Použijte nástroje Chaos Engineering Tools ke kontrole spolehlivosti výroby
Pojďme prozkoumat, jak můžete zajistit spolehlivost vašeho provozu díky nástrojům pro chaos engineering.
Chaos engineering je metoda, která spočívá v experimentování s vaším systémem nebo aplikací s cílem odhalit jejich slabá místa a limity. Jedná se o situace, které jste při vývoji možná nepředpokládali. Záměrným vyvoláváním chyb v systému můžete odhalit jeho zranitelnosti, provést nezbytné opravy a posílit jeho odolnost.
Mnoho renomovaných firem, jako Netflix, LinkedIn a Facebook, využívá chaos engineering k lepšímu porozumění své mikroservisní architektury a distribuovaným systémům. Tato praxe pomáhá identifikovat problémy dříve, než se k nim dostanou uživatelské stížnosti, což umožňuje včasná nápravná opatření. Díky tomu mohou tyto organizace obsluhovat miliony uživatelů, zvýšit svou produktivitu a ušetřit značné finanční prostředky. 🤑
Přínosy Chaos Engineering:
- Prevence finančních ztrát díky odhalení kritických problémů
- Snížení četnosti selhání systému nebo aplikace
- Zlepšení uživatelské zkušenosti díky plynulému provozu a vysoké dostupnosti služeb
- Získání hlubších znalostí o systému a budování důvěry v jeho spolehlivost
Jak velká je vaše jistota ohledně spolehlivosti vašeho produkčního prostředí? Je váš systém skutečně odolný vůči nečekaným událostem?
Pojďme se na to podívat s pomocí populárních nástrojů pro chaos testování.
Chaos Mesh
Chaos Mesh je nástroj pro správu chaosu, který uměle vytváří chyby v různých vrstvách systému Kubernetes. Zahrnuje moduly, síť, systémové I/O a jádro. Dokáže automaticky ukončovat Kubernetes pody a simulovat latence. Dokáže narušovat komunikaci mezi pody a simulovat chyby čtení/zápisu. Umožňuje naplánovat experimenty s chaosem a definovat jejich rozsah. Tyto experimenty se specifikují pomocí YAML souborů.
Chaos Mesh nabízí panel pro analýzu experimentů. Funguje na Kubernetes a je kompatibilní s většinou cloudových platforem. Jedná se o open-source projekt, který byl nedávno přijat do sandboxu CNCF. Díky principům chaos engineeringu můžete Chaos Mesh začlenit do vašeho DevOps workflow a vytvářet odolné aplikace.
Charakteristiky Chaos Engineering:
- Snadné nasazení na Kubernetes clusterech bez nutnosti úprav v logice deploymentu
- Pro nasazení nejsou vyžadovány žádné specifické závislosti
- Definuje objekty chaosu pomocí CustomResourceDefinitions (CRD)
- Poskytuje ovládací panel pro monitorování všech experimentů
Chaos ToolKit je open-source a jednoduchý nástroj pro automatizaci experimentů chaos engineeringu.
Chaos ToolKit se integruje do systému pomocí sady ovladačů nebo pluginů, které podporují AWS, Google Cloud, Slack, Prometheus a další.
