Rozpoznání pojmenované entity (NER) Vysvětleno v laických podmínkách
Rozpoznávání pojmenovaných entit, zkráceně NER, je efektivní nástroj pro pochopení textového obsahu a identifikaci konkrétních prvků, které lze využít v různých oblastech.
Od třídění jmen osob po označování dat, organizací, míst a dalších, NER si postupně získává významnou pozici v oblasti porozumění jazyku.
Mnoho organizací se potýká s obrovským množstvím dat v různých formátech, ať už jde o obsah, osobní údaje, zpětnou vazbu klientů, informace o produktech a mnoho dalšího.
Pokud potřebujete informace ihned, jste nuceni provádět vyhledávací operace, což může být časově, energeticky i finančně náročné, zvláště pokud pracujete s rozsáhlými datovými sadami.
Právě NER nabízí efektivní řešení pro vyhledávání a rychlé nalezení relevantních informací v organizacích.
V tomto článku se podrobně podíváme na NER, jeho matematické základy, různé možnosti jeho využití a další důležité aspekty.
Začněme!
Co je to rozpoznávání pojmenovaných entit?
Rozpoznávání pojmenovaných entit (NER) je metoda zpracování přirozeného jazyka (NLP), která umožňuje identifikovat a klasifikovat specifické entity v neuspořádaných textových datech.
Mezi tyto entity patří široká škála informací, například organizace, lokality, jména osob, číselné údaje, data a další. Díky NER jsou stroje schopné tyto entity extrahovat, což z něj činí klíčový nástroj pro překlad, odpovídání na otázky a další aplikace napříč různými obory.
Zdroj: Scaler
NER se tedy zaměřuje na vyhledávání a kategorizaci rozmanitých entit v neuspořádaném textu do předem definovaných skupin, jako jsou organizace, lékařské kódy, množství, jména, procenta, peněžní částky, časové údaje a další.
Pro lepší pochopení si uvedeme příklad:
[William] zakoupil nemovitost od společnosti [Z1 Corp.] v roce [2023]. V tomto případě NER identifikuje a klasifikuje entity takto:
- William – jméno osoby
- Z1 Corp. – organizace
- 2023 – čas
NER nachází své uplatnění v mnoha oblastech umělé inteligence, včetně hlubokého učení, strojového učení (ML) a neuronových sítí. Je klíčovou součástí systémů NLP, jako jsou nástroje pro analýzu sentimentu, vyhledávače a chatboty. Navíc jej lze s úspěchem aplikovat ve financích, zákaznické podpoře, vzdělávání, zdravotnictví, lidských zdrojích i analýze sociálních médií.
Zjednodušeně řečeno, NER automaticky rozpoznává, klasifikuje a extrahuje klíčové informace z nestrukturovaného textu, bez nutnosti lidské analýzy. Umožňuje rychlé získání relevantních informací z rozsáhlých datových souborů.
Dále NER poskytuje organizacím důležité informace o produktech, tržních trendech, zákaznících i konkurenci. Například zdravotnická zařízení využívají NER k extrahování klíčových lékařských informací z dokumentace pacientů. Mnoho firem jej používá k monitorování zmínek o své značce v publikacích.
Klíčové koncepty: NER

Je důležité se seznámit se základními pojmy souvisejícími s NER. Nyní si probereme některé klíčové termíny, které je dobré znát:
- Pojmenovaná entita: Jakékoli slovo, které odkazuje na místo, organizaci, osobu nebo jinou entitu.
- Korpus: Sbírka různých textů sloužící k analýze jazyka a trénování NER modelů.
- POS tagování: Proces, při kterém se text označuje podle slovních druhů, jako jsou přídavná jména, slovesa a podstatná jména.
- Chunking: Proces seskupování slov do smysluplných frází na základě syntaktické struktury a slovních druhů.
- Tréninková a testovací data: Data používaná k trénování modelu s označenými daty a následně k vyhodnocení jeho výkonu na jiné datové sadě.
Použití NER v NLP

NER se široce uplatňuje v různých oblastech NLP, včetně analýzy sentimentu, doporučovacích systémů, odpovídání na otázky, extrakce informací a dalších.
- Analýza sentimentu: NER umožňuje detekovat sentiment vyjádřený v textu vůči konkrétní entitě, například produktu nebo službě. Tato data jsou následně využívána ke zlepšování zákaznické spokojenosti a identifikaci oblastí vyžadujících zlepšení.
- Doporučovací systémy: NER se používá k rozpoznávání preferencí a zájmů uživatelů na základě entit zmíněných v jejich online aktivitě nebo vyhledávacích dotazech. Tato data umožňují poskytování personalizovaných doporučení.
