
Web scraping je výkonná technika pro extrahování informací z webových stránek a jejich automatickou analýzu. I když to můžete udělat ručně, může to být únavný a časově náročný úkol. Nástroje pro stírání webu urychlují a zefektivňují proces a přitom stojí méně.
Zajímavé je, že Tabulky Google mají potenciál být vaším komplexním nástrojem pro odstraňování webových stránek díky funkci IMPORTXML. S IMPORTXML můžete snadno sbírat data z webových stránek a používat je pro analýzu, vytváření sestav nebo jakékoli jiné úlohy založené na datech.
Table of Contents
Funkce IMPORTXML v Tabulkách Google
Tabulky Google poskytují vestavěnou funkci nazvanou IMPORTXML, která umožňuje importovat data z webových formátů, jako jsou XML, HTML, RSS a CSV. Tato funkce může změnit hru, pokud chcete shromažďovat data z webových stránek bez použití složitého kódování.
Zde je základní syntaxe IMPORTXML:
=IMPORTXML(url, xpath_query)
- url: Adresa URL webové stránky, ze které chcete získat data.
- xpath_query: Dotaz XPath, který definuje data, která chcete extrahovat.
XPath (XML Path Language) je jazyk používaný k navigaci v dokumentech XML, včetně HTML, což vám umožňuje určit umístění dat ve struktuře HTML. Pro správné používání IMPORTXML je nezbytné porozumět dotazům XPath.
Pochopení XPath
