Jak používat příkaz grep v systému Linux
Příkaz grep v Linuxu slouží jako mocný nástroj pro vyhledávání textových řetězců a vzorců. Umožňuje efektivně prohledávat soubory a filtrovat odpovídající řádky, a to i z výstupu jiných příkazů. V tomto článku si ukážeme jeho možnosti a praktické využití.
Historie příkazu grep
Příkaz grep se v linuxovém a unixovém světě těší velké oblibě z několika důvodů. Je nepostradatelný pro svou funkčnost, disponuje velkým množstvím možností, a také se váže k zajímavému příběhu svého vzniku. I když některé z jeho funkcí mohou působit komplikovaně, jeho původ je překvapivě jednoduchý.
Ken Thompson, autor grep, původně vytvořil tento nástroj extrahováním schopností prohledávání pomocí regulárních výrazů z textového editoru ed. Program měl sloužit pro osobní potřebu při práci s textovými soubory. Jeho kolega z Bell Labs, Doug Mcilroy, si však uvědomil jeho potenciál a oslovil Thompsona, aby vyřešil problém jeho kolegy Lee McMahona.
McMahon se pokoušel analyzovat Federalistické spisy a identifikovat jejich autory pomocí textové analýzy. Potřeboval nástroj, který by uměl rychle a efektivně vyhledávat fráze a textové řetězce v souborech. Thompson během jedné noci upravil svůj nástroj, aby byl použitelný i pro ostatní, a přejmenoval ho na grep. Název byl odvozen z příkazového řetězce editoru ed – g/re/p, což znamená "globální vyhledávání regulárních výrazů".
Zajímavý rozhovor o vzniku grep s Brian Kernighan si můžete poslechnout na YouTube.
Základní vyhledávání s grep
Pro základní vyhledávání zadejte na příkazové řádce hledaný text a název souboru, který chcete prohledat:
grep hledaný_text název_souboru
Příkaz grep zobrazí všechny řádky, ve kterých se hledaný text nachází. Standardně je v mnoha distribucích výstup z grep zvýrazněn barvou, což usnadňuje jeho vizuální identifikaci, díky nastavení:
alias grep='grep --colour=auto'
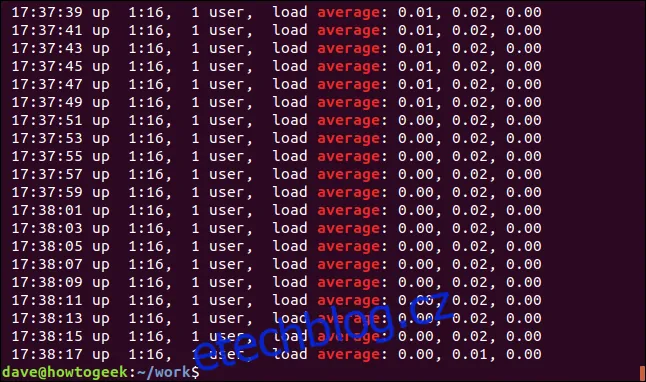
Podívejme se na příklad s více shodnými řádky. Budeme hledat slovo "Průměr" v souboru protokolu. Abychom ignorovali velikost písmen, použijeme volbu `-i`:
grep -i Průměr soubor.log

Výsledkem jsou všechny řádky, které obsahují slovo "průměr", s textem zvýrazněným.
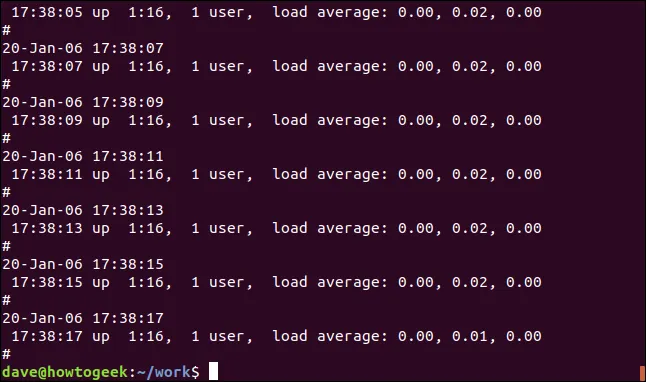
Pokud chceme zobrazit řádky, které *ne*obsahují hledaný text, použijeme volbu `-v` (invertovat shodu):
grep -v Mem soubor.log

