Průvodce, jak zabránit narušení sítě
Data představují klíčový prvek pro podniky a různé organizace, avšak jejich hodnota se odvíjí od správné struktury a efektivní správy.
Statistiky ukazují, že 95 % společností v současnosti vnímá správu a strukturování nestrukturovaných dat jako komplikaci.
Zde se uplatňuje dolování dat, proces, který se zaměřuje na odhalování, analýzu a získávání významných vzorců a hodnotných informací z rozsáhlých souborů neuspořádaných dat.
Firmy využívají specializovaný software k identifikaci modelů chování ve velkých objemech dat, což jim umožňuje lépe poznat své klienty a cílové skupiny. Tímto způsobem mohou vytvářet obchodní a marketingové strategie s cílem navýšit prodeje a omezit výdaje.
Kromě uvedených výhod je detekce podvodů a neobvyklých jevů považována za jednu z nejzásadnějších aplikací dolování dat.
Tento text objasňuje koncept detekce anomálií a zkoumá, jak může přispět k ochraně před úniky dat a narušeními sítě, čímž zajišťuje bezpečnost dat.
Co znamená detekce anomálií a jaké jsou její druhy?
Dolování dat primárně hledá vzájemné vazby, korelace a trendy. Nicméně, je to také velmi účinná metoda, jak identifikovat anomálie nebo odlehlé datové body v rámci sítě.
Anomálie v kontextu dolování dat představují datové body, které se odlišují od zbytku datové sady a vybočují z obvyklého chování, které je pro danou sadu charakteristické.
Anomálie lze rozdělit do různých kategorií:
- Změny v událostech: Tyto odkazují na náhlé nebo postupné odchylky od běžného chování.
- Odlehlé hodnoty: Jedná se o malé, nepravidelně se objevující anomální vzorce během sběru dat. Mohou být dále klasifikovány jako globální, kontextové a kolektivní.
- Drift: Představuje pozvolnou a dlouhodobou změnu v datové sadě, která není směřována jedním konkrétním směrem.
Detekce anomálií je tedy technika zpracování dat, která je velmi užitečná pro odhalování podezřelých transakcí, analýzu případových studií s vysokou mírou nerovnováhy a detekci nemocí. To vše slouží k tvorbě spolehlivých modelů datové vědy.
Například, společnost může analyzovat svůj peněžní tok a hledat neobvyklé nebo opakující se transakce na neznámý bankovní účet, aby odhalila podvody a případně zahájila další vyšetřování.
Jaké výhody přináší detekce anomálií?
Detekce anomálního chování uživatelů napomáhá posílit bezpečnostní systémy a zvyšuje jejich přesnost.
Provádí analýzu a interpretaci různých informací, které poskytují bezpečnostní systémy. Díky tomu lze identifikovat potenciální hrozby a rizika v rámci sítě.
Následují výhody, které detekce anomálií nabízí společnostem:
- Identifikace kybernetických bezpečnostních hrozeb a úniků dat v reálném čase díky algoritmům umělé inteligence, které nepřetržitě monitorují data a hledají neobvyklé chování.
- Zrychlení a zjednodušení sledování neobvyklých aktivit a vzorců v porovnání s manuální detekcí anomálií, což vede k úspoře času a snížení náročnosti při řešení hrozeb.
- Omezení provozních rizik díky včasné identifikaci provozních chyb, jako jsou například náhlé poklesy výkonu.
- Prevence rozsáhlých obchodních škod díky rychlé detekci anomálií. Bez systému detekce anomálií může společnostem trvat týdny či měsíce, než odhalí možné nebezpečí.
Detekce anomálií je tedy neocenitelným nástrojem pro podniky, které pracují s velkým množstvím zákaznických a obchodních dat. Pomáhá jim identifikovat příležitosti k rozvoji a odstraňovat bezpečnostní hrozby a provozní překážky.
Jaké techniky se využívají při detekci anomálií?
Detekce anomálií využívá různé postupy a algoritmy strojového učení (ML) pro sledování dat a identifikaci hrozeb.