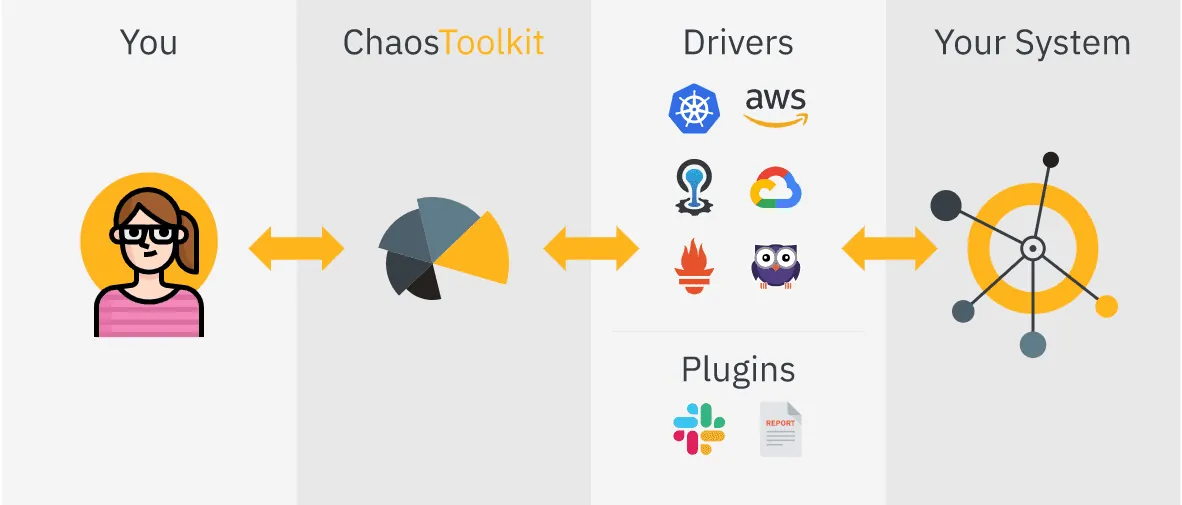
Vlastnosti Chaos ToolKit:
- Poskytuje deklarativní Open API pro vytváření experimentů chaosu nezávislých na dodavateli nebo technologii
- Lze snadno integrovat do CICD pipeline pro automatizaci
- Nabízí komerční a podnikovou podporu prostřednictvím ChaosIQ
ChaosKube
Jak už napovídá název, je určen pro Kubernetes.
Chaoskube je open-source nástroj pro chaos, který pravidelně ukončuje náhodné pody v Kubernetes clusteru. Pomáhá vám pochopit, jak bude systém reagovat v případě selhání podu. Ve výchozím nastavení ukončuje pody v libovolném namespace každých 10 minut. Můžete filtrovat cílové pody pomocí namespace, štítků, anotací atd. Snadno se instaluje.

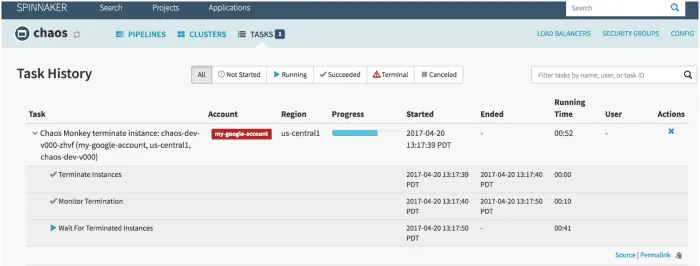
Chaos Monkey
Chaos Monkey je nástroj pro ověřování odolnosti cloudových systémů tím, že do nich záměrně vnáší poruchy, čímž se testuje jejich reakce. Vytvořil ho Netflix pro testování odolnosti a obnovitelnosti AWS infrastruktury. Název Chaos Monkey (Chaosová opice) odkazuje na destrukci, kterou vytváří při testování poruch, podobně jako divoká opice.
Chaos Monkey stál u zrodu nové inženýrské praxe chaos engineering. Je založen na myšlence, že je lepší opakovaně prožívat menší selhání, než být konfrontován s náhlým velkým výpadkem.
