Nejlepší Python knihovny pro datové vědce
Tento text se zaměřuje na představení a objasnění některých z nejlepších knihoven v jazyce Python, které jsou neocenitelné pro datové vědce a týmy zabývající se strojovým učením.
Python se v těchto dvou oblastech uplatňuje jako ideální jazyk, a to zejména díky bohaté nabídce specializovaných knihoven.
Tato výhoda pramení z možností, které knihovny Pythonu nabízejí v oblastech jako je vstup a výstup dat, analýza dat a další operace zpracování dat, které jsou klíčové pro datové vědce a odborníky na strojové učení při jejich práci s daty.
Co jsou knihovny Pythonu?
Knihovna Pythonu představuje rozsáhlý soubor integrovaných modulů, které obsahují předkompilovaný kód včetně tříd a metod. Díky tomu vývojáři nemusí psát kód od základu.
Význam Pythonu v kontextu datové vědy a strojového učení
Python se pyšní jedněmi z nejlepších knihoven, které jsou dostupné odborníkům na strojové učení a datovou vědu.
Jeho snadno pochopitelná syntaxe umožňuje efektivní implementaci komplexních algoritmů strojového učení. Navíc, díky této syntaxi je proces učení rychlejší a snazší.
Python také podporuje rychlý vývoj prototypů a bezproblémové testování aplikací.
Velká komunita Pythonu je pro datové vědce neocenitelná, protože nabízí rychlé řešení jejich dotazů.
Jak velký užitek přinášejí knihovny Pythonu?
Knihovny Pythonu jsou velmi užitečné při vývoji aplikací a modelů v oblasti strojového učení a datové vědy.
Tyto knihovny značně pomáhají vývojářům tím, že umožňují opětovné použití kódu. Místo toho, aby objevovali znovu kolo, mohou importovat knihovnu s konkrétní funkcí, kterou potřebují.
Které knihovny Pythonu se používají ve strojovém učení a datové vědě?
Odborníci na datovou vědu doporučují několik Python knihoven, které by měli znát všichni, kdo se o tuto oblast zajímají. V závislosti na konkrétní aplikaci, odborníci na strojové učení a datovou vědu využívají různé knihovny Pythonu, které lze rozdělit do kategorií jako knihovny pro nasazení modelů, dolování a extrakci dat, zpracování dat a vizualizaci dat.
Tento článek se zaměřuje na některé z nejčastěji používaných knihoven Pythonu v datové vědě a strojovém učení.
Nyní se na ně podíváme blíže.
Numpy
Knihovna Numpy, jejíž plný název zní Numerical Python Code, je postavena s využitím vysoce optimalizovaného kódu C. Datoví vědci ji upřednostňují kvůli jejím pokročilým matematickým a vědeckým výpočetním schopnostem.
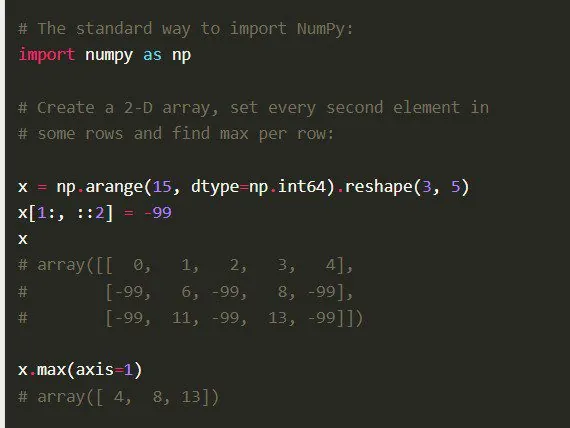
Funkce
- Numpy má syntaxi na vysoké úrovni, která je pro programátory se zkušenostmi snadno pochopitelná.
- Výkon této knihovny je poměrně vysoký díky optimalizovanému kódu C.
- Nabízí nástroje pro numerické výpočty včetně Fourierovy transformace, lineární algebry a generátorů náhodných čísel.
- Jedná se o open-source projekt, což umožňuje přispívání od velkého počtu vývojářů.
Numpy nabízí další komplexní funkce, jako je vektorizace matematických operací, indexování a klíčové koncepty při implementaci polí a matic.
Pandy
Pandas je renomovaná knihovna ve světě strojového učení, která poskytuje datové struktury na vysoké úrovni a mnoho nástrojů pro jednoduchou a efektivní analýzu rozsáhlých datových sad. Tato knihovna dokáže provádět složité operace s daty pomocí minimálního počtu příkazů.