Níže uvádíme hlavní techniky používané při detekci anomálií:
#1. Techniky strojového učení
Techniky strojového učení využívají algoritmy ML k analýze dat a detekci anomálií. Mezi různé typy algoritmů strojového učení pro detekci anomálií patří:
- Shlukovací algoritmy
- Klasifikační algoritmy
- Algoritmy hlubokého učení
Mezi běžně používané techniky ML pro detekci anomálií a hrozeb patří podpůrné vektorové stroje (SVM), shlukování k-means a automatické kodéry.
#2. Statistické techniky
Statistické techniky využívají statistické modely k odhalení neobvyklých vzorců v datech, jako jsou například neočekávané výkyvy ve výkonu určitého zařízení. Zaměřují se na hodnoty, které se vymykají očekávanému rozsahu.
Mezi běžné techniky pro detekci statistických anomálií patří testování hypotéz, IQR, Z-skóre, modifikované Z-skóre, odhad hustoty, boxplot, analýza extrémních hodnot a histogram.
#3. Techniky dolování dat

Techniky dolování dat využívají klasifikaci a shlukování k odhalení anomálií v datových sadách. Mezi běžné techniky dolování dat patří spektrální shlukování, shlukování založené na hustotě a analýza hlavních komponent.
Shlukovací algoritmy se používají k seskupování podobných datových bodů do shluků, přičemž hledají datové body a anomálie, které se od těchto shluků liší.
Na druhou stranu klasifikační algoritmy přiřazují datové body k předem definovaným třídám a odhalují datové body, které do těchto tříd nepatří.
#4. Techniky založené na pravidlech
Jak naznačuje název, techniky detekce anomálií založené na pravidlech používají soubor předem definovaných pravidel pro identifikaci anomálií v datech.
Tyto techniky se poměrně snadno nastavují a používají, ale mohou být málo flexibilní a nemusí být efektivní při adaptaci na měnící se chování a vzorce dat.
Například, lze snadno naprogramovat systém založený na pravidlech, aby označil transakce, které překračují určitou částku v dolarech, jako podezřelé.
#5. Techniky specifické pro danou oblast
Pro detekci anomálií v konkrétních datových systémech lze využít techniky specifické pro danou oblast. Tyto techniky mohou být velmi účinné při detekci anomálií ve specifických doménách, ale v jiných oblastech mimo specifikovanou doménu mohou být méně efektivní.
Například, pomocí technik specifických pro danou oblast lze navrhnout techniky určené speciálně pro odhalování anomálií ve finančních transakcích. Nicméně, nemusejí být účinné při hledání anomálií nebo poklesu výkonu strojů.
Proč je strojové učení důležité pro detekci anomálií?
Strojové učení hraje klíčovou roli v detekci anomálií a má velký význam.
V současné době většina společností a organizací, které potřebují detekovat odlehlé hodnoty, pracuje s obrovským množstvím dat, od textu, informací o zákaznících a transakcích až po multimediální soubory, jako jsou obrázky a videoobsah.
Ruční zpracování všech bankovních transakcí a dat generovaných každou sekundu, aby se získal smysluplný přehled, je prakticky nemožné. Navíc většina firem čelí obtížím při strukturování neuspořádaných dat a smysluplném uspořádání pro účely analýzy.
Právě zde hrají klíčovou roli nástroje a techniky, jako je strojové učení (ML). Pomáhají při sběru, čištění, strukturování, uspořádání, analýze a ukládání obrovských objemů neuspořádaných dat.
Techniky a algoritmy strojového učení dokážou zpracovávat velké datové soubory a nabízejí flexibilitu při používání a kombinování různých metod a algoritmů, aby bylo dosaženo co nejlepších výsledků.
Strojové učení rovněž přispívá ke zefektivnění procesů detekce anomálií pro reálné aplikace a šetří cenné zdroje.
Níže uvádíme další výhody a důležitost strojového učení v kontextu detekce anomálií:
- Umožňuje efektivní detekci anomálií automatizací procesu identifikace vzorů a anomálií bez nutnosti explicitního programování.
- Algoritmy strojového učení se snadno přizpůsobují měnícím se vzorcům datových sad, což zvyšuje jejich účinnost a odolnost.
- Jsou schopné zpracovávat velké a složité datové sady, což zaručuje efektivitu detekce anomálií i při komplikované struktuře dat.
