Základy a pokročilé techniky inženýrství funkcí pro strojové učení
Chcete proniknout do tajů inženýrství funkcí pro strojové učení a datovou vědu? Jste na správné adrese! Tento článek vám krok za krokem vysvětlí, co je to inženýrství funkcí a jak ho efektivně využívat. Pusťme se do toho a začněte objevovat svět extrakce užitečných datových prvků!
Co vlastně je Feature Engineering?
Při vytváření modelů strojového učení, ať už pro obchodní nebo experimentální účely, pracujete s daty uspořádanými do sloupců a řádků. V datové vědě a ML se sloupce označují jako atributy nebo proměnné. Jednotlivé řádky v tabulce se nazývají pozorování nebo instance. Sloupce, tedy atributy, jsou v surové datové sadě považovány za „features“ (funkce).
Nicméně tyto surové funkce často nejsou optimální pro trénování modelů. Inženýrství funkcí se zaměřuje na transformaci a úpravu těchto sloupců s metadaty do podoby funkčních prvků, které minimalizují šum a maximalizují unikátní signály. Tím se zlepší kvalita trénovacích dat.
Příklad 1: Finanční modelování
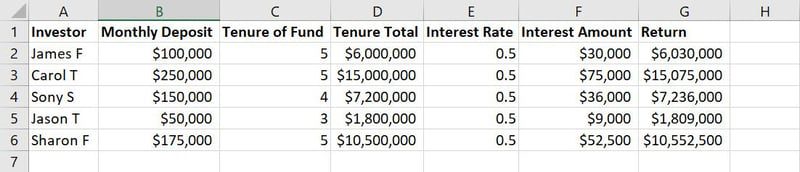
Na výše uvedeném obrázku jsou sloupce A až G funkcemi. Hodnoty a textové řetězce v těchto sloupcích, například jména, výše vkladu, roky vkladu a úrokové sazby, představují pozorování. Při modelování pomocí strojového učení se provádí úprava, kombinace a transformace dat, aby se vytvořily relevantní a významné funkce a zmenšila se celková databáze potřebná k tréninku modelu. Tento proces se označuje jako inženýrství funkcí.
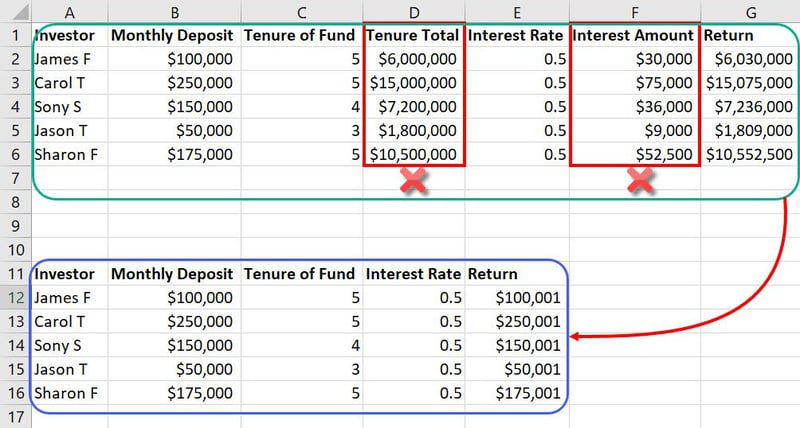
V původním datovém souboru mohou být funkce jako „Celková držba“ a „Výše úroku“ zbytečné, jelikož zatěžují tréninkový model zbytečnými daty. Můžeme je tedy odstranit, čímž snížíme celkový počet funkcí z původních sedmi. Při práci s modely ML, které zpracovávají tisíce sloupců a miliony řádků, i omezení počtu o dvě funkce může mít velký dopad na efektivitu celého projektu.
Příklad 2: AI pro vytváření hudebních playlistů
Někdy je možné z několika existujících funkcí vytvořit zcela novou. Představte si, že vyvíjíte AI, která bude automaticky sestavovat playlisty na základě událostí, preferencí a nálad uživatelů.
