Průvodce nastavením a spuštěním krok za krokem
V současných informačních systémech vznikají každým dnem ohromná množství datových záznamů. Zahrnují například vaše finanční operace, zadané objednávky nebo údaje z automobilových senzorů. Pokud je potřeba tyto datové proudy zpracovávat v reálném čase a spolehlivě přesouvat záznamy mezi různými firemními systémy, je Apache Kafka ideálním řešením.
Apache Kafka představuje open-source platformu pro streamování dat, která zvládne zpracovat více než milion záznamů za sekundu. Kromě této vysoké propustnosti nabízí Apache Kafka vynikající škálovatelnost, dostupnost, nízkou latenci a trvalé úložiště dat.
Společnosti jako LinkedIn, Uber a Netflix se spoléhají na Apache Kafka pro zpracování a streamování dat v reálném čase. Nejjednodušší způsob, jak se seznámit s Apache Kafka, je spustit jej na lokálním počítači. Získáte tak praktický přehled o fungování serveru Apache Kafka a budete moci vytvářet a konzumovat zprávy.
Díky praktickým zkušenostem s provozováním serveru, tvorbou témat a psaním kódu v jazyce Java pomocí klienta Kafka budete připraveni využít Apache Kafka k naplnění vašich potřeb v oblasti datových toků.
Jak stáhnout Apache Kafka na lokální počítač
Nejnovější verzi Apache Kafka lze stáhnout z oficiální webové stránky. Stažený soubor bude komprimován do formátu .tgz. Po stažení bude potřeba jej extrahovat.
Uživatelé Linuxu mohou otevřít terminál a přejít do složky, kam byl komprimovaný soubor uložen. Následně je třeba spustit tento příkaz:
tar -xzvf kafka_2.13-3.5.0.tgz
Po provedení příkazu vznikne nová složka s názvem kafka_2.13-3.5.0. Pro vstup do této složky použijte příkaz:
cd kafka_2.13-3.5.0
Nyní lze vypsat obsah složky příkazem ls.
Uživatelé Windows mohou postupovat obdobně. Pokud není k dispozici příkaz tar, lze pro rozbalení archivu použít nástroj třetí strany, jako je například WinZip.
Jak spustit Apache Kafka na lokálním počítači
Po stažení a rozbalení Apache Kafka je čas jej spustit. Nejsou vyžadovány žádné instalátory. Použití je možné ihned prostřednictvím příkazové řádky nebo terminálu.
Před spuštěním Apache Kafka je nutné mít na systému nainstalovanou Java 8+. Apache Kafka vyžaduje pro svůj běh instalaci Javy.
#1. Spuštění serveru Apache Zookeeper
Prvním krokem je spuštění serveru Apache Zookeeper. Je součástí staženého archivu. Jedná se o službu, která zajišťuje správu konfigurací a poskytuje synchronizaci pro další služby.
Po přechodu do složky s extrahovaným obsahem archivu spusťte tento příkaz:
Pro Linux:
bin/zookeeper-server-start.sh config/zookeeper.properties
Pro Windows:
bin/windows/zookeeper-server-start.bat config/zookeeper.properties
Soubor zookeeper.properties definuje konfiguraci pro spuštění serveru Apache Zookeeper. Konfigurovat lze například lokální složku pro uložení dat a port, na kterém bude server běžet.
#2. Spuštění serveru Apache Kafka
Nyní, když je spuštěn server Apache Zookeeper, je čas spustit i server Apache Kafka.
Otevřete nový terminál nebo příkazovou řádku a přejděte do složky s extrahovanými soubory. Server Apache Kafka spustíte následujícím příkazem:
Pro Linux:
bin/kafka-server-start.sh config/server.properties
Pro Windows:
bin/windows/kafka-server-start.bat config/server.properties
Server Apache Kafka je nyní spuštěn. Pokud je potřeba změnit výchozí konfiguraci, lze to provést úpravou souboru server.properties. Detailní informace o jednotlivých nastaveních jsou k dispozici v oficiální dokumentaci.
Jak používat Apache Kafka na lokálním počítači
Nyní, když máte servery Apache Zookeeper a Apache Kafka v provozu, je možné začít s vytvářením a konzumací zpráv. Podívejme se, jak vytvořit první téma, zprávu a jak s ní pracovat.
Jaké jsou kroky pro vytvoření tématu v Apache Kafka?
