
Tento článek zmiňuje a vysvětluje některé z nejlepších pythonových knihoven pro datové vědce a tým strojového učení.
Python je ideální jazyk, který se v těchto dvou oblastech skvěle používá hlavně pro knihovny, které nabízí.
To je způsobeno aplikacemi knihoven Python, jako je vstup/výstup dat I/O a analýza dat, mimo jiné operace manipulace s daty, které datoví vědci a odborníci na strojové učení používají ke zpracování a zkoumání dat.
Table of Contents
Knihovny Pythonu, co to je?
Knihovna Pythonu je rozsáhlá sbírka vestavěných modulů obsahujících předkompilovaný kód, včetně tříd a metod, takže vývojáři nemusí implementovat kód od začátku.
Význam Pythonu v datové vědě a strojovém učení
Python má ty nejlepší knihovny pro použití odborníky na strojové učení a datovou vědu.
Jeho syntaxe je snadná, a proto je efektivní implementovat složité algoritmy strojového učení. Jednoduchá syntaxe navíc zkracuje křivku učení a usnadňuje pochopení.
Python také podporuje rychlý vývoj prototypů a hladké testování aplikací.
Velká komunita Pythonu je užitečná pro datové vědce, aby v případě potřeby pohotově hledali řešení svých dotazů.
Jak užitečné jsou knihovny Pythonu?
Knihovny Pythonu jsou nápomocné při vytváření aplikací a modelů v oblasti strojového učení a datové vědy.
Tyto knihovny výrazně pomáhají vývojářům s opětovnou použitelností kódu. Proto můžete importovat relevantní knihovnu, která implementuje specifickou funkci v rámci vašeho programu, jinou než znovuobjevení kola.
Knihovny Pythonu používané ve strojovém učení a datové vědě
Odborníci na datovou vědu doporučují různé knihovny Pythonu, které musí nadšenci datové vědy znát. V závislosti na jejich relevanci v aplikaci používají odborníci na strojové učení a datovou vědu různé knihovny Pythonu kategorizované do knihoven pro nasazení modelů, dolování a seškrabování dat, zpracování dat a vizualizaci dat.
Tento článek identifikuje některé běžně používané knihovny Pythonu v Data Science a Machine learning.
Pojďme se na ně nyní podívat.
Numpy
Numpy Python knihovna, také Numerical Python Code v plném rozsahu, je postavena s dobře optimalizovaným C kódem. Data Scientists jej preferují pro jeho hluboké matematické výpočty a vědecké výpočty.
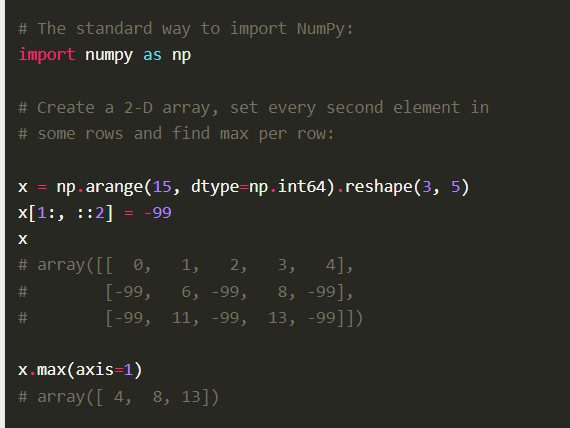
Funkce
Numpy přichází s dalšími komplexními funkcemi, jako je vektorizace matematických operací, indexování a klíčové koncepty při implementaci polí a matic.
pandy
Pandas je slavná knihovna v oblasti strojového učení, která poskytuje datové struktury na vysoké úrovni a četné nástroje pro snadnou a efektivní analýzu rozsáhlých datových sad. S velmi malým počtem příkazů může tato knihovna překládat složité operace s daty.