Zde nevidíme žádné zvýraznění, protože se jedná o řádky, které neodpovídají zadanému vzoru.
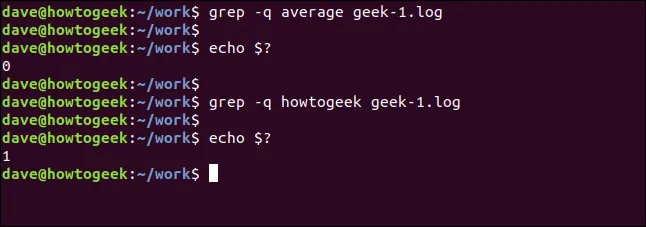
Příkaz grep může běžet i bez vypisování jakéhokoli výstupu. Vrátí pouze návratovou hodnotu, která signalizuje úspěšnost vyhledávání. Nulová hodnota znamená, že hledaný text byl nalezen, jednička naopak, že nebyl nalezen. Tuto návratovou hodnotu můžeme ověřit pomocí proměnné `$?`:
grep -q průměr soubor.log echo $?
grep -q nesmysl soubor.log echo $?
Rekurzivní vyhledávání
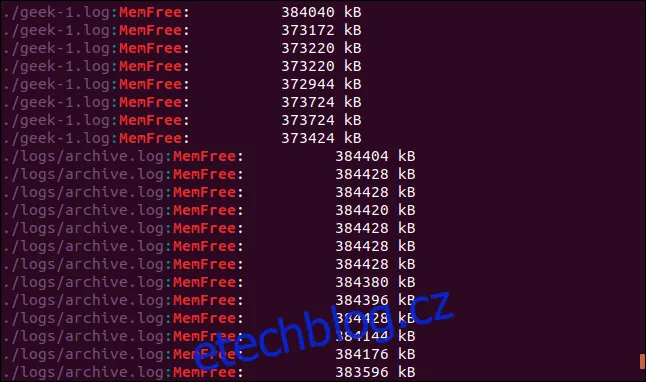
Pro prohledávání celých adresářových struktur, včetně všech podadresářů, se používá volba `-r` (rekurzivní). Je důležité zadat cestu k adresáři, který má být prohledán, namísto názvu souboru. Následující příklad prohledá aktuální adresář a všechny jeho podadresáře:
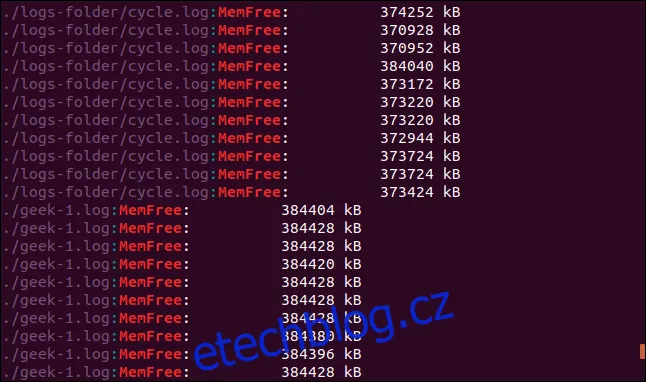
grep -r -i memfree .

Výstup obsahuje cestu k adresáři a název souboru, ve kterém se hledaný text nachází.
Volba `-R` (rekurzivní dereference) umožňuje sledovat i symbolické odkazy. Pokud v aktuálním adresáři existuje symbolický odkaz s názvem `logs-folder`, který ukazuje na `/home/uživatel/logs`:
ls -l logs-folder

Použitím `-R` grep prohledá i adresář, na který symbolický odkaz směřuje:
grep -R -i memfree .