Tato knihovna se skládá z mnoha vestavěných metod, které umí seskupovat, indexovat, načítat, rozdělovat, restrukturalizovat data a filtrovat sady před tím, než je vloží do jedno a vícerozměrných tabulek.
Hlavní charakteristiky knihovny Pandas
- Pandas usnadňují označování dat do tabulek a automatické zarovnávání a indexování dat.
- Dokáže rychle načítat a ukládat datové formáty jako JSON a CSV.
Je vysoce efektivní díky své robustní funkčnosti pro analýzu dat a vysoké flexibilitě.
Matplotlib
Matplotlib je 2D grafická knihovna v Pythonu, která dokáže snadno zpracovávat data z mnoha zdrojů. Vizualizace, které generuje, jsou statické, animované a interaktivní a uživatel si je může přiblížit. Díky tomu je Matplotlib efektivní pro vizualizace a tvorbu grafů. Umožňuje také upravovat rozložení a vizuální styl.
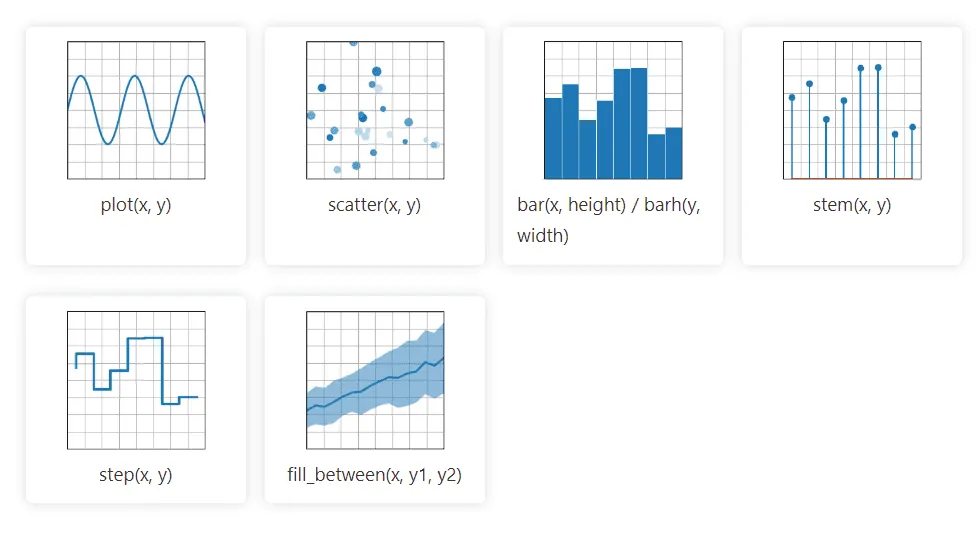
Jeho dokumentace je open-source a nabízí obsáhlou sbírku nástrojů potřebných pro implementaci.
Matplotlib importuje pomocné třídy pro práci s rokem, měsícem, dnem a týdnem, což usnadňuje manipulaci s daty časových řad.
Scikit-learn
Pokud hledáte knihovnu pro práci s komplexními daty, Scikit-learn by měla být vaší první volbou. Knihovna Scikit-learn je široce využívána odborníky na strojové učení. Je propojena s dalšími knihovnami, jako jsou NumPy, SciPy a matplotlib. Nabízí algoritmy učení s dohledem i bez dohledu, které lze použít v produkčních aplikacích.