Než vytvoříte první téma, je důležité si vysvětlit, co téma vlastně je. V Apache Kafka je téma logickým úložištěm dat, které slouží ke streamování. Lze si jej představit jako kanál, kterým se data přesouvají z jedné komponenty do druhé.
Téma podporuje více producentů i více konzumentů – tedy více systémů může do tématu zapisovat a z něj číst. Na rozdíl od jiných systémů pro zasílání zpráv může být zpráva z tématu přijata více než jednou. Lze také nastavit dobu uchovávání zpráv.
Představte si například systém (producent), který generuje data o bankovních transakcích. Jiný systém (konzument) tato data zpracuje a zašle uživateli notifikaci. K tomu je zapotřebí téma.
Otevřete nový terminál nebo příkazovou řádku a přejděte do složky, kam byl archiv rozbalen. Následující příkaz vytvoří téma s názvem transactions:
Pro Linux:
bin/kafka-topics.sh --create --topic transactions --bootstrap-server localhost:9092
Pro Windows:
bin/windows/kafka-topics.bat --create --topic transactions --bootstrap-server localhost:9092
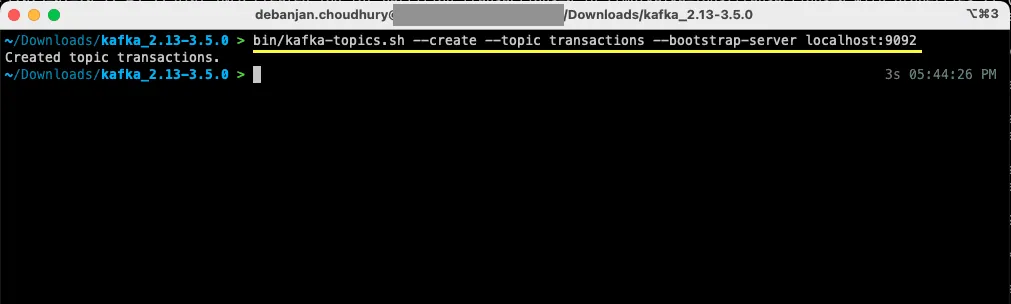
Nyní bylo vytvořeno první téma a je možné začít s vytvářením a přijímáním zpráv.
Jak vytvořit zprávu pro Apache Kafka?
S připraveným tématem Apache Kafka je nyní možné vytvořit první zprávu. Otevřete nový terminál nebo příkazovou řádku, nebo použijte okno, které bylo použito pro vytvoření tématu. Opět se ujistěte, že se nacházíte ve správné složce, do které byl extrahován obsah archivu. Zprávu do tématu lze odeslat pomocí následujícího příkazu:
Pro Linux:
bin/kafka-console-producer.sh --topic transactions --bootstrap-server localhost:9092
Pro Windows:
bin/windows/kafka-console-producer.bat --topic transactions --bootstrap-server localhost:9092
Po spuštění příkazu se terminál nebo příkazová řádka přepne do režimu čekání na vstup. Napište svou první zprávu a stiskněte Enter.
> This is a transactional record for $100

Tímto krokem byla vytvořena první zpráva pro Apache Kafka na lokálním počítači. Nyní je možné ji dále zpracovat.
Jak zkonzumovat zprávu od Apache Kafka?
Jakmile máte vytvořeno téma a do něj odeslanou zprávu, je možné ji zkonzumovat.
Apache Kafka umožňuje připojit k jednomu tématu více konzumentů. Každý konzument může patřit do skupiny konzumentů, která je identifikována logickým identifikátorem. Pokud například dvě služby potřebují zpracovávat stejná data, mohou mít rozdílné skupiny konzumentů.
Naopak pokud jsou dvě instance stejné služby, je třeba se vyhnout dvojímu zpracování stejné zprávy. V takovém případě budou mít obě instance stejnou skupinu konzumentů.
