Kompletní průvodce REGEX na Google Search Console
Google Search Console, zkráceně GSC, je neocenitelný nástroj pro SEO specialisty, kteří chtějí analyzovat a interpretovat výkon webových stránek.
Zavedení regulárních výrazů, známých jako REGEX, přineslo revoluci do způsobu, jakým získáváme užitečné poznatky o obsahu a jak generujeme nové nápady pro jeho tvorbu.
Funkce REGEX byla v oblasti webové analýzy dlouho očekávaná. Umožňuje totiž filtrování specifických elementů z libovolné URL adresy, což bylo dříve komplikované, nebo dokonce nemožné.
V následujícím textu vám představím tipy a triky, jak efektivně využívat REGEX v Google Search Console. Seznámíte se také s různými operátory, které lze kombinovat s kódy REGEX pro dosažení požadované interpretace dat.
REGEX neboli regulární výraz: stručný přehled
Google Search Console je bezplatná služba, kterou webmasteři používají pro správu a monitorování výkonu svých webových stránek. Poskytuje detailní přehledy o míře prokliku, počtu zobrazení, kliknutí 🖱️ a hodnocení klíčových slov. Tyto informace jsou klíčové pro hodnocení úspěšnosti SEO strategií.
Nicméně, při filtrování dat o výkonu URL adres existovala určitá omezení. GSC umožňovala exportovat maximálně 1000 řádků pro analýzu. Filtrování URL adres bylo omezeno na konkrétní sekce, jako je definování cesty, vlastnosti domény nebo předpony, a neumožňovalo složitější řetězce a varianty.
Příchod regulárních výrazů (Regex) představuje významný pokrok v GSC. Jeho cílem je poskytnout SEO specialistům systém, díky kterému mohou z GSC získávat detailnější informace o funkčnosti a výkonu webových stránek.
Regex umožňuje odhalovat klíčové SEO detaily webu pomocí specifických kódů aplikovaných na stránky nebo filtry dotazů. Tyto kódy se skládají z metaznaků obklopujících řetězec, který souvisí s parametrem filtrování. Po zadání Regex kódu se na panelu zobrazí výsledek, který je možné uložit pro pozdější použití.
Výhody využití Regex v GSC
Hlavním cílem práce s Google Search Console je analýza webu z technického hlediska. SEO týmy využívají řadu nástrojů a technik pro optimalizační strategii, jejímž cílem je dosáhnout vysokých pozic 📈 ve vyhledávačích a generovat návštěvnost webu.
Regex přináší další výhodu tím, že usnadňuje proces sběru užitečných dat, která lze následně využít ke zdokonalení optimalizačních strategií. Níže jsou uvedeny příklady, jaké informace lze pomocí Regex získat.
✨ Pomocí Regex kódů v dotazech můžete zjistit objem vyhledávání pro konkrétní klíčová slova nebo fráze. To vám pomůže s generováním nových témat pro váš blog a zvýšením jeho návštěvnosti.
✨ Regex kódy šetří čas SEO specialistů, kteří pracují ve velkých společnostech a zpracovávají obrovské objemy webových dat. K filtrování dotazů nebo stránek podle konkrétních požadavků stačí několik metaznaků a řetězců ve správné syntaxi.
✨ Jednou z hlavních výhod je schopnost pracovat s komplexními kombinacemi slov, vět a URL. Důležité je umístit znaky ve správném pořadí, aby byl Regex kód funkční.
✨ Bezpochyby poskytuje lepší přehled o webu, včetně stránek s vysokým i nízkým výkonem a sledování trendů.
✨ Regex kódy můžete aplikovat na vlastní reporty a monitorovat tok návštěvnosti na webu pro konkrétní dotazy. Následně můžete zadat vašemu týmu specifické úkoly.
Je možné nastavit různé kombinace znaků Regex k vytvoření kódu a jeho následné využití k optimalizaci vašeho webu.
Kde používat Regex v Google Search Console?
