Audio Deepfakes: Může někdo říct, jestli jsou falešné?
Technologie deepfake videí nás naučila nedůvěřovat tomu, co vidíme. Nyní, s příchodem deepfake audia, je zpochybněna i důvěra v to, co slyšíme. Opravdu prezident vyhlásil válku Kanadě? Opravdu vás váš otec žádá o heslo k e-mailu po telefonu?
Přidejme si další existenciální obavy na seznam toho, jak nás vlastní arogance může dovést ke zkáze. V éře Reagana byla největší hrozbou jaderná, chemická a biologická válka.
Následně jsme se strachovali z šedivé hrozby nanotechnologií a globálních pandemií. Dnes čelíme deepfakům – ztrátě kontroly nad naší podobou i hlasem.
Co je to Deepfake Zvuk?
Většina z nás už viděla video deepfake, kde algoritmy strojového učení nahrazují obličej jedné osoby obličejem někoho jiného. Ty nejlepší z nich jsou děsivě realistické. Nyní se totéž děje i se zvukem. Deepfake zvuk vzniká "naklonováním" hlasu, což vede k syntetickému zvuku, který je téměř nerozeznatelný od hlasu skutečné osoby.
Zohaib Ahmed, CEO společnosti Resemble AI, popisuje technologii klonování hlasu své společnosti jako „Photoshop pro hlas”.
Nicméně, špatné úpravy ve Photoshopu jsou snadno rozpoznatelné. Bezpečnostní experti však uvádějí, že lidé se v rozlišení skutečného a falešného deepfake zvuku orientují s přesností pouhých 57 %, což je srovnatelné s hádáním pomocí hodu mincí.
K tomu přispívá fakt, že mnoho hlasových nahrávek pochází z nekvalitních telefonních hovorů nebo jsou nahrávány v hlučném prostředí. Díky tomu jsou deepfake zvuky ještě obtížněji rozpoznatelné. S klesající kvalitou záznamu se stává těžší odhalit známky toho, že hlas není autentický.
Proč by ale někdo potřeboval "Photoshop pro hlasy"?
Přínosy Syntetického Zvuku
Poptávka po syntetickém zvuku je obrovská. Podle Ahmeda jsou investice do této technologie velmi rychle návratné.
To platí zejména pro herní průmysl. Dříve byla řeč jediná složka hry, kterou nešlo vytvořit na vyžádání. Dokonce i v interaktivních hrách se scénami na úrovni filmů jsou verbální interakce s nehratelnými postavami statické.
Technologie se ale rychle vyvíjí. Herní studia mohou nyní naklonovat hlas herce a pomocí nástrojů pro převod textu na řeč mohou postavy pronášet repliky v reálném čase.
Existují i tradiční využití v reklamě a v technické a zákaznické podpoře, kde je zásadní lidsky znějící a autentický hlas, který reaguje osobně a kontextově bez nutnosti lidského zásahu.
Společnosti zabývající se klonováním hlasu vidí velký potenciál i v medicínských aplikacích. Vytvoření náhradního hlasu není v medicíně nic nového – Stephen Hawking používal robotický syntetizovaný hlas po ztrátě svého v roce 1985. Moderní klonování hlasu slibuje něco ještě lepšího.
V roce 2008 společnost CereProc, specializující se na syntetický hlas, navrátila hlas zesnulému filmovému kritikovi Rogeru Ebertovi. CereProc dříve vytvořil webovou stránku, kde lidé mohli zadávat zprávy, které byly poté vysloveny hlasem bývalého prezidenta George Bushe.
Matthew Aylett, hlavní vědecký pracovník CereProc, uvedl, že Ebert si pomyslel: "Pokud dokázali zkopírovat Bushův hlas, měli by být schopni zkopírovat i můj." Ebert požádal společnost o vytvoření náhradního hlasu, což učinili zpracováním velké knihovny jeho hlasových nahrávek.
"Byl to jeden z prvních případů, kdy se to někomu podařilo, a byl to skutečný úspěch," řekl Aylett.
V posledních letech spolupracovalo mnoho společností (včetně CereProc) s ALS Association na Projektu Revoice, který má za cíl poskytovat syntetické hlasy lidem trpícím ALS.