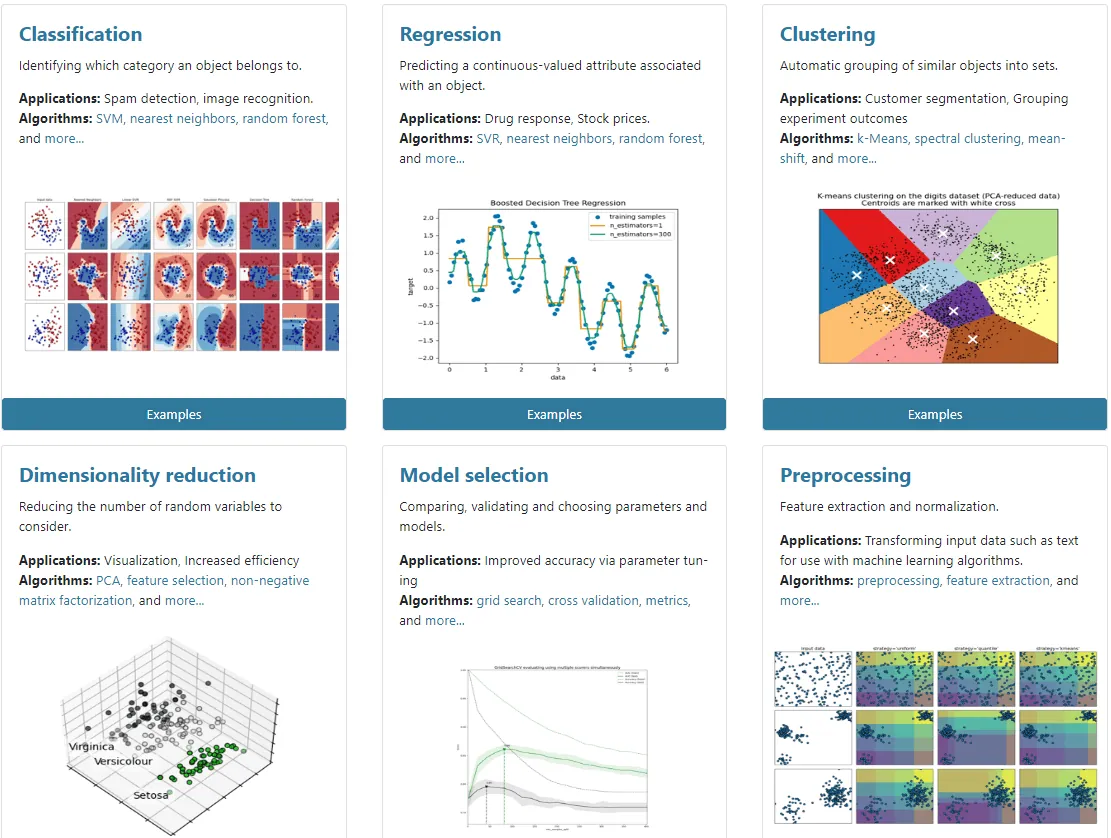
Vlastnosti knihovny Scikit-learn Python
- Identifikace kategorií objektů, například pomocí algoritmů jako SVM a náhodného lesa v aplikacích, jako je rozpoznávání obrázků.
- Predikce spojité hodnoty, což je objekt spojený s úlohou zvanou regrese.
- Extrakce funkcí.
- Snížení rozměrů, tedy snížení počtu náhodných proměnných.
- Shlukování podobných objektů do skupin.
Knihovna Scikit-learn je efektivní při extrahování funkcí z textových a obrazových datových sad. Navíc umožňuje ověřovat přesnost modelů s dohledem na neznámých datech. Její mnohé dostupné algoritmy umožňují dolování dat a další úlohy strojového učení.
SciPy
SciPy (Scientific Python Code) je knihovna pro strojové učení, která poskytuje moduly aplikované na matematické funkce a algoritmy. Její algoritmy řeší algebraické rovnice, interpolaci, optimalizaci, statistiku a integraci.
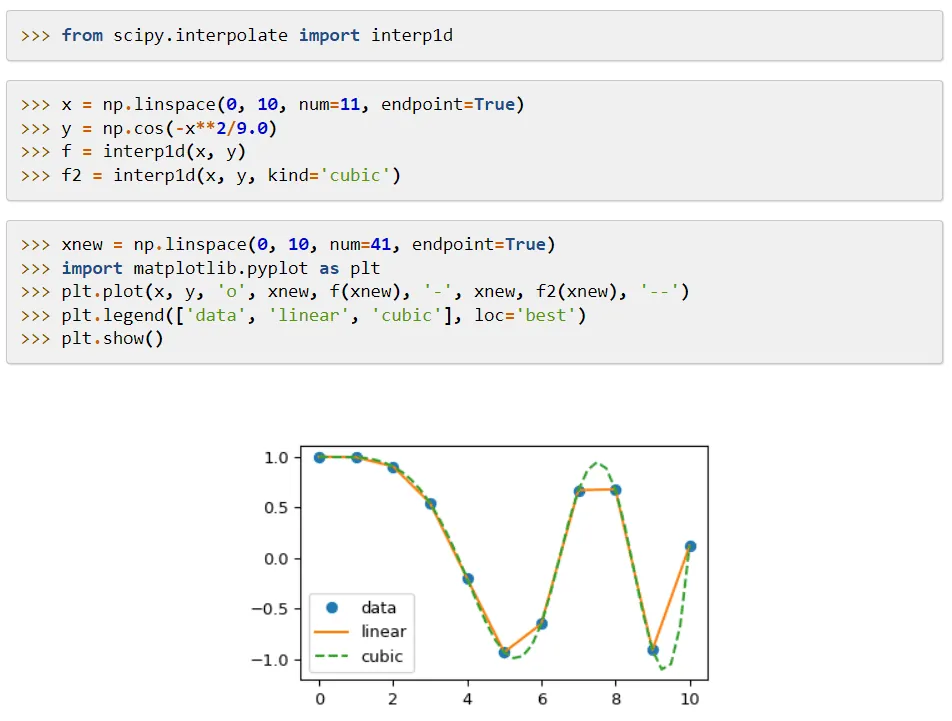
Hlavní výhodou je její rozšíření NumPy, které přidává nástroje pro řešení matematických funkcí a poskytuje datové struktury, jako jsou řídké matice.
