Příkaz `uniq` v operačním systému Linux je nástroj pro analýzu textových souborů, který identifikuje a zpracovává unikátní nebo opakující se řádky. Tento návod se podrobně věnuje jeho možnostem a funkcím a ukazuje, jak maximalizovat jeho efektivitu.
Analýza shodných textových řádků v Linuxu
Příkaz `uniq` je efektivní, adaptabilní a specializuje se na svou úlohu. Nicméně, jako mnoho nástrojů v Linuxu, má své zvláštnosti. S těmito nuancemi je nutné se seznámit, aby nedošlo k nejasnostem při interpretaci výsledků. V průběhu článku si je objasníme.
Příkaz `uniq` je ideální pro konkrétní úkoly a funguje nejlépe v rámci propojených příkazů. Často se kombinuje s příkazem `sort`, protože `uniq` vyžaduje, aby vstupní data byla seřazená.
Pusťme se do práce!
Použití `uniq` bez parametrů
Máme textový soubor s textem písně Roberta Johnsona „I Believe I’ll Dust My Broom“. Podívejme se, jak `uniq` s tímto souborem pracuje.
Pro zobrazení výstupu použijeme příkaz `less`:
uniq dust-my-broom.txt | less
Zobrazí se nám kompletní text písně, včetně duplicitních řádků:
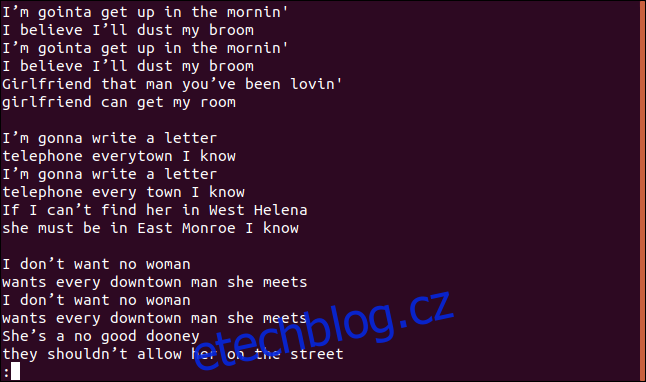
Výsledkem nejsou pouze unikátní řádky, ale ani nejsou identifikovány duplikáty.
To je proto, že implicitně se `uniq` chová, jako byste použili volbu `-u` (unikátní řádky). V takovém případě příkaz `uniq` zobrazí pouze řádky, které jsou v souboru jedinečné. Důvodem, proč jsou zobrazeny i duplicitní řádky, je skutečnost, že příkaz `uniq` detekuje duplikáty pouze v případě, že se vyskytují za sebou. Proto je důležité soubor před použitím `uniq` seřadit.
Po seřazení souboru se duplicitní řádky seskupí a `uniq` je pak může správně detekovat a zpracovat. Provedeme seřazení, předáme výstup do `uniq` a výsledek zobrazíme pomocí `less`.
Zadáme tento příkaz:
sort dust-my-broom.txt | uniq | less

Zobrazí se seřazený seznam unikátních řádků.
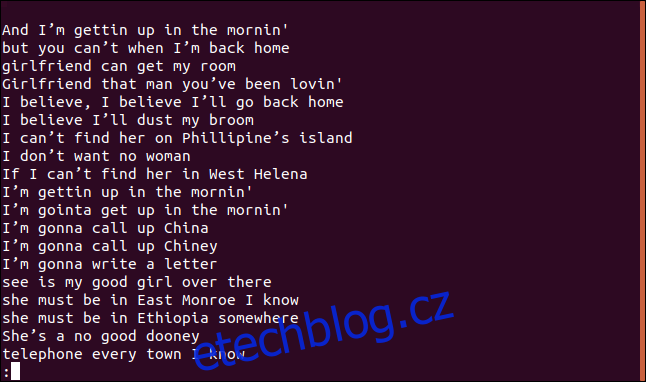
Řádek „I believe I’ll dust my broom“ se v písni opakuje, a to dokonce dvakrát v prvních čtyřech řádcích.
Proč je tedy zobrazen v seznamu jedinečných řádků? Protože při prvním výskytu je každý řádek považován za jedinečný. Pouze následující výskyty jsou brány jako duplikáty. Můžeme to chápat tak, že se zobrazí pouze první výskyt každého unikátního řádku.
Opět seřadíme soubor a výstup přesměrujeme do nového souboru. Díky tomu nemusíme seřadit soubor při každém spuštění příkazu.
Použijeme následující příkaz:
sort dust-my-broom.txt > sorted.txt