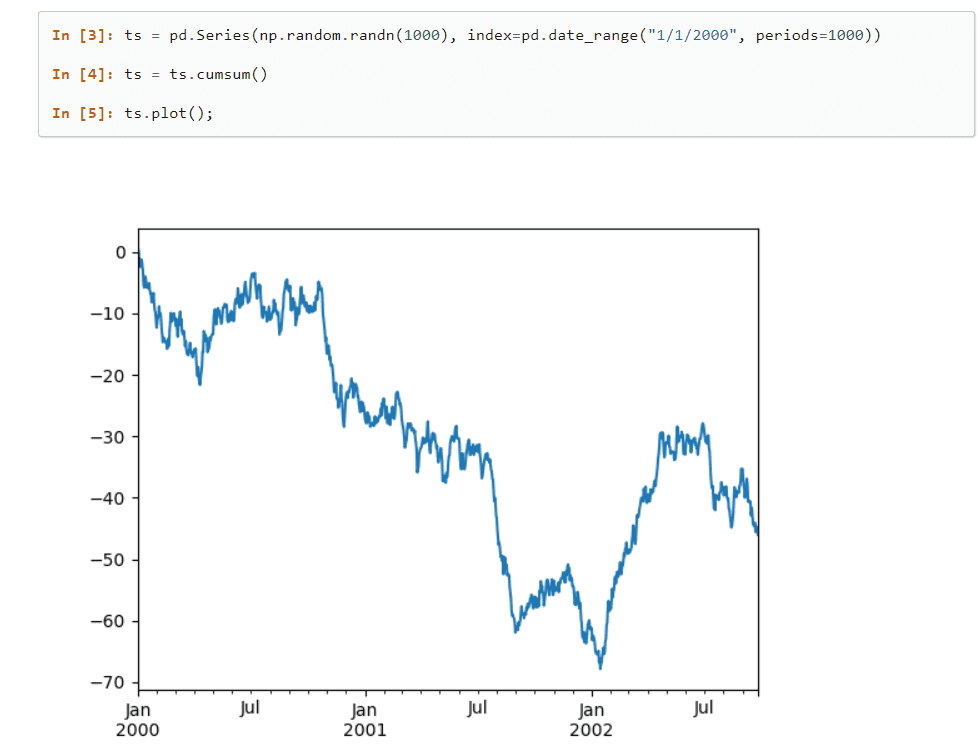
Četné vestavěné metody, které mohou seskupit, indexovat, načíst, rozdělit, restrukturalizovat data a filtrovat sady před jejich vložením do jednorozměrných a vícerozměrných tabulek; tvoří tuto knihovnu.
Hlavní rysy knihovny Pandas
Je vysoce efektivní pro svou dobrou funkčnost analýzy dat a vysokou flexibilitu.
Matplotlib
2D grafická Python knihovna Matplotlib může snadno zpracovávat data z mnoha zdrojů. Vizualizace, které vytváří, jsou statické, animované a interaktivní, které si uživatel může přiblížit, čímž je efektivní pro vizualizace a vytváření grafů. Umožňuje také přizpůsobení rozvržení a vizuálního stylu.
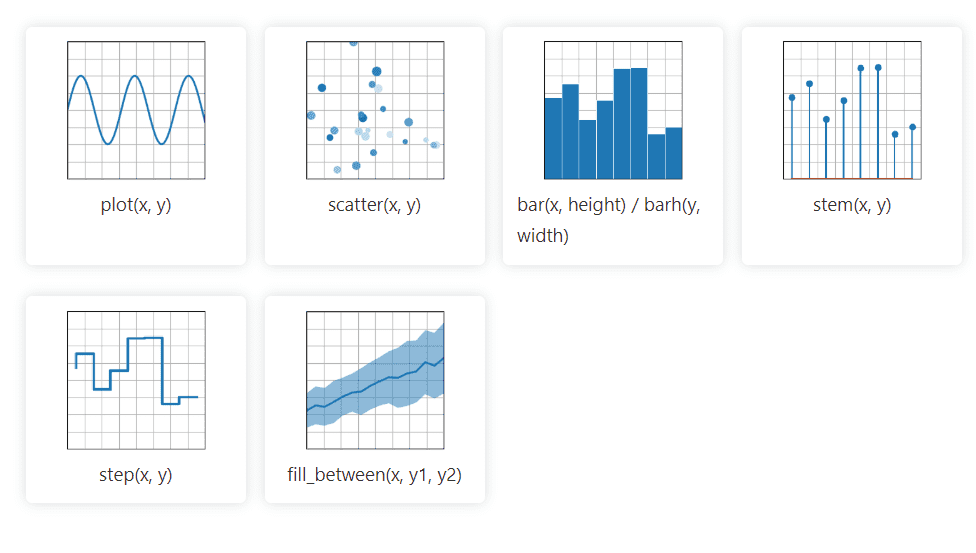
Jeho dokumentace je open source a nabízí rozsáhlou sbírku nástrojů potřebných pro implementaci.
