Tato skrytá funkce Google Dokumentů dělá hledání a nahrazování mnohem mocnějším.
Stěžejní body
- Regulární výrazy (RegEx) v Dokumentech Google umožňují komplexní vyhledávání, ačkoli nemohou nahrazovat text pomocí vzorů.
- Použití RegEx zvyšuje přesnost při vyhledávání a nahrazování textu, zvláště v obsáhlých dokumentech.
- RegEx se efektivně uplatní při odstraňování čísel citací, identifikaci opakujících se slov a úpravě webových odkazů.
Při práci s rozsáhlými textovými dokumenty je často klíčové rychle nalézt konkrétní textové úseky. Funkce "Najít a nahradit" v Google Dokumentech je užitečná, ale s pomocí skryté funkce lze její možnosti ještě rozšířit: Regulární výrazy (RegEx).
Vylepšení vyhledávání a nahrazování pomocí RegEx
Schopnost přesně lokalizovat specifické texty v dokumentu je nesmírně cenná. Funkce "Najít a nahradit" v Google Dokumentech to usnadňuje a nabízí přidané pohodlí. S pomocí regulárních výrazů (RegEx) však můžete své vyhledávací schopnosti posunout na vyšší úroveň. RegEx představuje účinný nástroj, který využívá speciální sekvence znaků k nalezení textových vzorů, což umožňuje vyhledávání s mimořádnou přesností.
V Google Dokumentech můžete RegEx využít k upřesnění procesu vyhledávání. Zatímco standardní funkce "Najít" umožňuje hledat pouze přesně zadaný text, RegEx vám dovoluje definovat vzory a snadno nacházet složité sekvence textu.
Bohužel, Google Dokumenty v současnosti nepodporují nahrazování textu pomocí RegEx vzorů. To znamená, že ačkoli můžete RegEx použít k vyhledání konkrétních textových řetězců, nahradit je můžete pouze pevně definovaným textem.
Na rozdíl od Google Dokumentů nabízí Tabulky Google funkci REGEXREPLACE, která umožňuje vyhledávání a nahrazování textu pomocí RegEx, což z ní činí velmi efektivní nástroj pro
vyhledávání a nahrazování v Tabulkách Google
.
I přes toto omezení může RegEx v Google Dokumentech ušetřit velké množství času, zvláště při práci s rozsáhlými dokumenty. Možnost RegEx je ve výchozím nastavení neaktivní, a proto ji lze snadno přehlédnout. Jakmile se však s jejími možnostmi seznámíte, zjistíte, že je překvapivě snadná na používání a může se stát neocenitelnou součástí vašeho editačního nástroje.
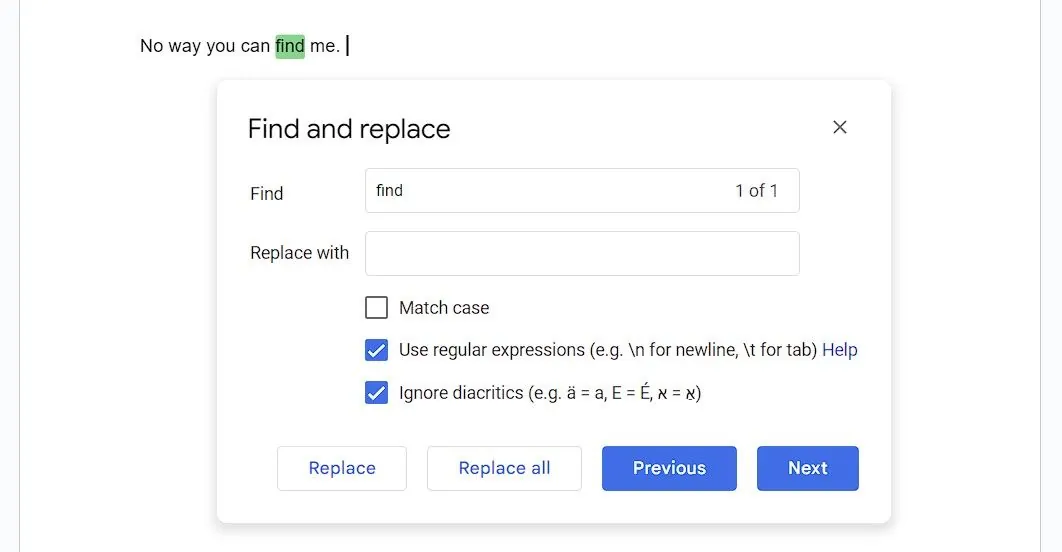
Chcete-li začít používat "Najít a nahradit" s RegEx v Google Dokumentech, stiskněte Ctrl/Cmd + F pro otevření nabídky "Najít". Poté klikněte na tři vertikální tečky pro otevření okna "Najít a nahradit". Zaškrtněte políčko "Použít regulární výrazy" a můžete začít.