XPath poskytuje různé funkce a výrazy pro navigaci a filtrování dat v dokumentu HTML. Komplexní průvodce XML a XPath přesahuje rozsah tohoto článku, takže se spokojíme s některými základními koncepty XPath:
- Výběr prvku: Prvky můžete vybrat pomocí / a // k označení cest. Například /html/body/div vybere všechny prvky div v těle dokumentu.
- Výběr atributu: Chcete-li vybrat atributy, můžete použít @. Například //@href vybere všechny atributy href na stránce.
- Predikátové filtry: Prvky můžete filtrovat pomocí predikátů uzavřených v hranatých závorkách ([ ]). Například /div[@class=”container”] vybere všechny prvky div s kontejnerem třídy.
- Funkce: XPath poskytuje různé funkce, jako například obsahuje(), začíná-s() a text() pro provádění specifických akcí, jako je kontrola obsahu textu nebo hodnot atributů.
Zatím znáte syntaxi IMPORTXML, znáte adresu URL webu a víte, který prvek chcete extrahovat. Ale jak získáte XPath prvku?
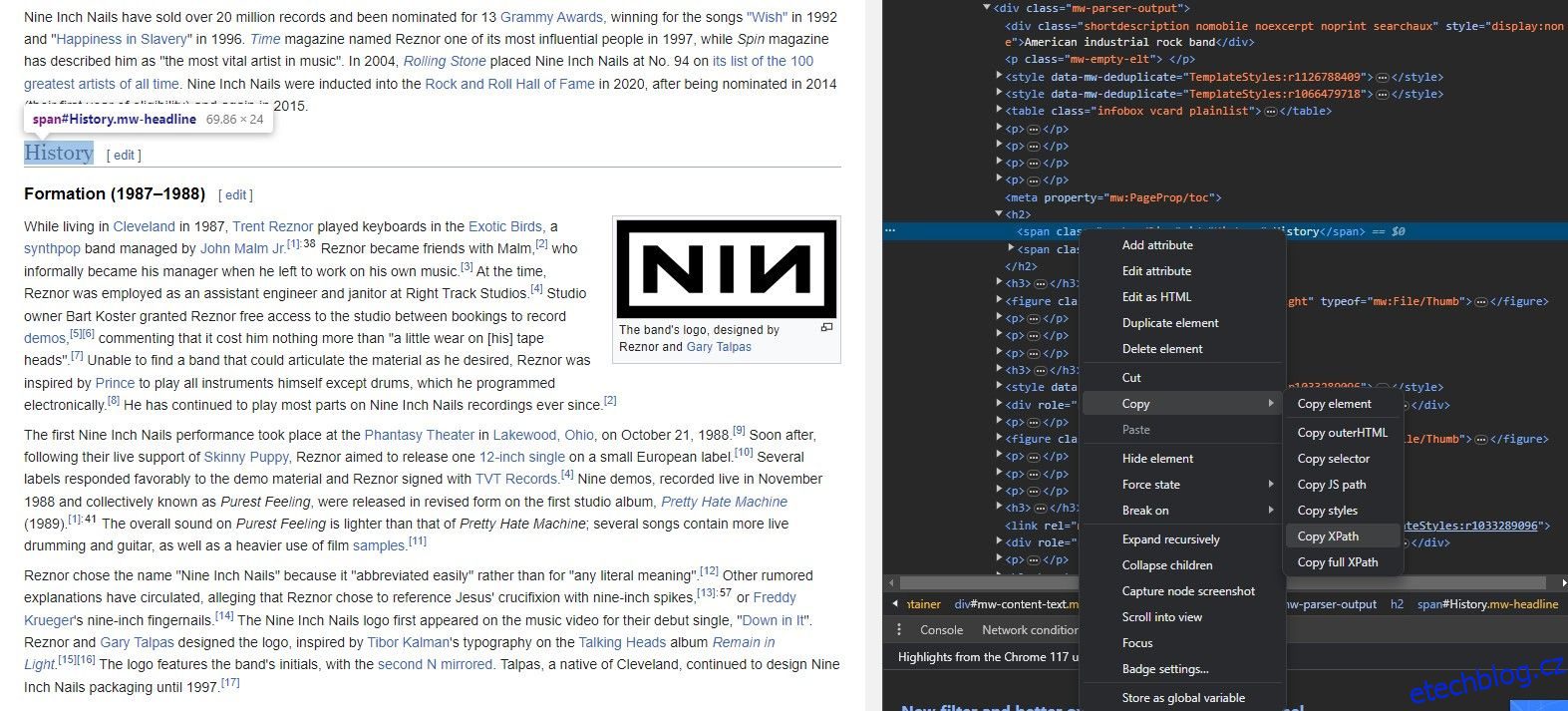
Nemusíte znát strukturu webu nazpaměť, abyste mohli extrahovat data pomocí IMPORTXML. Ve skutečnosti má každý prohlížeč šikovný nástroj, který vám umožní okamžitě zkopírovat cestu XPath jakéhokoli prvku.
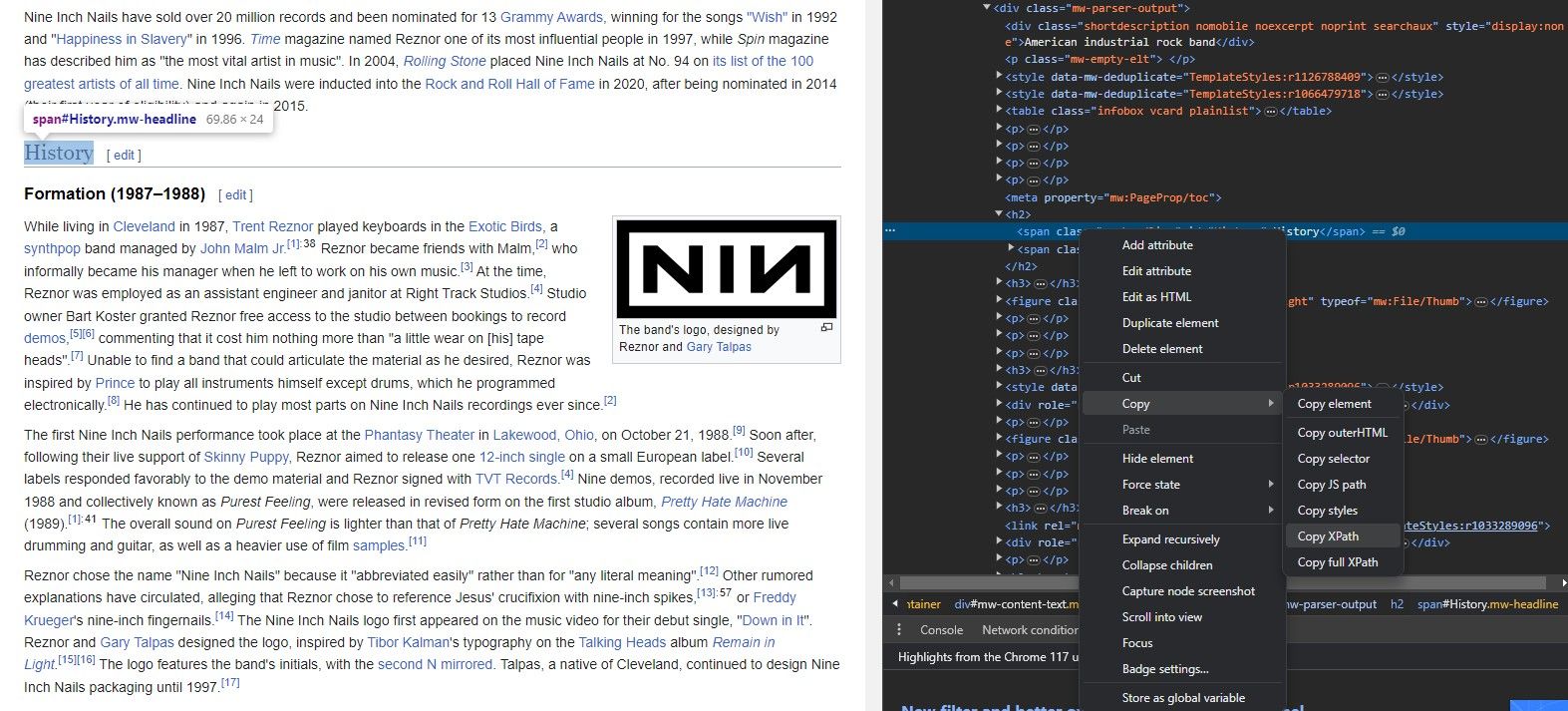
Nástroj Inspect Element umožňuje extrahovat XPath z prvků webu. Zde je postup:
Nyní, když máte vše, co potřebujete, je čas vidět IMPORTXML v akci a seškrábat nějaké odkazy.