Matplotlib importuje pomocné třídy pro implementaci roku, měsíce, dne a týdne, což usnadňuje manipulaci s daty časových řad.
Scikit-učte se
Pokud uvažujete o knihovně, která vám pomůže pracovat s komplexními daty, Scikit-learn by měla být vaší ideální knihovnou. Odborníci na strojové učení široce využívají Scikit-learn. Knihovna je spojena s dalšími knihovnami jako NumPy, SciPy a matplotlib. Nabízí algoritmy učení pod dohledem i bez dozoru, které lze použít pro produkční aplikace.

Vlastnosti knihovny Scikit-learn Python
Knihovna Scikit-learn je účinná při extrakci funkcí z textových a obrazových datových sad. Navíc je možné zkontrolovat přesnost kontrolovaných modelů na neviditelných datech. Jeho četné dostupné algoritmy umožňují dolování dat a další úlohy strojového učení.
SciPy
SciPy (Scientific Python Code) je knihovna pro strojové učení, která poskytuje moduly aplikované na matematické funkce a algoritmy, které jsou široce použitelné. Jeho algoritmy řeší algebraické rovnice, interpolaci, optimalizaci, statistiku a integraci.
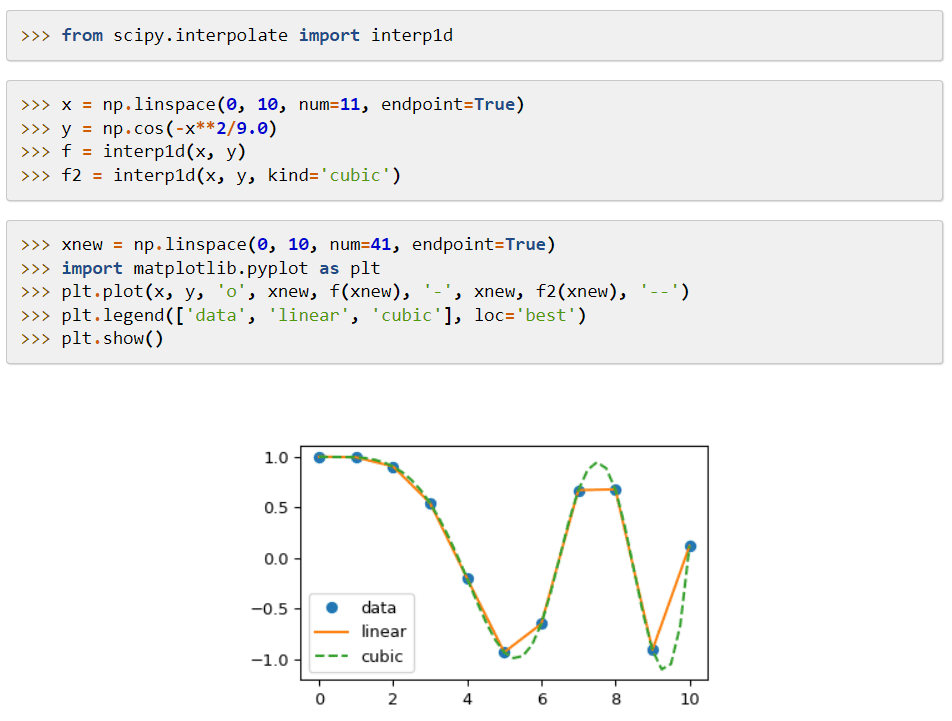
Jeho hlavním rysem je jeho rozšíření na NumPy, které přidává nástroje pro řešení matematických funkcí a poskytuje datové struktury, jako jsou řídké matice.
SciPy používá k manipulaci a vizualizaci dat příkazy a třídy na vysoké úrovni. Jeho systémy pro zpracování dat a prototypové systémy z něj dělají ještě efektivnější nástroj.
Navíc syntaxe SciPy na vysoké úrovni usnadňuje použití programátorům na jakékoli úrovni zkušeností.
Jedinou nevýhodou SciPy je jeho výhradní zaměření na numerické objekty a algoritmy; proto nemůže nabídnout žádnou funkci vykreslování.
PyTorch
Tato rozmanitá knihovna strojového učení efektivně implementuje výpočty tenzorů s akcelerací GPU, vytváří dynamické výpočetní grafy a automatické výpočty přechodů. Knihovna Torch, open-source knihovna strojového učení vyvinutá na C, vytváří knihovnu PyTorch.

