Používání linuxových rour umožňuje koordinovat a propojovat různé nástroje příkazové řádky. Zjednodušte komplexní úkoly a dosáhněte vyšší efektivity práce spojením menších, specializovaných příkazů do efektivního celku. Ukážeme vám, jak na to.
Roury: Klíčový prvek Linuxu
Roury patří mezi nejcennější funkce, které systémy Linux a Unix nabízejí. Jejich využití je nesmírně široké. Ať už narazíte na jakýkoli článek týkající se příkazové řádky Linuxu – ať už na jakémkoliv webu – zjistíte, že se roury objevují velmi často. I v článcích na How-To Geek se s nimi setkáte téměř v každém.
Linuxové roury umožňují provádět operace, které nejsou přímo dostupné ve shellu. Filozofie designu Linuxu klade důraz na existenci mnoha malých utilit, které velmi dobře plní svou specifickou funkci, bez zbytečných přídavků. Díky tomu můžete řetězit příkazy pomocí rour a výstup jednoho příkazu se stává vstupem pro další. Každý z příkazů přináší své unikátní schopnosti a vy tak můžete sestavit velmi efektivní tým.
Jednoduchý příklad použití
Představte si, že máte adresář obsahující různé typy souborů a chcete zjistit, kolik souborů určitého typu se v něm nachází. Existují různé způsoby, jak toho dosáhnout, ale v tomto příkladu se zaměříme na použití rour.
Seznam souborů v adresáři získáte snadno pomocí příkazu `ls`:
ls
Pro oddělení souborů, o které se zajímáme, použijeme příkaz `grep`. Chceme vyhledat soubory, které mají v názvu nebo příponě slovo „page“.
K propojení výstupu z příkazu `ls` s příkazem `grep` použijeme speciální znak shellu „|“:
ls | grep "page"

Příkaz `grep` vypíše řádky, které odpovídají hledanému vzoru. Tím získáme seznam obsahující pouze soubory s příponou „.page“.
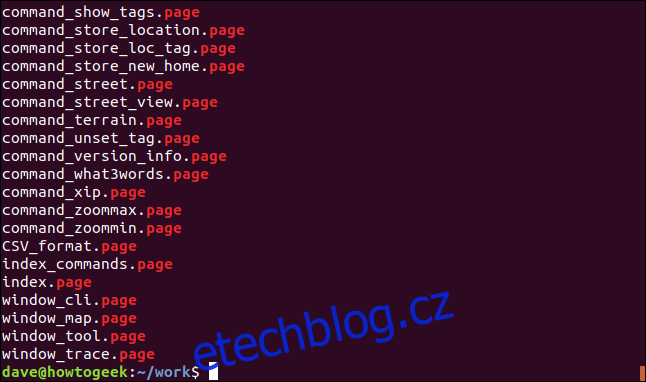
I tento jednoduchý příklad demonstruje sílu rour. Výstup příkazu `ls` nebyl zobrazen v terminálu, ale byl předán jako data příkazu `grep`. Výstup, který vidíme, pochází z příkazu `grep`, který je posledním příkazem v řetězci.
Rozšíření řetězce příkazů
Nyní můžeme začít rozšiřovat náš řetězec propojených příkazů. Můžeme spočítat soubory s příponou „.page“ přidáním příkazu `wc`. S příkazem `wc` použijeme volbu `-l` (počet řádků). Všimněte si, že jsme také přidali volbu `-l` (dlouhý formát) k příkazu `ls`. To využijeme později.
ls -l | grep "page" | wc -l

Příkaz `grep` již není posledním příkazem v řetězci, takže jeho výstup nevidíme. Výstup z `grep` je předán do `wc`. Výstup, který se zobrazuje v terminálu, pochází z `wc`. Příkaz `wc` oznamuje, že v adresáři je 69 souborů „.page“.
Zkusme věci ještě trochu rozšířit. Odstraníme příkaz `wc` a nahradíme ho příkazem `awk`. Výstup z `ls -l` má devět sloupců. Pomocí `awk` vytiskneme sloupce pět, tři a devět, což odpovídá velikosti souboru, vlastníkovi a názvu souboru.
ls -l | grep "page" | awk '{print $5 " " $3 " " $9}'