Alternativně můžete okno "Najít a nahradit" otevřít pomocí jediné klávesové zkratky:
Ctrl + H
na Windows nebo
Cmd + Shift + H
na Mac.
Google Dokumenty používají syntaxi RE2 pro RegEx. Kompletního průvodce syntaxí naleznete na stránce GitHub RE2. Pokud s RegEx nemáte zkušenosti, následující příklady častého použití vám pomohou pochopit jeho princip.
Přesnější nahrazování slov
Jedním z běžných problémů standardní funkce "Najít a nahradit" je, že často nahrazuje slova i uvnitř jiných slov. Například, pokud chcete nahradit slovo "dům" slovem "byt", můžete omylem změnit slovo "domácí" na "bytecí" nebo "domov" na "bytov". To může vést k nežádoucím a nesprávným změnám.
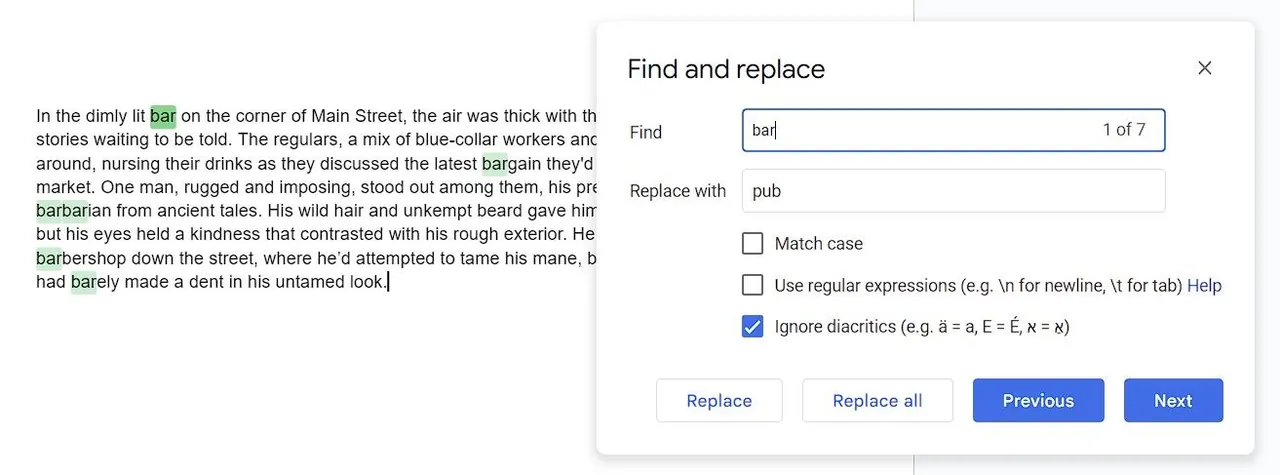
Zde přichází na řadu RegEx. S jeho pomocí můžete definovat, že chcete najít pouze konkrétní slovo "dům" a nikoli případy, kde je "dům" součástí delšího slova. V RegEx syntaxi RE2 \b označuje hranici slova, čímž zajistíte, že vyhledávání se omezí pouze na samotné slovo, bez vlivu na jiná slova, která obsahují stejné znaky.
Pro tento příklad následující sekvence najde pouze slovo "dům":
\b(dům)\b
Když tuto sekvenci zadáte, můžete do pole "Nahradit čím" zadat "byt" a s jistotou kliknout na "Nahradit vše", vědomi si, že budou nahrazeny pouze přesné výskyty slova "dům".