Po shromáždění dat o skladbách a hudbě z různých zdrojů vznikne následující databáze:
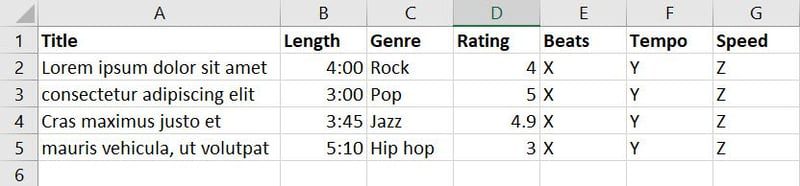
Tato databáze obsahuje sedm funkcí. Pro trénování modelu ML, který má rozhodovat o vhodnosti písně pro danou událost, můžete například zkombinovat žánr, hodnocení, beaty, tempo a rychlost do nové funkce nazvané „Použitelnost“.
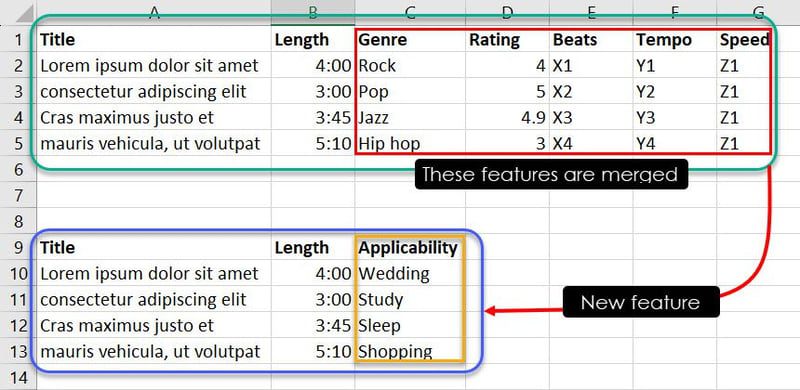
Na základě odborných znalostí nebo identifikovaných vzorů lze kombinací specifických hodnot určit, která píseň je vhodná pro jakou událost. Například kombinace hodnot „Jazz“, „4.9“, „X3“, „Y3“ a „Z1“ může modelu napovědět, že skladba „Cras maximus justo et“ je vhodná do playlistu pro poslech před spaním.
Typy funkcí ve strojovém učení
Kategorické vlastnosti
Tento typ datových atributů slouží k reprezentaci odlišných kategorií nebo štítků a používá se pro kvalitativní datové sady.
1. Řadové kategorické rysy
Řadové rysy mají kategorie, které jsou seřazeny podle významu. Příkladem jsou úrovně vzdělání, jako je středoškolské, bakalářské a magisterské. Mezi nimi existují zřetelné rozdíly v úrovni, ale ne kvantitativní.
2. Nominální kategorické vlastnosti
Nominální rysy jsou kategorie bez inherentního pořadí. Příkladem jsou barvy, země nebo druhy zvířat. Rozdíly jsou pouze kvalitativní.
Vlastnosti pole
Data organizovaná v polích nebo seznamech. Datoví vědci a vývojáři ML je často využívají pro zpracování sekvencí nebo vkládání kategorických dat.
1. Funkce pole vkládání
Vkládaná pole transformují kategorická data na husté vektory. Běžně se používají v systémech zpracování přirozeného jazyka a doporučení.
2. Seznam funkcí pole
Pole seznamů ukládají sekvence dat, například seznamy položek v objednávce nebo historii akcí.
Číselné vlastnosti
Používají se pro provádění matematických operací, protože reprezentují kvantitativní data.
1. Intervalové číselné funkce
Mají konzistentní intervaly mezi hodnotami, ale nemají skutečný nulový bod (např. data z monitorování teploty). Nula zde označuje bod mrazu, ale atribut v daném místě stále existuje.
2. Poměrové číselné znaky
Mají konzistentní intervaly mezi hodnotami a také skutečný nulový bod. Příkladem jsou věk, výška a příjem.