Jak odstranit odkazy z webu pomocí IMPORTXML
IMPORTXML můžete použít k seškrábání všech druhů dat z webových stránek. To zahrnuje odkazy, videa, obrázky a téměř jakýkoli prvek webu. Odkazy jsou jedním z nejvýraznějších prvků webové analýzy a o webu se můžete hodně dozvědět pouze analýzou stránek, na které odkazuje.
IMPORTXML vám umožňuje rychle seškrábat odkazy v Tabulkách Google a poté je dále analyzovat pomocí různých funkcí, které Tabulky Google nabízejí.
1. Odstranění všech odkazů
Chcete-li odstranit všechny odkazy z webové stránky, můžete použít následující vzorec:
=IMPORTXML(url, "//a/@href")
Tento dotaz XPath vybere všechny atributy href prvků a efektivně extrahuje všechny odkazy na stránce.
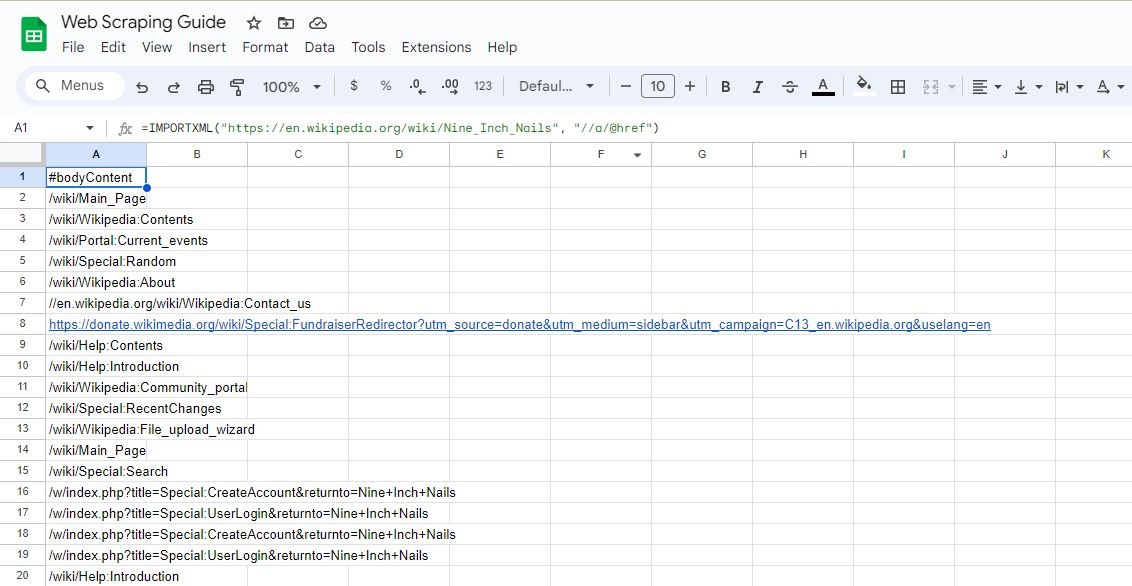
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//a/@href")
Výše uvedený vzorec smaže všechny odkazy v článku na Wikipedii.
Je dobré zadat adresu URL webové stránky do samostatné buňky a poté na tuto buňku odkazovat. Zabráníte tak tomu, aby vaše receptura byla příliš dlouhá a nepraktická. Totéž můžete udělat s dotazem XPath.