Takto grep prohledá nejen aktuální adresář a podadresáře, ale i adresáře, na které směřují symbolické odkazy.
Hledání celých slov
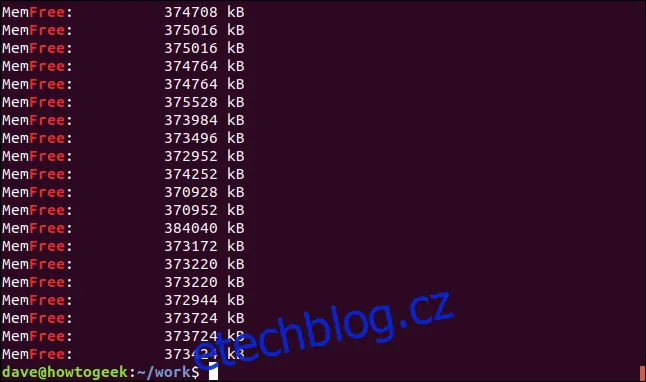
Grep standardně vyhledává zadaný text kdekoli v řádku, včetně jeho výskytu v rámci jiných slov. Pokud například hledáme slovo "volný":
grep -i volný soubor.log

Získáme i řádky, které obsahují slovo "volný" jako součást slova "MemVolný".
Pro vyhledání pouze celých slov použijeme volbu `-w` (regulární výraz slova):
grep -w -i volný soubor.log echo $?
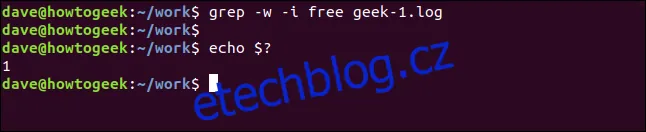
V tomto případě se nenajde žádný výskyt, jelikož se slovo "volný" v souboru nevyskytuje jako samostatné slovo.
Více hledaných výrazů
Volba `-E` (extended regexp) umožňuje vyhledávat více slov současně. (Tato volba nahrazuje zastaralou verzi příkazu egrep).
Následující příkaz vyhledá výskyty slov "průměr" a "memfree":
grep -E -w -i "průměr|memfree" soubor.log

Příkaz zobrazí všechny řádky, kde se vyskytuje alespoň jedno z hledaných slov.
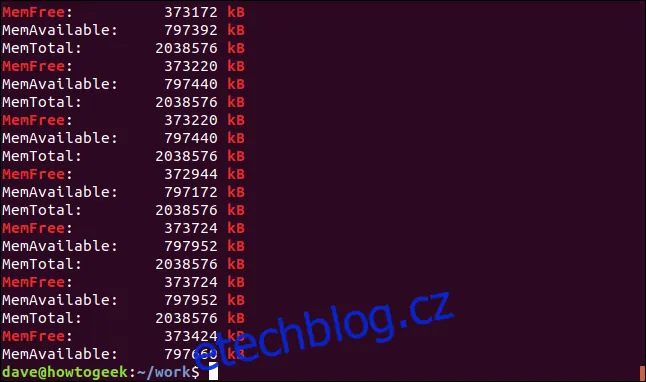
Je také možné vyhledávat kombinace celých slov a jejich částí. Pomocí volby `-e` (vzory) můžeme zadat více hledaných výrazů, přičemž využijeme i možnosti regulárních výrazů. Závorky `[]` definují množinu znaků, ze které se má jeden znak použít pro shodu. Následující příklad vyhledá slovo, které obsahuje buď "kB" nebo "KB":

Nalezeny jsou řádky s oběma řetězci, a některé řádky dokonce obsahují oba.
Přesná shoda celých řádků
Volba `-x` (řádkový regulární výraz) zajistí, že se grep bude shodovat pouze s řádky, kde **celý** řádek odpovídá hledanému výrazu. Pro vyhledání konkrétního datumu a času, o kterém víme, že se v souboru objeví pouze jednou:
grep -x "20-Leden--06 15:24:35" soubor.log