Nyní máme seřazený soubor, se kterým můžeme dále pracovat.
Počítání duplicitních výskytů
S volbou `-c` (count) můžeme zobrazit, kolikrát se daný řádek v souboru vyskytuje.
Zadejte následující příkaz:
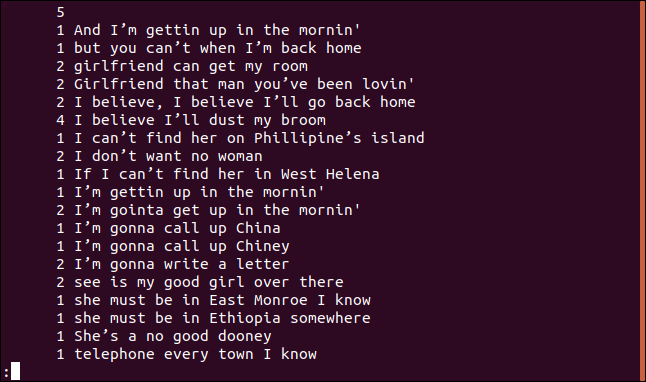
uniq -c sorted.txt | less

Každý řádek začíná číslem, které udává, kolikrát se daný řádek v souboru vyskytuje. První řádek je prázdný a udává počet prázdných řádků v souboru.
Pokud chceme výstup seřadit numericky, můžeme použít výstup z `uniq` v kombinaci s příkazem `sort`. V tomto příkladu použijeme volby `-r` (reverzní) a `-n` (numerické řazení) a výsledky zobrazíme pomocí `less`.
Zadáme tento příkaz:
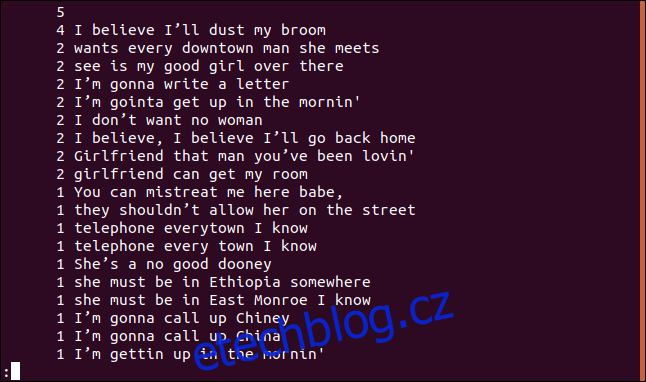
uniq -c sorted.txt | sort -rn | less

Seznam je seřazen sestupně podle četnosti výskytu každého řádku.
Zobrazení pouze duplicitních řádků
Pokud chceme zobrazit pouze ty řádky, které se v souboru opakují, použijeme volbu `-d` (repeated). Bez ohledu na to, kolikrát se řádek v souboru opakuje, zobrazí se pouze jednou.
Pro použití zadejte tento příkaz:
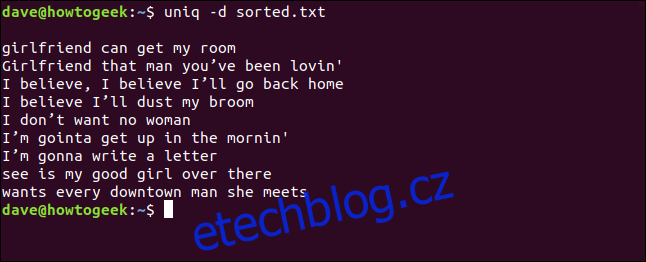
uniq -d sorted.txt

Zobrazí se nám duplicitní řádky. Prázdný řádek na začátku znamená, že v souboru jsou duplicitní prázdné řádky.
Můžeme také kombinovat volby `-d` (repeated) a `-c` (count) a propojit výstup s příkazem `sort`. Získáme tak seřazený seznam řádků, které se v souboru vyskytují alespoň dvakrát.
Zadejte tento příkaz:
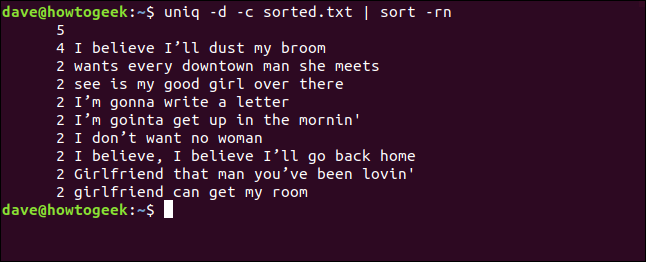
uniq -d -c sorted.txt | sort -rn
Zobrazení všech duplicitních řádků
Pokud chceme vidět všechny duplicitní řádky včetně každého jejich výskytu, můžeme použít volbu `-D` (all-repeated).
Zadejte tento příkaz:
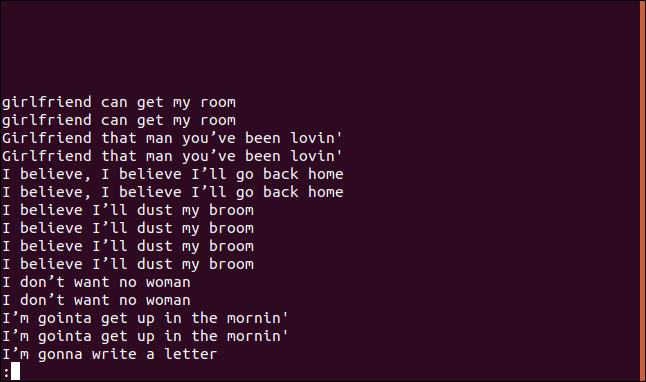
uniq -D sorted.txt | less

