Technika souborového učení vám může výrazně pomoci při zdokonalování rozhodovacích procesů a efektivním řešení rozmanitých problémů v reálném světě, a to díky kombinování poznatků z několika různých modelů.
Strojové učení (ML) nadále proniká do mnoha oblastí a sektorů, ať už se jedná o finance, zdravotnictví, vývoj softwaru nebo bezpečnostní technologie.
Kvalitní trénink modelů strojového učení vám může dopomoci k dosažení značného pokroku ve vašem podnikání nebo profesi. Existuje mnoho metod, jak toho docílit.
V tomto článku se zaměříme na souborové učení, jeho význam, praktické aplikace a používané techniky.
Čtěte dále a dozvíte se více!
Co je to souborové učení?
V kontextu strojového učení a statistiky se termín „soubor“ používá pro označení metod, které vytvářejí různé hypotézy s využitím společného základního algoritmu.
Souborové učení je specifický přístup ve strojovém učení, který spočívá ve strategickém vytváření a kombinování více modelů (považovaných za experty nebo klasifikátory). Hlavním cílem je vyřešení daného výpočetního problému nebo vytvoření přesnějších predikcí.
Tento přístup si klade za cíl zlepšit predikční schopnosti, aproximaci funkcí, klasifikaci a celkovou efektivitu daného modelu. Dále se používá ke snížení rizika, že dojde k výběru nevhodného nebo méně efektivního modelu. Pro dosažení lepších výsledků predikce se využívá hned několik učebních algoritmů.
Důležitost souborového učení v ML
Při práci s modely strojového učení se setkáváme s různými faktory, jako je zkreslení, variabilita a šum, které mohou vést k chybám. Souborové učení může pomoci minimalizovat tyto zdroje chyb a zajistit vyšší stabilitu a přesnost vašich ML algoritmů.
Níže uvádíme hlavní důvody, proč je souborové učení tak široce využíváno:
Výběr optimálního klasifikátoru
Souborové učení vám napomáhá při výběru lepšího modelu nebo klasifikátoru, čímž se snižuje riziko spojené s výběrem nesprávného modelu.
Pro různé typy problémů se používají rozdílné typy klasifikátorů, jako jsou např. podpůrné vektorové stroje (SVM), vícevrstvý perceptron (MLP), naivní Bayesovy klasifikátory, rozhodovací stromy atd. Dále existují rozličné implementace klasifikačních algoritmů, ze kterých je třeba vybírat. Výkon na různých trénovacích datech se také může lišit.
Nicméně, namísto spoléhání se pouze na jeden model, můžete využít soubor všech těchto modelů a kombinovat jejich individuální výstupy. Tím se vyhnete výběru modelů s nižším výkonem.
Dostupnost dat
Mnohé metody a modely ML nejsou tak účinné, pokud jim poskytneme buď příliš málo, nebo naopak příliš velké množství dat.
Souborové učení je na druhou stranu schopno fungovat efektivně v obou situacích, ať už je objem dat malý nebo naopak velmi rozsáhlý.
- Pokud je množství dat omezené, můžete využít bootstrapping pro trénování různých klasifikátorů pomocí rozdílných vzorků dat vytvořených pomocí bootstrapu.
- V případě, že je k dispozici rozsáhlé množství dat, které by mohlo ztížit trénink jediného klasifikátoru, lze data strategicky rozdělit na menší podmnožiny.
Komplexita

Jeden klasifikátor nemusí být schopen řešit velmi složité problémy. Jejich rozhodovací hranice, které oddělují data různých tříd, mohou být dosti komplexní. Pokud proto použijete lineární klasifikátor na nelineární, komplexní hranici, nebude schopen se ji naučit.
Jestliže ale správně zkombinujete soubor vhodných lineárních klasifikátorů, můžete dosáhnout toho, že se danou nelineární hranici naučí. Klasifikátor rozdělí data do mnoha jednodušších a menších částí, kde se každý klasifikátor naučí pouze jednu zjednodušenou část. Různé klasifikátory se dále zkombinují, aby se získala přibližná hranice rozhodnutí.