- Zajišťují včasnou identifikaci a detekci anomálií okamžitě po jejich výskytu, čímž šetří čas a zdroje.
- Systémy detekce anomálií založené na strojovém učení dosahují vyšší úrovně přesnosti než tradiční metody.
Detekce anomálií ve spojení se strojovým učením tak umožňuje rychlejší a včasnější odhalování anomálií, čímž se předchází bezpečnostním hrozbám a nebezpečným narušením.
Jaké algoritmy strojového učení se využívají pro detekci anomálií?
Anomálie a odlehlé hodnoty v datech lze detekovat pomocí různých algoritmů dolování dat, které slouží ke klasifikaci, shlukování nebo učení asociačních pravidel.
Tyto algoritmy dolování dat se obvykle dělí do dvou kategorií – algoritmy učení s dohledem a bez dohledu.
Učení s dohledem
Učení s dohledem je běžný typ výukového algoritmu, který zahrnuje algoritmy, jako jsou podpůrné vektorové stroje, logistická a lineární regrese a klasifikace do více tříd. Tento typ algoritmu se trénuje na označených datech, což znamená, že trénovací datový soubor obsahuje jak normální vstupní data, tak odpovídající správný výstup nebo anomální příklady pro konstrukci prediktivního modelu.
Jeho cílem je tedy vytvářet předpovědi výstupu pro neviditelná a nová data na základě vzorů trénovacích datových sad. Aplikace algoritmů učení s dohledem zahrnují rozpoznávání obrazu a řeči, prediktivní modelování a zpracování přirozeného jazyka (NLP).
Učení bez dohledu
Učení bez dohledu se netrénuje na žádných označených datech. Místo toho odhaluje komplikované procesy a základní datové struktury, aniž by poskytoval vedení trénovacího algoritmu a namísto toho, aby dělal konkrétní předpovědi.
Aplikace algoritmů učení bez dohledu zahrnují detekci anomálií, odhad hustoty a kompresi dat.
Nyní se podívejme na některé oblíbené algoritmy detekce anomálií založené na strojovém učení.
Místní odlehlý faktor (LOF)
Local Outlier Factor neboli LOF je algoritmus detekce anomálií, který při rozhodování, zda je datový bod anomálií, zvažuje místní hustotu dat.
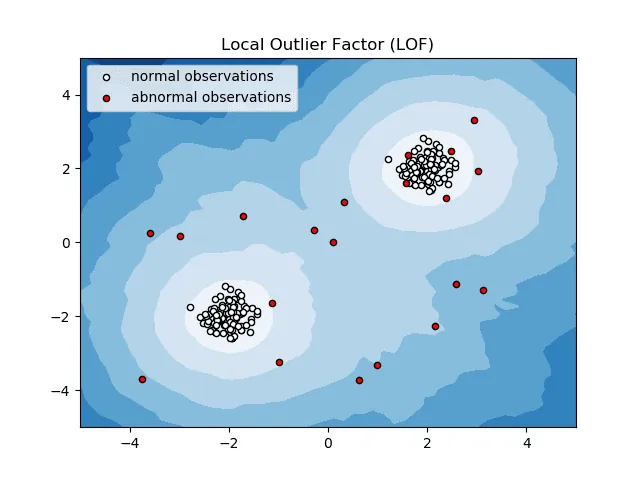
Zdroj: scikit-learn.org
Porovnává místní hustotu položky s místními hustotami jejích sousedů, aby analyzovala oblasti s podobnou hustotou a položky s srovnatelně nižší hustotou než jejich sousedé – což nejsou nic jiného než anomálie nebo odlehlé hodnoty.
Zjednodušeně řečeno, hustota obklopující odlehlou nebo anomální položku se liší od hustoty kolem jejích sousedů. Proto se tento algoritmus také nazývá algoritmus detekce odlehlých hodnot založený na hustotě.
K-Nearest Neighbor (K-NN)
K-NN je nejjednodušší klasifikační a kontrolovaný algoritmus detekce anomálií, který se snadno implementuje, ukládá všechny dostupné příklady a data a klasifikuje nové příklady na základě podobností v metrikách vzdálenosti.