Výpis obsahuje záznam pro každý duplikovaný řádek.
S volbou `–group` můžeme zobrazit duplicitní řádky oddělené prázdným řádkem buď před skupinou (prepend), za skupinou (append), nebo před i za skupinou (both).
Použijeme `append` a zadáme tento příkaz:
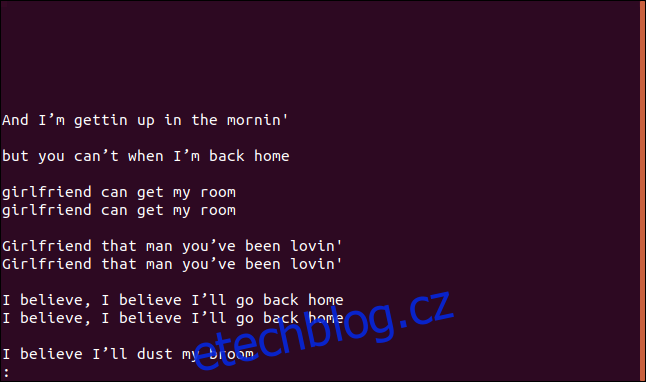
uniq --group=append sorted.txt | less

Skupiny jsou odděleny prázdnými řádky pro lepší čitelnost.
Kontrola specifického počtu znaků
Příkaz `uniq` standardně porovnává celé řádky. Pokud ale chceme omezit kontrolu jen na určitý počet znaků, můžeme použít volbu `-w` (check-chars).
V tomto příkladu zopakujeme předchozí příkaz, ale porovnání omezíme jen na první tři znaky. Provedeme to tímto příkazem:
uniq -w 3 --group=append sorted.txt | less