Mezi klíčové vlastnosti patří:
PyTorch můžete použít při vývoji NLP aplikací.
Keras
Keras je open-source knihovna Pythonu pro strojové učení používaná k experimentování s hlubokými neuronovými sítěmi.
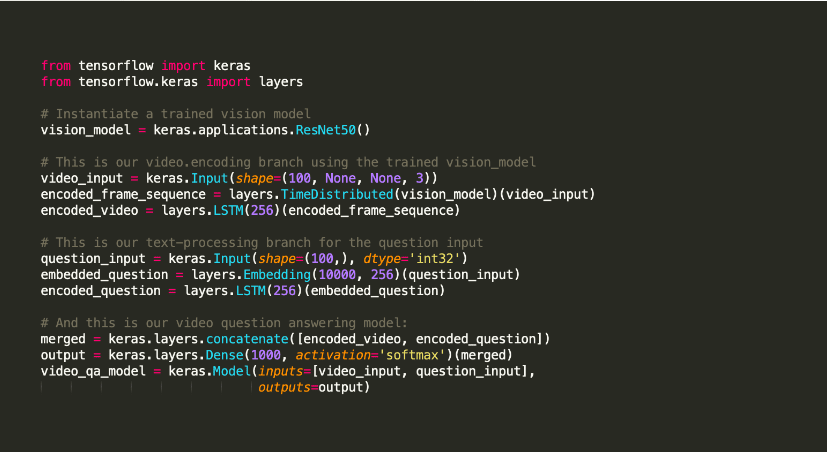
Je známý tím, že nabízí nástroje, které mimo jiné podporují úkoly, jako je kompilace modelů a vizualizace grafů. Pro svůj backend používá Tensorflow. Případně můžete v backendu použít Theano nebo neuronové sítě jako CNTK. Tato backendová infrastruktura jí pomáhá vytvářet výpočtové grafy používané k implementaci operací.
Klíčové vlastnosti knihovny
Aplikace Keras zahrnují stavební bloky neuronové sítě, jako jsou vrstvy a cíle, mimo jiné nástroje, které usnadňují práci s obrázky a textovými daty.
Seaborn
Seaborn je dalším cenným nástrojem ve vizualizaci statistických dat.
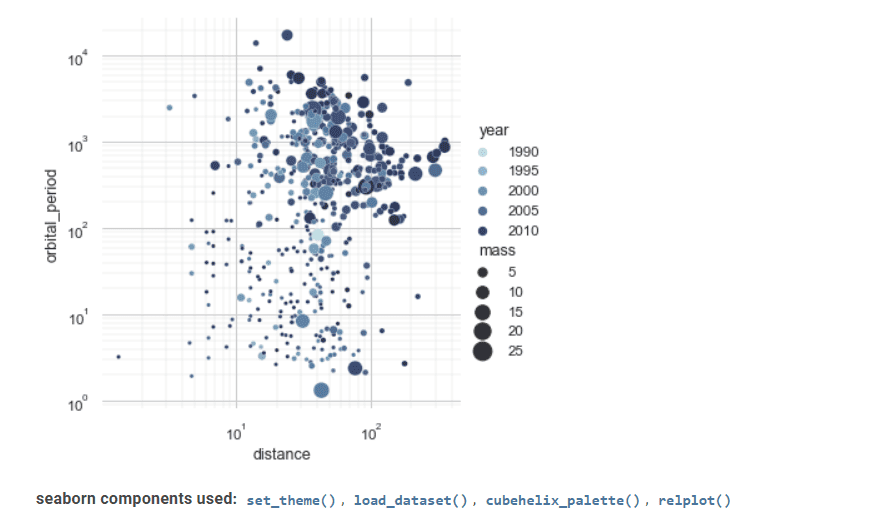
Jeho pokročilé rozhraní může implementovat atraktivní a informativní statistické grafické výkresy.
Zápletka
Plotly je 3D webový vizualizační nástroj postavený na knihovně Plotly JS. Má širokou podporu pro různé typy grafů, jako jsou spojnicové grafy, bodové grafy a rámečkové grafy.
Jeho aplikace zahrnuje vytváření webových vizualizací dat v noteboocích Jupyter.