Výsledkem je pouze jediný řádek, který přesně odpovídá zadanému vzoru.
Opačný efekt získáme použitím `-v` pro zobrazení řádků, které se neshodují. To může být užitečné při práci s konfiguračními soubory. Následující příklad filtruje komentáře z konfiguračního souboru `/etc/sudoers`:
sudo grep -v "#" /etc/sudoers
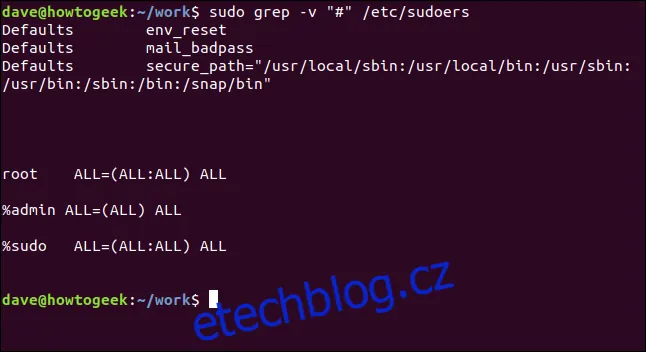
Získaný výstup je tak mnohem přehlednější a umožňuje rychleji analyzovat klíčové parametry konfigurace.
Zobrazení pouze odpovídajícího textu
V některých případech nemusí být žádoucí zobrazovat celé řádky, ale pouze text, který se shoduje s hledaným výrazem. Volba `-o` (pouze shoda) tuto funkci umožňuje:
grep -o MemVolný soubor.log

Výsledkem je zobrazení pouze textu, který odpovídá hledanému vzoru, bez celého řádku.

Počítání s grep
Příkaz grep umí nejen vyhledávat, ale i poskytovat číselné informace. Můžeme zjistit počet výskytů hledaného textu v souboru, a to pomocí volby `-c` (count):
grep -c průměr soubor.log

V tomto příkladu nám grep sdělí, že se hledaný výraz vyskytuje 240 krát.
Volba `-n` (číslo řádku) zobrazí číslo řádku pro každý odpovídající řádek:
grep -n Leden soubor.log