Ujistěte se, že se terminál nachází ve správné složce. Ke spuštění konzumenta použijte tento příkaz:
Pro Linux:
bin/kafka-console-consumer.sh --topic transactions --from-beginning --bootstrap-server localhost:9092 --group notif-consumer
Pro Windows:
bin/windows/kafka-console-consumer.bat --topic transactions --from-beginning --bootstrap-server localhost:9092 --group notif-consumer
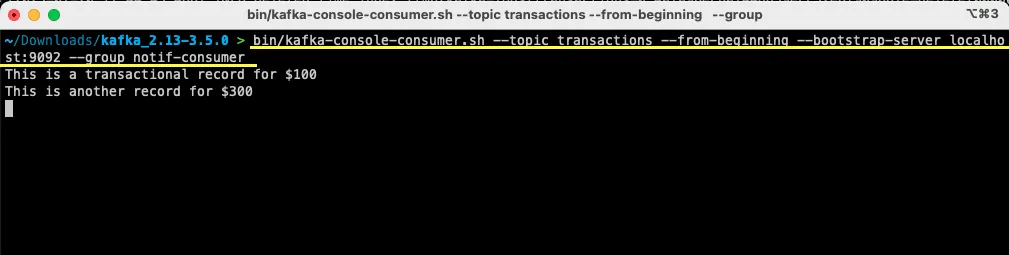
V terminálu se zobrazí zpráva, kterou jste dříve vytvořili. Tímto jste úspěšně zkonzumovali první zprávu pomocí Apache Kafka.
Příkaz kafka-console-consumer přijímá několik argumentů. Podívejme se, co každý z nich znamená:
- Téma – určuje téma, ze kterého se bude konzumovat
- --from-beginning – udává konzoli, aby začala číst zprávy od začátku
- --bootstrap-server – specifikuje server Apache Kafka
- --group – udává skupinu spotřebitelů. Pokud není parametr skupiny spotřebitelů uveden, bude vygenerován automaticky.
S běžícím konzumentem můžete zkoušet vytvářet nové zprávy. Uvidíte, že jsou spotřebovány a zobrazeny v terminálu.
Po vytvoření tématu a odeslání i spotřebování zprávy, se podívejme na integraci s aplikací Java.
Jak vytvořit producenta a konzumenta Apache Kafka pomocí Javy
Než začnete, ujistěte se, že máte na počítači nainstalovanou Java 8+. Apache Kafka poskytuje vlastní klientskou knihovnu, která umožňuje snadné připojení. Pokud ke správě závislostí používáte Maven, přidejte do souboru pom.xml tuto závislost:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.5.0</version>
</dependency>
Knihovnu si můžete stáhnout také z Maven Repository a přidat ji do své Java třídy.
Po přidání knihovny otevřete preferovaný editor kódu. Podívejme se, jak spustit producenta a konzumenta pomocí Javy.
Vytvoření Apache Kafka Java producenta
S nainstalovanou knihovnou kafka klientů je možné začít s tvorbou producenta Kafka.
Vytvořte třídu s názvem SimpleProducer.java. Bude zodpovědná za odesílání zpráv do vytvořeného tématu. Uvnitř této třídy vytvoříte instanci org.apache.kafka.clients.producer.KafkaProducer. Toho producenta budete následně používat k odesílání zpráv.
Pro vytvoření producenta Kafka je potřeba hostitel a port serveru Apache Kafka. Protože běží na lokálním počítači, hostitelem bude localhost. A protože nebyly při spuštění serveru změněny výchozí vlastnosti, port bude 9092. Následující kód ukazuje, jak vytvořit producenta:
package org.example.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
public class SimpleProducer {
private final KafkaProducer<String, String> producer;
public SimpleProducer(String host, String port) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
this.producer = new KafkaProducer<>(properties);
}
}
Jsou nastaveny tři vlastnosti. Projděme si je:
- BOOTSTRAP_SERVERS_CONFIG – definuje, kde běží server Apache Kafka
- KEY_SERIALIZER_CLASS_CONFIG – udává producentovi, jaký formát má použít pro odesílání klíčů zpráv
- VALUE_SERIALIZER_CLASS_CONFIG – definuje formát pro odesílání samotné zprávy
Protože se posílají textové zprávy, obě vlastnosti jsou nastaveny na použití StringSerializer.class.