2. Seškrábání všech textů odkazů
Chcete-li extrahovat text odkazů spolu s jejich adresami URL, můžete použít:
=IMPORTXML(url, "//a")
Tento dotaz vybere všechny prvky a z výsledků můžete extrahovat text odkazu a adresy URL.
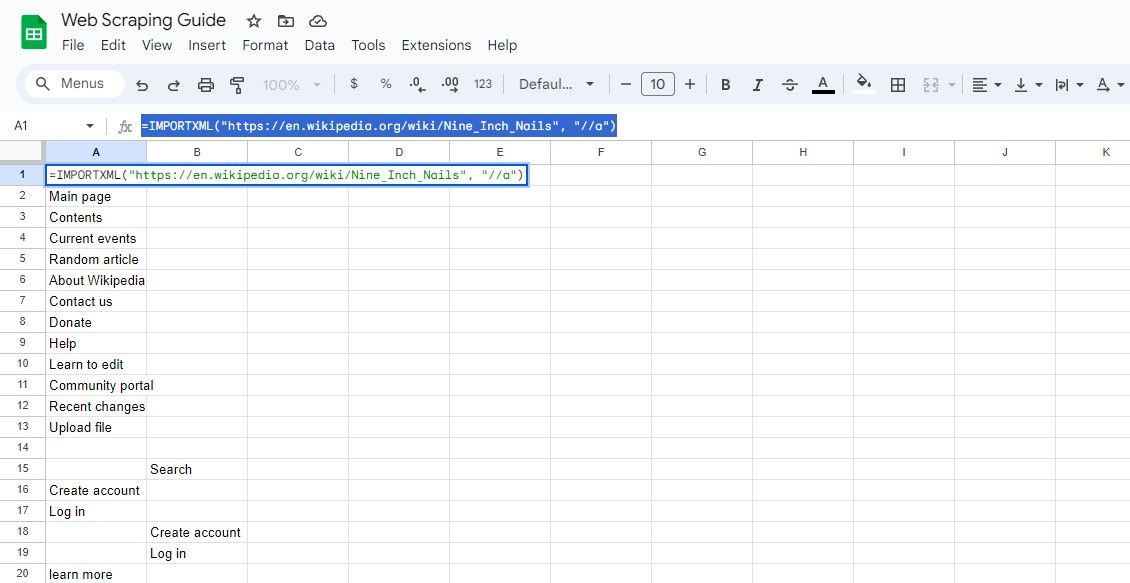
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//a")
Výše uvedený vzorec získá texty odkazů ve stejném článku na Wikipedii.
Jak odstranit konkrétní odkazy z webu pomocí IMPORTXML
Někdy může být nutné odstranit konkrétní odkazy na základě kritérií. Mohlo by vás například zajímat extrahování odkazů obsahujících určité klíčové slovo nebo odkazů umístěných v určité části stránky.
Se správnou znalostí XPath můžete přesně určit jakýkoli prvek, který hledáte.
1. Odstranění odkazů obsahujících klíčové slovo
Chcete-li odstranit odkazy, které obsahují konkrétní klíčové slovo, můžete použít funkci include() XPath:
=IMPORTXML(url, "//a[contains(@href, 'keyword')]/@href")
Tento dotaz vybere atributy href prvků, kde href obsahuje zadané klíčové slovo.
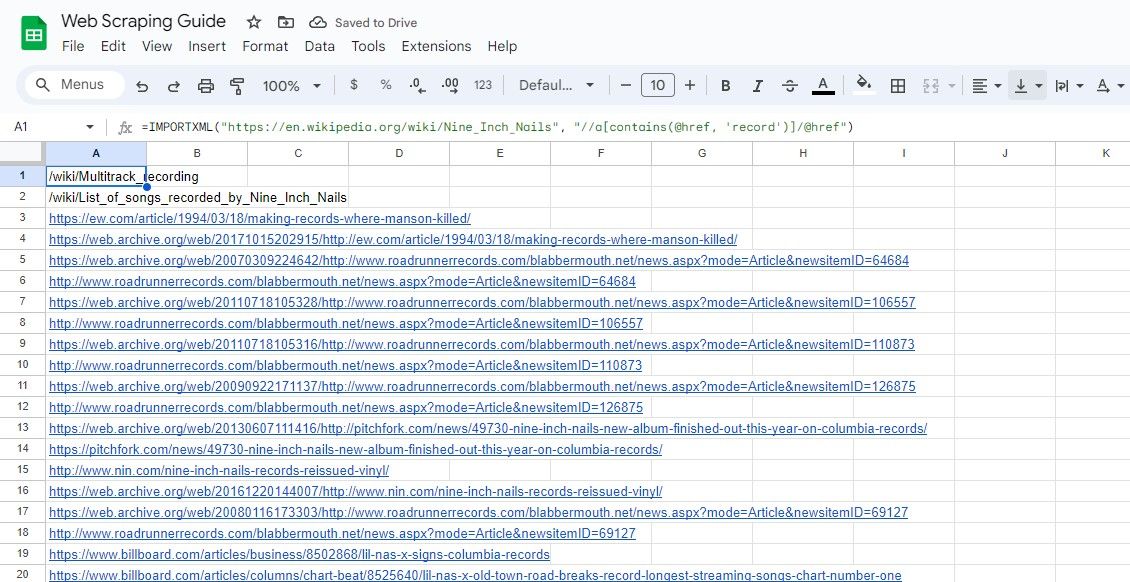
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//a[contains(@href, 'record')]/@href")
Výše uvedený vzorec seškrábe všechny odkazy, které obsahují slovo záznam ve svém textu ve vzorovém článku na Wikipedii.