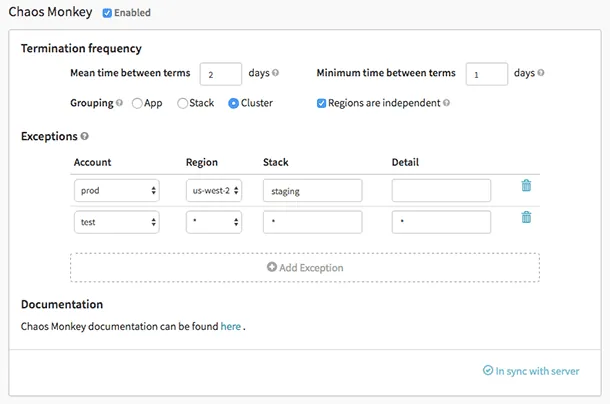
Funkce Chaos Monkey:
- Pomáhá vám připravit se na neočekávaná selhání instancí
- Podporuje redundanci pro ochranu před nečekanými poruchami
- Využívá Spinnaker pro zajištění kompatibility mezi různými cloudy
- Poskytuje konfigurovatelný plán pro simulaci poruch
- Je integrován s govendor pro přidávání nových závislostí
Simmy
Simmy je nástroj pro vkládání chyb, který je kompatibilní s projektem Polly pro .NET. Umožňuje vytvářet politiky vkládání chaosu prostřednictvím Polly, kde se spouští váš kód. Nabízí různé politiky, jako je například politika výjimek pro vkládání výjimek do systému, nebo politika chování pro zavádění nového chování. Tyto politiky jsou navrženy tak, aby zaváděly chování náhodně.
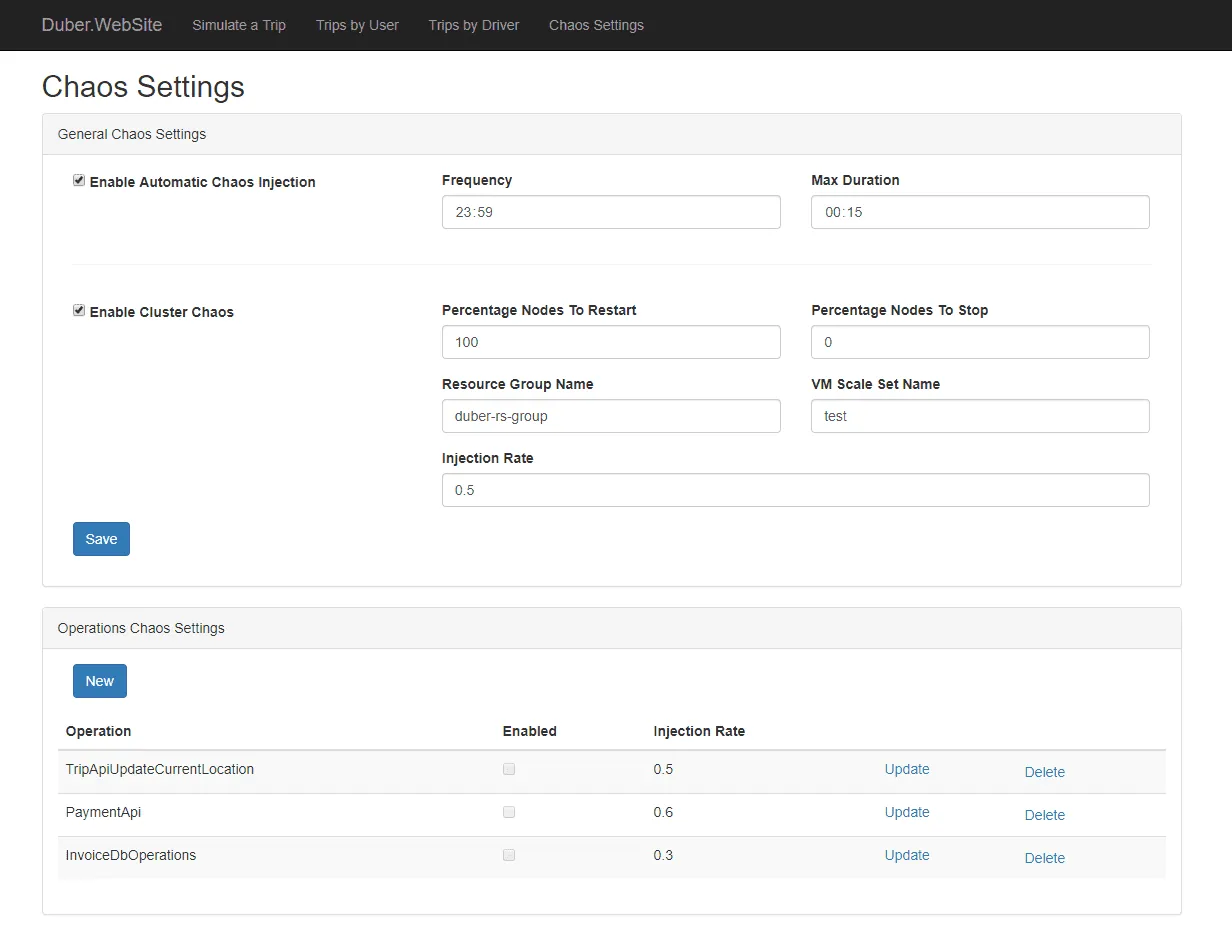
Vlastnosti Simmy:
- Poskytuje "opičí" nebo chaosové politiky pro vnášení chaosu
- Umožňuje jednoduché testování selhání závislostí
- Podporuje rychlý návrat k funkčnímu stavu a kontroluje oblast "výbuchu"
- Je připraven pro použití v produkčním prostředí
- Umožňuje definovat poruchy na základě vnějších faktorů
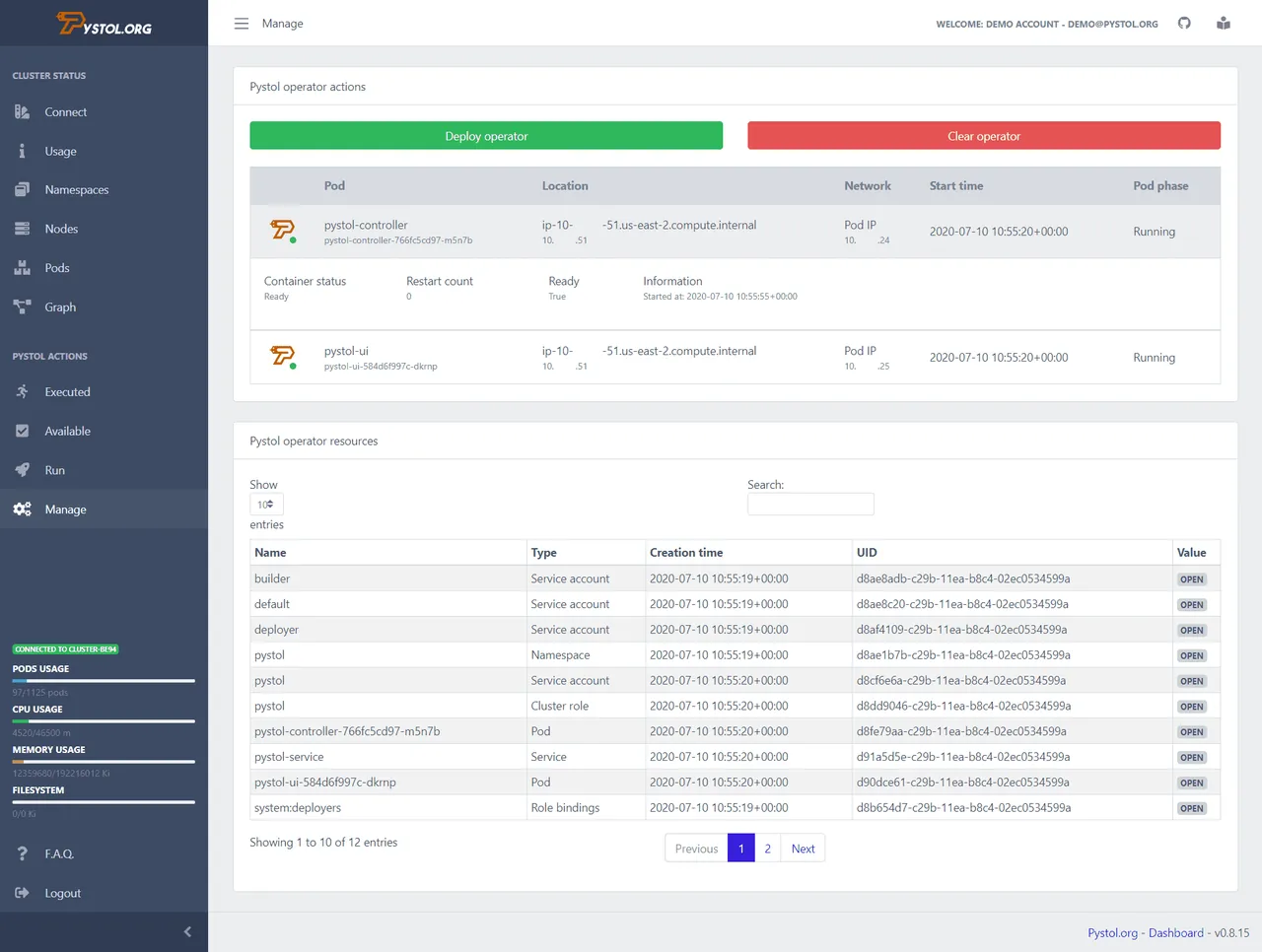
Pystol
Pystol je nástroj pro injektování chyb v cloud-nativních prostředích. Sleduje dění v ETCD pomocí Kubernetes operátorů. Při akci vložení chyby operátoři vytvoří pody a spustí kolekce Ansible. Vývojáři tak nemusí psát vlastní akce.
Pystol nabízí předdefinované akce pro testování systému. V případě potřeby může vývojář vytvořit nové akce pomocí GoLang a Pythonu.