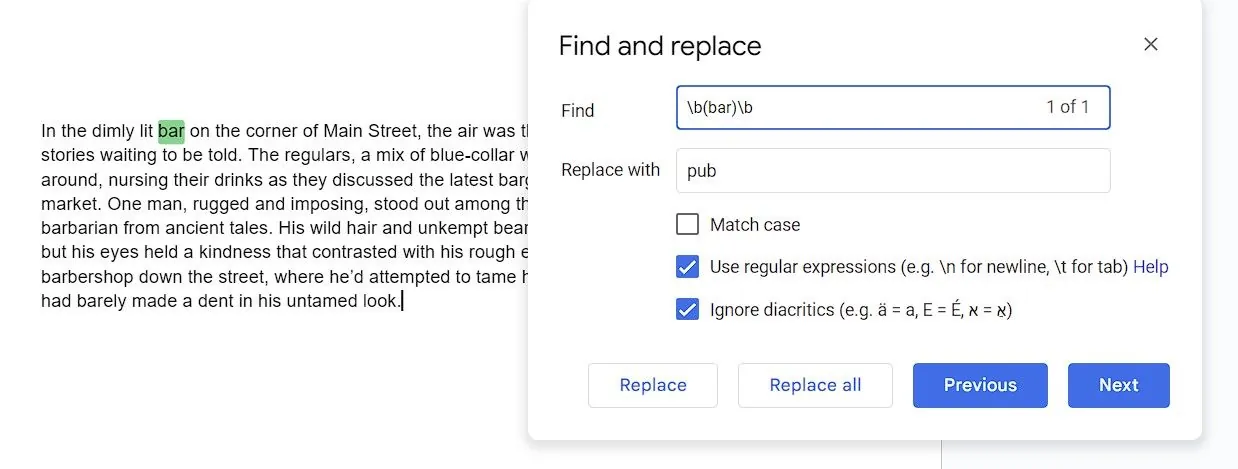
Odstranění čísel citací
Odborné články často obsahují čísla citací, které informují čtenáře o původu informací a potvrzují jejich věrohodnost. Pokud však citujete z webové stránky, nemusí být tato čísla citací nutná, protože váš text nebude obsahovat rozsáhlý seznam referencí. V takových případech mohou čísla citací text rušit a snižovat jeho čitelnost.
S pomocí RegEx můžete rychle odstranit tato čísla citací v Google Dokumentech a ponechat pouze potřebný text. Příklad textu:

Odstraňování čísel citací a závorek jednotlivě by bylo zdlouhavé. Nicméně, následující RegEx sekvence dokáže najít všechna čísla citací najednou:
\[\d+\]
\d+ znamená, že hledáme jednu nebo více číslic a závorky ([ ]) určují, že číslice budou uvnitř závorek. Poté ponechte pole "Nahradit čím" prázdné a klikněte na "Nahradit vše" pro smazání čísel citací.
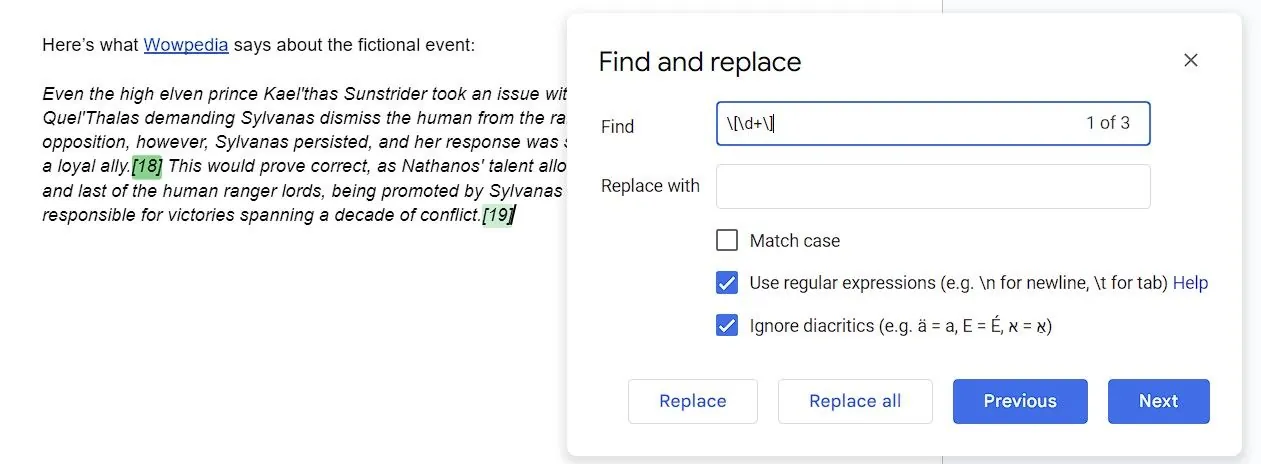
Nalezení duplicitních slov
Duplicitní slova se v našem textu objevují poměrně často, zvláště po úpravách. Náš mozek má tendenci je automaticky přehlížet, což ztěžuje jejich odhalení při korekturách. I když kvalitní gramatická kontrola může zachytit duplicitní slova, můžete k jejich nalezení využít také RegEx v Google Dokumentech.