Odhad spolehlivosti
V rámci souborového učení je rozhodnutí, které systém učiní, spojeno s přidělením míry důvěryhodnosti. Představte si situaci, kdy máte soubor různých klasifikátorů trénovaných na daný problém. Pokud se většina klasifikátorů shodne na určitém rozhodnutí, pak lze jeho výsledek považovat za vysoce spolehlivé rozhodnutí.
Na druhou stranu, pokud s rozhodnutím nesouhlasí polovina klasifikátorů, je toto rozhodnutí považováno za nedůvěryhodné.
Nicméně, nízká nebo vysoká míra důvěry není vždy zárukou správného rozhodnutí. Nicméně, je pravděpodobnější, že rozhodnutí s vysokou mírou jistoty bude správné, pokud je soubor řádně trénovaný.
Přesnost s Data Fusion
Data shromážděná z více zdrojů mohou, pokud jsou strategicky kombinována, zvýšit přesnost rozhodnutí v klasifikaci. Tato přesnost bývá vyšší než v případě použití dat z jediného zdroje.
Jak souborové učení funguje?
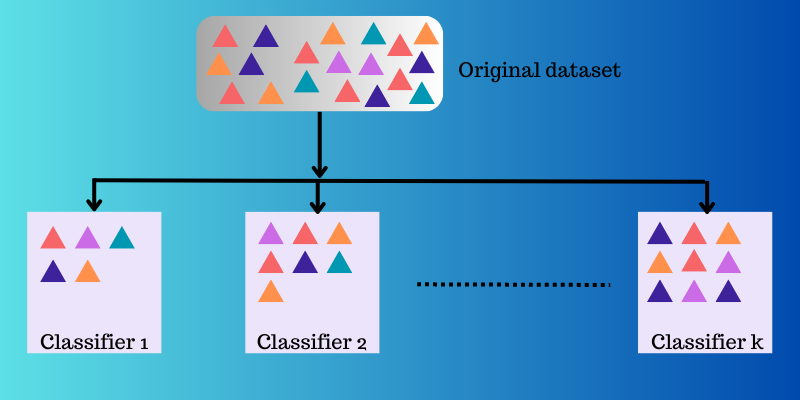
Souborové učení kombinuje mapovací funkce, které se naučily různé klasifikátory, a nakonec je spojuje do jedné mapovací funkce.
Následuje příklad, jak funguje souborové učení.
Příklad: Vyvíjíte aplikaci pro objednávání jídla. Abychom zajistili uživatelům vysokou kvalitu, je žádoucí shromáždit jejich zpětnou vazbu týkající se problémů, se kterými se potýkají, chyb, nedostatků atd.
Za tímto účelem se můžete dotazovat rodinných příslušníků, přátel, kolegů a dalších lidí, se kterými jste v pravidelném kontaktu, na jejich preference ohledně jídla a jejich zkušenosti s online objednáváním. Aplikaci můžete také spustit v beta verzi a sbírat zpětnou vazbu v reálném čase bez zkreslení.
V tomto případě tedy dochází k zohledňování mnoha nápadů a pohledů od různých lidí, což pomáhá zlepšovat uživatelský zážitek.
Stejným způsobem funguje souborové učení a jeho modely. Využívá soubor modelů a kombinuje je, aby dosáhl konečného výsledku, což přispívá ke zlepšení přesnosti a výkonnosti predikcí.
Základní techniky souborového učení
#1. Režim (Modus)
„Režim“ představuje hodnotu, která se v datové sadě vyskytuje nejčastěji. V kontextu souborového učení používají odborníci ML několik modelů k vytváření predikcí pro každý datový bod. Tyto predikce se považují za jednotlivé hlasy. Predikce, která byla předpovězena většinou modelů, je považována za finální. Tato technika se nejčastěji používá u problémů klasifikace.
Příklad: Pokud čtyři lidé ohodnotili vaši aplikaci známkou 4, a jeden ji ohodnotil známkou 3, pak by režim byl 4, protože většina hlasovala pro 4.
#2. Průměr / Aritmetický průměr
Při použití této techniky odborníci vezmou v úvahu všechny predikce modelu a vypočítají jejich průměr, aby se dostali ke konečné predikci. Většinou se používá při vytváření predikcí pro regresní problémy, výpočty pravděpodobností v klasifikačních problémech a další.