SciPy používá příkazy a třídy na vysoké úrovni pro manipulaci a vizualizaci dat. Její systémy pro zpracování dat a prototypové systémy z ní dělají ještě efektivnější nástroj.
Syntaxe SciPy na vysoké úrovni je navíc pro programátory všech úrovní zkušeností snadno použitelná.
Jedinou nevýhodou SciPy je její zaměření pouze na numerické objekty a algoritmy, takže nenabízí žádnou funkci vykreslování.
PyTorch
Tato všestranná knihovna pro strojové učení efektivně implementuje výpočty tenzorů s akcelerací GPU, vytváří dynamické výpočetní grafy a automatické výpočty přechodů. Základem knihovny PyTorch je knihovna Torch, která je open-source knihovnou pro strojové učení vyvinutou v jazyce C.
Mezi klíčové vlastnosti patří:
- Podpora bezproblémového vývoje a škálování díky dobré podpoře na hlavních cloudových platformách.
- Robustní ekosystém nástrojů a knihoven podporuje vývoj počítačového vidění a dalších oblastí jako je zpracování přirozeného jazyka (NLP).
- Zajištění plynulého přechodu mezi dychtivým a grafickým režimem pomocí Torch Script, zatímco používá TorchServe pro urychlení cesty do produkce.
- Distribuovaný backend Torch umožňuje distribuované školení a optimalizaci výkonu ve výzkumu a výrobě.
PyTorch můžete použít při vývoji aplikací NLP.
Keras
Keras je open-source knihovna Pythonu pro strojové učení, která se používá k experimentování s hlubokými neuronovými sítěmi.
Je známá tím, že nabízí nástroje, které mimo jiné podporují úkoly, jako je kompilace modelů a vizualizace grafů. Jako backend využívá Tensorflow. Alternativně můžete v backendu použít Theano nebo neuronové sítě, jako je CNTK. Tato backendová infrastruktura jí pomáhá vytvářet výpočetní grafy používané k implementaci operací.
Klíčové vlastnosti knihovny
- Může efektivně běžet jak na centrální procesorové jednotce, tak na grafické procesorové jednotce.
- Ladění je s Keras jednodušší, protože je založeno na Pythonu.
- Keras je modulární, díky tomu je výrazný a přizpůsobivý.
- Keras můžete nasadit kdekoliv přímým exportem jeho modulů do JavaScriptu a spustit jej v prohlížeči.
Aplikace Keras zahrnují stavební bloky neuronové sítě, jako jsou vrstvy a cíle, a další nástroje, které usnadňují práci s obrázky a textovými daty.
Seaborn
Seaborn je dalším cenným nástrojem pro vizualizaci statistických dat.