Získáme tak seznam těchto sloupců pro všechny vyhledané soubory.
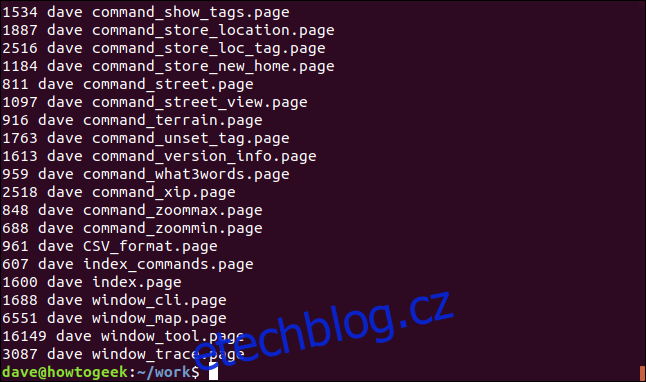
Nyní tento výstup předáme příkazu `sort`. Pomocí volby `-n` (číselné řazení) zajistíme, že se první sloupec bude považovat za čísla.
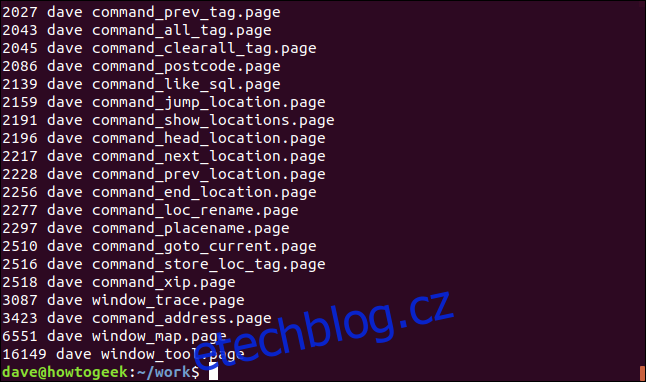
ls -l | grep "page" | awk '{print $5 " " $3 " " $9}' | sort -n

Výstup je nyní seřazen podle velikosti souboru s naším vlastním výběrem tří sloupců.
Přidání dalšího příkazu
Nakonec přidáme příkaz `tail`. Řekneme mu, ať zobrazí pouze posledních pět řádků výstupu.
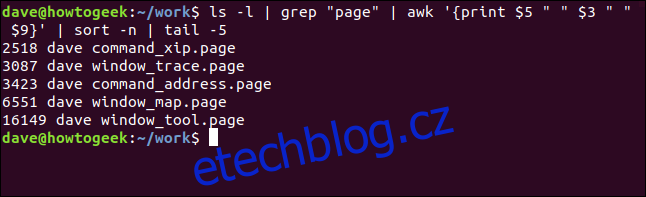
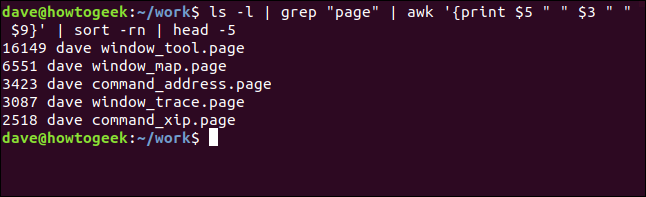
ls -l | grep "page" | awk '{print $5 " " $3 " " $9}' | sort -n | tail -5

Náš příkaz se nyní dá interpretovat jako „zobraz mi pět největších souborů ‚.page‘ v tomto adresáři, seřazených podle velikosti.“ Samozřejmě, neexistuje jeden příkaz, který by toho dosáhl. Ale s použitím rour jsme si vytvořili vlastní. Můžeme tento – nebo jakýkoliv jiný dlouhý příkaz – uložit jako alias nebo funkci shellu, abychom si ušetřili psaní.
Zde je výstup:
Pořadí můžeme obrátit přidáním volby `-r` (reverse) do příkazu `sort` a použitím `head` místo `tail` pro zobrazení řádků z horní části výstupu.