Příklad: V předchozím příkladu, kde čtyři lidé ohodnotili vaši aplikaci známkou 4, zatímco jedna osoba ji ohodnotila známkou 3, by průměr byl (4+4+4+4+3)/5=3,8
#3. Vážený průměr
V rámci této metody souborového učení přidělují odborníci různým modelům různé váhy pro vytváření predikcí. Přidělená váha zde popisuje význam každého modelu.
Příklad: Předpokládejme, že 5 osob poskytlo zpětnou vazbu k vaší aplikaci. 3 z nich jsou vývojáři aplikací, zatímco 2 nemají s vývojem aplikací žádné zkušenosti. Proto bude zpětná vazba od těchto 3 lidí mít větší váhu než od zbylých 2.
Pokročilé techniky souborového učení
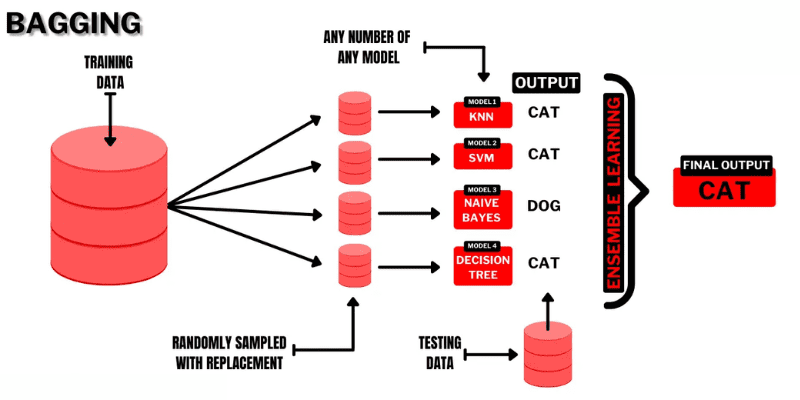
#1. Bagging
Bagging (Bootstrap AGGregatING) je intuitivní a jednoduchá technika souborového učení, která dosahuje dobrých výsledků. Jak název napovídá, vychází z kombinace dvou pojmů, „Bootstrap“ a „agregace“.
Bootstrapping je další metoda vzorkování, při které je třeba vytvořit podmnožiny několika pozorování z původní datové sady s náhradou. Velikost podmnožiny zde bude stejná jako velikost původní datové sady.
 Zdroj: Buggy programmer
Zdroj: Buggy programmer
Při použití baggingu se podmnožiny, nebo takzvané „bagy“, používají k porozumění rozložení celé sady. V rámci baggingu ale mohou být podmnožiny menší než původní datový soubor. Tato metoda pracuje s jedním algoritmem ML. Cílem kombinování výsledků z různých modelů je dosáhnout generalizovaného výsledku.
Takto funguje bagging:
- Z původní sady se vygeneruje několik podmnožin a vyberou se pozorování s náhradami. Podmnožiny se používají při trénování modelů nebo rozhodovacích stromů.
- Pro každou podmnožinu se vytvoří slabý nebo základní model. Modely jsou na sobě nezávislé a běží paralelně.
- Konečná predikce se provede kombinací každé predikce z každého modelu pomocí statistických metod, jako je průměrování, hlasování atd.
Mezi populární algoritmy používané v rámci této techniky souboru patří:
- Náhodný les
- Sbalené rozhodovací stromy
Výhodou této metody je, že pomáhá udržovat chyby rozptylu v rozhodovacích stromech na minimu.