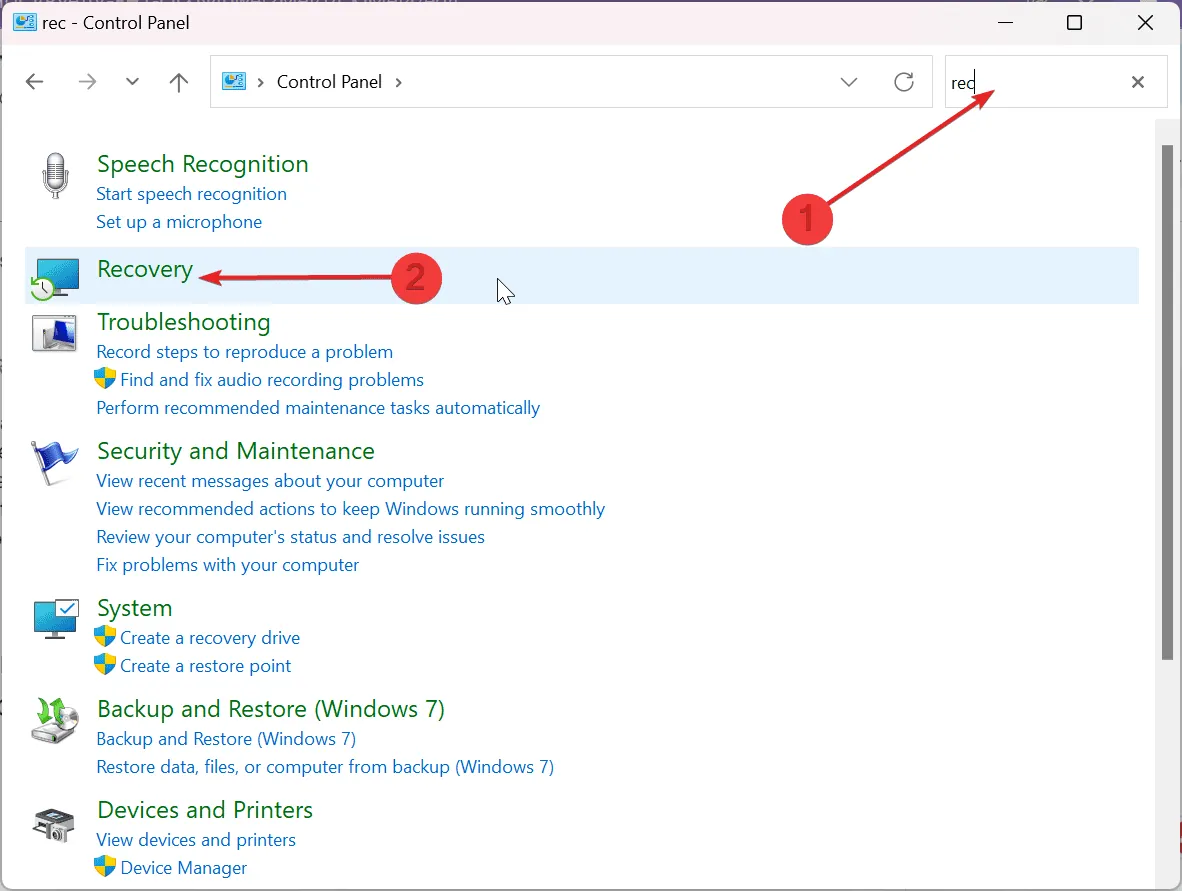
Pro používání funkce Regex v GSC je klíčový přístup k vlastnictví webu. Je to nezbytná podmínka, protože bez tohoto přístupu nebudete moci web přidat jako svou nemovitost v Google Search Console pro žádnou analytickou práci.
Přihlaste se do Google Search Console pomocí vašeho Gmail ID a začněte přidáním nemovitosti (webu) z možnosti na bočním panelu. Nemovitostí je web, který vlastníte nebo máte oprávnění k přístupu v konzoli.