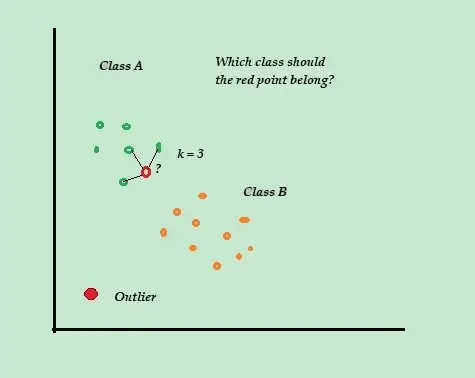
Zdroj: directiondatascience.com
Tento klasifikační algoritmus se také nazývá líný žák, protože ukládá pouze označená tréninková data – aniž by během tréninkového procesu dělal cokoli jiného.
Když přijde nový neoznačený trénovací datový bod, algoritmus se podívá na K-nejbližší nebo nejbližší trénovací datové body, aby je použil ke klasifikaci a určení třídy nového neoznačeného datového bodu.
Algoritmus K-NN používá k určení nejbližších datových bodů následující metody detekce:
- Euklidovská vzdálenost k měření vzdálenosti pro spojitá data.
- Hammingova vzdálenost pro měření blízkosti nebo „blízkosti“ dvou textových řetězců pro diskrétní data.
Zvažte například, že vaše tréninkové datové sady se skládají ze dvou označení třídy, A a B. Pokud přijde nový datový bod, algoritmus vypočítá vzdálenost mezi novým datovým bodem a každým z datových bodů v datové sadě a vybere body. které jsou co do počtu nejblíže novému datovému bodu.
Předpokládejme tedy, že K=3 a 2 ze 3 datových bodů jsou označeny jako A, pak je nový datový bod označen jako třída A.
Algoritmus K-NN tedy funguje nejlépe v dynamických prostředích s častými požadavky na aktualizaci dat.
Jedná se o oblíbený algoritmus detekce anomálií a dolování textu s aplikacemi ve financích a podnicích pro detekci podvodných transakcí a zvýšení míry odhalování podvodů.
Support Vector Machine (SVM)
Support vector machine je řízený algoritmus pro detekci anomálií založený na strojovém učení, který se většinou používá v regresních a klasifikačních problémech.
Používá multidimenzionální nadrovinu k rozdělení dat do dvou skupin (nové a normální). Nadrovina tedy funguje jako rozhodovací hranice, která odděluje normální pozorování dat a nová data.
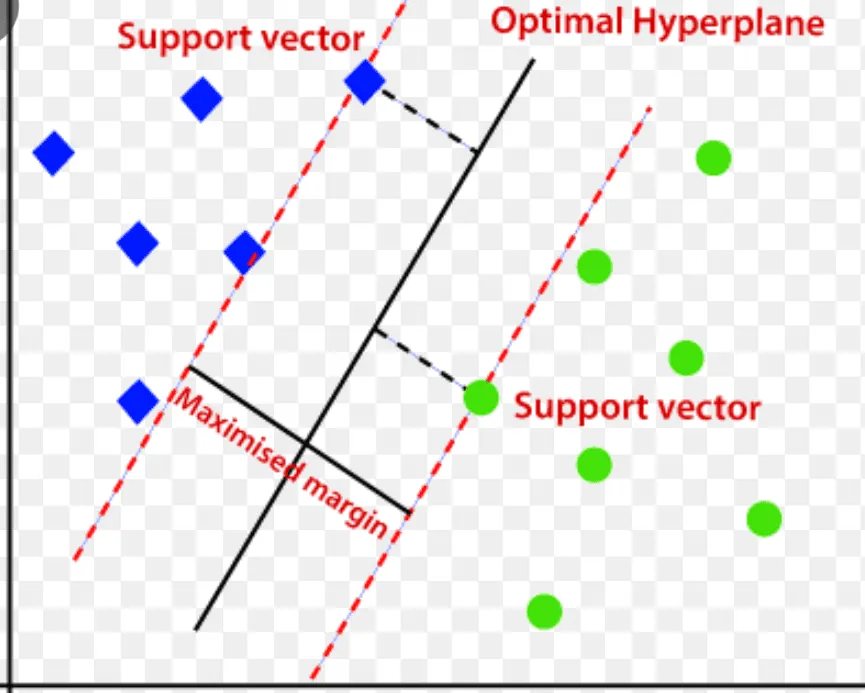
Zdroj: www.analyticsvidhya.com
Vzdálenost mezi těmito dvěma datovými body se označuje jako okraje.