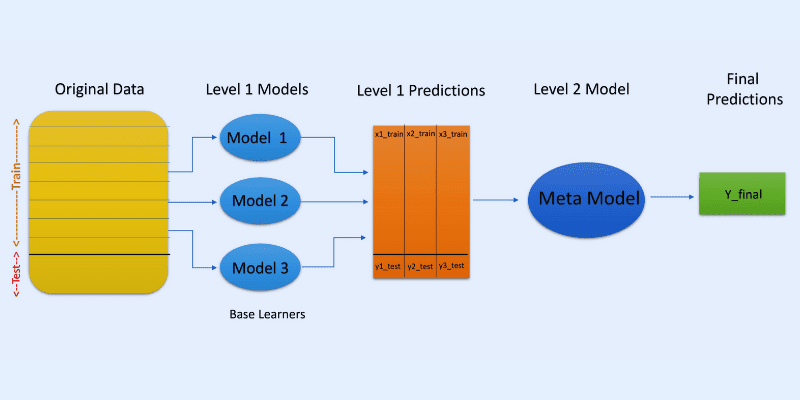
#2. Stohování (Stacking)
 Zdroj obrázku: OpenGenus IQ
Zdroj obrázku: OpenGenus IQ
Při stohování nebo zobecňování se skládané predikce z různých modelů, jako je rozhodovací strom, používají pro vytvoření nového modelu pro předpovědi na testovací sadě.
Stohování zahrnuje vytvoření bootstrapped podmnožin dat pro tréninkové modely, podobně jako bagging. Výstup modelů je zde však brán jako vstup, který je následně předán dalšímu klasifikátoru, známému jako metaklasifikátor, pro konečnou predikci vzorků.
Důvodem, proč se používají dvě klasifikační vrstvy, je ověření, zda se trénovací datové sady správně naučily. Přestože je běžný dvouvrstvý přístup, lze použít i více vrstev.
Můžete například použít 3-5 modelů v první vrstvě nebo úrovni 1 a jeden model ve vrstvě 2 nebo úrovni 2. Druhá vrstva slouží ke kombinování predikcí získaných v úrovni 1, a vytváří konečnou predikci.
Kromě toho lze pro agregaci predikcí použít jakýkoli model strojového učení; běžné jsou lineární modely, jako je lineární regrese, logistická regrese atd.
Mezi populární algoritmy ML používané při stohování patří:
- Míchání
- Super soubor
- Naskládané modely
Poznámka: Při prolnutí se používá validační nebo holdout sada z trénovací datové sady pro vytváření predikcí. Na rozdíl od vrstvení, prolnutí zahrnuje predikce, které se provádějí pouze na vyhrazených datech.
#3. Posilování (Boosting)
Boosting je iterativní metoda souborového učení, která upravuje váhu konkrétního pozorování v závislosti na jeho minulé nebo předchozí klasifikaci. To znamená, že každý následující model se zaměřuje na opravu chyb zjištěných v předchozím modelu.
Pokud pozorování není klasifikováno správně, pak zesílení zvýší jeho váhu.
Při posilování odborníci nejprve trénují první posilovací algoritmus na kompletní datové sadě. Poté sestaví následující ML algoritmy za využití reziduí extrahovaných z předchozího posilovacího algoritmu. Nesprávně klasifikovaným pozorováním předpovídaným předchozím modelem je tak přiřazena větší váha.
Postup funguje následovně:
- Z původní datové sady se vygeneruje podmnožina. Každý datový bod má na začátku stejnou váhu.
- Základní model je vytvořen na podmnožině.
- Predikce se provádí na kompletní datové sadě.
- Pomocí skutečných a predikovaných hodnot se vypočítají chyby.
- Nesprávně predikovaná pozorování získají větší váhu.
- Vytvoří se nový model a na této datové sadě se provede konečná predikce, přičemž se model pokusí napravit dříve provedené chyby. Podobným způsobem se vytvoří více modelů, přičemž každý opraví chyby z předchozího modelu.
- Konečná predikce se provede z konečného modelu, což je vážený průměr všech modelů.
Mezi oblíbené algoritmy posilování patří:
- CatBoost
- LightGBM
- AdaBoost
Výhodou posilování je, že generuje lepší predikce a snižuje chyby způsobené zkreslením.
Další techniky souborového učení

Směs expertů: Tato metoda se využívá pro trénování více klasifikátorů, jejichž výstupy se kombinují pomocí obecného lineárního pravidla. Váhy pro jednotlivé kombinace jsou zde určeny pomocí trénovatelného modelu.
Většinové hlasování: Zahrnuje výběr lichého počtu klasifikátorů a pro každý vzorek se vypočítají predikce. Třída, která od klasifikátorů získá nejvíce „hlasů“, se stane předpokládanou třídou souboru. Využívá se k řešení problémů, jako je binární klasifikace.