Tentokrát je zobrazeno pět největších souborů „.page“, od největšího k nejmenšímu:
Příklady z praxe
Zde jsou dva praktické příklady z nedávných článků How-To Geek.
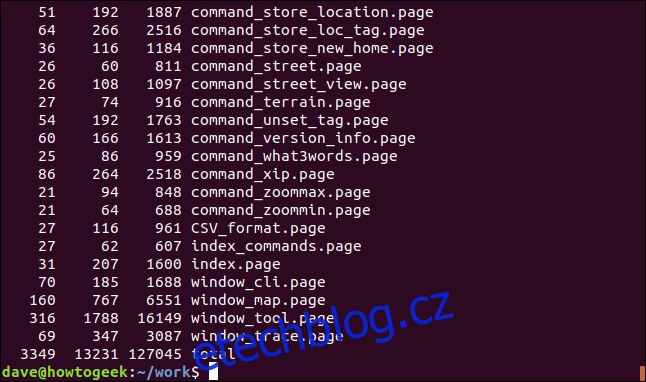
Některé příkazy, jako `xargs`, jsou navrženy tak, aby přijímaly vstup. Můžeme tak nechat `wc` spočítat slova, znaky a řádky ve více souborech. Předáme výstup z `ls` do `xargs`, který přidá seznam názvů souborů do `wc` jakoby byly zadány jako parametry příkazového řádku.
ls *.page | xargs wc

Celkový počet slov, znaků a řádků je zobrazen na konci terminálu.
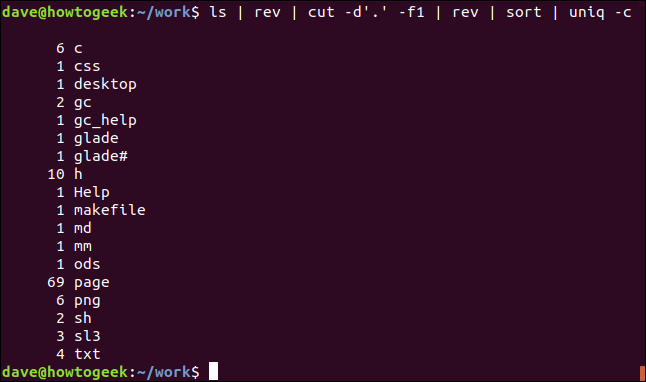
Zde je příklad, jak získat seřazený seznam jedinečných přípon souborů v aktuálním adresáři s počtem souborů každého typu:
ls | rev | cut -d'.' -f1 | rev | sort | uniq -c

Zde se toho děje poměrně dost:
`ls`: Zobrazí seznam souborů v adresáři.
`rev`: Obrátí text v názvech souborů.
`cut`: Ořízne řetězec u prvního výskytu zadaného oddělovače „.“. Text za ním je odstraněn.
`rev`: Obrátí zbývající text, což je přípona souboru.
`sort`: Seřadí seznam abecedně.
`uniq`: Spočítá počet každého jedinečného záznamu v seznamu.
Výstup zobrazuje abecedně seřazený seznam přípon souborů s počtem souborů každého typu.
Pojmenované roury
K dispozici máme ještě jeden typ rour, takzvané pojmenované roury. Roury v předchozích příkladech jsou vytvářeny shell skriptem za běhu, během zpracování příkazového řádku. Tyto roury se vytvoří, použijí a poté zruší. Jsou dočasné a nezanechávají po sobě žádné stopy. Existují pouze po dobu spuštění příkazu, který je používá.
Pojmenované roury se v souborovém systému objevují jako trvalé objekty. Můžete je zobrazit pomocí příkazu `ls`. Jsou trvalé v tom smyslu, že přežijí i restart počítače – i když veškerá nepřečtená data v nich se v tu chvíli ztratí.
Pojmenované roury byly dříve často používány, aby umožnily různým procesům odesílat a přijímat data. Dnes už se s nimi tak často nesetkáváme. Jistě se najdou lidé, kteří je stále používají, ale v poslední době se s nimi moc nesetkávám. Nicméně pro úplnost si ukážeme, jak je používat.
Pojmenované roury se vytvářejí pomocí příkazu `mkfifo`. Tento příkaz vytvoří pojmenovanou rouru s názvem „geek-pipe“ v aktuálním adresáři.
mkfifo geek-pipe

