Jak synchronizovat vaši místní databázi Oracle do AWS na denní bázi
Přesun databází do cloudu: Realita migračních projektů
Sledováním vývoje podnikového softwaru za posledních dvacet let je patrný jasný trend: přesouvání databází do cloudových prostředí.
Osobně jsem se podílel na řadě migračních projektů, jejichž cílem bylo převést stávající lokální databáze do cloudových databází v rámci Amazon Web Services (AWS). Ačkoli dokumentace AWS často prezentuje tento proces jako jednoduchý, moje zkušenost mi říká, že realizace takového plánu nemusí být vždy snadná a může dojít i k selháním.
V tomto článku se podělím o reálné zkušenosti s migrací, přičemž se zaměřím na následující aspekty:
- Zdroj: Ačkoli v zásadě na typu zdroje nezáleží (podobný přístup lze aplikovat na většinu oblíbených databází), zaměřím se na Oracle, systém, který velké korporace často volí po mnoho let.
- Cíl: V tomto případě nebudu specifikovat cílovou databázi. V rámci AWS máte na výběr z mnoha možností a prezentovaný přístup bude platit pro jakoukoli z nich.
- Režim: Migrace může probíhat buď jako úplné obnovení dat, nebo inkrementálně. Dále můžeme data načítat dávkově (se zpožděním mezi zdrojem a cílem) nebo téměř v reálném čase. V článku se zaměřím na oba přístupy.
- Frekvence: Migraci lze provést jednorázově, s následným kompletním přesunem do cloudu, nebo může vyžadovat přechodné období s daty aktuálními na obou stranách. To vyžaduje denní synchronizaci mezi lokálním prostředím a AWS. První přístup je jednodušší, ale druhý je častěji požadován a nese s sebou více potenciálních problémů. Proberu oba tyto scénáře.
Popis Problému
Častý požadavek zní jednoduše:
"Chceme začít vyvíjet služby v prostředí AWS. Prosím, zkopírujte všechna naše data do databáze 'ABC'. Rychle a bez problémů. Data v AWS potřebujeme ihned. Změny v návrhu databáze, které budou odpovídat našim aktivitám, vyřešíme později."
Předtím, než se pustíte do implementace, je důležité zvážit následující:
- Nepodlehněte příliš rychle myšlence "prostě to zkopírujeme a vyřešíme to později". Ano, je to nejjednodušší a nejrychlejší řešení, ale může vést k zásadním architektonickým problémům, které nebude možné později opravit bez rozsáhlého refaktoringu většiny vaší nové cloudové platformy. Cloudový ekosystém se značně liší od lokálního prostředí. S postupem času se budou zavádět nové služby a uživatelé začnou s daty pracovat odlišně. Kopírování lokálního stavu 1:1 do cloudu je téměř nikdy není dobrý nápad. Zkontrolujte, zda tomu tak není i ve vašem specifickém případě.
- Klaďte si smysluplné otázky:
- Kdo bude typickým uživatelem nové platformy? Zatímco v lokálním prostředí to mohou být transakční firemní uživatelé, v cloudu to mohou být datoví vědci, analytici, nebo dokonce služby jako Databricks, Glue či modely strojového učení.
- Budou se běžné denní úlohy provádět i po přesunu do cloudu? Pokud ne, jak se změní?
- Plánujete výrazný nárůst dat v budoucnosti? Odpověď je s největší pravděpodobností ano, což je častý důvod pro migraci do cloudu. Nový datový model by měl být na to připraven.
- Zvažte běžné dotazy, které budou uživatelé na nové databázi spouštět. To určí, nakolik je třeba změnit stávající datový model, aby byl efektivní.
Nastavení Migrace
Jakmile je cílová databáze vybrána a datový model uspokojivě prodiskutován, dalším krokem je seznámit se s nástrojem AWS Schema Conversion Tool. Tento nástroj nabízí několik klíčových funkcí:
- Analýza a extrakce zdrojového datového modelu. SCT načte informace o lokální databázi a vygeneruje zdrojový datový model.
- Návrh struktury cílového datového modelu na základě vybrané cílové databáze.
- Generování skriptů pro nasazení cílové databáze, které umožní vytvořit databázi v cloudu s odpovídající strukturou. Tyto skripty připraví databázi pro načtení dat z lokálního prostředí.