Maximální pravidlo: Tato metoda využívá rozdělení pravděpodobnosti každého klasifikátoru a při vytváření předpovědí využívá míru spolehlivosti. Uplatnění nalézá v problémech více-třídní klasifikace.
Praktické využití souborového učení
#1. Detekce obličeje a emocí
Souborové učení využívá techniky, jako je analýza nezávislých komponent (ICA) k provádění detekce obličeje.
Dále se souborové učení používá při zjišťování emocí člověka prostřednictvím analýzy řeči. Jeho schopnosti navíc umožňují uživatelům provádět detekci emocí obličeje.
#2. Bezpečnostní aplikace
Detekce podvodů: Souborové učení napomáhá ke zvýšení výkonu modelování normálního chování. Proto se považuje za účinný nástroj při odhalování podvodných aktivit, například v systémech kreditních karet a bankovnictví, telekomunikačních podvodech, praní špinavých peněz atd.

DDoS: Distribuované odmítnutí služby (DDoS) je závažný útok, který může postihnout ISP. Klasifikátory souborů dokáží omezit detekci chyb a také rozlišit útoky od běžného provozu.
Detekce narušení: Souborové učení je použitelné v monitorovacích systémech, jako jsou nástroje detekce narušení, kde slouží k detekci kódů narušitelů pomocí monitorování sítí nebo systémů, vyhledávání anomálií a podobně.
Detekce malwaru: Souborové učení je poměrně efektivní při odhalování a klasifikaci škodlivého kódu, jako jsou počítačové viry a červy, ransomware, trojské koně, spyware atd. pomocí technik strojového učení.
#3. Přírůstkové učení
Při přírůstkovém učení se algoritmus ML učí z nové datové sady a zároveň si zachovává předchozí znalosti, aniž by měl přístup k předchozím datům. Systémy souborového učení se v přírůstkovém učení používají tak, že pro každou novou datovou sadu se přidá nový klasifikátor.
#4. Medicína
Souborové klasifikátory jsou užitečné v lékařské diagnostice, například při detekci neuro-kognitivních poruch (jako je Alzheimerova choroba). Detekce se provádí tak, že se jako vstupy berou MRI datové sady a provádí se klasifikace cervikální cytologie. Dále se využívá v proteomice (studium proteinů), neurovědě a dalších oblastech.
#5. Dálkový průzkum Země
Detekce změn: Souborové klasifikátory se používají k provádění detekce změn pomocí metod, jako je bayesovské průměrování a většinové hlasování.
Mapování krajinného pokryvu: K efektivnímu zjišťování a mapování krajinného pokryvu se používají metody souborového učení, jako je posilování, rozhodovací stromy, analýza hlavních komponent jádra (KPCA) atd.
#6. Finance
Přesnost je klíčový aspekt financí, ať už jde o výpočty nebo predikce. Má zásadní vliv na výsledky vašich rozhodnutí. Souborové metody mohou analyzovat změny v datech akciového trhu, odhalovat manipulaci s cenami akcií a další.
Další vzdělávací zdroje

#1. Ensemble Methods for Machine Learning
Tato kniha vám pomůže naučit se a implementovat důležité metody souborového učení od základů.
#2. Ensemble Methods: Foundations and Algorithms
Tato kniha představuje základy souborového učení a jeho algoritmy. Rovněž popisuje, jak se používá v reálném světě.
#3. Ensemble Learning
Nabízí úvod do metody sjednoceného souboru, jeho výzvy, aplikace atd.
#4. Ensemble Machine Learning: Methods and Applications:
Poskytuje komplexní přehled o pokročilých technikách souborového učení.
Závěr
Doufáme, že nyní máte základní představu o souborovém učení, jeho metodách, praktických příkladech použití a důvodech, proč může být prospěšné. Souborové učení má potenciál řešit mnoho problémů z reálného života, od oblasti bezpečnosti a vývoje aplikací po finance, medicínu a další. Jeho využití se rozšiřuje, a je tedy pravděpodobné, že v budoucnu dojde k dalšímu vylepšování tohoto konceptu.
Dále můžete prozkoumat některé nástroje pro generování syntetických dat pro trénování modelů strojového učení.