Data Lake vs. Data Warehouse: Jaké jsou rozdíly?
Současné podniky se zaměřují na data. Firmy hledají způsoby, jak efektivně těžit a analyzovat informace z mnoha zdrojů, aby zlepšily své tržby a ziskovost.
Jaké je však nejvhodnější místo pro uchovávání a integraci dat z různých zdrojů a jejich co nejefektivnější využití?
Datová jezera a datové sklady jsou oblíbené způsoby, jak spravovat velká objemy dat. Hlavní rozdíly mezi nimi spočívají v tom, jakým způsobem organizace data přijímají, uchovávají a následně využívají. Čtěte dále a dozvíte se více.
Co je datové jezero?
Datové jezero je centralizované úložiště, kde se data z mnoha zdrojů – v libovolném formátu (strukturovaném či nestrukturovaném) – ukládají v původní podobě. Představuje jakousi zásobárnu nezpracovaných dat, u nichž ještě není určen konkrétní účel. Podniky do datových jezer ukládají data, která by v budoucnu mohla být užitečná pro analýzu.
Klíčové charakteristiky datového jezera:
- Obsahuje kombinaci relevantních a irelevantních dat, proto vyžaduje velké množství úložného prostoru.
- Ukládá data v reálném čase i dávková data – například data ze zařízení IoT, sociálních sítí nebo cloudových aplikací v reálném čase a dávková data z databází nebo datových souborů.
- Vyznačuje se plochou architekturou.
- Vzhledem k tomu, že data nejsou zpracována, dokud nejsou potřeba pro analýzu, je nutné je dobře spravovat a udržovat, jinak se může datové jezero proměnit v "datovou bažinu".
Jak tedy můžeme rychle získat data z tak rozsáhlého a zdánlivě chaotického úložiště? Datové jezero využívá pro tento účel metadatové značky a identifikátory!
Co je datový sklad?
Datový sklad je organizovanější a strukturovanější úložiště, které obsahuje data připravená k analýze. Strukturovaná, polostrukturovaná i nestrukturovaná data z mnoha zdrojů se přijímají, integrují, čistí, třídí, transformují a přizpůsobují k následnému využití.
Datový sklad obsahuje velké množství historických i aktuálních dat. Zpravidla se data zpracovávají pro řešení konkrétních obchodních úkolů (analýza). Tyto informace jsou pak dotazovány systémy Business Intelligence (BI) pro účely analýzy, generování reportů a přehledů.
Datové sklady se obvykle skládají z:
- Databáze (SQL nebo NoSQL) pro uchovávání a správu dat.
- Nástrojů pro transformaci a analýzu dat pro jejich přípravu.
- BI nástrojů pro dolování dat, statistickou analýzu, reporting a vizualizaci.
Protože datové sklady slouží specifickému účelu, jsou v nich vždy relevantní data. V datových skladech je také možné využít pokročilé funkce, jako je umělá inteligence a prostorové nebo grafické funkce. Datové sklady vytvořené pro specifickou doménu se nazývají datová tržiště.
Klíčové rozdíly mezi datovými jezery a datovými sklady
Zopakujme si, že datové jezero obsahuje nezpracovaná data, jejichž účel nebyl dopředu definován. Naopak, datový sklad obsahuje data, která jsou připravena k analýze a jsou již ve své nejlepší formě.