Na začátku každého odpovídajícího řádku se objeví číslo jeho pozice.
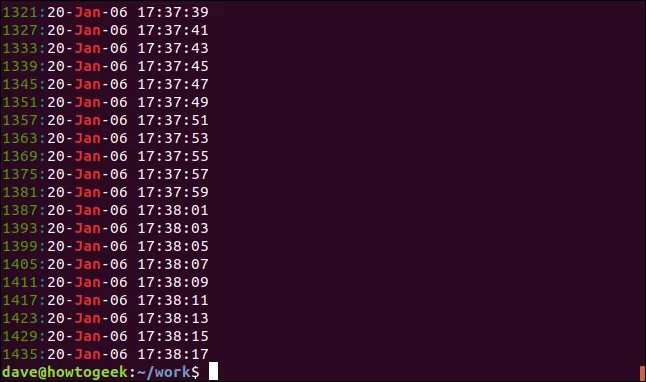
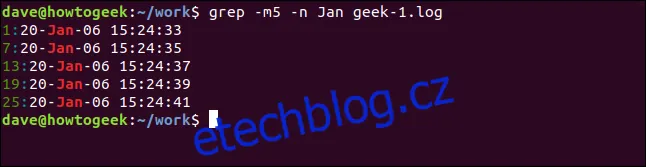
Pro omezení počtu zobrazených výsledků použijeme volbu `-m` (max. počet). Následující příklad zobrazí pouze prvních pět odpovídajících řádků:
grep -m5 -n Leden soubor.log
Přidání kontextu
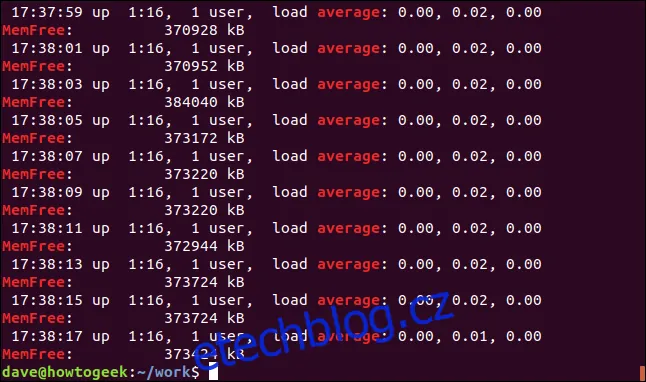
Často je užitečné zobrazit i okolní řádky k nalezenému textu. To nám pomáhá pochopit kontext a lépe analyzovat výsledky.
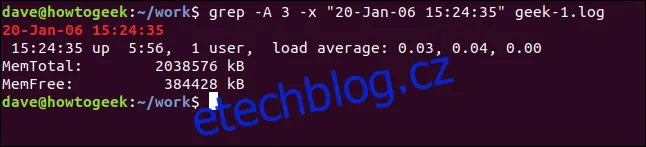
Pro zobrazení řádků, které následují za odpovídajícím řádkem, použijeme volbu `-A` (po kontextu). V následujícím příkladu se zobrazí tři řádky za nalezeným řádkem:
grep -A 3 -x "20-Leden-06 15:24:35" soubor.log
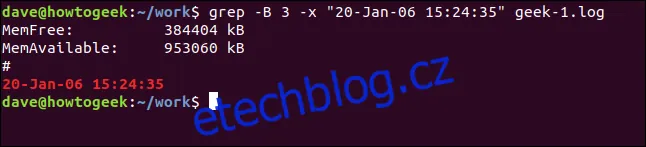
Volba `-B` (kontext před) zobrazí naopak řádky, které předcházejí nalezenému řádku:
grep -B 3 -x "20-Leden-06 15:24:35" soubor.log
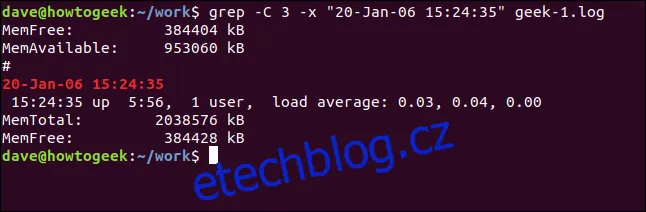
Pro zobrazení řádků před i za nalezeným řádkem použijeme volbu `-C` (kontext):
grep -C 3 -x "20-Leden-06 15:24:35" soubor.log
Zobrazení odpovídajících souborů
Pokud nás zajímá pouze to, které soubory obsahují hledaný text, můžeme použít volbu `-l` (soubory se shodou). Následující příklad zobrazí, které soubory se zdrojovým kódem v jazyce C obsahují odkaz na hlavičkový soubor `sl.h`:
grep -l "sl.h" *.c

Zobrazí se pouze názvy souborů, ve kterých se hledaný text nachází.

Volba `-L` (soubory bez shody) zobrazí naopak soubory, které hledaný text neobsahují:
grep -L "sl.h" *.c

Začátek a konec řádků
Grep umožňuje specifikovat pozici hledaného textu na začátku nebo na konci řádku. Regulární výraz `^` reprezentuje začátek řádku. Následující příkaz zobrazí řádky, které začínají mezerou:
grep "^ " soubor.log

Zobrazí se řádky, které mají na začátku mezeru.
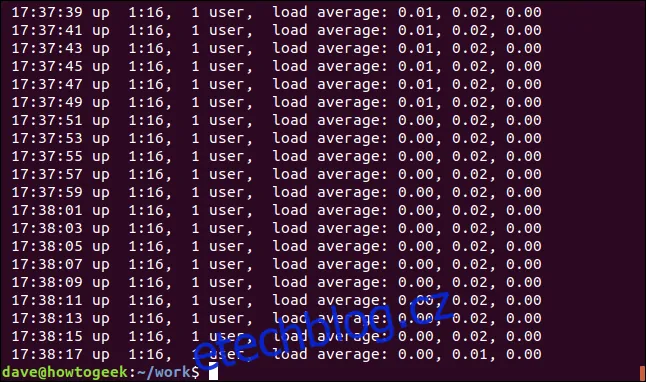
Konec řádku je reprezentován regulárním výrazem `$`. Následující příkaz vyhledá řádky, které končí na "00":
grep "00$" soubor.log