Poskytuje panel pro nepřetržitou integraci, který nabízí souhrnný přehled o všech operacích. Pystol lze spustit lokálně nebo v kontejneru pomocí Docker image. Nabízí webové uživatelské rozhraní a rozhraní CLI. Webové uživatelské rozhraní je doporučeno.
Muxy
Muxy je proxy server, který testuje odolnost vašeho systému vůči selháním v distribuovaném prostředí. Dokáže simulovat poruchy na úrovni přenosu (vrstva 4), TCP relace (vrstva 5) a HTTP protokolu (vrstva 7).
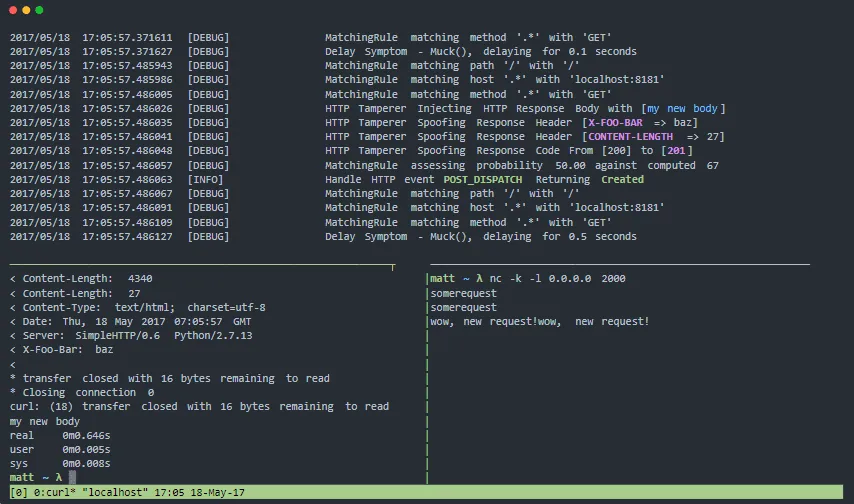
Funkce Muxy:
- Modulární architektura a snadné rozšiřování
- Oficiální Docker kontejner
- Jednoduchá instalace bez závislostí
- Vhodné pro průběžné testování odolnosti
- Simuluje problémy s připojením k síti pro distribuované systémy a mobilní zařízení
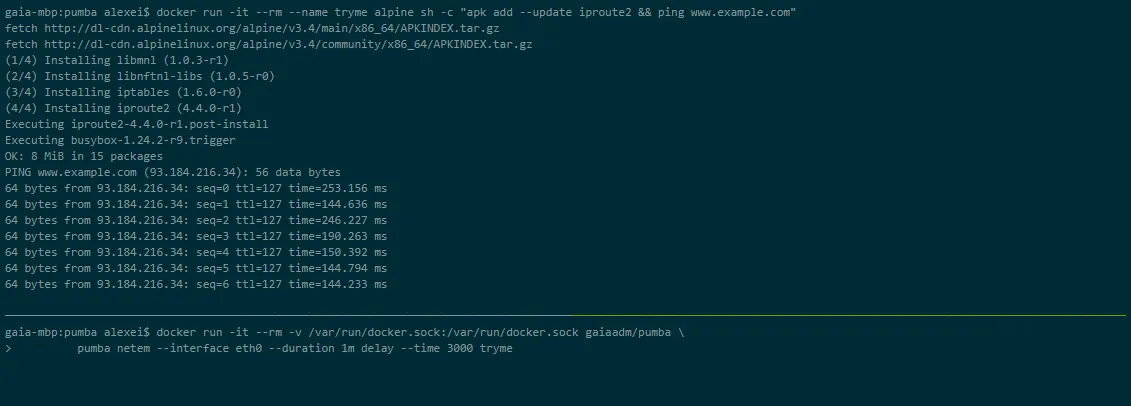
Pumba