Jak Funguje Syntetický Zvuk
Klonování hlasu je momentálně velkým hitem a mnoho společností vyvíjí vlastní nástroje. Společnosti Resemble AI a Descript nabízejí online ukázky, které si může kdokoli zdarma vyzkoušet. Stačí nahrát fráze, které se objeví na obrazovce a během několika minut se vytvoří model vašeho hlasu.
Za to vděčíme umělé inteligenci, konkrétně algoritmům hlubokého učení, které dokážou přiřadit nahranou řeč k textu a porozumět fonémům, které tvoří váš hlas. Výsledné stavební bloky jazyka jsou poté použity k aproximaci slov, která vás software nikdy neslyšel mluvit.
Základní technologie je známá již delší dobu, ale jak zdůraznil Aylett, bylo potřeba jí trochu pomoci.
"Kopírování hlasu bylo jako pečení koláče," řekl. "Bylo to trochu těžké a existovaly různé způsoby, jak to ručně vyladit, aby to fungovalo."
Vývojáři potřebovali obrovské množství nahrávek hlasu, aby dosáhli přijatelných výsledků. Poté, před několika lety, se situace změnila. Výzkum v oblasti počítačového vidění se ukázal jako zásadní. Vědci vyvinuli generativní adversariální sítě (GAN), které dokázaly poprvé extrapolovat a předpovídat na základě existujících dat.
„Místo toho, aby počítač viděl obrázek koně a řekl "to je kůň", mohl nyní můj model udělat z koně zebru," uvedl Aylett. "Exploze syntézy řeči je tedy způsobena akademickou prací v oblasti počítačového vidění."
Jednou z největších inovací v klonování hlasu bylo celkové snížení množství nezpracovaných dat potřebných k vytvoření hlasového modelu. Dříve systémy vyžadovaly desítky, někdy i stovky hodin zvuku. Nyní lze kompetentní hlasy generovat z pouhých minut obsahu.
Existenciální Strach z Nedůvěry
Tato technologie, spolu s jadernou energií, nanotechnologií, 3D tiskem a CRISPR, je vzrušující i děsivá zároveň. Již se objevily případy, kdy byli lidé podvedeni hlasovými klony. V roce 2019 byla jedna společnost ve Spojeném království podvedena deepfake telefonátem a přišla o peníze.
Nemusíte chodit daleko, abyste našli přesvědčivé zvukové padělky. Kanál YouTube Vokální syntéza představuje známé osobnosti, které pronášejí výroky, které nikdy neřekly, například George W. Bush čte knihu "In Da Club" od 50 Centa. A je to velmi realistické.
Jinde na YouTube najdete bývalé prezidenty, včetně Obamy, Clintonové a Reagana, rapující NWA. Hudba a zvuky na pozadí pomáhají zamaskovat některé zjevné robotické nedostatky, ale i v této nedokonalé formě je potenciál této technologie zřejmý.
Experimentovali jsme s nástroji Resemble AI a Descript a vytvořili si vlastní hlasový klon. Descript používá engine pro klonování hlasu, který se dříve nazýval Lyrebird a byl obzvláště působivý. Byli jsme šokováni kvalitou. Slyšet svůj vlastní hlas říkat věci, o kterých víte, že jste nikdy neřekli, je znepokojující.
Řeč sice nese robotické prvky, ale při běžném poslechu by většina lidí neměla důvod si myslet, že se jedná o podvrh.
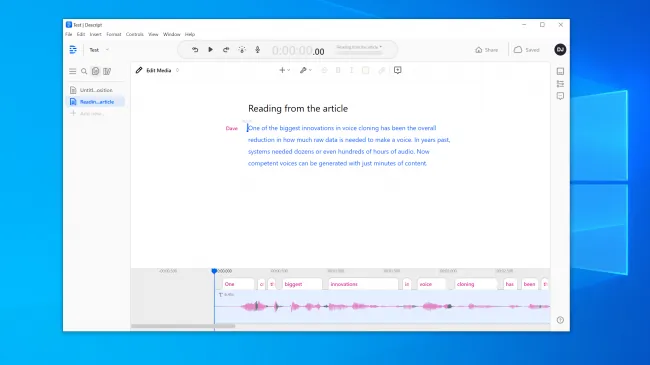
Vkládali jsme větší naděje do Resemble AI. Ta poskytuje nástroje pro vytváření konverzací s více hlasy a změnu expresivity, emocí a tempa dialogu. Nicméně jsme si nemysleli, že hlasový model zachytil základní kvality hlasu, který jsme použili. Bylo nepravděpodobné, že by někoho oklamal.
