Klíčové body
- Zobecnění je klíčové pro efektivní hluboké učení, jelikož zajišťuje přesné predikce i s neznámými daty. Učení s nulovým počtem příkladů (zero-shot learning) to umožňuje tím, že umělá inteligence využívá již získané znalosti k přesnému odhadování výsledků i pro dosud neviděné kategorie bez nutnosti označených dat.
- Zero-shot learning se inspiruje lidským učením a zpracováním informací. Díky doplňkovým sémantickým datům je model schopen rozpoznat nové kategorie, podobně jako člověk dokáže identifikovat kytaru s dutým tělem, když rozumí jejím specifickým charakteristikám.
- Zero-shot learning zlepšuje AI díky efektivnějšímu zobecňování, škálovatelnosti, snížení přetrénování a ekonomické efektivitě. Umožňuje trénovat modely na rozsáhlých datových souborech, získávat více informací pomocí transfer learningu, lépe chápat kontext a omezuje potřebu velkých objemů označených dat. S vývojem umělé inteligence bude význam zero-shot learningu v řešení náročných problémů v různých oborech narůstat.
Jedním z primárních cílů hlubokého učení je vyvinout modely se schopností zobecňovat poznatky. Zobecnění je zásadní, neboť model díky němu dokáže rozpoznávat smysluplné vztahy a generovat přesné predikce či rozhodnutí i v případě, že se setká s neznámými daty. Pro trénování takových modelů je typicky potřeba velké množství označených dat, což může být nákladné, časově náročné a někdy i prakticky nemožné.
Právě zde nastupuje zero-shot learning, který umožňuje AI využívat existující znalosti k vytváření poměrně přesných odhadů i bez dostatku označených dat.
Co je to Zero-Shot Learning?
Zero-shot learning je specifická forma transfer learningu. Zaměřuje se na to, jak využít již trénovaný model k identifikaci nových kategorií, které dosud neviděl, a to tak, že mu poskytneme doplňující informace o tom, jak nové kategorie charakterizovat.
Díky tomu, že model disponuje všeobecnými znalostmi o určitých tématech a že mu poskytneme další sémantické informace, dokáže poměrně přesně určit, jaký objekt má za úkol rozpoznat.
Představme si, že potřebujeme rozpoznávat zebry, avšak nemáme model, který by se na ně specializoval. Místo toho využijeme existující model, který se učí rozpoznávat koně, a řekneme mu, že koně s černými a bílými pruhy jsou zebry. Pokud následně modelu předložíme obrázky zeber a koní, je velmi pravděpodobné, že je správně identifikuje.
Stejně jako mnoho technik hlubokého učení, i zero-shot learning se inspiruje tím, jak lidé učí a zpracovávají informace. Lidské učení je přirozeně „zero-shot“. Pokud byste měli za úkol najít v obchodě s hudebními nástroji kytaru s dutým tělem, mohli byste mít problém. Ale jakmile se dozvíte, že kytara s dutým tělem má na jedné nebo obou stranách otvor ve tvaru písmene F, pravděpodobně ji okamžitě najdete.
Podívejme se na praktický příklad klasifikační aplikace využívající zero-shot learning, kterou nabízí open source hostitelský web LLM Hugging Face, a to pomocí modelu clip-vit-large.