Význam inženýrství funkcí v ML a datové vědě
- Efektivní extrakce funkcí zvyšuje přesnost modelů a tím i spolehlivost předpovědí, což přináší hodnotu pro rozhodování.
- Pečlivý výběr funkcí eliminuje irelevantní a nadbytečné atributy, zjednodušuje modely a šetří výpočetní zdroje.
- Dobře navržené funkce odhalují datové vzorce a pomáhají datovým vědcům porozumět komplexním vztahům v datové sadě.
- Přizpůsobení funkcí konkrétním algoritmům optimalizuje výkon modelu napříč různými metodami strojového učení.
- Kvalitní funkce vedou k rychlejšímu trénování modelů a nižším nákladům na výpočetní techniku.
Následně prozkoumáme proces inženýrství funkcí krok za krokem.
Proces konstrukčního inženýrství krok za krokem

- Sběr dat: Prvním krokem je získávání dat z různých zdrojů, jako jsou databáze, soubory nebo API.
- Čištění dat: Získaná data je třeba vyčistit, identifikovat a opravit chyby, nesrovnalosti nebo odlehlé hodnoty.
- Zpracování chybějících hodnot: Chybějící hodnoty mohou negativně ovlivnit model ML, proto je třeba je doplnit nebo je opatrně odstranit, aby nedošlo ke zkreslení.
- Kódování kategorických proměnných: Kategorické proměnné je nutné převést do numerického formátu, který je vhodný pro algoritmy strojového učení.
- Škálování a normalizace: Škálování zajišťuje, že numerické prvky jsou v konzistentním měřítku, aby nedominovaly funkce s vysokými hodnotami.
- Výběr funkcí: Identifikace a zachování nejrelevantnějších funkcí, snížení rozměru a zlepšení efektivity modelu.
- Vytváření funkcí: Generování nových funkcí ze stávajících, abyste získali cenné informace.
- Transformace funkcí: Použití transformačních technik (např. logaritmy nebo mocninné transformace) k optimalizaci dat pro modelování.