Zástupce společnosti Resemble AI nám řekl, že „většina lidí je ohromena výsledky, pokud to dělají správně." Vytvořili jsme model hlasu dvakrát, s podobnými výsledky. Je tedy zřejmé, že vytvoření hlasového klonu, který lze použít k digitální krádeži, není vždy snadné.
I tak se zakladatel společnosti Lyrebird (která je nyní součástí Descriptu), Kundan Kumar, domnívá, že jsme již překročili kritický bod.
„V malém procentu případů už jsme tam,“ řekl Kumar. „Pokud použiji syntetický zvuk ke změně několika slov v řeči, je to už tak dobré, že budete mít problém zjistit, co se změnilo.”
Můžeme také předpokládat, že se tato technologie bude časem zlepšovat. Systémy budou potřebovat méně audia pro vytvoření modelu a rychlejší procesory budou schopny sestavit model v reálném čase. Inteligentnější AI se naučí, jak přidat přesvědčivější lidskou kadenci a důraz na řeč bez nutnosti předlohy.
To znamená, že se možná blížíme k široké dostupnosti jednoduchého klonování hlasu.
Etika Pandořiny Skříňky
Zdá se, že většina společností, které v této oblasti pracují, je připravena zacházet s technologií zodpovědně. Resemble AI má například na svých webových stránkách celou sekci věnovanou etice a následující citát je povzbudivý:
„Spolupracujeme se společnostmi prostřednictvím přísného procesu, abychom se ujistili, že hlas, který klonují, je pro ně použitelný a že máme patřičné souhlasy s hlasovými herci.“
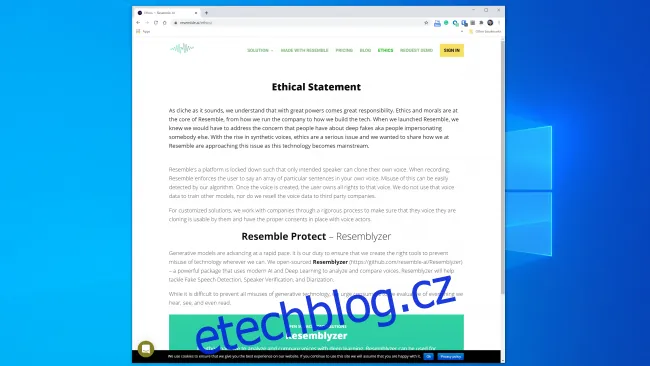
Stejně tak Kumar uvedl, že společnost Lyrebird měla od začátku obavy ze zneužití. To je důvod, proč nyní, jako součást společnosti Descript, umožňuje lidem klonovat pouze svůj vlastní hlas. Resemble i Descript vyžadují, aby lidé nahrávali své vzorky živě, aby se zabránilo klonování hlasu bez souhlasu.
Je povzbudivé, že hlavní komerční hráči zavedli etické zásady. Je však důležité si uvědomit, že tyto společnosti nejsou strážci této technologie. Již existuje řada open-source nástrojů, pro které neexistují žádná pravidla. Podle Henryho Ajdera, vedoucího zpravodajství o hrozbách ve společnosti Deeptrace, ke zneužití technologie nepotřebujete pokročilé znalosti programování.
„Velký pokrok v této oblasti přišel díky spolupráci na platformách, jako je GitHub, a využití open-source implementací dříve publikovaných akademických prací,“ řekl Ajder. „Může to používat kdokoli, kdo má základní znalosti programování.”
Bezpečnostní Experti to Znají
Zločinci se pokoušeli krást peníze po telefonu dávno předtím, než bylo možné hlasové klonování. Bezpečnostní experti byli vždy ve střehu, aby takovýmto pokusům zabránili. Bezpečnostní společnost Pindrop se snaží zastavit bankovní podvody ověřením, zda je volající skutečně tím, za koho se vydává, a to podle jeho hlasu. Jen v roce 2019 Pindrop analyzoval 1,2 miliardy hlasových interakcí a zabránil pokusům o podvod v hodnotě 470 milionů dolarů.
Před příchodem klonování hlasu používali podvodníci různé triky. Nejjednodušší bylo volat s osobními údaji o značce z jiného místa.