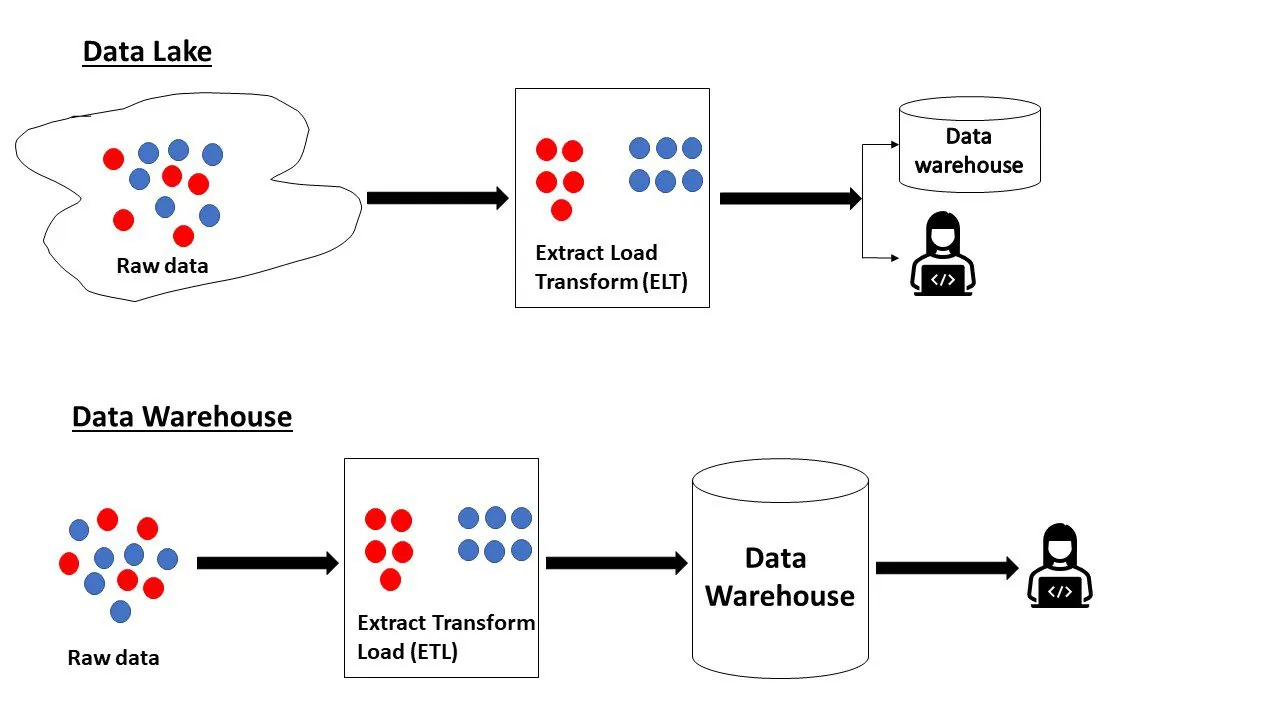
Následuje srovnání některých rozdílů mezi datovým jezerem a datovým skladem:
| Data Lake | Data Warehouse |
| Přijímá surová nebo zpracovaná data v libovolném formátu z mnoha zdrojů. | Získává strukturovaná data z mnoha zdrojů pro analýzu a vytváření reportů. |
| Schéma se vytváří "za chodu" podle potřeby (schema-on-read). | Předdefinované schéma při zápisu do skladu (schema-on-write). |
| Nová data lze snadno přidávat. | Data jsou připravena až po zpracování, takže každá nová změna vyžaduje více času a úsilí. |
| Data je třeba aktualizovat a spravovat, aby byla relevantní. | Data jsou již ve své nejlepší formě, proto nevyžadují zvláštní údržbu. |
| Skládá se z obrovských objemů velkých dat (petabajty). | Množství dat je obvykle menší než v datovém jezeře (terabajty). Datový sklad může obsahovat provozní data celé organizace, analytická data nebo data relevantní pro specifickou doménu. |
| Využívají ho datoví specialisté pro různé účely, například streamovanou analýzu, umělou inteligenci, prediktivní analýzu a mnoho dalších případů použití. | Používají ho obchodní analytici pro zpracování transakcí (OLTP), provozní analýzu (OLAP), reporting, vytváření vizualizací. |
| Data lze uchovávat a archivovat po delší dobu, aby je bylo možné kdykoliv analyzovat. | Data je nutné často čistit, aby se do nich vešla nejaktuálnější data. |
| Úložiště je levné. | Ukládání a zpracování jsou nákladné a časově náročné, a proto by měly být pečlivě plánovány. |
| Datoví specialisté mohou zkoumáním dat objevovat nové problémy a řešení. | Rozsah dat je omezen na konkrétní obchodní problém. |
| Vzhledem k tomu, že data nejsou organizována specifickým způsobem, k ukládání dat lze použít relační i nerelační databáze. | Datové sklady obvykle využívají relační databáze, protože data musí být v konkrétním formátu. |
Příklady využití datových jezer a datových skladů
Může se zdát, že datové jezero je vhodnější volbou, protože je škálovatelnější, flexibilnější a cenově dostupnější. Datový sklad ale může být skvělým nápadem, pokud potřebujete relevantnější a strukturovanější data pro specifickou analýzu.
Níže uvádíme některé příklady využití datového jezera:
#1. Dodavatelský řetězec a řízení
Obrovské objemy dat v datových jezerech pomáhají s prediktivní analýzou v dopravě a logistice. S využitím historických a aktuálních dat mohou firmy efektivně plánovat každodenní operace, sledovat pohyb zásob v reálném čase a optimalizovat náklady.
#2. Zdravotní péče
Datové jezero obsahuje veškeré historické i aktuální informace o pacientech. To je užitečné při výzkumu, hledání vzorců, poskytování lepší a včasné léčby nemocí, automatizaci diagnostiky a získávání aktuálních podrobností o zdravotním stavu pacienta.
