
Zpracování velkých dat je jedním z nejsložitějších postupů, kterým organizace čelí. Proces se stává složitějším, když máte velký objem dat v reálném čase.
V tomto příspěvku zjistíme, co je zpracování velkých dat, jak se to dělá, a prozkoumáme Apache Kafka a Spark – dva z nejznámějších nástrojů pro zpracování dat!
Table of Contents
Co je zpracování dat? jak se to dělá?
Zpracování dat je definováno jako jakákoli operace nebo soubor operací, ať už jsou prováděny pomocí automatizovaného procesu či nikoli. Lze si to představit jako shromažďování, řazení a organizaci informací podle logické a vhodné dispozice pro interpretaci.
Když uživatel přistupuje k databázi a získává výsledky pro své vyhledávání, je to zpracování dat, které mu poskytuje výsledky, které potřebuje. Informace extrahované jako výsledek vyhledávání jsou výsledkem zpracování dat. Informační technologie se proto soustředí na zpracování dat.
Tradiční zpracování dat bylo prováděno pomocí jednoduchého softwaru. S příchodem Big Data se však věci změnily. Big Data jsou informace, jejichž objem může být přes sto terabajtů a petabajtů.
Tyto informace jsou navíc pravidelně aktualizovány. Příklady zahrnují data pocházející z kontaktních center, sociálních médií, burzovní obchodní data atd. Taková data se někdy také nazývají datový tok – neustálý, nekontrolovaný tok dat. Jeho hlavní charakteristikou je, že data nemají žádné definované limity, takže nelze říci, kdy stream začíná nebo končí.
Data se zpracovávají, jakmile dorazí na místo určení. Někteří autoři tomu říkají zpracování v reálném čase nebo online. Odlišným přístupem je blokové, dávkové nebo offline zpracování, při kterém jsou bloky dat zpracovávány v časových oknech hodin nebo dnů. Dávka je často proces, který běží v noci a konsoliduje data daného dne. Existují případy, kdy časová okna v délce týdne nebo dokonce měsíce generují zastaralé zprávy.
Vzhledem k tomu, že nejlepšími platformami pro zpracování velkých dat prostřednictvím streamování jsou otevřené zdroje, jako je Kafka a Spark, umožňují tyto platformy použití dalších odlišných a vzájemně se doplňujících. To znamená, že jako open source se vyvíjejí rychleji a používají více nástrojů. Tímto způsobem jsou datové toky přijímány z jiných míst proměnlivou rychlostí a bez přerušení.
Nyní se podíváme na dva nejznámější nástroje pro zpracování dat a porovnáme je:
Apache Kafka
Apache Kafka je systém pro zasílání zpráv, který vytváří streamovací aplikace s nepřetržitým tokem dat. Kafka, původně vytvořený LinkedIn, je založen na logu; log je základní forma úložiště, protože každá nová informace je přidána na konec souboru.

Kafka je jedním z nejlepších řešení pro velká data, protože jeho hlavní charakteristikou je vysoká propustnost. S Apache Kafka je dokonce možné transformovat dávkové zpracování v reálném čase,
Apache Kafka je systém zasílání zpráv typu publikovat a odebírat, ve kterém aplikace publikuje a aplikace, která se přihlásí k odběru, přijímá zprávy. Doba mezi zveřejněním a přijetím zprávy může být milisekundy, takže řešení Kafka má nízkou latenci.
Kafkova práce
Architektura Apache Kafka zahrnuje producenty, spotřebitele a samotný klastr. Producentem je jakákoli aplikace, která publikuje zprávy do clusteru. Spotřebitelem je jakákoli aplikace, která přijímá zprávy od Kafky. Cluster Kafka je sada uzlů, které fungují jako jediná instance služby zasílání zpráv.
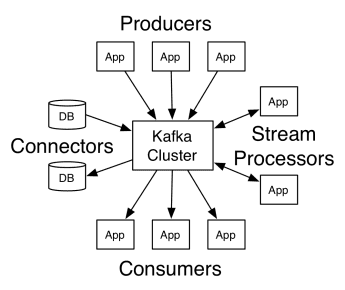 Kafkova práce
Kafkova práce
Kafka cluster se skládá z několika brokerů. Broker je Kafka server, který přijímá zprávy od producentů a zapisuje je na disk. Každý broker spravuje seznam témat a každé téma je rozděleno do několika oddílů.