Po přidání webové stránky nebo jakékoli URL adresy budete vyzváni k jejímu ověření ✅. Postup ověření je uveden ve sloupci a po jeho dokončení můžete vybrat svou nemovitost pro další kroky.
Pod názvem nemovitosti klikněte na parametr "Výkon" a poté na tlačítko "Nový" nad grafem pro možnosti filtrování.
Pro použití Regex kódu k filtrování výsledků máte na výběr Dotaz nebo Stránky.
Vysvětlení znaků Regex
Při filtrování dotazů a stránek v Google Search Console se používá několik sad znaků jako regulární výrazy. Každý metaznak má ve filtru specifický význam. Pokud jim dobře porozumíte, nebude analýza GSC s pomocí Regex složitá.
V tabulce níže uvádím vysvětlení některých symbolů a znaků používaných v Regex kódech, doplněné o příklady.
| Znaky | Použití | Příklad |
| () | Tyto závorky se používají pro seskupování znaků nebo výrazů, také označované jako zachycující skupiny. | (Geek) Zobrazí všechny webové stránky, které mají na začátku názvu slovo "Mobile". |
| [^] | Pokud zpětné lomítko následuje za stříškou, bude filtrovat URL adresy s daným slovem "mobile". | [^\mobile] Filtruje URL s daným slovem "mobile" |
| | | Symbol "NEBO", používaný k vyjádření volby v kódu. | Mobile|PC Sestava zobrazí všechny stránky, které obsahují jedno z těchto dvou slov. |
| ^ | Symbol stříšky odpovídá slovu nebo frázi na začátku řetězce. | ^Mobil Zobrazí všechny webové stránky, které začínají slovem "Mobil" |
| $ | Symbol dolaru odpovídá slovu nebo frázi na konci řetězce. | Mobile$ Zobrazí všechny webové stránky končící slovem "Mobile" |
| . | Tečka se používá pro shodu libovolného jednotlivého znaku v řetězci. | to. Zobrazí všechny webové stránky končící "to" a libovolným znakem. |
| \ | Zpětné lomítko se používá pro ignorování doslovného významu znaků. | \d Zobrazí stránky obsahující číslice 0-9. |
| [xyz] | Odpovídá dotazu, který obsahuje jeden nebo všechny znaky uvedené v závorce (x, y, nebo z). | Mobile[xyz] Zobrazí stránky s kombinacemi mobilex, mobilezy, mobilezxy. |
| [c-m] | Odpovídá dotazu, který obsahuje libovolné malé nebo velké písmeno v rozmezí c až m. | Mobile[c-m] Zobrazí stránky s kombinacemi, mobilecjg, mobileeel, mobilecdf. |
| [3-7] | Odpovídá dotazu s čísly mezi 3 a 7. | Mobile[0-9] Zobrazí stránky s kombinacemi mobile73, mobile654, mobile445. |
| [\w] | Odpovídá každému slovu na webových stránkách s písmeny "to" jako "to, do". | [\w]*Mobilní, pohybliví[\w] Zpětné lomítko následované malým "w", odpovídá jakémukoli slovu nebo znaku. |
| [\W] | Porovná stránky se slovem "mobilní" s dalšími slovy, např. mobilní telefon, mobilní aplikace. | [\W]*Mobilní, pohybliví[\W] Zpětné lomítko následované velkým "W", odpovídá všemu kromě písmen a číslic. |
Pomocí těchto znaků je možné vytvářet složitější kódy a filtrovat dotazy v GSC.
Konkrétní regulární výrazy v Google Search Console
Pomocí metaznaků v Google Search Console můžete vytvářet unikátní vzory nebo kódy pro konkrétní účely. Níže uvádím několik příkladů, které si můžete vyzkoušet na svém GSC portálu.
🔶 ^[\w\W\s\S]{70,}$
Tento kód bude odpovídat všem slovům, číslům, neslovním a speciálním znakům, symbolům, mezerám a jiným než bílým znakům nebo novým řádkům. Kvantifikátor "70" znamená, že řetězec je dlouhý nebo má alespoň 70 znaků.