Následně se podíváme na různé metody inženýrství funkcí.
Metody konstrukčního inženýrství
1. Analýza hlavních komponent (PCA)
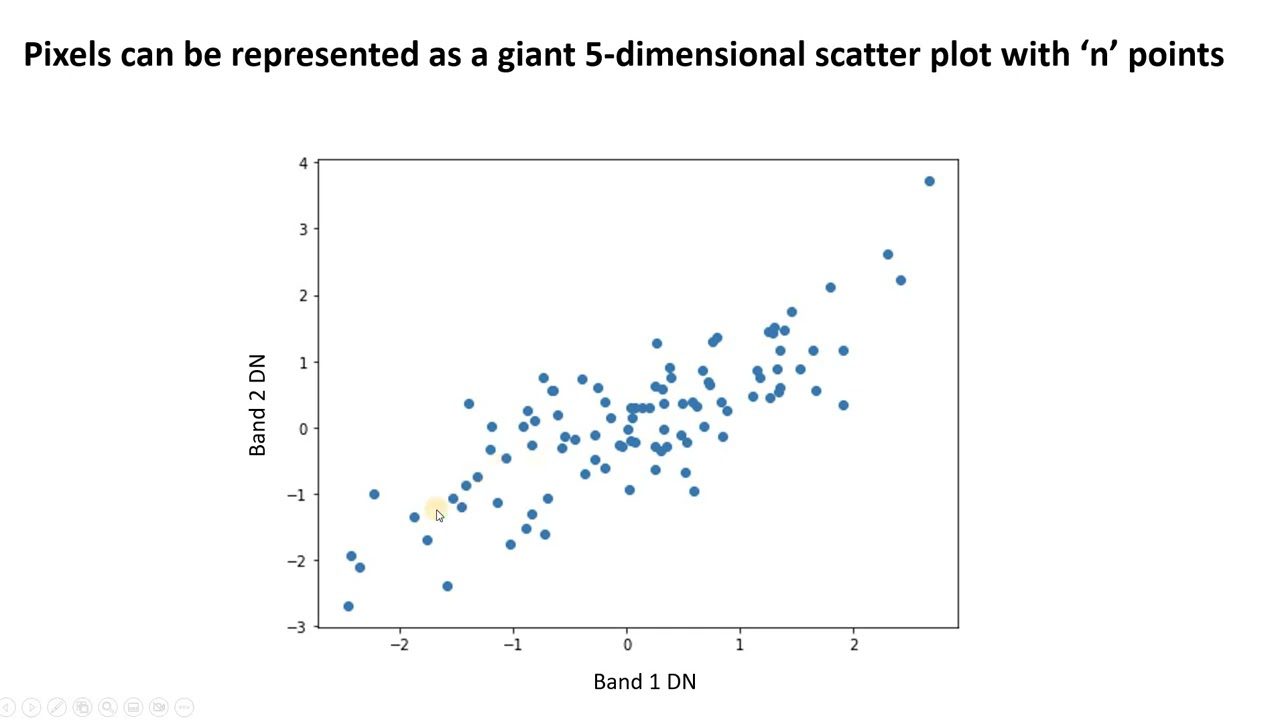
PCA zjednodušuje složitá data nalezením nových nekorelovaných funkcí, které se nazývají hlavní komponenty. Lze ji použít ke snížení rozměrů a zlepšení výkonu modelu.
2. Polynomiální vlastnosti
Vytváření polynomiálních prvků přidává možnosti existujícím prvkům a zachycuje složité vztahy v datech. Pomáhá modelu porozumět nelineárním vzorům.
3. Manipulace s odlehlými hodnotami
Odlehlé hodnoty jsou neobvyklé datové body, které mohou ovlivnit výkon modelů. Identifikací a správou odlehlých hodnot zabráníte zkresleným výsledkům.
4. Log Transform
Logaritmická transformace normalizuje data se zkresleným rozdělením a snižuje dopad extrémních hodnot, čímž je připraví pro modelování.
5. t-Distributed Stochastic Neighbor Embedding (t-SNE)
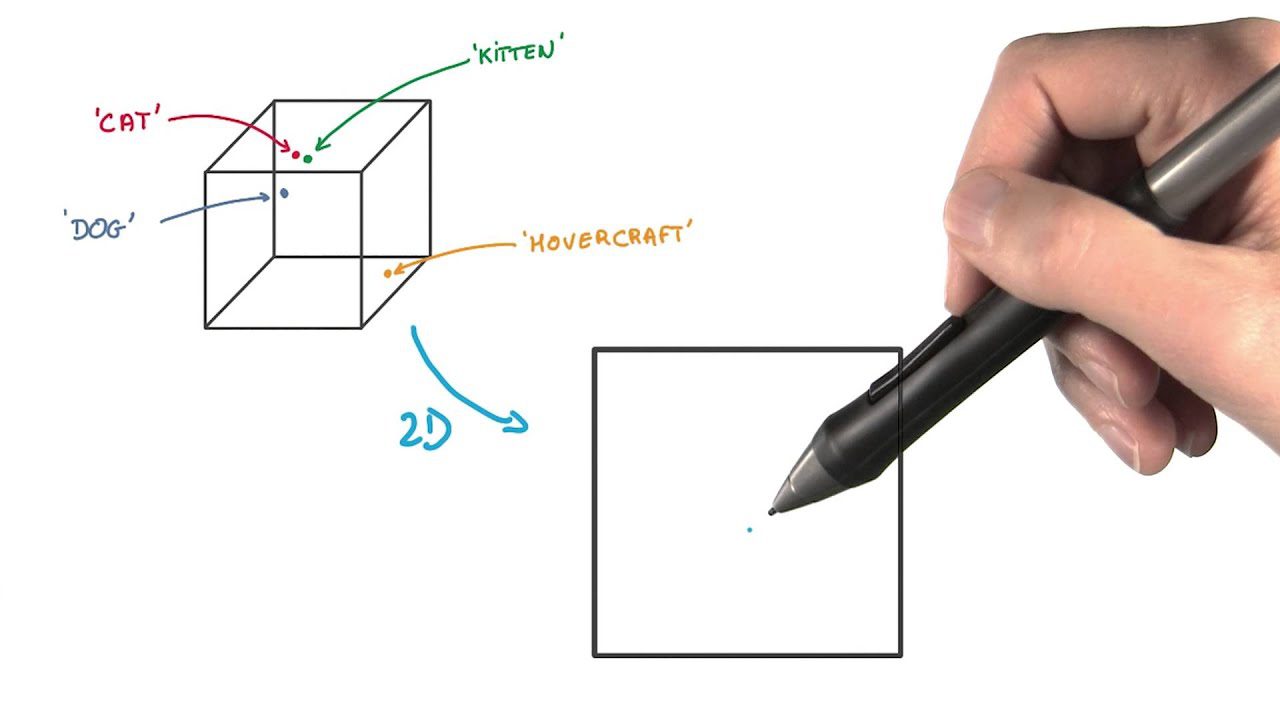
t-SNE je užitečné pro vizualizaci vysoce rozměrných dat. Snižuje rozměrnost, usnadňuje zobrazení shluků dat a zachovává strukturu dat.
V této metodě extrakce prvků jsou datové body reprezentovány jako tečky v prostoru nižší dimenze. Podobné datové body v původním vysoce rozměrném prostoru jsou v reprezentaci nižší dimenze blízko sebe.
Od ostatních metod redukce rozměrů se liší zachováním struktury a vzdáleností mezi datovými body.
6. One-Hot Encoding
One-hot encoding transformuje kategorické proměnné do binárního formátu (0 nebo 1). Získáte tak nové binární sloupce pro každou kategorii. Díky tomu jsou kategorická data vhodná pro algoritmy ML.
7. Kódování počtu
Kódování počtu nahrazuje kategorické hodnoty počtem jejich výskytů v datové sadě. Tímto způsobem lze zachytit cenné informace z kategorických proměnných.