Po obdržení zpráv je broker rozešle registrovaným spotřebitelům pro každé téma.
Nastavení Apache Kafka spravuje Apache Zookeeper, který ukládá metadata clusteru, jako je umístění oddílu, seznam názvů, seznam témat a dostupné uzly. Zookeeper tedy udržuje synchronizaci mezi různými prvky clusteru.
Zookeeper je důležitý, protože Kafka je distribuovaný systém; to znamená, že zápis a čtení provádí několik klientů současně. Pokud dojde k poruše, Zookeeper vybere náhradu a obnoví operaci.
Případy užití
Kafka se stala populární zejména pro své použití jako nástroj pro zasílání zpráv, ale její všestrannost přesahuje to a lze ji použít v různých scénářích, jako v příkladech níže.
Zasílání zpráv
Asynchronní forma komunikace, která odděluje strany, které komunikují. V tomto modelu jedna strana posílá data jako zprávu Kafkovi, takže jiná aplikace je později spotřebuje.
Sledování aktivity
Umožňuje ukládat a zpracovávat data sledující interakci uživatele s webem, jako jsou zobrazení stránek, kliknutí, zadávání dat atd.; tento typ činnosti obvykle generuje velký objem dat.
Metriky
Zahrnuje agregaci dat a statistik z více zdrojů za účelem vytvoření centralizované zprávy.
Agregace protokolů
Centrálně agreguje a ukládá soubory protokolu pocházející z jiných systémů.
Zpracování streamu
Zpracování datových kanálů se skládá z několika fází, kde se nezpracovaná data spotřebovávají z témat a agregují, obohacují nebo transformují do jiných témat.
Pro podporu těchto funkcí platforma v podstatě poskytuje tři rozhraní API:
- Streams API: Funguje jako stream procesor, který spotřebovává data z jednoho tématu, transformuje je a zapisuje do jiného.
- Connectors API: Umožňuje připojení témat ke stávajícím systémům, jako jsou relační databáze.
- API pro producenty a spotřebitele: Umožňuje aplikacím publikovat a využívat data Kafka.
Profesionálové
Replikované, dělené a uspořádané
Zprávy v Kafka jsou replikovány napříč oddíly napříč uzly clusteru v pořadí, v jakém přicházejí, aby byla zajištěna bezpečnost a rychlost doručení.
Transformace dat
S Apache Kafka je dokonce možné transformovat dávkové zpracování v reálném čase pomocí dávkového API ETL streamů.
Sekvenční přístup na disk
Apache Kafka uchovává zprávu na disku a ne v paměti, protože má být rychlejší. Ve skutečnosti je přístup do paměti ve většině situací rychlejší, zvláště pokud uvažujete o přístupu k datům, která jsou na náhodných místech v paměti. Kafka však dělá sekvenční přístup a v tomto případě je disk efektivnější.
Apache Spark
Apache Spark je výpočetní stroj pro velká data a sada knihoven pro zpracování paralelních dat napříč clustery. Spark je evolucí Hadoopu a programovacího paradigmatu Map-Reduce. Může být 100x rychlejší díky efektivnímu využití paměti, která při zpracování neuchovává data na discích.
Spark je organizován na třech úrovních:
- Nízkoúrovňová rozhraní API: Tato úroveň obsahuje základní funkce pro spouštění úloh a další funkce vyžadované ostatními komponentami. Dalšími důležitými funkcemi této vrstvy jsou správa zabezpečení, sítě, plánování a logického přístupu k souborovým systémům HDFS, GlusterFS, Amazon S3 a další.
- Strukturovaná rozhraní API: Úroveň Strukturované rozhraní API se zabývá manipulací s daty prostřednictvím DataSets nebo DataFrames, které lze číst ve formátech jako Hive, Parquet, JSON a další. Pomocí SparkSQL (API, které nám umožňuje psát dotazy v SQL) můžeme manipulovat s daty tak, jak chceme.