- Odpovědi na otázky: NER pomáhá extrahovat specifické entity z textu, které se následně používají k zodpovězení otázek. To je klíčové pro virtuální asistenty a chatboty.
- Extrakce informací: NER je nástrojem pro extrahování klíčových informací z velkého množství neuspořádaného textu, jako jsou příspěvky na sociálních sítích, recenze, zpravodajské články a další. Získaná data slouží k vytváření cenných poznatků a rozhodování na základě ověřených informací.
Matematické koncepty: NER
NER využívá různé matematické koncepty, jako je strojové učení, hluboké učení, teorie pravděpodobnosti a další. Následují některé matematické techniky:
- Skryté Markovovy modely: Jedná se o statistický přístup pro úlohy sekvenční klasifikace, jako je NER. Posloupnost slov v textu je reprezentována jako stavy, kde každý stav představuje konkrétní pojmenovanou entitu. Analýzou pravděpodobností lze identifikovat pojmenované entity v textu.
- Hluboké učení: Pro úlohy NER se používají techniky hlubokého učení, jako jsou neuronové sítě, které umožňují efektivní a přesnou identifikaci a kategorizaci pojmenovaných entit.
- Podmíněná náhodná pole: Tento grafický model se používá při sekvenčním označování. Umožňuje modelování podmíněné pravděpodobnosti každého tagu v posloupnosti slov a pomáhá při identifikaci pojmenovaných entit v textu.
Jak NER funguje?
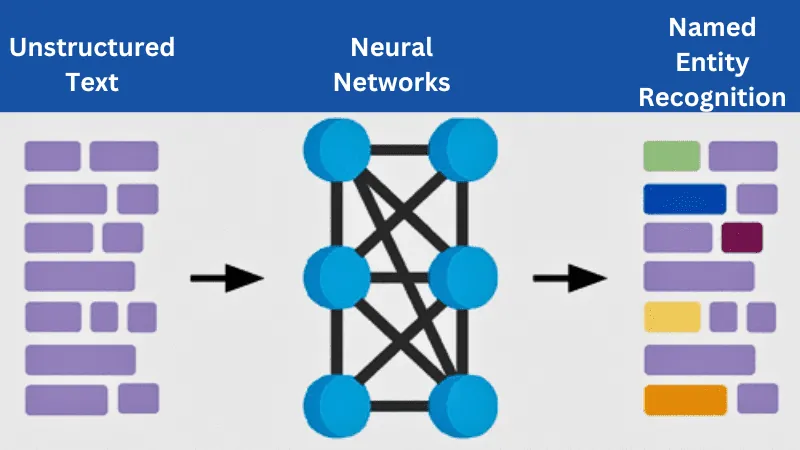 Zdroj: Publikace ACS
Zdroj: Publikace ACS
Rozpoznávání pojmenovaných entit (NER) funguje jako proces extrakce informací a skládá se z několika klíčových kroků:
#1. Předzpracování textu
Prvním krokem je příprava textových informací pro analýzu. Obvykle se jedná o úkoly jako tokenizace, kdy se text rozdělí na jednotlivé tokeny před zahájením identifikace entit.
Například věta „Bill Gates založil Microsoft“ se rozdělí na tokeny: „Bill“, „Gates“, „založil“ a „Microsoft“.
#2. Identifikace entit
Potenciální pojmenované entity se detekují pomocí statistických metod nebo lingvistických pravidel. Tento krok zahrnuje rozpoznávání vzorů, jako jsou specifické formáty (data) nebo velká písmena u jmen („Bill Gates“). Jakmile je předzpracování dokončeno, algoritmy NER prohledávají text a hledají slova nebo sekvence, které odpovídají entitám.
#3. Klasifikace entit
Po identifikaci entit dochází k jejich zařazení do specifických typů, tříd nebo skupin. Běžné kategorie zahrnují organizace, data, lokality, osoby a další. Pro tento úkol se využívají modely strojového učení, které jsou trénované na označených datech.
Například „Bill Gates“ je zařazen jako „osoba“ a „Microsoft“ jako „organizace“.
#4. Kontextová analýza
NER se nezastaví pouze u rozpoznávání a klasifikace entit. Pro zvýšení přesnosti se často bere v úvahu kontext, v němž se entity objevují. Tento krok umožňuje přesnější kategorizaci na základě okolností.
Například ve větě „Bill Gates založil Microsoft“ kontext umožňuje systémům identifikovat „Bill“ jako jméno osoby, nikoli jako fakturu.
