Jak používat Scikit-LLM pro analýzu textu s velkými jazykovými modely
Scikit-LLM je pythonový balíček, který usnadňuje integraci rozsáhlých jazykových modelů (LLM) do ekosystému scikit-learn. Jeho hlavním cílem je zjednodušit úlohy spojené s analýzou textu. Pokud máte zkušenosti s knihovnou scikit-learn, práce se Scikit-LLM pro vás bude intuitivní a snadná.
Je důležité zdůraznit, že Scikit-LLM není náhradou za scikit-learn. Zatímco scikit-learn je univerzální nástroj pro strojové učení, Scikit-LLM se specializuje na specifické potřeby analýzy textových dat.
Začínáme se Scikit-LLM
Pro začátek s Scikit-LLM budete potřebovat nainstalovat knihovnu a nakonfigurovat API klíč. Nejprve ve vašem vývojovém prostředí vytvořte nové virtuální prostředí. To minimalizuje riziko konfliktů verzí knihoven. Následně v terminálu spusťte tento příkaz:
pip install scikit-llm
Tím se nainstaluje Scikit-LLM spolu s jeho závislostmi.
K získání API klíče je nutné navštívit web poskytovatele LLM. Pro klíč OpenAI API postupujte takto:
Přejděte na stránku OpenAI API. V pravém horním rohu klikněte na svůj profil a z menu vyberte možnost "Zobrazit API klíče". Otevře se stránka s API klíči.
Na této stránce klikněte na tlačítko "Vytvořit nový tajný klíč".
Pojmenujte svůj klíč a klikněte na "Vytvořit tajný klíč". Po vygenerování klíč zkopírujte a uložte na bezpečné místo, protože OpenAI ho znovu nezobrazí. V případě ztráty klíče bude nutné vygenerovat nový.
Po získání API klíče otevřete své IDE a importujte třídu `SKLLMConfig` z knihovny Scikit-LLM. Tato třída slouží k nastavení konfigurace pro používání rozsáhlých jazykových modelů.
from skllm.config import SKLLMConfig
Tato třída vyžaduje nastavení vašeho OpenAI API klíče a ID organizace.
SKLLMConfig.set_openai_key("Váš API klíč")
SKLLMConfig.set_openai_org("ID Vaší organizace")
ID organizace a její název nejsou totožné. ID organizace je jedinečný identifikátor vaší organizace. Najdete ho na stránce nastavení organizace OpenAI. Po jeho zkopírování máte navázané spojení mezi Scikit-LLM a rozsáhlým jazykovým modelem.
Scikit-LLM vyžaduje aktivní tarif s průběžnými platbami, protože bezplatný zkušební účet OpenAI má omezení na tři požadavky za minutu, což je pro Scikit-LLM nedostatečné.
Pokus o použití bezplatného zkušebního účtu způsobí při provádění analýzy textu chybu podobnou této:

Více informací o limitech sazeb naleznete na stránce s limity sazeb OpenAI.
Je důležité zmínit, že OpenAI není jediným poskytovatelem LLM, kterého můžete využít. Existují i další alternativy.
Import potřebných knihoven a načtení datové sady
Importujte knihovnu pandas, kterou použijete k načtení datové sady. Dále importujte potřebné třídy z Scikit-LLM a scikit-learn.
import pandas as pd
from skllm import ZeroShotGPTClassifier, MultiLabelZeroShotGPTClassifier
from skllm.preprocessing import GPTSummarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.preprocessing import MultiLabelBinarizer
Nyní načtěte datovou sadu, na které chcete provádět analýzu textu. V tomto příkladu se používá datová sada filmů IMDB, ale můžete použít i vlastní data.
data = pd.read_csv("imdb_movies_dataset.csv")
data = data.head(100)
Použití pouze prvních 100 řádků není povinné, můžete pracovat s celou datovou sadou.
Dále extrahujte vstupní prvky (Description) a cílové sloupce (Genre). Následně rozdělte datovou sadu na trénovací a testovací.
X = data['Description']y = data['Genre']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Sloupec "Genre" obsahuje štítky, které se model pokusí predikovat.
Klasifikace textu Zero-Shot s využitím Scikit-LLM
Klasifikace textu Zero-Shot je funkcionalita, kterou nabízejí rozsáhlé jazykové modely. Tato metoda umožňuje kategorizovat text do předem definovaných kategorií, bez explicitního trénování na označených datech. Je velmi užitečná v situacích, kdy je třeba text zařadit do kategorií, které nebyly součástí trénovacího procesu.