K odeslání zprávy do tématu je potřeba použít metodu producer.send(), která přijímá ProducerRecord. Následující kód definuje metodu, která odešle zprávu do tématu a vypíše odpověď včetně posunu zprávy.
public void produce(String topic, String message) throws ExecutionException, InterruptedException {
ProducerRecord<String, String> record = new ProducerRecord<>(topic, message);
final Future<RecordMetadata> send = this.producer.send(record);
final RecordMetadata recordMetadata = send.get();
System.out.println(recordMetadata);
}
S celým kódem můžete posílat zprávy do svého tématu. Testování lze provést pomocí hlavní metody, jak je ukázáno v následujícím kódu:
package org.example.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
public class SimpleProducer {
private final KafkaProducer<String, String> producer;
public SimpleProducer(String host, String port) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
this.producer = new KafkaProducer<>(properties);
}
public void produce(String topic, String message) throws ExecutionException, InterruptedException {
ProducerRecord<String, String> record = new ProducerRecord<>(topic, message);
final Future<RecordMetadata> send = this.producer.send(record);
final RecordMetadata recordMetadata = send.get();
System.out.println(recordMetadata);
}
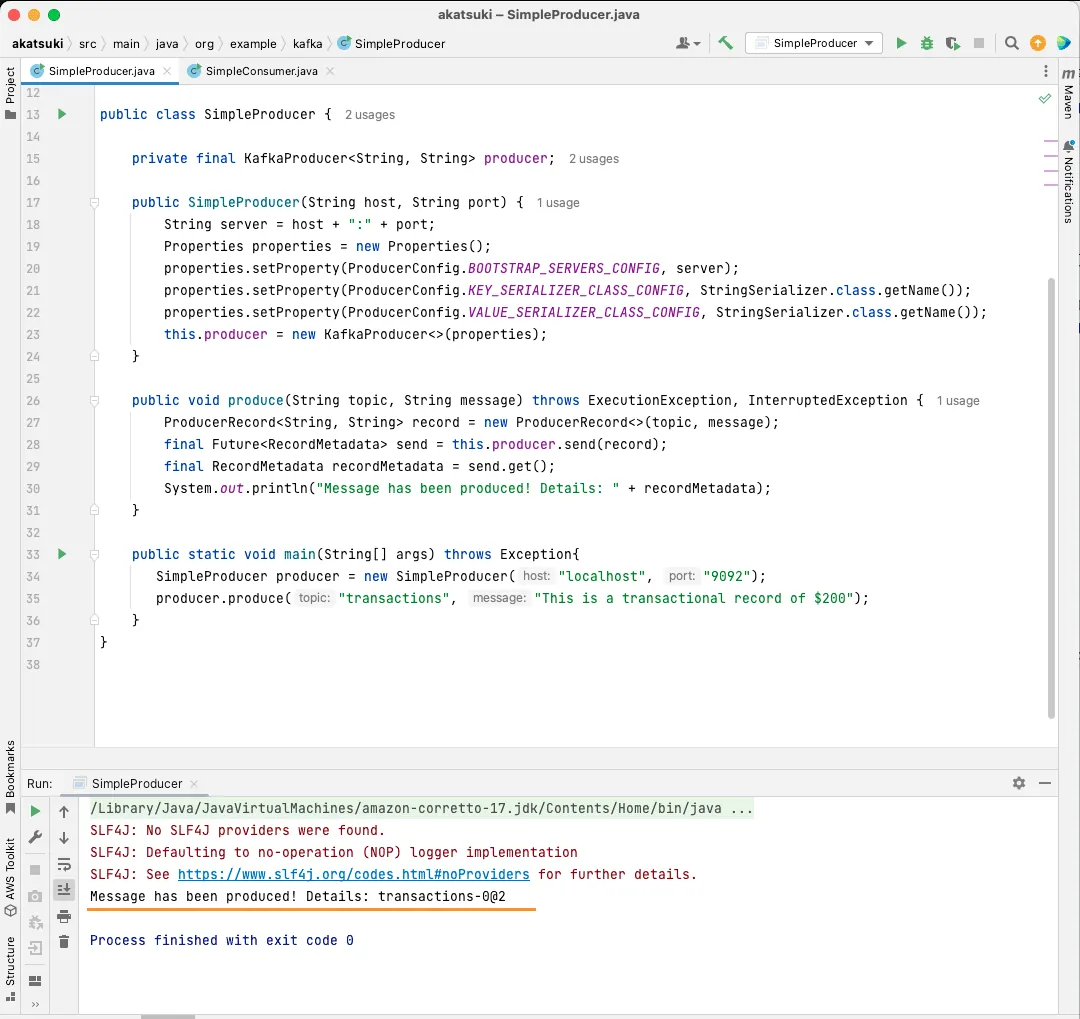
public static void main(String[] args) throws Exception{
SimpleProducer producer = new SimpleProducer("localhost", "9092");
producer.produce("transactions", "This is a transactional record of $200");
}
}
V tomto kódu se vytváří SimpleProducer, který se připojí k serveru Apache Kafka na lokálním počítači. Interně používá KafkaProducer k odesílání textových zpráv do vašeho tématu.