- Vysoká úroveň: Na nejvyšší úrovni máme ekosystém Spark s různými knihovnami, včetně Spark Streaming, Spark MLlib a Spark GraphX. Jsou zodpovědní za péči o příjem streamování a okolní procesy, jako je obnova po havárii, vytváření a ověřování klasických modelů strojového učení a práce s grafy a algoritmy.
Práce Sparku
Architektura aplikace Spark se skládá ze tří hlavních částí:
Driver Program: Je zodpovědný za orchestraci provádění zpracování dat.
Cluster Manager: Je to komponenta zodpovědná za správu různých strojů v clusteru. Potřebné pouze v případě, že Spark běží distribuovaně.
Pracovní uzly: Jedná se o stroje, které provádějí úkoly programu. Pokud je Spark spuštěn lokálně na vašem počítači, bude hrát roli Driver Program a Workes. Tento způsob provozování Sparku se nazývá Standalone.
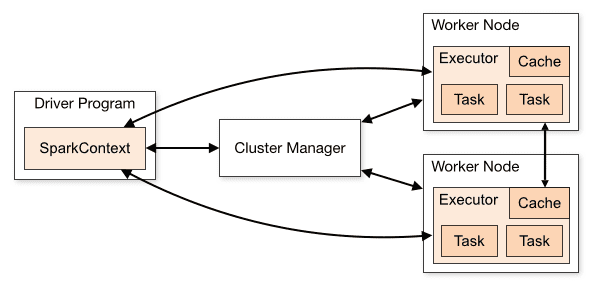 Přehled clusteru
Přehled clusteru
Spark kód může být napsán v mnoha různých jazycích. Konzole Spark s názvem Spark Shell je interaktivní pro učení a zkoumání dat.
Takzvaná aplikace Spark se skládá z jedné nebo více Jobs, umožňujících podporu rozsáhlého zpracování dat.
Když mluvíme o provádění, Spark má dva režimy:
- Klient: Ovladač běží přímo na klientovi, který neprochází přes Správce prostředků.
- Cluster: Ovladač spuštěný na aplikačním hlavním serveru prostřednictvím Správce prostředků (v režimu Cluster, pokud se klient odpojí, aplikace bude pokračovat v běhu).
Je nutné používat Spark správně, aby propojené služby, jako je Resource Manager, dokázaly identifikovat potřebu každého spuštění a poskytovaly nejlepší výkon. Je tedy na vývojáři, aby znal nejlepší způsob, jak spouštět své úlohy Spark, strukturovat provedené volání, a proto můžete strukturovat a konfigurovat spouštěcí nástroje Spark tak, jak chcete.
Úlohy Spark primárně využívají paměť, takže je běžné upravovat hodnoty konfigurace Spark pro spouštěče pracovních uzlů. V závislosti na zátěži Spark je možné určit, že určitá nestandardní konfigurace Spark poskytuje optimálnější provedení. Za tímto účelem lze provést srovnávací testy mezi různými dostupnými možnostmi konfigurace a samotnou výchozí konfigurací Spark.
Případy použití
Apache Spark pomáhá při zpracování obrovského množství dat, ať už v reálném čase nebo archivovaných, strukturovaných nebo nestrukturovaných. Níže jsou uvedeny některé z jeho oblíbených případů použití.
Obohacování dat
Společnosti často používají kombinaci historických údajů o zákaznících s údaji o chování v reálném čase. Spark může pomoci vybudovat kontinuální ETL kanál pro převod nestrukturovaných dat událostí na strukturovaná data.
Spouštěcí událost Detekce
Spark Streaming umožňuje rychlou detekci a reakci na některé vzácné nebo podezřelé chování, které by mohlo naznačovat potenciální problém nebo podvod.
Komplexní analýza dat relace
Pomocí Spark Streaming lze seskupovat a analyzovat události související s relací uživatele, jako jsou jeho aktivity po přihlášení do aplikace. Tyto informace lze také průběžně používat k aktualizaci modelů strojového učení.
Profesionálové
Iterativní zpracování
Pokud je úkolem zpracovávat data opakovaně, pružné distribuované datové sady Spark (RDD) umožňují více operací s mapou v paměti, aniž by bylo nutné zapisovat na disk prozatímní výsledky.