Pro klasifikaci textu Zero-Shot s Scikit-LLM použijte třídu `ZeroShotGPTClassifier`.
zero_shot_clf = ZeroShotGPTClassifier(openai_model="gpt-3.5-turbo")
zero_shot_clf.fit(X_train, y_train)
zero_shot_predictions = zero_shot_clf.predict(X_test)
print("Zpráva o klasifikaci textu Zero-Shot:")
print(classification_report(y_test, zero_shot_predictions))
Výstup bude podobný následujícímu:
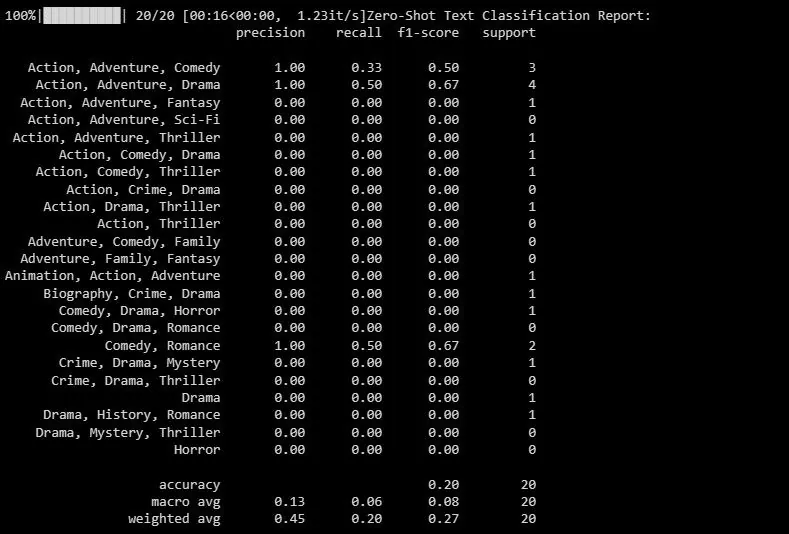
Zpráva o klasifikaci poskytuje metriky pro každý štítek, který model předpovídá.
Klasifikace textu Multi-Label Zero-Shot s Scikit-LLM
V některých případech může text patřit do více kategorií současně, s čímž tradiční klasifikační modely mívají problémy. Scikit-LLM však umožňuje i tuto formu klasifikace. Multi-label klasifikace textu Zero-Shot je užitečná pro přiřazování více popisných štítků jednomu textovému vzorku.
Použijte `MultiLabelZeroShotGPTClassifier` k predikci více štítků, které se hodí pro daný vzorek textu.
candidate_labels = ["Akční", "Komedie", "Drama", "Horor", "Sci-Fi"]
multi_label_zero_shot_clf = MultiLabelZeroShotGPTClassifier(max_labels=2)
multi_label_zero_shot_clf.fit(X_train, candidate_labels)
multi_label_zero_shot_predictions = multi_label_zero_shot_clf.predict(X_test)
mlb = MultiLabelBinarizer()
y_test_binary = mlb.fit_transform(y_test)
multi_label_zero_shot_predictions_binary = mlb.transform(multi_label_zero_shot_predictions)
print("Zpráva o klasifikaci textu Multi-Label Zero-Shot:")
print(classification_report(y_test_binary, multi_label_zero_shot_predictions_binary))
V tomto kódu definujete seznam kandidátních štítků, do kterých může text spadat.
Výstup je následující:
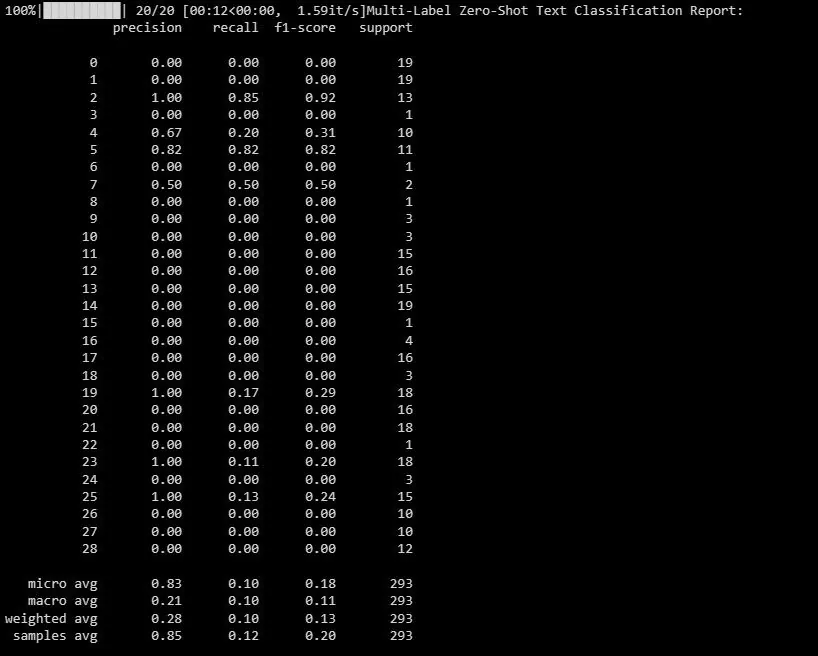
Tento přehled poskytuje metriky pro každý jednotlivý štítek v multi-label klasifikaci.