Pumba je nástroj příkazového řádku pro chaos testování Docker kontejnerů. S Pumbou můžete záměrně "shazovat" kontejnery aplikace a sledovat reakci systému. Umožňuje také zátěžové testování prostředků kontejneru, jako je CPU, paměť, systém souborů, I/O.
Pumbu lze spustit i v Kubernetes clusteru. Pro nasazení Pumpy na Kubernetes uzly se používají DaemonSets. Pro spuštění více Pumba příkazů v jednom DaemonSetu lze použít více Pumba kontejnerů.
ChaosBlade
ChaosBlade je open-source nástroj od Alibaby pro vkládání experimentů do systémů. Testuje všechny selhání, kterým Alibaba čelila za posledních deset let, a aplikuje best practices pro jejich prevenci. Drží se principů chaos engineeringu pro testování odolnosti distribuovaných systémů.
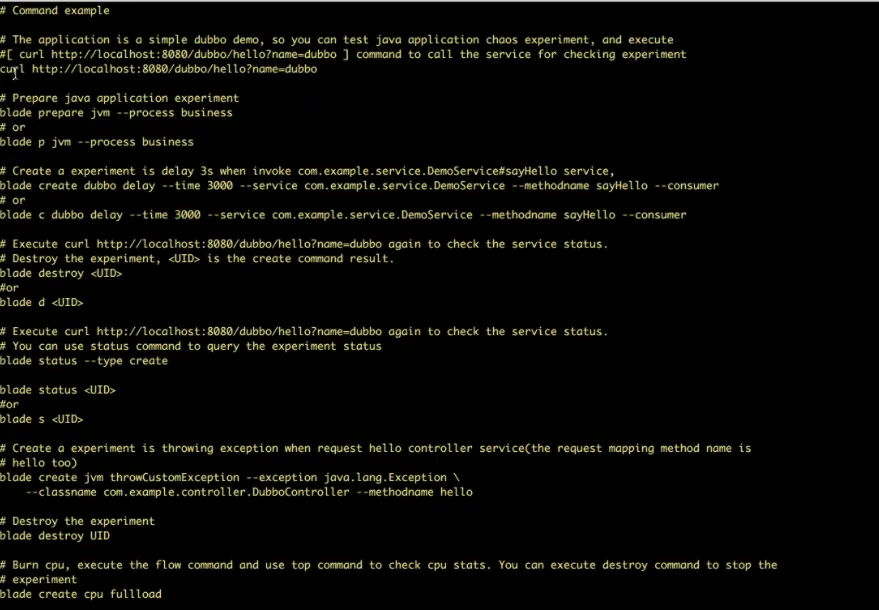
Vlastnosti ChaosBlade:
- Nabízí experimentální scénáře pro různé zdroje, jako je CPU, síť, paměť, disk atd.