Tato metoda inženýrství prvků používá frekvenci nebo počet výskytů každé kategorie jako nový číselný prvek namísto původních štítků kategorií.
8. Standardizace funkcí

Funkce s vyššími hodnotami mohou dominovat funkcím s nižšími hodnotami, což může způsobit zkreslení ML modelu. Standardizace zabraňuje takovému zkreslení.
Proces standardizace obvykle zahrnuje dvě techniky:
- Standardizace Z-skóre: Transformuje každý prvek tak, aby měl průměr 0 a směrodatnou odchylku 1. Od každého datového bodu se odečte průměr a výsledek se vydělí směrodatnou odchylkou.
- Minimální a maximální škálování: Transformuje data do určitého rozsahu, obvykle mezi 0 a 1. Dosáhne se toho odečtením minimální hodnoty prvku od každého datového bodu a vydělením rozsahem.
9. Normalizace
Prostřednictvím normalizace jsou číselné rysy škálovány do společného rozsahu, obvykle mezi 0 a 1. Zachovává relativní rozdíly mezi hodnotami a zajišťuje, že všechny prvky jsou rovnocenné.

1. Featuretools
Featuretools je open-source framework v Pythonu, který automaticky vytváří funkce z časových a relačních datových sad. Může být použit s nástroji, které již používáte pro vývoj ML. Využívá Deep Feature Synthesis pro automatizaci návrhu funkcí a má knihovnu nízkoúrovňových funkcí pro vytváření funkcí. API Featuretools je vhodné pro přesné zacházení s časem.
2. CatBoost
Pokud hledáte open-source knihovnu, která kombinuje více rozhodovacích stromů a vytváří výkonný prediktivní model, CatBoost je ideální volbou. Nabízí přesné výsledky s výchozími parametry, takže nemusíte trávit hodiny laděním. Umožňuje také používat nečíselné faktory pro zlepšení výsledků trénování a nabízí rychlé a přesné předpovědi.