Příklad: Tento typ kódu je užitečný při ověřování hesel, filtrování seznamů produktů s detailním popisem, a podobně.
🔶 (\w+\s){6,}\w+
Tento Regex kód se skládá ze tří sekcí. Jeho cílem je porovnat slova a čísla, mezi nimiž jsou mezery. Kód vybere řetězce o délce minimálně 6 slov nebo delší, jako například: "Řetězce, které jsou alespoň 6 slov nebo delší."
Příklad: Tento kód se hodí při filtrování článků s delšími názvy, dlouhých komentářů na sociálních sítích atd.
🔶 ^(kdo|co|kde|kdy|proč|jak)[“ “]
Tento Regex kód je jednoduchý a užitečný pro bloggery a SEO specialisty. Je zřejmé, že se bude shodovat se všemi dotazy ve vyhledávači, které začínají jedním z těchto slov: kdo, co, kde, kdy, proč nebo jak. Řetězec musí začínat jedním z těchto slov, za nímž musí následovat mezera. Proto se neshoduje se slovy jako "nicméně" nebo "celý".
Příklad: Tento kód je vhodný pro sledování tržních trendů a diskuzí uživatelů za účelem získání nových nápadů pro tvorbu obsahu.
🔶 „kdo|co|kde|kdy|proč|jak“
Podobně jako předchozí kód, i tento se shoduje se všemi řetězci, které obsahují jakékoli z uvedených slov, bez ohledu na to, zda jimi řetězec začíná nebo ne.
Příklad: Tento kód se hodí pro identifikaci pochybných tvrzení, filtrování uživatelských vstupů apod.
🔶 .*
Tečka metaznaku následovaná hvězdičkou se často označuje jako zástupný znak, protože ji můžete použít ke spárování jakéhokoli specifického řetězce tak, že jej vložíte pod tento kód.
Příklad: Regex .*Android.* načte všechny stránky, které obsahují slovo Android. Použití kódu .* na filtru zobrazí všechny stránky, které se za daný měsíc objevily ve vyhledávači.
🔶 [^\/\.\-:0-9A-Za-z_]
Za symbolem stříšky následuje zpětné lomítko, které vyloučí znaky uvedené v kódu. V tomto případě se kód shodu s řetězci, které neobsahují lomítko, číslice, tečku, dvojtečku, pomlčku a všechna velká a malá písmena.
Příklad: Kód se tak hodí pro zachycení URL adres, metapopisů nebo obsahu, který obsahuje speciální znaky jako &%$@.
🔶 ?i)(((je|jsou).(značka|stránka|společnost)|(značka|stránka|společnost).(je|jsou)).*(zmetek|spolehlivý))
Jedná se o komplexní Regex kód s několika specifickými částmi. Znak "?i" na začátku kódu označuje ignorování rozdílů mezi velkými a malými písmeny. Kód se tedy bude shodovat s řetězci bez ohledu na velikost písmen. Závorky za tímto znakem obsahují slova oddělená svislou čarou (OR).
Tento Regex kód detekuje dotazy, které obsahují slova je nebo jsou, značka, společnost nebo web, a také slova zmetek nebo spolehlivý, bez ohledu na velikost písmen.
Příklad: Tento kód se hodí k analýze zákaznických dotazů. Můžete tak zjistit, zda jsou recenze vašeho webu pozitivní, nebo negativní.
🔶 (kwd1|kwd2).*
Jedná se o zjednodušené použití disjunkčního kódu, kde GSC odfiltruje stránky nebo dotazy, které obsahují slovo kwd1 nebo kwd2, následované libovolným písmenem nebo číslem.
Příklad: Tento vzor můžete použít k extrahování stránek, které obsahují daná slova, a to v URL adrese, v názvu, v popisu nebo v obsahu.