Protože cílem je zvětšit vzdálenost mezi dvěma body, SVM určí nejlepší nebo optimální nadrovinu s maximální rezervou, aby byla vzdálenost mezi dvěma třídami co největší.
Pokud jde o detekci anomálií, SVM vypočítá okraj pozorování nového datového bodu z nadroviny, aby je klasifikoval.
Pokud rezerva překročí nastavený práh, klasifikuje nové pozorování jako anomálii. Současně, pokud je rozpětí menší než prahová hodnota, je sledování klasifikováno jako normální.
Algoritmy SVM jsou tedy vysoce účinné při zpracování vysoce dimenzionálních a komplexních souborů dat.
Izolační les
Isolation Forest je algoritmus detekce anomálií strojového učení bez dozoru založený na konceptu klasifikátoru náhodného lesa.
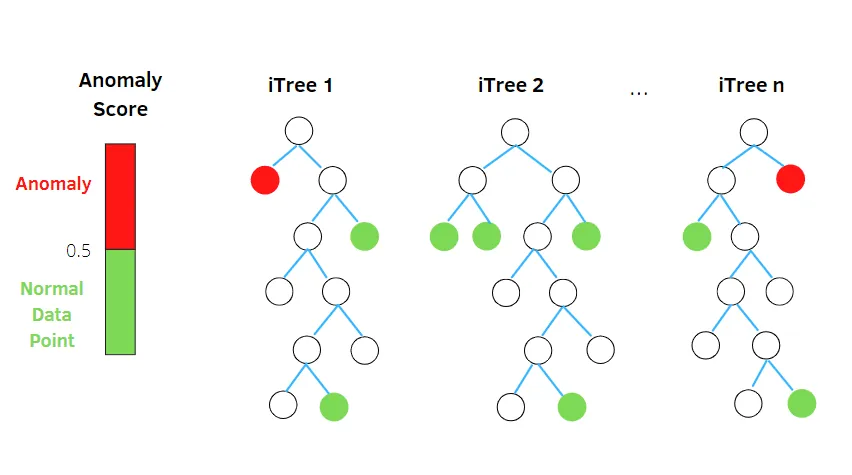
Zdroj: betterprogramming.pub
Tento algoritmus zpracovává náhodně podvzorkovaná data v sadě dat ve stromové struktuře na základě náhodných atributů. Konstruuje několik rozhodovacích stromů k izolaci pozorování. A považuje konkrétní pozorování za anomálii, pokud je izolováno na menším počtu stromů na základě míry kontaminace.
Zjednodušeně řečeno, algoritmus izolačního lesa rozděluje datové body do různých rozhodovacích stromů – zajišťuje, že každé pozorování bude izolované od jiného.
Anomálie obvykle leží mimo shluk datových bodů, což usnadňuje identifikaci anomálií ve srovnání s normálními datovými body.
Algoritmy izolačních lesů mohou snadno pracovat s kategorickými a numerickými daty. V důsledku toho se rychleji trénují a jsou vysoce účinné při odhalování anomálií ve velkých rozměrech a velkých souborech dat.
Rozsah interkvartilní
Mezikvartilní rozsah nebo IQR se používá k měření statistické variability nebo statistické disperze k nalezení anomálních bodů v souborech dat jejich rozdělením do kvartilů.