Jednou z užitečných funkcí RegEx je zpětný odkaz, který umožňuje sekvenci zapamatovat si, co nalezla. Toho lze využít k nalezení duplicitních po sobě jdoucích slov s následující RegEx sekvencí:
\b(\w+)\s+\1\b
Výše uvedený kód označuje hranice slova s \b, slovo samotné pomocí \w+ a umisťuje toto slovo do závorek, čímž vytvoří zachycenou skupinu, na kterou se lze později odkazovat. \s+ představuje jeden nebo více znaků mezery a \1 je zpětný odkaz na první zachycenou skupinu (samotné slovo).
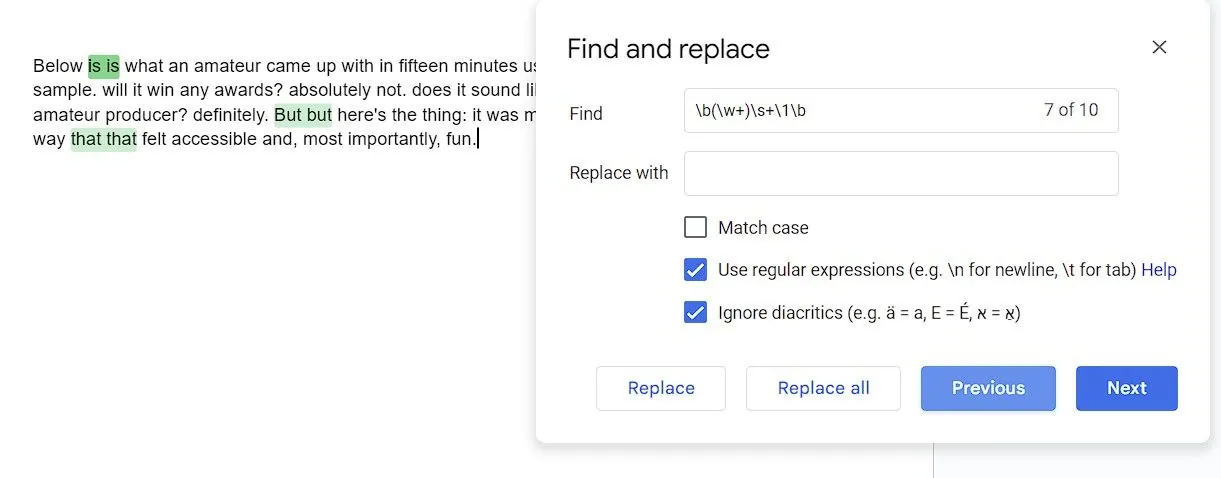
Zjednodušeně řečeno, RegEx sekvence hledá slovo, následované mezerou a poté toto samé slovo znovu. Efektivně tak zvýrazní všechna duplicitní slova v dokumentu.
Pokud by Google Dokumenty podporovaly RegEx i pro nahrazování, bylo by možné odstranit všechna duplicitní slova najednou. V současnosti je nutné každé duplicitní slovo najít pomocí RegEx a poté jej odstranit individuálně.