Grafické zpracování
Sparkův výpočetní model s GraphX API je vynikající pro iterativní výpočty typické pro grafické zpracování.
Strojové učení
Spark má MLlib – vestavěnou knihovnu strojového učení, která má hotové algoritmy, které běží také v paměti.
Kafka vs. Spark
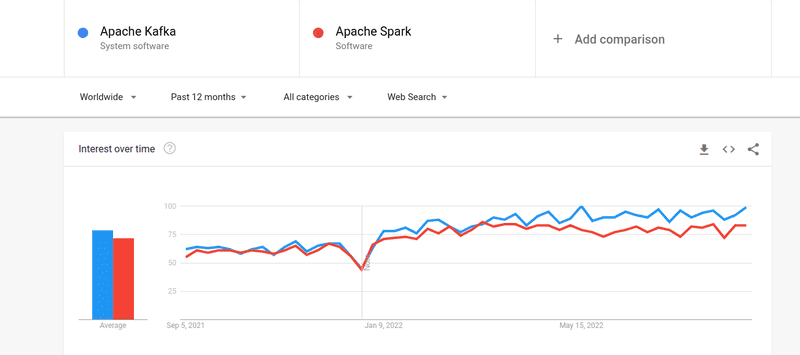
I když byl zájem lidí o Kafku i Spark téměř podobný, existují mezi nimi určité zásadní rozdíly; Pojďme se podívat.
#1. Zpracování dat
Kafka je nástroj pro streamování a ukládání dat v reálném čase, který je zodpovědný za přenos dat mezi aplikacemi, ale k vybudování kompletního řešení to nestačí. Pro úkoly, které Kafka nedělá, jsou proto potřeba jiné nástroje, jako je Spark. Spark je na druhé straně první dávkovou platformou pro zpracování dat, která čerpá data z Kafkových témat a převádí je do kombinovaných schémat.
#2. Správa paměti
Spark používá Robust Distributed Datasets (RDD) pro správu paměti. Místo toho, aby se pokoušela zpracovávat velké soubory dat, distribuuje je přes více uzlů v clusteru. Naproti tomu Kafka používá sekvenční přístup podobný HDFS a data ukládá do vyrovnávací paměti.
#3. ETL transformace
Spark i Kafka podporují proces transformace ETL, který kopíruje záznamy z jedné databáze do druhé, obvykle z transakční (OLTP) na analytickou (OLAP). Na rozdíl od Sparku, který přichází s vestavěnou schopností pro proces ETL, však Kafka spoléhá na to, že jej podporuje Streams API.
#4. Stálost dat

Použití RRD ve Sparku vám umožňuje ukládat data na více místech pro pozdější použití, zatímco v Kafka musíte definovat objekty datové sady v konfiguraci, abyste zachovali data.
#5. Obtížnost
Spark je kompletní řešení a snadněji se učí díky podpoře různých programovacích jazyků na vysoké úrovni. Kafka závisí na řadě různých API a modulů třetích stran, což může ztěžovat práci.
#6. Zotavení
Spark i Kafka poskytují možnosti obnovy. Spark používá RRD, což mu umožňuje nepřetržitě ukládat data, a pokud dojde k selhání clusteru, lze je obnovit.

Kafka nepřetržitě replikuje data uvnitř clusteru a replikuje napříč brokery, což vám umožňuje přejít k různým brokerům, pokud dojde k selhání.
Podobnosti mezi Sparkem a Kafkou
Apache SparkApache KafkaOpenSourceOpenSourceBuild Streamování dat AplikaceBuild Aplikace pro streamování datPodporuje stavové zpracováníPodporuje stavové zpracováníPodporuje SQLPodporuje SQLPodobnosti mezi Spark a Kafka
Závěrečná slova
Kafka a Spark jsou oba open-source nástroje napsané v Scala a Java, které vám umožňují vytvářet aplikace pro streamování dat v reálném čase. Mají několik věcí společných, včetně stavového zpracování, podpory SQL a ETL. Kafka a Spark lze také použít jako doplňkové nástroje, které pomohou vyřešit problém složitosti přenosu dat mezi aplikacemi.