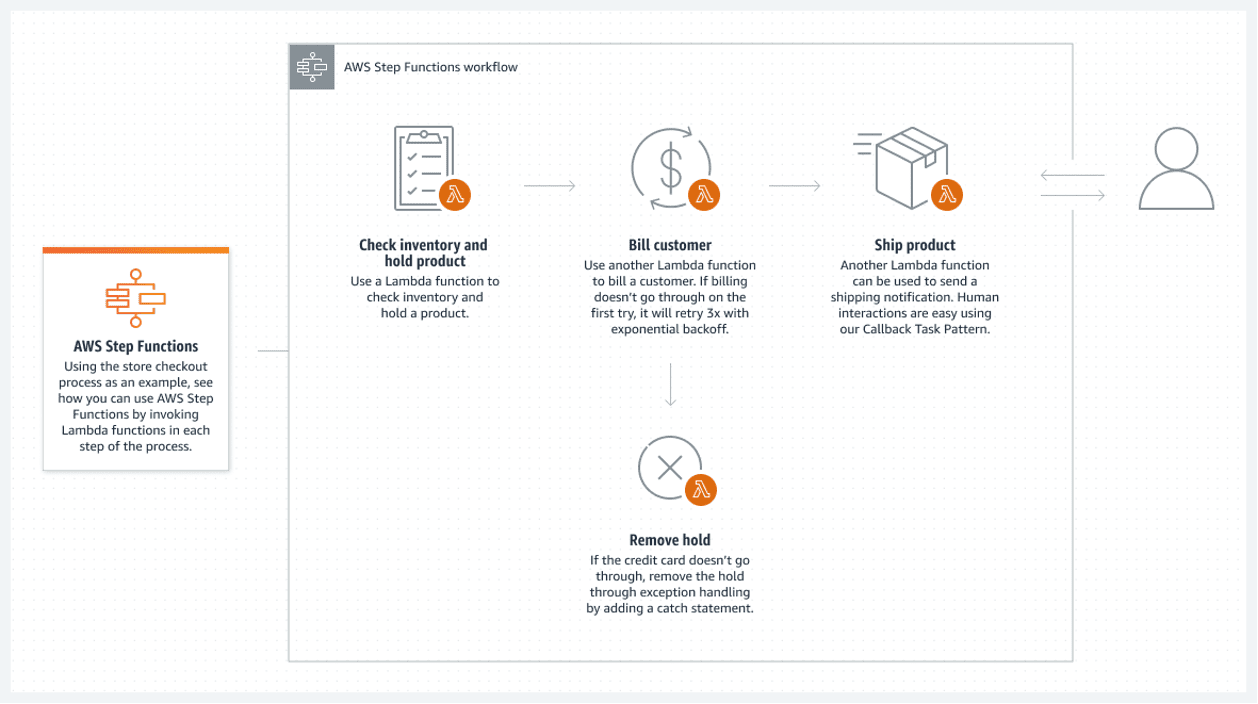 Zdroj: aws.amazon.com
Zdroj: aws.amazon.com
I když jsou všechny hlavní komponenty systému bezserverové, automaticky to nezaručuje celkově bezserverovou architekturu. Toho je možné dosáhnout pouze tehdy, když i dávkové procesy mezi komponentami probíhají bez serveru.
AWS Step Functions nabízejí nejlepší řešení v cloudu AWS. Propojený seznam funkcí AWS Lambda tvoří step function. Tyto funkce vytvářejí vývojový diagram, který má jasné počáteční a koncové stavy. Funkce Lambda, obvykle napsaná v jazyce Python nebo Node JS, je spustitelný kousek kódu, který zpracovává vše, co je potřeba.
Následuje příklad, jak lze využít step function:
Tento bezserverový tok má jednu hlavní nevýhodu: každá funkce Lambda může běžet maximálně 15 minut. Rozdělení toku na menší Lambda funkce to může učinit méně problematickým.
Je možné volat více Lambda funkcí současně v jednom kroku, což v podstatě znamená paralelizovat krok s více lambda prováděnými současně. Před pokračováním se počká na dokončení všech paralelních zpracování lambda. Poté se pokračuje k dalšímu zpracování Lambda.
Závěrem
Bezserverová architektura nabízí jedinečnou příležitost k vytvoření cloudové platformy, která pokrývá celé systémové prostředí. Tato platforma je horizontálně škálovatelná a má přitom nízké provozní náklady.
Je to ideální řešení pro projekty s omezeným rozpočtem. Je to vynikající možnost pro průzkum, zejména když nikdo nezná skutečné zatížení systému. To je obzvláště důležité po úspěšné registraci všech uživatelů. Projektové týmy tak mohou získat celkový přehled o tom, jak systém funguje. Všechny tyto výhody si můžete užívat bez nutnosti dělat kompromisy.
Toto řešení nemusí stačit pro všechny situace, zejména pro ty s vysokými nároky na CPU. Nicméně, cloud AWS se v oblasti bezserverových řešení neustále vyvíjí. Obvykle je dobré před rozhodnutím o bezserverové variantě pro váš další cloudový projekt AWS provést důkladný průzkum.
Podívejte se také na nejlepší bezserverové databáze pro moderní aplikace.