- Nabízí experimentální scénáře pro uzly, sítě a pody v Kubernetes
- Disponuje intuitivními CLI příkazy pro provádění experimentů
Litmus
Litmus dodržuje principy cloudového chaos engineeringu. Jeho cílem je poskytnout kompletní framework pro odhalování slabin v Kubernetes systémech a aplikacích na něm běžících.
Využívá chaos Operator a CRD (CustomResourceDefinitions) pro plug-and-play funkcionalitu. Spočívá v vložení chaosové logiky do Docker image, integraci do Litmus frameworku a orchestraci pomocí CRD.

Vlastnosti Litmus:
- Pomáhá SRE a vývojářům odhalovat slabá místa v Kubernetes systémech
- Nabízí obecné, předpřipravené experimenty
- Poskytuje Chaos API pro řízení chaos workflow
- Litmus SDK podporuje Go, Python a Ansible pro tvorbu vlastních experimentů
Gremlin
Gremlin pomáhá inženýrům vytvářet odolnější software. Poskytuje platformu pro bezpečné, zabezpečené a jednoduché provádění chaos engineering experimentů.

Umožňuje cíleně vkládat selhání do hostitelů nebo kontejnerů bez ohledu na to, kde se nacházejí (veřejný cloud nebo vlastní datacentrum).
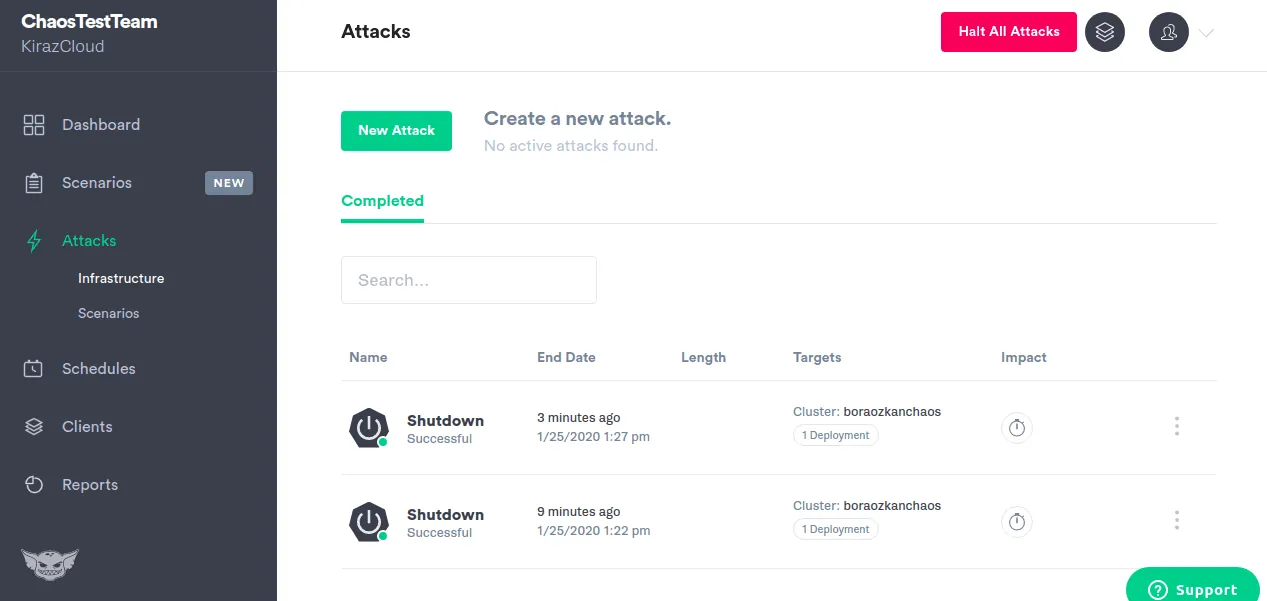
Funkce Gremlin:
- Instaluje lehkého agenta na hostitele nebo kontejnery pro vkládání selhání