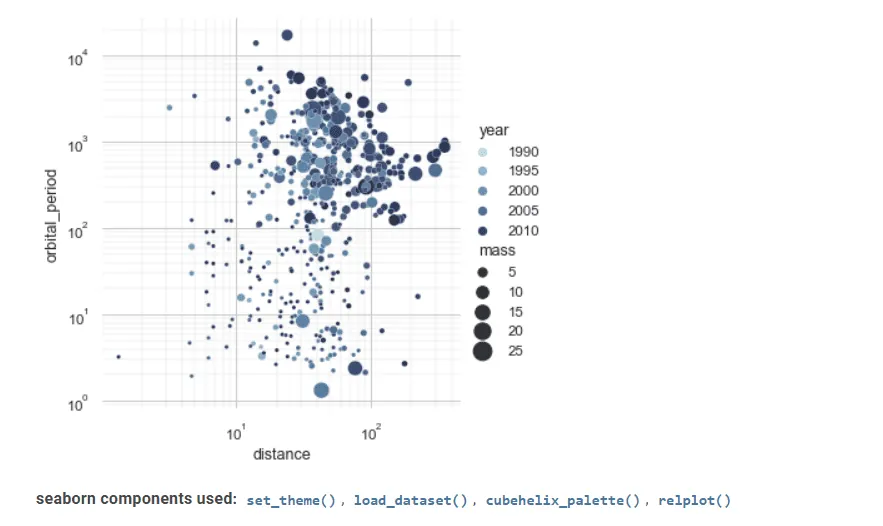
Jeho pokročilé rozhraní dokáže vytvářet atraktivní a informativní statistické grafické výkresy.
Plotly
Plotly je 3D webový vizualizační nástroj postavený na knihovně Plotly JS. Poskytuje širokou podporu pro různé typy grafů, jako jsou spojnicové grafy, bodové grafy a krabicové grafy.
Používá se například k vytváření webových vizualizací dat v noteboocích Jupyter.
Plotly je vhodný pro vizualizaci, protože dokáže pomocí nástroje pro zobrazení hodnoty při přejetí kurzorem zvýraznit odlehlé hodnoty nebo abnormality v grafu. Grafy si také můžete přizpůsobit dle svých představ.
Nevýhodou Plotlyho je, že jeho dokumentace není vždy aktuální, takže se může obtížně používat jako průvodce pro uživatele. Navíc má mnoho nástrojů, které se uživatel musí naučit. Je náročné si všechny zapamatovat.
Vlastnosti knihovny Plotly Python
- 3D grafy, které používá, umožňují více bodů interakce.
- Má zjednodušenou syntaxi.
- Můžete chránit soukromí svého kódu a přitom sdílet své výtvory.
SimpleITK
SimpleITK je knihovna pro analýzu obrazu, která nabízí rozhraní pro Insight Toolkit (ITK). Je postavena na C++ a je open-source.
Vlastnosti knihovny SimpleITK
- Její I/O obrazových souborů podporuje a dokáže převést až 20 formátů obrazových souborů jako jsou JPG, PNG a DICOM.
- Poskytuje mnoho filtrů pro segmentaci obrazu, včetně Otsu, sad úrovní a povodí.
- Interpretuje obrázky jako prostorové objekty, nikoli jako pole pixelů.
Její zjednodušené rozhraní je dostupné v různých programovacích jazycích, jako jsou R, C#, C++, Java a Python.
Statsmodel
Statsmodel odhaduje statistické modely, implementuje statistické testy a zkoumá statistická data pomocí tříd a funkcí.
Specifikace modelů využívá vzorce ve stylu R, pole NumPy a datové rámce Pandas.
Scrapy
Tento open-source balíček je preferovaným nástrojem pro získávání (seškrabávání) a procházení dat z webových stránek. Je asynchronní, a proto poměrně rychlý. Scrapy má architekturu a funkce, které zajišťují její efektivitu.
K nevýhodám patří, že se jeho instalace pro různé operační systémy liší. Navíc jej nelze použít na webech postavených na JS. Může také pracovat pouze s Pythonem 2.7 nebo novějšími verzemi.
Odborníci na datovou vědu jej používají při dolování dat a automatizovaném testování.
Funkce
- Dokáže exportovat data ve formátech JSON, CSV a XML a ukládat je do různých backendů.
- Má vestavěnou funkci pro sběr a extrakci dat ze zdrojů HTML/XML.
- K rozšíření Scrapy můžete použít dobře definované API.
Pillow
Pillow je zobrazovací knihovna Pythonu, která slouží k manipulaci a zpracování obrázků.
Rozšiřuje možnosti zpracování obrázků v Pythonu, podporuje různé formáty souborů a nabízí vynikající interní reprezentaci.
Díky Pillow je snadný přístup k datům uloženým v základních formátech souborů.
Závěr 💃
Tímto jsme shrnuli náš průzkum některých z nejlepších knihoven Pythonu pro datové vědce a odborníky na strojové učení.
Jak tento článek ukazuje, Python má mnoho užitečných balíčků pro strojové učení a datovou vědu. Python nabízí i další knihovny, které můžete použít v jiných oblastech.
Možná se budete chtít dozvědět více o některých z nejlepších datových vědeckých notebooků.
Příjemné učení!