🔶 (Klíčové slovo1 A Klíčové slovo2)
Tento kód je příkladem konjunkčního výrazu. "AND" je operátor používaný v Regex kódu. Získáte tak stránky, které obsahují obě slova ve stejném pořadí.
Příklad: Tento kód můžete použít v GSC pro získání stránek, které mají daná dvě slova v názvu nebo popisu v přesně daném pořadí.
🔶 „klíčové slovo1 klíčové slovo2“
Tento kód se hodí pro vyhledávání přesné fráze nebo pořadí slov na webové stránce.
Příklad: Použijte tento kód v GSC pro nalezení stránek s názvem, popisem nebo obsahem, který obsahuje konkrétní frázi.
🔶 (Klíčové slovo 1 | Klíčové slovo 2)
Tento kód obsahuje dvě slova a svislou čáru. GSC tak zobrazí stránky, které obsahují buď "Klíčové slovo 1" nebo "Klíčové slovo 2", ale ne obě.
Příklad: Použijte tento kód pro extrahování stránek s jedním z uvedených slov oddělených svislou čarou.
🔶 (Klíčové slovo1)\b(Klíčové slovo2)\b
Tento Regex kód obsahuje dvě slova se znakem "\b", který je symbolem pro hranici slova. Zobrazí stránky, které obsahují obě slova, a žádné další slovo, číslici nebo znak mezi nimi.
Příklad: Použijte tento kód ve filtru GSC pro nalezení stránek, které obsahují dvě samostatná slova v sousedství.
🔶 (Klíčové slovo1)\w+(Klíčové slovo2)
Tento kód obsahuje dvě slova s metaznakem "\w+" mezi nimi, kde "w" je malé. Zobrazí tak všechny stránky, které obsahují obě slova, bez ohledu na počet slov mezi nimi, a to v názvu, v popisu nebo v obsahu.
Příklad: Tento kód se hodí pro extrahování stránek, které obsahují obě slova kdekoli v názvu, obsahu, nebo meta popisu.
🔶 (klíčové slovo)\bfráze
Jedná se o jednoduchý Regex kód, který spojuje slovo v závorkách s frází, za kterou následuje. Metaznak "\b" označuje hranici slova nebo absence jiných znaků mezi slovy.
Příklad: Tento kód v GSC zobrazí stránky, které obsahují daná slova v řadě kdekoli v článku, například "klíčové slovo fráze".
🔶 a-url.|.b-url.|.c-url.|.e-url.|.f-url.|.g-url.|.h-url.|.i-url.|.j -url.|.k-url.|.l-url.|.m-url.|.n-url.|.o-url.|.p-url.|.
Tento Regex kód obsahuje několik URL adres "a,b,c,e,g...", které jsou oddělené svislou čárou. Zobrazí tak řetězce s jednou z těchto URL adres.
Příklad: V GSC můžete použít tento vzor pro získání webových stránek, které obsahují specifické URL adresy v názvu nebo v článku.
🔶 ^(jablko|koule|kočka|kachní farma)$
Tento kód zaručuje shodu začátku řetězce s jedním z daných slov: jablko, koule, kočka, nebo kachní farma, jelikož jsou odděleny svislou čárou. Zaručuje také, že se v řetězci neobjeví žádné další slovo nebo znak.
Příklad: Tento kód se hodí pro získání informací o stránkách, které na začátku obsahují daná klíčová slova.
🔶 .*\/$
Cílem tohoto Regex kódu je zachytit jakýkoli řetězec, ať už se jedná o slova nebo čísla, ale musí končit lomítkem.
Příklad: Můžete jej použít pro vyhledání stránek, jejichž URL adresa končí lomítkem.
🔶 .(nejlepší|nahoře|vs|recenze).*
Tento kód se shoduje s řetězci, které na začátku obsahují tečku, za ní následuje jedno z daných slov oddělených svislou čarou, a po němž následují další slova, čísla, nebo speciální znaky.