Vytvoření konzumenta Apache Kafka Java
Nyní je čas vytvořit konzumenta Apache Kafka pomocí Java klienta. Vytvořte třídu s názvem SimpleConsumer.java. Pro tuto třídu definujte konstruktor, který inicializuje org.apache.kafka.clients.consumer.KafkaConsumer. Pro vytvoření konzumenta potřebujete hostitele a port, na kterém běží server Apache Kafka. Dále je potřeba specifikovat skupinu konzumentů a téma, ze kterého se bude konzumovat. Použijte následující fragment kódu:
package org.example.kafka;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.List;
import java.util.Properties;
import java.util.concurrent.atomic.AtomicBoolean;
public class SimpleConsumer {
private static final String OFFSET_RESET = "earliest";
private final KafkaConsumer<String, String> consumer;
private boolean keepConsuming = true;
public SimpleConsumer(String host, String port, String consumerGroupId, String topic) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, consumerGroupId);
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, OFFSET_RESET);
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
this.consumer = new KafkaConsumer<>(properties);
this.consumer.subscribe(List.of(topic));
}
}
Stejně jako producent, i konzument Kafka přijímá objekt Properties. Projděme si jednotlivé vlastnosti:
- BOOTSTRAP_SERVERS_CONFIG – informuje konzumenta, kde běží server Apache Kafka
- GROUP_ID_CONFIG – udává skupinu konzumentů
- AUTO_OFFSET_RESET_CONFIG – udává, od kterého místa v tématu má konzument začít přijímat zprávy
- KEY_DESERIALIZER_CLASS_CONFIG – informuje konzumenta o typu klíče zprávy
- VALUE_DESERIALIZER_CLASS_CONFIG – informuje konzumenta o typu samotné zprávy
Protože se v tomto případě konzumují textové zprávy, jsou vlastnosti deserializéru nastaveny na StringDeserializer.class.
Nyní se budou přijímat zprávy z tématu. Pro zjednodušení se každá spotřebovaná zpráva vypíše do konzole. Jak toho dosáhnout, ukazuje následující kód:
private boolean keepConsuming = true;
public void consume() {
while (keepConsuming) {
final ConsumerRecords<String, String> consumerRecords = this.consumer.poll(Duration.ofMillis(100L));
if (consumerRecords != null && !consumerRecords.isEmpty()) {
consumerRecords.iterator().forEachRemaining(consumerRecord -> {
System.out.println(consumerRecord.value());
});
}
}
}
Tento kód se bude opakovaně dotazovat na téma. Když obdrží spotřebitelský záznam, vypíše zprávu. Otestujte konzumenta pomocí hlavní metody. Spustí se Java aplikace, která bude kontinuálně konzumovat téma a vypisovat zprávy. Ukončení konzumenta je možné zastavením Java aplikace.
package org.example.kafka;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.List;
import java.util.Properties;
import java.util.concurrent.atomic.AtomicBoolean;
public class SimpleConsumer {
private static final String OFFSET_RESET = "earliest";
private final KafkaConsumer<String, String> consumer;
private boolean keepConsuming = true;
public SimpleConsumer(String host, String port, String consumerGroupId, String topic) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, consumerGroupId);
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, OFFSET_RESET);
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
this.consumer = new KafkaConsumer<>(properties);
this.consumer.subscribe(List.of(topic));
}
public void consume() {
while (keepConsuming) {
final ConsumerRecords<String, String> consumerRecords = this.consumer.poll(Duration.ofMillis(100L));
if (consumerRecords != null && !consumerRecords.isEmpty()) {
consumerRecords.iterator().forEachRemaining(consumerRecord -> {
System.out.println(consumerRecord.value());
});
}
}
}
public static void main(String[] args) {
SimpleConsumer simpleConsumer = new SimpleConsumer("localhost", "9092", "transactions-consumer", "transactions");
simpleConsumer.consume();
}
}
Po spuštění kódu se zobrazí zprávy, které byly vytvořeny java producentem, i ty, které byly vytvořeny pomocí konzolového producenta. To je způsobeno tím, že vlastnost AUTO_OFFSET_RESET_CONFIG byla nastavena na earliest.