Výsledky i seskupení jsou zcela odlišné.
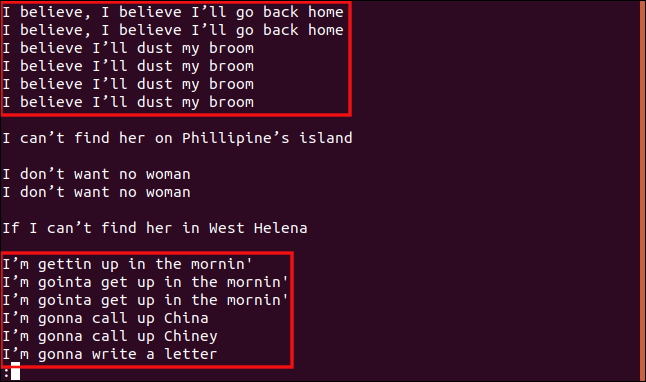
Všechny řádky začínající na „I b“ jsou seskupeny dohromady, protože tato část řádků je identická, a tudíž jsou brány jako duplikáty.
Podobně všechny řádky, které začínají na „I am“ jsou brány jako duplikáty i přesto, že zbytek textu je odlišný.
Ignorování specifického počtu znaků
V některých případech může být užitečné ignorovat určitý počet znaků na začátku každého řádku, například pokud jsou řádky v souboru číslovány. Můžeme například chtít, aby `uniq` přeskočil časové razítko a začal porovnávat řádky až od šestého znaku.
Níže je verze našeho seřazeného souboru s očíslovanými řádky:
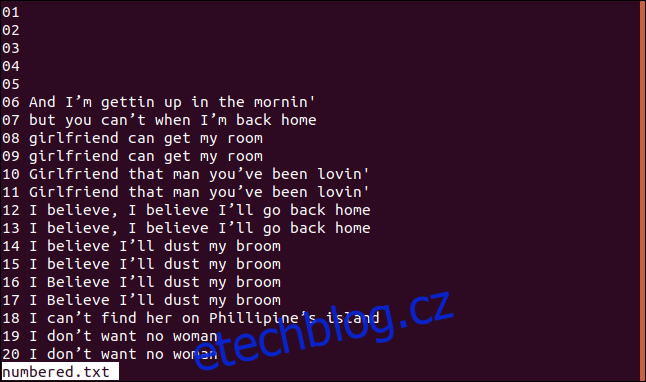
Pokud chceme, aby `uniq` začal porovnávat od třetího znaku, použijeme volbu `-s` (skip-chars) následovně:
uniq -s 3 -d -c numbered.txt
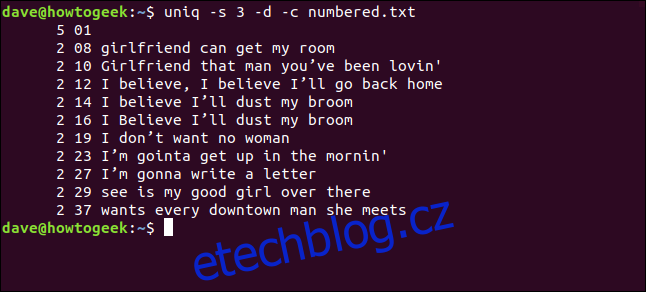
Řádky jsou detekovány jako duplikáty a jsou správně spočítány. Všimněte si, že zobrazená čísla řádků jsou čísla prvního výskytu každého duplikátu.
Místo znaků můžeme také přeskočit pole (řadu znaků a mezer). K tomu použijeme volbu `-f` (fields) pro určení, které pole má `uniq` ignorovat.
Zadáme následující příkaz, abychom řekli `uniq`, ať ignoruje první pole:
uniq -f 1 -d -c numbered.txt
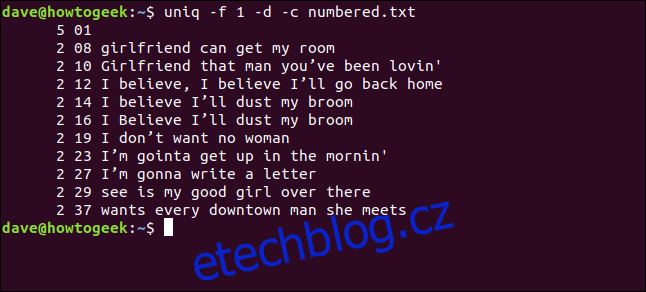
Získáme stejné výsledky, jako když jsme zadali, aby příkaz `uniq` přeskočil tři znaky na začátku každého řádku.
Ignorování velikosti písmen
Standardně `uniq` rozlišuje malá a velká písmena. Pokud se stejné písmeno vyskytne jednou jako velké a jednou jako malé, `uniq` bude řádky považovat za odlišné.
Podívejte se například na výstup tohoto příkazu:
uniq -d -c sorted.txt | sort -rn
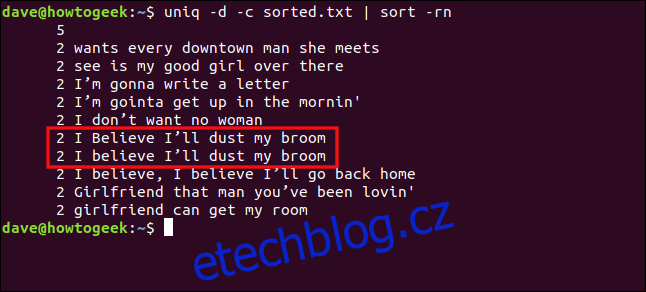
Řádky „I believe I’ll dust my broom“ a „i believe i’ll dust my broom“ nejsou považovány za duplikáty, protože se liší velikostí písmen v „I“ a „i“ .
Pokud ale použijeme volbu `-i` (ignore-case), budou tyto řádky brány jako duplikáty. Zadáme tento příkaz:
uniq -d -c -i sorted.txt | sort -rn
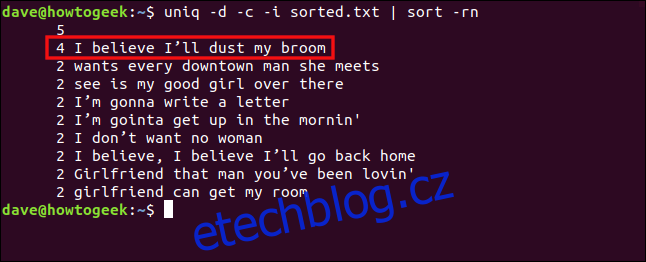
Řádky jsou nyní brány jako duplikáty a jsou seskupeny dohromady.
Linux nabízí mnoho specializovaných nástrojů. Stejně jako mnoho z nich, ani příkaz `uniq` není nástroj, který byste potřebovali každý den.
Proto je důležité znát, který nástroj je nejvhodnější pro daný problém. Díky praxi a testování se brzy stanete expertem.
Alternativně se můžete vždy podívat na How-To Geek, kde pravděpodobně najdete článek o daném problému.