Příklad: Tento vzor Regex je užitečný v komerčních reportech pro pochopení tržních trendů.
🔶 (koupit|levně|cena|koupit|objednat).
Tento kód se shoduje s řetězci, které obsahují jedno z uvedených slov oddělených svislou čarou a za nímž následují další slova, čísla nebo znaky.
Příklad: Tyto kódy se hodí pro vyhledávání transakčních vyhledávání nebo dotazů souvisejících s produkty vašeho webu.
🔶 (obličej(b|be)ook) 🔶 (f(a|e)ce(b|be)ook 🔶 (fa(c|s)(e|i)kniha)
Tyto kódy obsahují kombinace slov v závorkách oddělených svislými čarami.
První kód odpovídá řetězcům, které obsahují slovo "face" následované "b" nebo "be", a končí slovem "ook". Načtené stránky tedy budou obsahovat slovo facebook nebo facebeook.
Druhý kód odpovídá řetězcům, které obsahují slovo "f" následované "a" nebo "e", následované "ce", dále "b" nebo "be" a končí "ook". Načtené stránky tedy budou obsahovat různé kombinace, například facebook, fecebook, facebeook nebo fecebeook.
Třetí kód odpovídá řetězcům, které obsahují slovo "fa" následované "c" nebo "s", následované "e" nebo "I" a končí slovem "kniha". Načtené stránky tedy budou obsahovat libovolnou kombinaci, například facebook, facibook, fasebook nebo fasibook.
Příklad: Tyto kódy vám pomohou s hledáním pravopisných chyb na vašich webových stránkách.
🔶 .wp-.
Tento kód se shoduje s řetězci, které obsahují tečku, následuje "wp-" a další znaky.
Příklad: Je vhodný pro extrahování stránek s URL adresami WordPress.
🔶 .*/url-1/.* vs.*/url-2/.*
Tento kód obsahuje dvě různé URL adresy s porovnávacím znakem Regex. Z vašeho webu vybere dvě specifické URL adresy pro porovnání jejich metrik.
Příklad: Tento kód můžete použít pro porovnání návštěvnosti, chování uživatelů a dalších metrik mezi dvěma specifickými webovými stránkami na vašem webu.
Další méně obvyklé regexy
🔺 (?i)\bklíčové slovo\b
Tento kód se shoduje s řetězcem, který obsahuje slovo "klíčové slovo", bez ohledu na velikost písmen v textu.
🔺 „fráze“
Tento kód se jednoduše shoduje se stránkami, které obsahují přesně danou frázi.
🔺 \w{5}
Kód se shoduje s dotazy, které mají 5 slovních znaků.
🔺 \d{3}
Tento kód se shoduje s dotazy, které mají přesně 3 číslice.
🔺 ([^” “]*)
Tento Regex kód se shoduje s řetězci, které neobsahují žádné uvozovky.
🔺 (?i)\b(klíčové slovo1|klíčové slovo2|klíčové slovo3)\b
Tento kód se shoduje s řetězci, které obsahují libovolné z uvedených slov oddělených svislou čarou, bez ohledu na velikost písmen.
🔺 \W+
Tento kód se shoduje s libovolným počtem neslovních znaků, typicky speciálních znaků.
🔺 \d{3,5}
Tento kód se shoduje se všemi řetězci, které mají čísla s 3 až 5 číslicemi.
🔺 \b\w+\b
Tento kód se shoduje s libovolným počtem slovních znaků s hranicemi slov.
Závěrečná slova
Zavedení kódů Regex do výkonnostních filtrů udělalo z Google Search Console nástroj s obrovským potenciálem. Vše, co je potřeba, je pochopení struktury kódů pro získání analytických reportů.
Můžete vytvářet různé Regex kódy pro získání specifických informací o výkonu vašeho webu, které můžete použít pro jeho vylepšení a dosažení lepších výsledků.
Nezapomeňte si také prohlédnout triky vyhledávání Google, které vám pomohou zdokonalit vyhledávání na internetu.