Vektorizace textu s Scikit-LLM
Při vektorizaci se textová data převádějí do numerické podoby, která je srozumitelná modelům strojového učení. Scikit-LLM pro tento účel nabízí `GPTVectorizer`, který transformuje text do vektorů s pevnými dimenzemi pomocí modelů GPT.
K tomu lze použít techniku Term Frequency-Inverse Document Frequency (TF-IDF).
tfidf_vectorizer = TfidfVectorizer(max_features=1000)
X_train_tfidf = tfidf_vectorizer.fit_transform(X_train)
X_test_tfidf = tfidf_vectorizer.transform(X_test)
print("TF-IDF Vektorizované rysy (prvních 5 vzorků):")
print(X_train_tfidf[:5])
Zde je výstup:
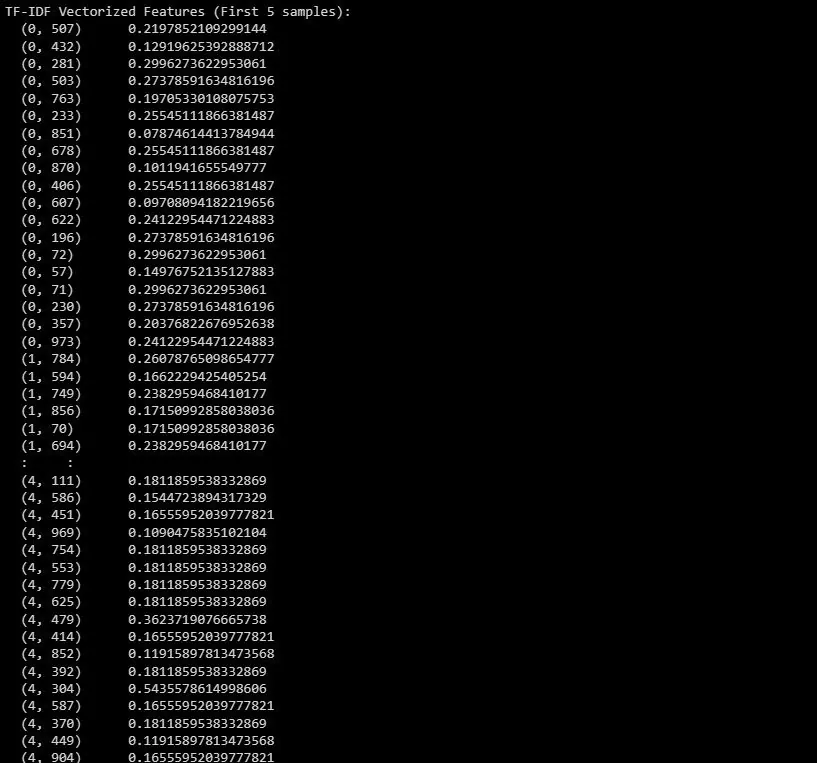
Tento výstup ukazuje TF-IDF vektorizované rysy pro prvních 5 vzorků v datové sadě.
Shrnutí textu s Scikit-LLM
Shrnutí textu zkracuje textový dokument při zachování nejdůležitějších informací. Scikit-LLM poskytuje `GPTSummarizer`, který využívá modely GPT k vytváření stručných souhrnů.
summarizer = GPTSummarizer(openai_model="gpt-3.5-turbo", max_words=15)
summaries = summarizer.fit_transform(X_test)
print(summaries)
Výstup je:
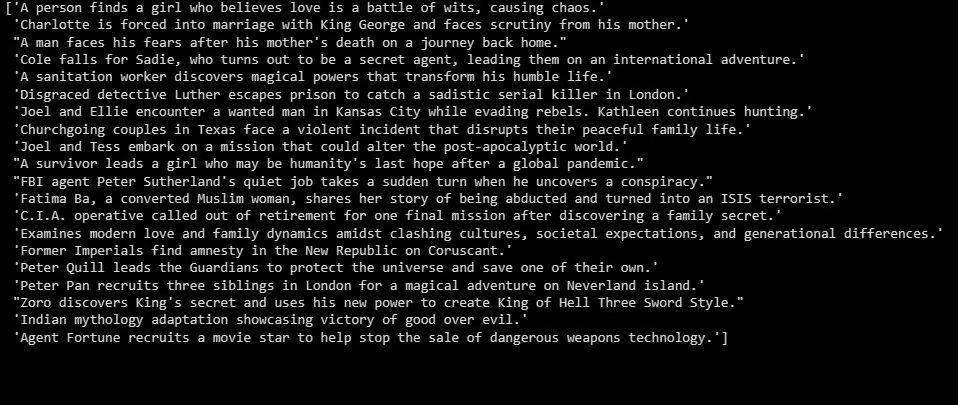
Výše uvedený výstup představuje souhrn testovacích dat.
Vytváření aplikací s LLM
Scikit-LLM otevírá široké možnosti pro analýzu textu s rozsáhlými jazykovými modely. Znalost principů a fungování těchto modelů je klíčová pro efektivní využití jejich silných stránek a minimalizaci slabých míst při vytváření nových aplikací.