Plotly je vhodný pro vizualizaci, protože může pomocí nástroje hover upozornit na odlehlé hodnoty nebo abnormality v grafu. Grafy si také můžete přizpůsobit podle svých preferencí.
Na druhou stranu Plotlyho je jeho dokumentace zastaralá; proto může být jeho použití jako vodítka pro uživatele obtížné. Navíc má mnoho nástrojů, které by se měl uživatel naučit. Může být náročné sledovat všechny z nich.
Vlastnosti knihovny Plotly Python
SimpleITK
SimpleITK je knihovna pro analýzu obrazu, která nabízí rozhraní k Insight Toolkit (ITK). Je založen na C++ a je open-source.
Vlastnosti knihovny SimpleITK
Jeho zjednodušené rozhraní je dostupné v různých programovacích jazycích jako R, C#, C++, Java a Python.
Statsmodel
Statsmodel odhaduje statistické modely, implementuje statistické testy a zkoumá statistická data pomocí tříd a funkcí.
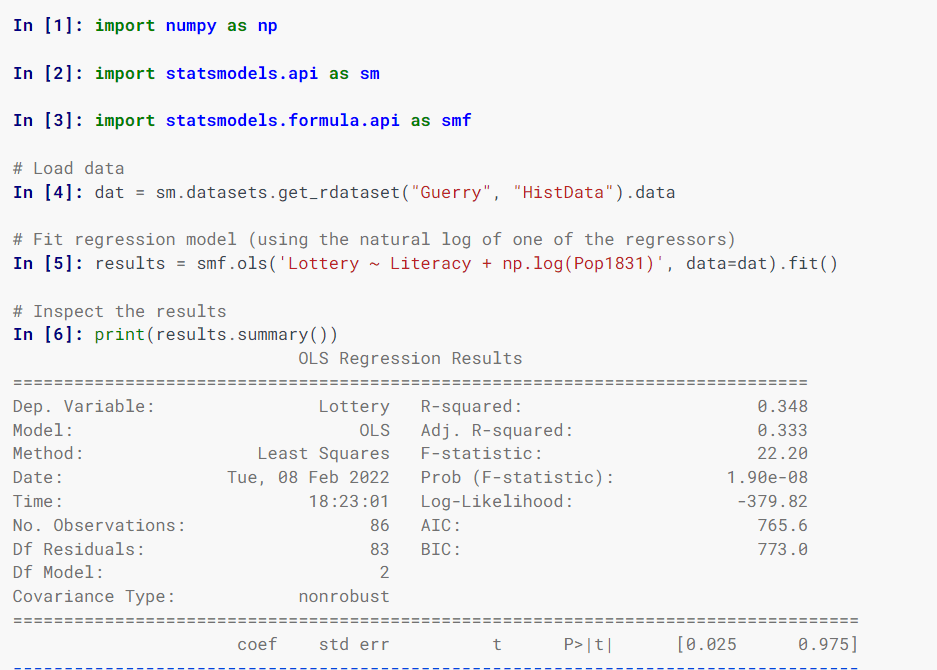
Specifikace modelů používá vzorce ve stylu R, pole NumPy a datové rámce Pandas.
špinavý
Tento balíček s otevřeným zdrojovým kódem je preferovaným nástrojem pro získávání (seškrabávání) a procházení dat z webových stránek. Je asynchronní, a tedy relativně rychlý. Scrapy má architekturu a funkce, díky kterým je efektivní.
Na straně záporů se jeho instalace pro různé operační systémy liší. Navíc jej nemůžete použít na webech postavených na JS. Také může pracovat pouze s Pythonem 2.7 nebo novějšími verzemi.
Odborníci Data Science jej aplikují při dolování dat a automatizovaném testování.
Funkce
Polštář
Pillow je zobrazovací knihovna Pythonu, která manipuluje a zpracovává obrázky.
Přidává k funkcím zpracování obrázků Python interpret, podporuje různé formáty souborů a nabízí vynikající interní reprezentaci.
K datům uloženým v základních souborových formátech lze snadno přistupovat díky Pillow.
Zabalení 💃
To shrnuje náš průzkum některých nejlepších knihoven Pythonu pro datové vědce a odborníky na strojové učení.
Jak ukazuje tento článek, Python má užitečnější balíčky strojového učení a datové vědy. Python má další knihovny, které můžete použít v jiných oblastech.
Možná budete chtít vědět o některých z nejlepších datových vědeckých notebooků.
Šťastné učení!