#5. Následné zpracování
Po prvotní identifikaci a kategorizaci je potřeba následné zpracování pro zpřesnění výsledků. Zahrnuje řešení nejednoznačností, využití znalostních databází, slučování entit s více tokeny a další postupy pro vylepšení extrahovaných dat.
Skvělé na NER je jeho schopnost interpretovat a rozumět nestrukturovanému textu a získávat z něj potřebné informace. Využívá data ze zpravodajských článků, webových stránek, výzkumných prací, příspěvků na sociálních sítích a dalších zdrojů.
Rozpoznáváním a kategorizací pojmenovaných entit přidává NER do textového prostředí další vrstvu významu a struktury.
Metody NER

Nejčastěji používané metody jsou následující:
#1. Metoda založená na strojovém učení s dohledem
Tato metoda využívá modely strojového učení, které jsou trénovány na textech, jež byly předem označeny lidmi a přiřazeny k příslušným kategoriím entit.
Tento přístup používá algoritmy, jako je maximální entropie a podmíněná náhodná pole, k získání komplexních statistických jazykových modelů. Je efektivní pro řešení lingvistických významů i dalších složitostí, ale vyžaduje velký objem trénovacích dat.
#2. Systémy založené na pravidlech
Tato metoda používá pravidla pro získávání informací. Zahrnuje identifikaci názvů nebo velkých písmen, například „Er“. Tento přístup vyžaduje značný lidský zásah pro zadávání, monitorování a dolaďování pravidel. Může však ignorovat textové varianty, které nejsou v trénovacích anotacích. Proto systémy založené na pravidlech nejsou schopny řešit komplexitu tak efektivně jako modely strojového učení.
#3. Systémy založené na slovníku
Tato metoda využívá slovník obsahující rozsáhlou databázi synonym a slovní zásoby pro identifikaci a křížovou kontrolu pojmenovaných identit. Problémem této metody je kategorizace pojmenovaných entit s různými pravopisnými variantami.
Existuje i mnoho dalších nově vznikajících metod NER. Podívejme se i na ně:
#4. Systémy strojového učení bez dohledu
Tyto systémy ML využívají modely, které nejsou předem trénované na textových datech. Modely učení bez dohledu jsou schopné vykonávat složitější úlohy než modely s dohledem.
#5. Bootstrapovací systémy
Bootstrapping systémy, známé také jako systémy s vlastním dohledem, kategorizují pojmenované entity na základě gramatických charakteristik, včetně slovních druhů, velkých písmen a dalších předem trénovaných kategorií.
Následně člověk upraví bootstrap systém tak, že označí predikce systému jako nesprávné nebo správné a ty správné přidá do nové tréninkové sady.
#6. Systémy neuronových sítí
Tyto systémy vytvářejí model rozpoznávání pojmenovaných entit pomocí obousměrných architektur (obousměrné reprezentace kodéru od společnosti Transformers), neuronových sítí a technik kódování. Tato metoda minimalizuje lidský zásah.
#7. Statistické systémy
Tato metoda používá pravděpodobnostní modely, které jsou trénované na textových vztazích a vzorech. Pomáhá snadno předvídat pojmenované entity z nových textových dat.
#8. Systémy označování sémantických rolí
Tento systém předzpracovává model rozpoznávání pojmenovaných entit s pomocí technik sémantického učení, které se učí vztahy mezi kategoriemi a kontextem.
#9. Hybridní systémy
Tato metoda je zajímavá, protože využívá aspekty několika přístupů v kombinaci.
Výhody NER
NER modely nabízejí řadu výhod.
- NER automatizuje proces extrakce dat z rozsáhlých objemů informací.
- Nachází využití v každém odvětví pro extrakci klíčových informací z nestrukturovaného textu.
- Šetří čas zaměstnancům při provádění úkolů extrakce dat.
- Zvyšuje přesnost procesů a úkolů NLP.
- Zajišťuje bezpečnost dat hostováním vlastních NER modelů, čímž eliminuje potřebu sdílet citlivé údaje s externími dodavateli.
- Přizpůsobuje se novým typům entit a terminologii v dynamicky se rozvíjejících oblastech.
Výzvy NER
- Nejednoznačnost: Mnoho slov použitých v textu může být nejednoznačných. Například slovo „Amazon“ může odkazovat na společnost, řeku i les. Rozlišení je možné díky konkrétnímu kontextu. To komplikuje rozpoznávání entit.
- Kontextová závislost: Význam slov se mění v závislosti na kontextu. Například „Apple“ v technologickém textu odkazuje na firmu, zatímco v jiném kontextu na ovoce. Není tak snadné rozpoznat přesnou entitu.