Podrobnosti o pojmenované rouře si můžeme zobrazit pomocí příkazu `ls` s volbou `-l` (dlouhý formát):
ls -l geek-pipe

První znak výpisu je „p“, což znamená, že se jedná o rouru. Kdyby tam bylo „d“, znamenalo by to adresář a pomlčka „-“ by znamenala, že jde o běžný soubor.
Použití pojmenované roury
Pojďme naši rouru použít. Nepojmenované roury, které jsme použili v předchozích příkladech, předávaly data okamžitě z odesílajícího příkazu do přijímacího příkazu. Data odeslaná pojmenovanou rourou zůstanou v rouře, dokud nebudou přečtena. Ve skutečnosti jsou data uložena v paměti, takže velikost pojmenované roury se ve výpisech z `ls` nebude měnit, ať už data obsahuje nebo ne.
Pro tento příklad použijeme dvě terminálová okna. Použijeme označení:
# Terminal-1
v jednom okně a
# Terminal-2
v druhém okně, abyste je mohli rozlišit. Znak „#“ říká shellu, že to, co následuje, je komentář a má to ignorovat.
Vezmeme náš předchozí příklad a přesměrujeme ho do pojmenované roury. V jednom příkazu tedy používáme nepojmenované i pojmenované roury:
ls | rev | cut -d'.' -f1 | rev | sort | uniq -c > geek-pipe

Přesměrováváme obsah pojmenované roury do `cat`, takže `cat` zobrazí tento obsah ve druhém okně terminálu. Zde je výstup:
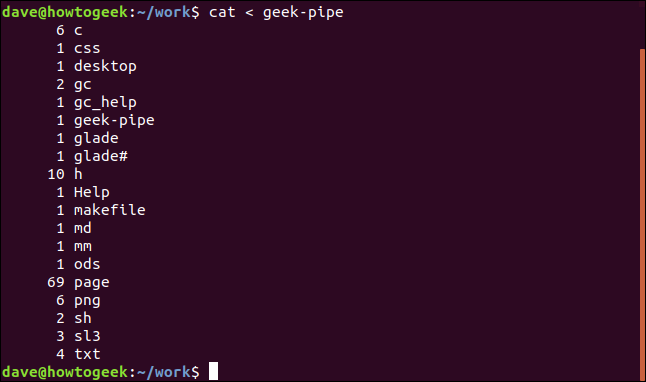
A uvidíte, že jste byli vráceni do příkazového řádku v prvním okně terminálu.

Co se tedy právě stalo?
Přesměrovali jsme část výstupu do pojmenované roury.
První okno terminálu se nevrátilo do příkazového řádku.
Data zůstala v rouře, dokud nebyla načtena v druhém terminálu.
Byli jsme vráceni do příkazového řádku v prvním okně terminálu.
Možná si myslíte, že byste mohli spustit příkaz v prvním okně terminálu jako úlohu na pozadí přidáním `&` na konec příkazu. A máte pravdu. V takovém případě bychom byli okamžitě vráceni do příkazového řádku.
Účelem nepoužití zpracování na pozadí bylo zdůraznit, že pojmenovaná roura je blokující proces. Vložením dat do pojmenované roury se otevře pouze jeden její konec. Druhý konec se neotevře, dokud čtecí program nezíská data. Jádro pozastaví proces v prvním okně terminálu, dokud se data nepřečtou z druhého konce roury.
Síla rour
V dnešní době jsou pojmenované roury spíše raritou.
Na druhou stranu běžné linuxové roury jsou jedním z nejužitečnějších nástrojů, které můžete mít k dispozici v terminálovém okně. Příkazová řádka Linuxu pro vás ožije a získáte zcela nové možnosti, když dokážete propojit sadu příkazů a vytvořit tak jeden komplexní a efektivní proces.
Malý tip: Je dobré postupovat po krocích a řetězit příkazy jeden po druhém. Nejdřív zprovoznit první část, pak přidat další příkaz.