Úprava webových odkazů
Webové adresy (URL) často obsahují zbytečné sledovací parametry, které je prodlužují a snižují jejich estetickou hodnotu. Tyto parametry obvykle pomáhají webové stránce sledovat informace, jako je způsob, jakým jste stránku objevili, zda jste přihlášeni a další. I když s tímto sledováním můžete souhlasit, tyto parametry dělají URL zbytečně dlouhými.

RegEx může pomoci vyčistit tyto URL odstraněním všeho, co následuje za otazníkem, což je obvyklé místo, kde sledovací parametry začínají:
\?(.+)
Sekvence začíná otazníkem. Tečka (.) značí jakýkoli znak a plus (+) značí jeden nebo více výskytů předchozího prvku (v tomto případě jakéhokoli znaku). Ačkoli tato RegEx sekvence úspěšně zvýrazní nepotřebné parametry v URL, má drobný problém: pokud máte větu s otazníkem pro interpunkci, sekvence jej také označí.
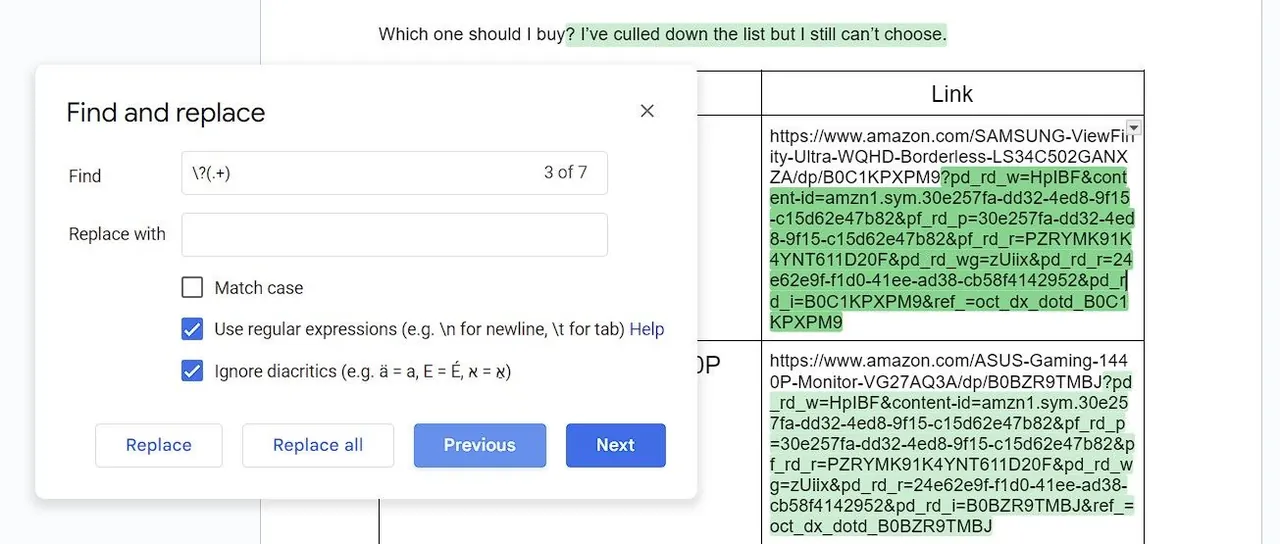
Pro vyřešení tohoto problému můžete RegEx sekvenci upravit:
\?(?!\s)(.+)
V této sekvenci ?! představuje negativní look-ahead aserci, která zajistí, že znak následující bezprostředně za otazníkem není bílé místo (\s). Tím se vyloučí skutečné otázky z nalezeného vzoru.
Nyní můžete bez obav odstranit nadbytečné parametry z URL tím, že je nahradíte prázdným řetězcem. S upravenými URL bude text přehlednější:

Nezapomeňte zkontrolovat upravené URL, abyste ověřili, že stále fungují!
Tyto příklady jsou jen malým náhledem na možnosti, které RegEx v Google Dokumentech nabízí. I když se na první pohled mohou zdát složité, RegEx jsou poměrně jednoduché, jakmile se s nimi seznámíte. Začněte experimentovat a brzy zjistíte, kolik času a úsilí vám RegEx mohou ušetřit.