- Rozmanitost dat: Pro metody NER založené na ML je dostupnost označených dat klíčová. Extrakce takových dat, zejména pro specializované domény nebo méně obvyklé jazyky, může být obtížná.
- Jazykové variace: Lidské jazyky mají různé formy v závislosti na dialektech, regionálních odlišnostech a slangu. Extrakce textu v cizím jazyce tak může být obtížná.
- Zobecnění modelu: Modely NER mohou vynikat v klasifikaci entit v jedné doméně, ale mohou být méně efektivní v jiné doméně. Modely NER se tedy mohou v různých doménách chovat odlišně.
Tyto problémy lze řešit kombinací pokročilých algoritmů, lingvistických znalostí a kvalitních dat. Vzhledem k tomu, že se NER neustále vyvíjí, výzkumné a vývojové týmy musí zdokonalovat různé techniky, aby se těmto výzvám postavily.
Případy použití NER
#1. Kategorizace obsahu

Vydavatelství a zpravodajské společnosti produkují velké množství online obsahu. Efektivní správa je proto zásadní pro maximální využití článků nebo zpráv.
Rozpoznávání pojmenovaných entit automaticky prohledá veškerý obsah a extrahuje data, jako jsou organizace, místa a jména osob. Znalost nezbytných tagů pro každý článek usnadňuje kategorizaci článků do definované hierarchie a zlepšuje tak poskytování obsahu.
#2. Vyhledávací algoritmy
Představte si, že máte interní vyhledávací algoritmus pro vašeho online vydavatele, který obsahuje miliony článků. Pro každý vyhledávací dotaz tento algoritmus musí projít veškerá slova v těchto článcích, což je časově náročný proces.
Pokud ale používáte NER, můžete snadno získat klíčové entity z článků a uložit je samostatně. To urychlí proces vyhledávání.
#3. Doporučení obsahu
Automatizace doporučovacího procesu je jedním z hlavních případů použití NER. Doporučovací systémy pomáhají uživatelům objevovat nový obsah a nápady.
Netflix je skvělým příkladem toho, jak efektivní doporučovací systém může uživatele více zaujmout. Pro vydavatele zpráv funguje NER efektivně při doporučování podobných článků. Toho lze dosáhnout shromážděním tagů z konkrétního článku a doporučením dalšího obsahu s podobnými entitami.
#4. Zákaznická podpora

Zákaznická podpora je pro každou organizaci důležitá. Existuje několik způsobů, jak zajistit hladké zpracování zpětné vazby od zákazníků. NER je jedním z nich. Podívejme se na příklad.
Zákazník může například napsat: „Zaměstnanci prodejny Adidas v San Diegu nemají dostatečné znalosti o sportovní obuvi.“ NER extrahuje tagy „San Diego“ (místo) a „sportovní obuv“ (produkt).
NER se používá ke klasifikaci jednotlivých stížností a jejich odeslání příslušnému oddělení organizace. Můžete tak vytvořit databázi zpětné vazby, která je kategorizována do různých oddělení a analyzovat jednotlivé případy.
#5. Vědecké práce
Online publikace a webové stránky časopisů obsahují mnoho odborných článků a výzkumných prací. Můžete najít stovky článků s podobnými tématy a drobnými odchylkami, takže strukturované uspořádání dat je obtížné.
Abyste se vyhnuli zdlouhavému procesu, můžete tyto dokumenty roztřídit na základě příslušných štítků.
Například existují tisíce prací o strojovém učení. Pokud chcete najít tu, která zmiňuje konvoluční neuronové sítě (CNN), je nutné použít entity. To vám pomůže rychle najít požadovaný článek.
Závěr
Technika NLP, Rozpoznávání pojmenovaných entit (NER), pomáhá s identifikací pojmenovaných entit v neuspořádaném textu a jejich kategorizací do předem definovaných skupin, jako jsou lokality, jména osob, produkty a další.
Primárním cílem NER je shromažďovat strukturované informace z nestrukturovaného textu a reprezentovat je v čitelné formě. Využívá různé modely a procesy a přináší mnoho výhod pro profesionály i podniky. Kromě NLP se také používá pro celou řadu aplikací.
Doufám, že vám toto vysvětlení pomůže pochopit tuto techniku, abyste ji mohli implementovat ve vašem podnikání a včas získávat relevantní a cenné informace.
Můžete si také prohlédnout některé z nejlepších kurzů NLP a prohloubit si své znalosti o zpracování přirozeného jazyka.