2. Seškrabávání odkazů v sekci
Chcete-li odstranit odkazy z určité části stránky, můžete zadat cestu XPath této části. Například:
=IMPORTXML(url, "//div[@class="section"]//a/@href")
Tento dotaz vybírá atributy href prvků v prvcích div s třídou „section“.
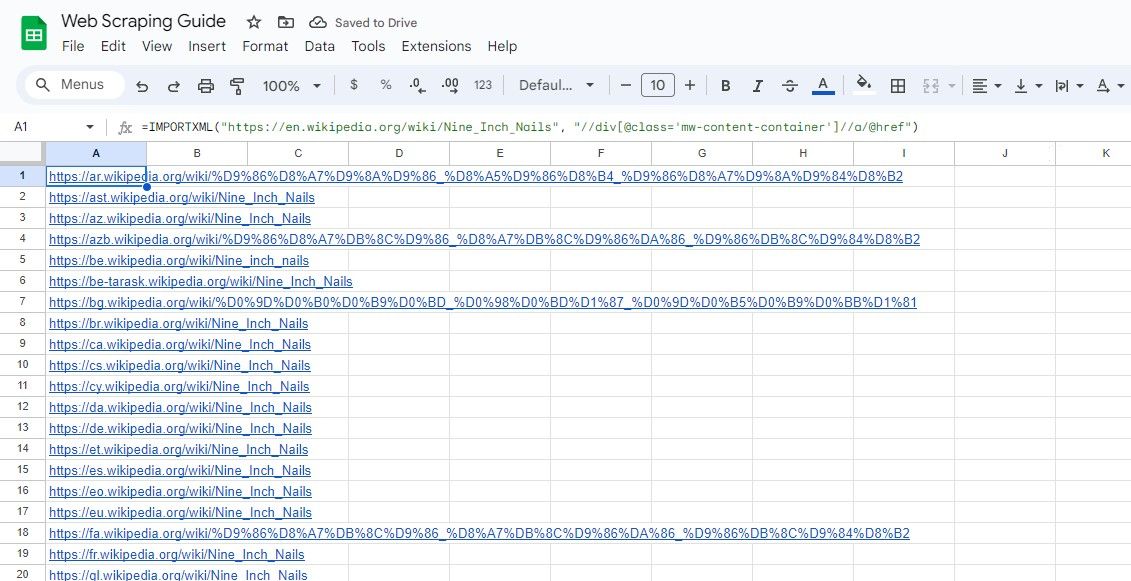
Podobně níže uvedený vzorec vybere všechny odkazy v rámci třídy div, které mají třídu mw-content-container:
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//div[@class="mw-content-container"]//a/@href")
Stojí za zmínku, že IMPORTXML můžete použít pro více než jen seškrabování webu. K importu datových tabulek z webových stránek do Tabulek Google můžete použít rodinu funkcí IMPORT.
Ačkoli Tabulky Google a Excel sdílejí většinu svých funkcí, rodina funkcí IMPORT je pro Tabulky Google jedinečná. Budete muset zvážit další metody importu dat z webů do Excelu.
Zjednodušte škrábání webu pomocí Tabulek Google
Web scraping pomocí Google Sheets a funkce IMPORTXML je všestranný a přístupný způsob shromažďování dat z webových stránek.
Zvládnutím XPath a pochopením toho, jak vytvářet efektivní dotazy, můžete odemknout plný potenciál IMPORTXML a získat cenné poznatky z webových zdrojů. Takže začněte škrábat a posuňte svou webovou analýzu na další úroveň!