#3. Streamování dat a IoT
Datová jezera mohou průběžně přijímat streamovaná data odesílaná do analytických kanálů pro kontinuální reporting a odhalování jakýchkoli neobvyklých aktivit či pohybů. To je možné díky schopnosti datových jezer shromažďovat data (téměř) v reálném čase.
Níže uvádíme některé příklady využití datového skladu:
#1. Finance
Finanční informace společnosti mohou být vhodnější pro datový sklad. Zaměstnanci mohou snadno přistupovat k organizovaným a strukturovaným informacím ve formě grafů a reportů, aby mohli řídit finanční procesy, zvládat rizika a činit strategická rozhodnutí.
#2. Marketing a segmentace zákazníků
Datový sklad vytváří jediný zdroj „pravdivých“ dat o zákaznících, shromážděných z mnoha zdrojů. Společnosti mohou tato data analyzovat, aby pochopily chování zákazníků, nabízely personalizované slevy, segmentovaly zákazníky na základě jejich preferencí a generovaly více potenciálních zákazníků.
#3. Firemní panely a reporty
Mnoho firem využívá datové sklady CRM a ERP k získávání dat o externích i interních zákaznících. Data jsou vždy relevantní a lze je bez obav využít k vytváření libovolných reportů a vizualizací.
#4. Migrace dat ze starších systémů
S pomocí funkcí ETL datových skladů mohou firmy snadno transformovat data ze starších systémů do použitelnějšího formátu, který mohou nové systémy analyzovat. To pomáhá organizacím získat přehled o historických trendech a přijímat přesná obchodní rozhodnutí.
Příklady nástrojů pro datová jezera
Mezi nejvýznamnější poskytovatele řešení pro datová jezera patří:
- Microsoft Azure – Azure umožňuje ukládat a analyzovat petabajty dat. Azure usnadňuje ladění a optimalizaci programů pro velká data.
- Google Cloud – Google cloud nabízí cenově efektivní příjem, ukládání a analýzu obrovských objemů velkých dat libovolného typu. Je také integrován s analytickými nástroji, jako jsou Apache Spark, BigQuery a další akcelerátory pro analýzu.
- Atlas MongoDB – Atlas data lake je plně spravované úložiště pro datová jezera. Nabízí nákladově efektivní způsoby ukládání rozsáhlých dat a dokáže spouštět vysoce výkonné dotazy s menšími nároky na výpočetní výkon, čímž šetří čas a náklady.
- Amazon S3 – Cloud AWS nabízí potřebné nástroje k vybudování flexibilního, bezpečného a cenově efektivního datového jezera. Poskytuje interaktivní konzoli pro správu uživatelů datového jezera a řízení jejich přístupu.
Příklady nástrojů pro datové sklady
Mezi přední poskytovatele řešení pro datové sklady patří:
- SAP – Datový sklad SAP umožňuje uživatelům sémanticky přistupovat k bohatým datům z mnoha zdrojů. Firmy mohou bezpečně sdílet poznatky a modely, urychlit rozhodování a bezpečně kombinovat externí a interní data.
- ClicData – Inteligentní a integrovaný datový sklad ClicData zajišťuje integritu, kvalitu a snadné vykazování dat. ClicData nabízí jak plánovací systémy, tak i API v reálném čase, takže máte vždy k dispozici aktuální data.
- Amazon Redshift – Jeden z nejpoužívanějších datových skladů, Redshift, používá SQL k analýze všech typů dat, které se nacházejí v různých databázích, jezerech nebo jiných úložištích. Nabízí skvělou rovnováhu mezi cenou a výkonem.
- IBM Db2 Warehouse – IBM nabízí interní, cloudová i integrovaná řešení pro datové sklady. Integruje také nástroje strojového učení a umělé inteligence pro hlubší analýzu dat a sdílí společný SQL engine pro zefektivnění dotazů.
- Oracle Cloud Data Warehouse – Oracle využívá in-memory databázi a nabízí grafické, strojové učení a prostorové funkce, které umožňují hluboké proniknutí do dat pro rychlejší a bohatší analýzu.
Závěrem
Datová jezera i datové sklady mají své výhody a ideální případy použití. Zatímco datová jezera jsou škálovatelnější a flexibilnější, datové sklady vždy poskytují spolehlivé a strukturované informace. Implementace datového jezera je relativně nová záležitost, zatímco datový sklad je zavedený koncept, který mnoho firem používá k efektivní správě svých interních i externích dat.