- Poskytuje více než 10 různých režimů útoku na infrastrukturu
- "State gremlins" umožňují manipulovat se systémovým časem, vypínat nebo restartovat hostitele a ukončovat procesy
- "Network gremlins" dokážou vnášet latenci, ztráty paketů nebo snižovat propustnost sítě
- Útoky na knihovnu Gremlin Alfi lze konfigurovat, spouštět a zastavovat přes webovou aplikaci, API nebo CLI
- Umožňuje přesně zacílit "oblast výbuchu"
- Umožňuje zastavit všechny útoky a vrátit systém do ustáleného stavu
Steadybit
Steadybit se snaží proaktivně snižovat prostoje a poskytuje přehled o problémech v systému. Můžete ho spustit lokálně v infrastruktuře nebo v cloudu jako službu (SaaS).
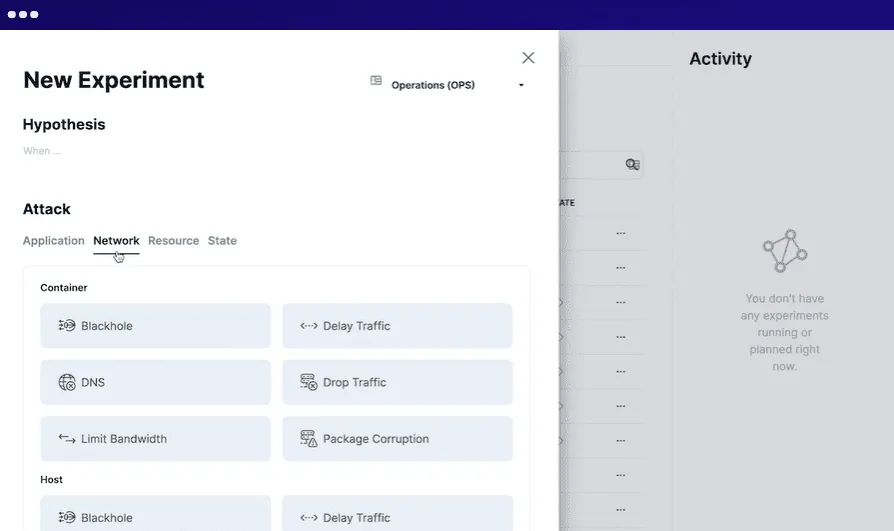
Při použití Steadybit definujete situaci, simulujete experimenty, provádíte simulace v produkčním prostředí a automatizujete proces. Spouští inteligentní agenty ve vašem systému pro odhalování potenciálních problémů a slabých míst. Snadno se integruje s různými systémy.
Závěr
Nebojte se a odvážně otestujte svůj provoz s pomocí nástrojů pro chaos engineering. Tyto nástroje vám pomohou odhalit dosud neznámá slabá místa v systému a zvýšit jeho odolnost.