Zobrazí se řádky, které končí na "00".
Použití pipes s grep
Grep je flexibilní nástroj, který lze využít v kombinaci s jinými příkazy pomocí rour (pipes). Můžeme tak filtrovat výstup z jiných příkazů a předávat ho dále pro další zpracování.
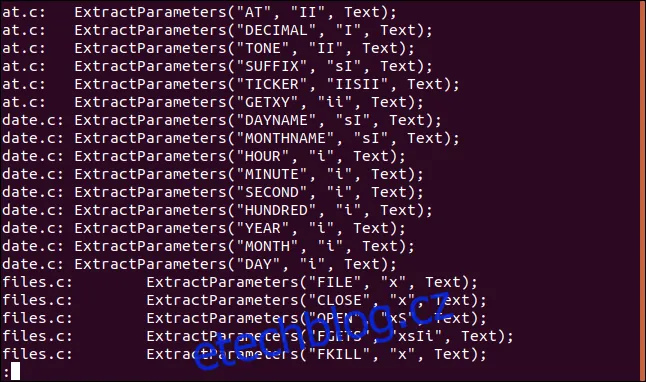
Pokud například chceme zobrazit všechny výskyty řetězce "ExtractParameters" v souborech se zdrojovým kódem v jazyce C, a očekáváme větší množství výstupu, můžeme využít `less` pro pohodlné prohlížení:
grep "ExtractParameters" *.c | less

Výstup z grep se zobrazí v `less`. Zde můžeme využít vyhledávání uvnitř `less`.
Pokud výstup z grep předáme do `wc` a použijeme volbu `-l` (řádky), získáme počet řádků v souborech, které obsahují "ExtractParameters". Podobný výsledek bychom dosáhli volbou `-c` v grep, ale demonstruje to využití pipes:
grep "ExtractParameters" *.c | wc -l

Další příklad: Výstup z příkazu `ls` je předán do `grep`, a následně do `sort`. Zobrazíme seznam souborů z aktuálního adresáře, vybereme ty, které obsahují "Srpen", a seřadíme je podle velikosti:
ls -l | grep "Srpen" | sort +4n
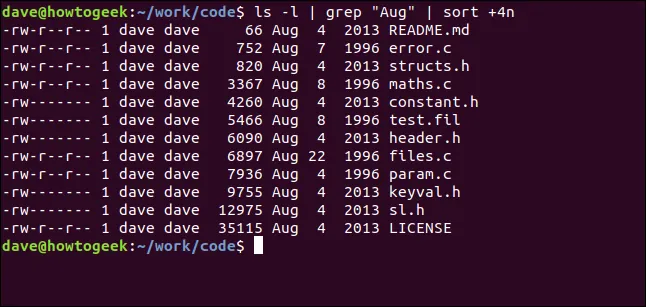
Pojďme si to rozebrat:
`ls -l`: Zobrazí výpis souborů v dlouhém formátu.
`grep "Srpen"`: Vybere z výstupu `ls` řádky, které obsahují slovo "Srpen".
`sort +4n`: Seřadí výstup z `grep` podle čtvrtého sloupce (velikost souboru), numericky.
Výsledkem je seřazený seznam všech souborů upravených v srpnu, seřazených podle velikosti souboru.
Grep: Více než příkaz, je to spojenec
Příkaz grep je skvělý nástroj, který je k dispozici pro efektivní práci s textem. I když vznikl v roce 1974, je stále aktuální, protože řeší problém, pro který byl navržen, a to velmi efektivně. Jeho možnosti lze ještě rozšířit použitím pokročilých regulárních výrazů.