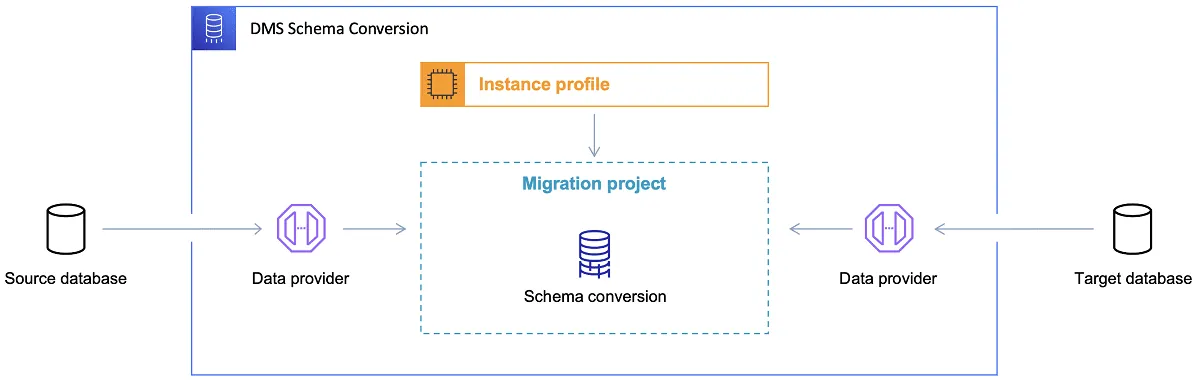
Odkaz: Dokumentace AWS
Zde je několik tipů pro použití nástroje Schema Conversion Tool.
Především byste téměř nikdy neměli přímo používat výstup nástroje. Považujte ho spíše za referenční materiál, který je třeba upravit na základě vašeho chápání dat a toho, jak budou v cloudu využívána.
Za druhé, tabulky byly pravděpodobně dříve navrženy s ohledem na rychlé a krátké dotazy na konkrétní entitu. Nyní se však data mohou používat pro analytické účely. Databázové indexy, které dříve fungovaly v lokálním prostředí, nyní mohou být nevhodné a nemusí zlepšit výkon databázového systému v novém kontextu. Můžete chtít data rozdělit v cílovém systému jinak, než tomu bylo ve zdrojovém.
Je také vhodné zvážit transformace dat během migrace, což znamená změnu cílového datového modelu pro některé tabulky (aby nebyly kopiemi 1:1). Následně bude potřeba implementovat transformační pravidla do migračního nástroje.
Pokud jsou zdrojová a cílová databáze stejného typu (např. Oracle on-premise vs. Oracle v AWS, PostgreSQL vs. Aurora Postgresql), nejlepší je použít migrační nástroj, který konkrétní databáze nativně podporuje (např. exporty a importy datových pump, Oracle Goldengate).
Většinou však zdrojová a cílová databáze kompatibilní nejsou a v takovém případě je ideální volbou AWS Database Migration Service.
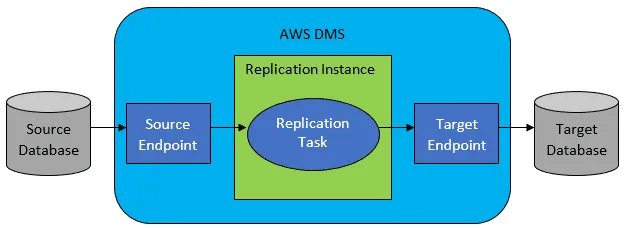
Odkaz: Dokumentace AWS
AWS DMS umožňuje konfiguraci úloh na úrovni tabulek, které definují:
- Přesný zdroj databáze a tabulku, ke které se má připojit.
- Příkazy použité pro získání dat pro cílovou tabulku.
- Transformační nástroje (pokud existují), které definují mapování zdrojových dat na cílová (pokud není 1:1).
- Přesnou cílovou databázi a tabulku, do které se mají data načíst.
Konfigurace DMS se provádí v uživatelsky přívětivém formátu, jako je JSON.
V nejjednodušším scénáři stačí spustit implementační skripty v cílové databázi a spustit úlohu DMS. Nicméně, realita je často mnohem složitější.
Jednorázová Úplná Migrace Dat

Nejjednodušší scénář nastává, když je potřeba přesunout celou databázi do cloudové databáze jednorázově. V takovém případě kroky vypadají následovně:
- Definujte DMS Task pro každou zdrojovou tabulku.
- Zkontrolujte konfiguraci úloh DMS, včetně nastavení paralelizmu, cachování proměnných, konfigurace serveru DMS a dimenzování clusteru DMS. Tato fáze obvykle zabere nejvíce času kvůli nutnosti testování a dolaďování optimální konfigurace.
- Ujistěte se, že každá cílová tabulka je vytvořena (prázdná) v cílové databázi s očekávanou strukturou.
- Naplánujte časové okno pro provedení migrace. Předem se ujistěte (testy výkonu), že okno bude dostatečné. Během migrace může dojít k omezení výkonu zdrojové databáze. Také by se během migrace neměla měnit zdrojová databáze. V opačném případě se migrovaná data mohou lišit od těch ve zdroji.