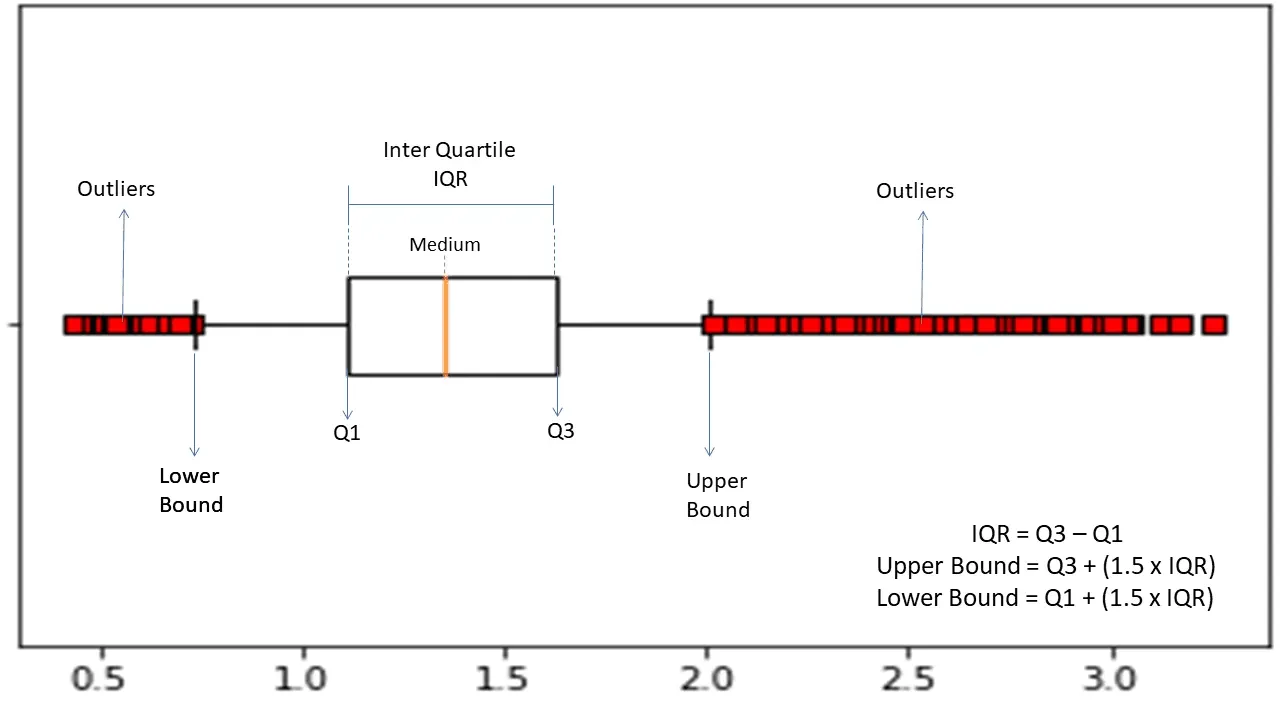
Zdroj: morioh.com
Algoritmus seřadí data ve vzestupném pořadí a rozdělí sadu na čtyři stejné části. Hodnoty oddělující tyto části jsou Q1, Q2 a Q3 – první, druhý a třetí kvartil.
Zde je percentilové rozložení těchto kvartilů:
- Q1 znamená 25. percentil dat.
- Q2 znamená 50. percentil dat.
- Q3 znamená 75. percentil dat.
IQR je rozdíl mezi třetím (75.) a prvním (25.) percentilovým souborem dat, který představuje 50 % dat.
Použití IQR pro detekci anomálií vyžaduje, abyste vypočítali IQR vaší datové sady a definovali spodní a horní hranici dat, abyste našli anomálie.
- Dolní hranice: Q1 – 1,5 * IQR
- Horní hranice: Q3 + 1,5 * IQR
Pozorování spadající mimo tyto hranice se obvykle považují za anomálie.
Algoritmus IQR je účinný pro datové sady s nerovnoměrně distribuovanými daty a tam, kde distribuce není dobře pochopena.
Závěrečná slova
Zdá se, že se rizika kybernetické bezpečnosti a narušení dat v nadcházejících letech neomezí – a očekává se, že toto rizikové odvětví bude v roce 2023 dále růst a samotné kybernetické útoky IoT se do roku 2025 zdvojnásobí.
Navíc kybernetické zločiny budou do roku 2025 stát globální společnosti a organizace odhadem 10,3 bilionu dolarů ročně.
To je důvod, proč je dnes potřeba technik detekce anomálií stále běžnější a nezbytnější pro detekci podvodů a předcházení narušení sítě.
Tento článek vám pomůže pochopit, co jsou anomálie při dolování dat, různé typy anomálií a způsoby, jak zabránit narušení sítě pomocí technik detekce anomálií založených na ML.
Dále můžete prozkoumat vše o matici zmatků ve strojovém učení.