3. Feature-Engine
Feature-Engine je knihovna v Pythonu s transformátory a vybranými funkcemi pro modely ML. Obsahuje transformátory pro úpravu proměnných, vytváření nových proměnných, práci s datem a časem, předzpracování dat, kategorické kódování, omezení nebo odstranění odlehlých hodnot a imputaci chybějících dat. Automaticky rozpoznává číselné, kategorické a datumové proměnné.
Výukové zdroje funkce Feature Engineering
Online kurzy a virtuální kurzy

1. Feature Engineering pro strojové učení v Pythonu: Datacamp
Tento kurz na Datacampu vás naučí, jak vytvářet nové funkce pro zlepšení výkonu modelů ML. Získáte znalosti o provádění inženýrství funkcí a získávání dat pro vývoj sofistikovaných aplikací ML.
2. Feature Engineering pro strojové učení: Udemy
V kurzu Feature Engineering for Machine Learning na Udemy se naučíte témata jako imputace, kódování proměnných, extrakce funkcí, diskretizace, funkce data a času, odlehlé hodnoty, a práce se zkreslenými proměnnými. Také se dozvíte, jak pracovat s řídkými, neviditelnými a vzácnými kategoriemi.
3. Feature: Pluralsight
Výuková cesta na Pluralsight má šest kurzů, které vás naučí význam inženýrství funkcí, způsoby jeho využití a extrakci funkcí z textu a obrázků.
4. Výběr funkcí pro strojové učení: Udemy
V kurzu na Udemy se naučíte míchání funkcí, filtrování, obálkování a vkládání metod, rekurzivní eliminaci funkcí a vyčerpávající vyhledávání. Kurz také pojednává o technikách výběru funkcí pomocí Pythonu, Lasu a rozhodovacích stromů a obsahuje 5,5 hodin videa na vyžádání a 22 článků.
5. Feature Engineering pro strojové učení: Skvělé učení
Tento kurz od Great Learning vás seznámí s inženýrstvím funkcí a naučí o nadměrném a nedostatečném vzorkování. Dále vám umožní provádět praktická cvičení na ladění modelu.
6. Feature: Coursera
Připojte se ke kurzu na Coursera a naučte se používat BigQuery ML, Keras a TensorFlow pro inženýrství funkcí. Tento středně pokročilý kurz zahrnuje také pokročilé techniky.
Digitální nebo vázané knihy

1. Feature Engineering pro strojové učení
Tato kniha vás naučí, jak transformovat funkce do formátů pro modely strojového učení a vysvětluje technické principy a praktické aplikace s cvičeními.
2. Feature Engineering a výběr
V této knize se naučíte metody vývoje prediktivních modelů v různých fázích a techniky pro nalezení nejlepších reprezentací prediktorů pro modelování.
3. Snadné inženýrství funkcí
Kniha je průvodce pro zvýšení prediktivní schopnosti algoritmů ML. Naučí vás navrhovat a vytvářet efektivní funkce pro aplikace založené na ML tím, že nabízí hloubkový přehled dat.
4. Feature Engineering Bookcamp
Tato kniha se zabývá praktickými případovými studiemi, které vás naučí technikám funkčního inženýrství pro lepší výsledky ML a vylepšené souboje s daty. Díky ní budete moci dosáhnout lepších výsledků, aniž byste strávili mnoho času dolaďováním parametrů ML.
5. The Art of Feature Engineering
Tento zdroj slouží jako základní prvek pro každého datového vědce nebo inženýra strojového učení. Kniha používá přístup napříč doménami k diskuzi o grafech, textech, časových řadách, obrázcích a případových studiích.
Závěr
V tomto článku jsme si rozebrali, co je inženýrství funkcí. Nyní, když znáte definici, postupný proces, metody a výukové zdroje, můžete je implementovat do svých projektů ML a dosáhnout úspěchu!
Dále se podívejte na článek o posilování.