Pokud je konfigurace DMS dobře provedena, nemělo by dojít k žádným problémům. Každá zdrojová tabulka bude zkopírována do cílové databáze AWS. Jedinou starostí je provedení činností a zajištění správného dimenzování v každém kroku, aby nedošlo k selhání z důvodu nedostatečného úložiště.
Inkrementální Denní Synchronizace

Zde se situace stává komplikovanější. V ideálním světě by vše probíhalo hladce, ale to se málokdy stává.
DMS lze nakonfigurovat do dvou režimů:
- Plné načtení – výchozí režim popsaný výše. Úlohy DMS se spouštějí po spuštění nebo podle naplánování. Po dokončení jsou úlohy DMS hotové.
- Change Data Capture (CDC) – v tomto režimu úloha DMS běží neustále. DMS sleduje zdrojovou databázi na změny na úrovni tabulek. Při změně se okamžitě pokusí replikovat změnu v cílové databázi na základě konfigurace.
Při použití CDC je třeba zvolit, jakým způsobem CDC extrahuje změny ze zdrojové databáze.
#1. Oracle Redo Logs Reader
Jednou z možností je použít nativní čtečku redo logů Oracle. CDC může využít logy k získání informací o změnách a na jejich základě replikovat změny do cílové databáze.
I když se to může zdát jako ideální volba, má háček: čtečka redo logů Oracle využívá zdroje Oracle clusteru, a tím ovlivňuje ostatní aktivity v databázi (vytváří aktivní relace v databázi).
Čím více úloh DMS máte nakonfigurováno (nebo čím více clusterů DMS paralelně používáte), tím více budete muset navýšit velikost clusteru Oracle – v podstatě vertikálně škálovat primární databázový cluster Oracle. To se projeví na nákladech, zejména pokud je denní synchronizace dlouhodobou záležitostí.
#2. AWS DMS Log Miner
Na rozdíl od předchozího řešení, jedná se o nativní řešení AWS pro stejný problém. V tomto případě DMS neovlivňuje zdrojovou databázi Oracle. Místo toho zkopíruje redo logy Oracle do clusteru DMS a tam zpracuje data. I když to šetří zdroje Oracle, je to pomalejší řešení, protože zahrnuje více operací. Log Miner je pomalejší než nativní čtečka Oracle.
V závislosti na velikosti zdrojové databáze a denním počtu změn, v nejlepším případě můžete dosáhnout inkrementální synchronizace téměř v reálném čase. V ostatních scénářích nebude synchronizace v reálném čase možná, nicméně zpoždění mezi zdrojem a cílem lze snížit optimalizací konfigurace výkonu, paralelizmu clusterů a experimentováním s počtem úloh DMS.
Je také dobré se seznámit s tím, které změny zdrojové tabulky CDC podporuje (např. přidání sloupce), protože ne všechny změny jsou podporovány. Někdy je jediný způsob, jak změnu aplikovat, ruční modifikace cílové tabulky a restartování úlohy CDC od nuly (s ztrátou všech dat v cílové databázi).
Když se věci pokazí, bez ohledu na to, co

Z vlastní zkušenosti vím, že existuje jeden specifický scénář spojený s DMS, kdy je obtížné dosáhnout slibované denní replikace.
DMS zpracovává redo logy pouze s určitou definovanou rychlostí. Nezáleží na tom, kolik máte instancí DMS. Každá instance čte redo logy pouze s určitou rychlostí, a to celé. Nezáleží ani na tom, zda používáte Oracle redo logs nebo AWS log miner. Obě varianty mají tento limit.
Pokud zdrojová databáze generuje velké množství změn během jednoho dne, kdy redo logy Oracle dosahují obrovských velikostí (např. 500 GB+ denně), CDC prostě nebude fungovat. Replikace se nestihne dokončit do konce dne. Následující den se přidají nové změny a množství nezpracovaných dat bude narůstat.
V takovém případě (po mnoha testech výkonu) se CDC ukázalo jako neproveditelné. Jediný způsob, jak zajistit replikaci všech změn v daný den, byl následující:
- Oddělení velkých tabulek, které se nepoužívají tak často a jejich replikace jednou týdně (např. o víkendu).
- Konfigurace replikace velkých tabulek rozdělením mezi více úloh DMS; jedna tabulka byla nakonec migrována 10 i více samostatnými úlohami DMS paralelně. Data mezi úlohami DMS byla rozložena pomocí vlastního kódu. Úlohy se spouštěly denně.
- Přidání dalších instancí DMS (v tomto případě až 4) a rovnoměrné rozdělení úloh DMS mezi ně, podle velikosti tabulek.
V podstatě jsme použili režim plného načtení DMS pro replikaci denních dat, protože to byl jediný způsob, jak zajistit dokončení replikace dat ve stejný den.
Není to dokonalé řešení, ale stále funguje a i po letech se osvědčilo. Možná tedy nakonec není tak špatné. 😃