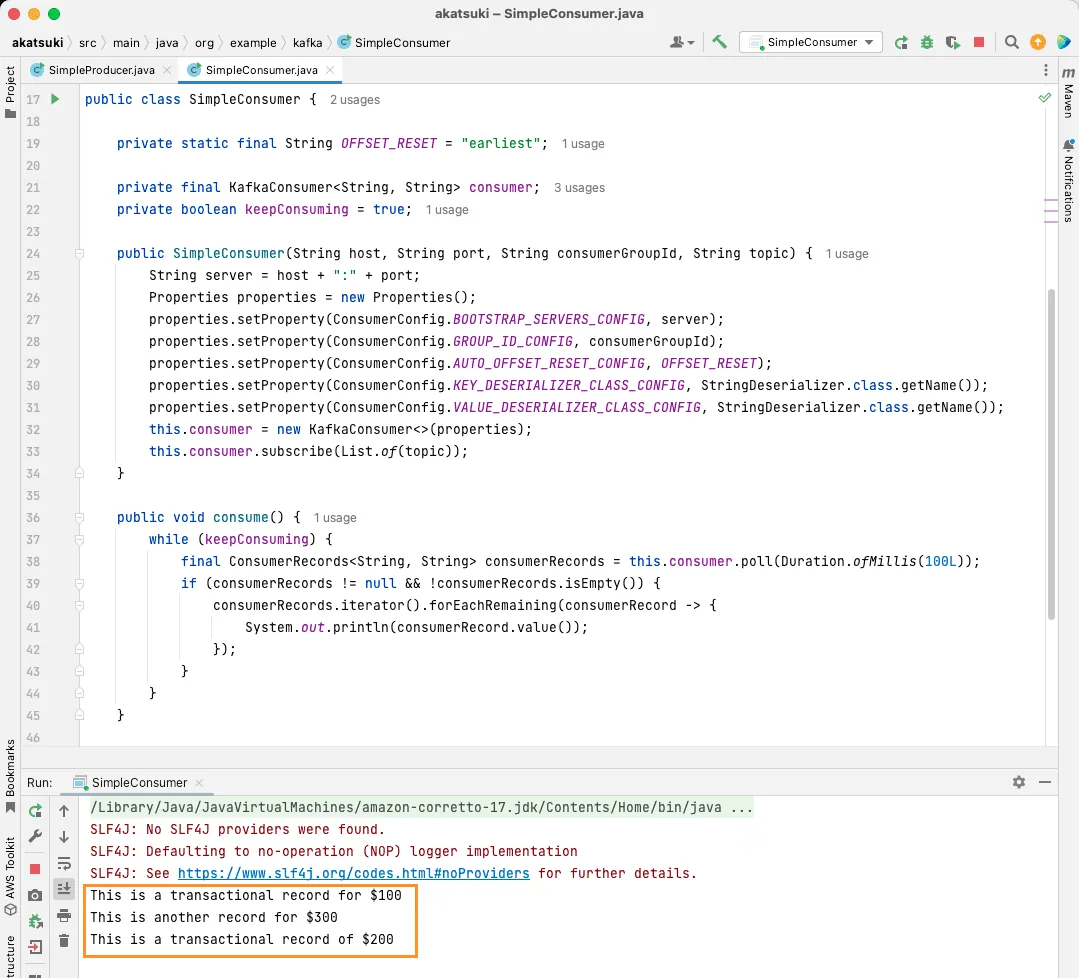
Při spuštěném SimpleConsumer lze používat konzolového producenta nebo Java aplikaci SimpleProducer pro odesílání dalších zpráv do tématu. Ty se budou spotřebovávat a vypisovat v konzoli.
Naplňte všechny potřeby datového kanálu s Apache Kafka
Apache Kafka umožňuje efektivně zpracovat veškeré požadavky na datové kanály. Díky instalaci Apache Kafka na lokálním počítači je možné prozkoumat všechny dostupné funkce, které Kafka nabízí. Oficiální Java klient umožňuje efektivní vytváření, připojování a komunikaci se serverem Apache Kafka.
Apache Kafka je flexibilní, škálovatelný a vysoce výkonný systém pro streamování dat, který může být zásadní pro váš projekt. Lze jej použít pro lokální vývoj, ale i pro integraci do produkčních systémů. Instalace Apache Kafka není složitá ani pro větší aplikace.
Pokud hledáte platformy pro streamování dat, můžete se podívat na doporučené platformy pro analýzu a zpracování v reálném čase.