„Náš akustický podpis nám umožňuje určit, že hovor přichází z telefonu Skype v Nigérii, a to díky zvukovým charakteristikám,” uvedl generální ředitel Pindropu Vijay Balasubramaniyan. „Pak můžeme porovnat, že zákazník používá telefon AT&T v Atlantě.“
Někteří zločinci si vytvořili kariéru používáním zvuků v pozadí, které má zmást bankovní úředníky.
„Měli jsme podvodníka, kterému jsme říkali Kohoutí Muž, protože měl v pozadí vždy kokrhání kohoutů,“ řekl Balasubramaniyan. „A pak tu byla paní, která používala dětský pláč v pozadí, aby přesvědčila operátory call centra, že prochází těžkým obdobím, a vzbudila jejich sympatie.“
A pak tu jsou mužští zločinci, kteří cílí na ženské bankovní účty.
„Používají technologii ke zvýšení frekvence svého hlasu, aby zněli žensky,” vysvětlil Balasubramaniyan. Někdy jsou úspěšní, ale „občas se software pokazí a zní to jako Chipmunkové.”
Klonování hlasu je samozřejmě jen nejnovější vývoj v tomto neustále narůstajícím boji. Bezpečnostní firmy už zaznamenaly podvodníky, kteří používali syntetický zvuk při takzvaném spearphishingovém útoku.
„U správného cíle může být odměna obrovská,“ řekl Balasubramaniyan. „Takže má smysl věnovat čas vytvoření syntetizovaného hlasu konkrétního jedince.“
Lze Rozpoznat Falešný Hlas?

Pokud jde o rozpoznání falešného hlasu, máme dobré i špatné zprávy. Špatná zpráva je, že se hlasové klony každým dnem zlepšují. Systémy hlubokého učení jsou stále inteligentnější a vytvářejí autentičtější hlasy, které vyžadují méně audio dat.
Jak můžete vidět v tomto klipu, kde prezident Obama řekl MC Renovi, aby se postavil, již jsme se dostali do bodu, kdy vysoce věrný a pečlivě zkonstruovaný hlasový model může znít lidskému uchu velmi přesvědčivě.
Čím delší je zvukový klip, tím je pravděpodobnější, že si všimnete, že je něco v nepořádku. U kratších klipů si však nemusíte všimnout, že je syntetický, zvláště pokud nemáte důvod zpochybňovat jeho legitimitu.
Čím lepší je kvalita zvuku, tím snazší je zaznamenat známky deepfake zvuku. Pokud někdo mluví přímo do studiového mikrofonu, můžete jeho hlas poslouchat velmi detailně. Záznam nekvalitního telefonního hovoru nebo konverzace zachycené na mobilním zařízení v hlučné garáži se bude posuzovat mnohem hůře.
Dobrou zprávou je, že i když mají lidé problém oddělit skutečné od falešného, počítače nemají stejná omezení. Naštěstí již existují nástroje pro ověřování hlasu. Společnost Pindrop má vlastní, které porovnávají různé systémy hlubokého učení. Používají je k ověření, zda je zvukový vzorek autentický. Zkoumají také, zda člověk dokáže vydat všechny zvuky, které jsou v ukázce slyšet.
V závislosti na kvalitě zvuku obsahuje každá sekunda řeči 8 000 až 50 000 datových vzorků, které lze analyzovat.
„Hledáme omezení řeči způsobená lidskou evolucí,“ vysvětlil Balasubramaniyan.
Například dva vokální zvuky mají minimální možné vzájemné oddělení. Je to způsobeno tím, že je fyzicky nemožné je vyslovit rychleji kvůli rychlosti, s jakou se svaly v ústech a hlasivky dokážou samy překonfigurovat.
„Když se podíváme na syntetický zvuk,” řekl Balasubramaniyan, „někdy vidíme věci, a říkáme si: 'Tohle by nikdy nemohl vytvořit člověk, protože jediný, kdo by to dokázal, by musel mít sedm stop dlouhý krk.'”
Existuje také třída zvuků zvaná „frikativy“. Vznikají, když vzduch prochází úzkým zúžením v krku, když vyslovujete písmena jako f, s, v a z. Frikativy je pro systémy hlubokého učení obzvlášť obtížné zvládnout, protože software je má problém odlišit od šumu.
Software pro klonování hlasu tedy alespoň prozatím naráží na skutečnost, že lidé jsou "pytle masa" a vzduch proudí otvory v jejich ...