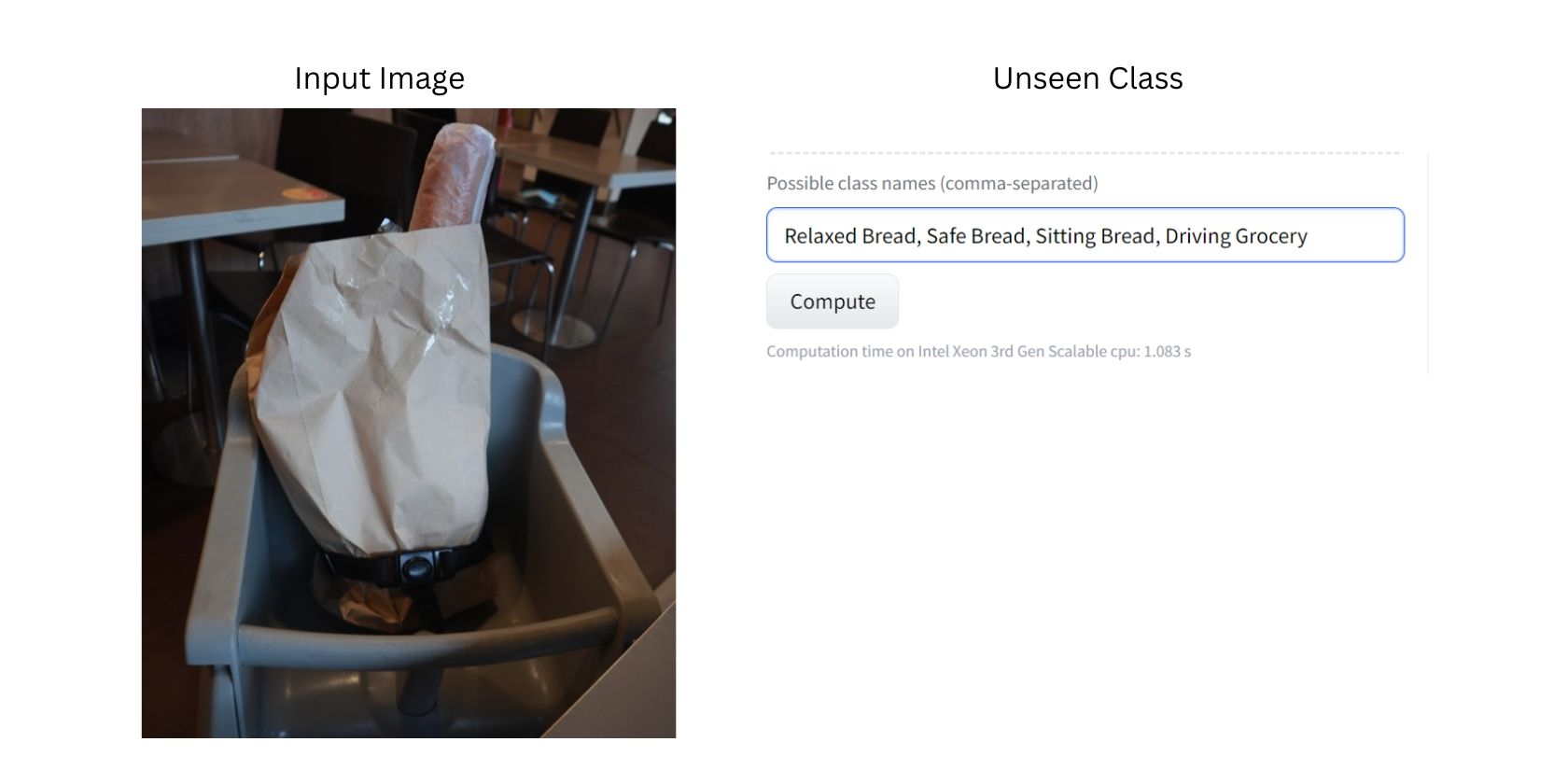
Na fotografii je chléb v nákupní tašce, která je připevněna k dětské židličce. Vzhledem k tomu, že model byl trénován na rozsáhlé databázi obrázků, pravděpodobně dokáže rozpoznat jednotlivé objekty na snímku, jako je chléb, nákupní taška, židle a bezpečnostní pásy.
Nyní chceme, aby model klasifikoval tento obrázek pomocí kategorií, které dosud neviděl. V tomto případě by to byly kategorie „Uvolněný chléb“, „Bezpečný chléb“, „Chléb na sezení“, „Nákup potravin“ a „Bezpečné nakupování potravin“.
Všimněte si, že jsme úmyslně použili neobvyklé kategorie, aby bylo lépe vidět, jak zero-shot klasifikace funguje.
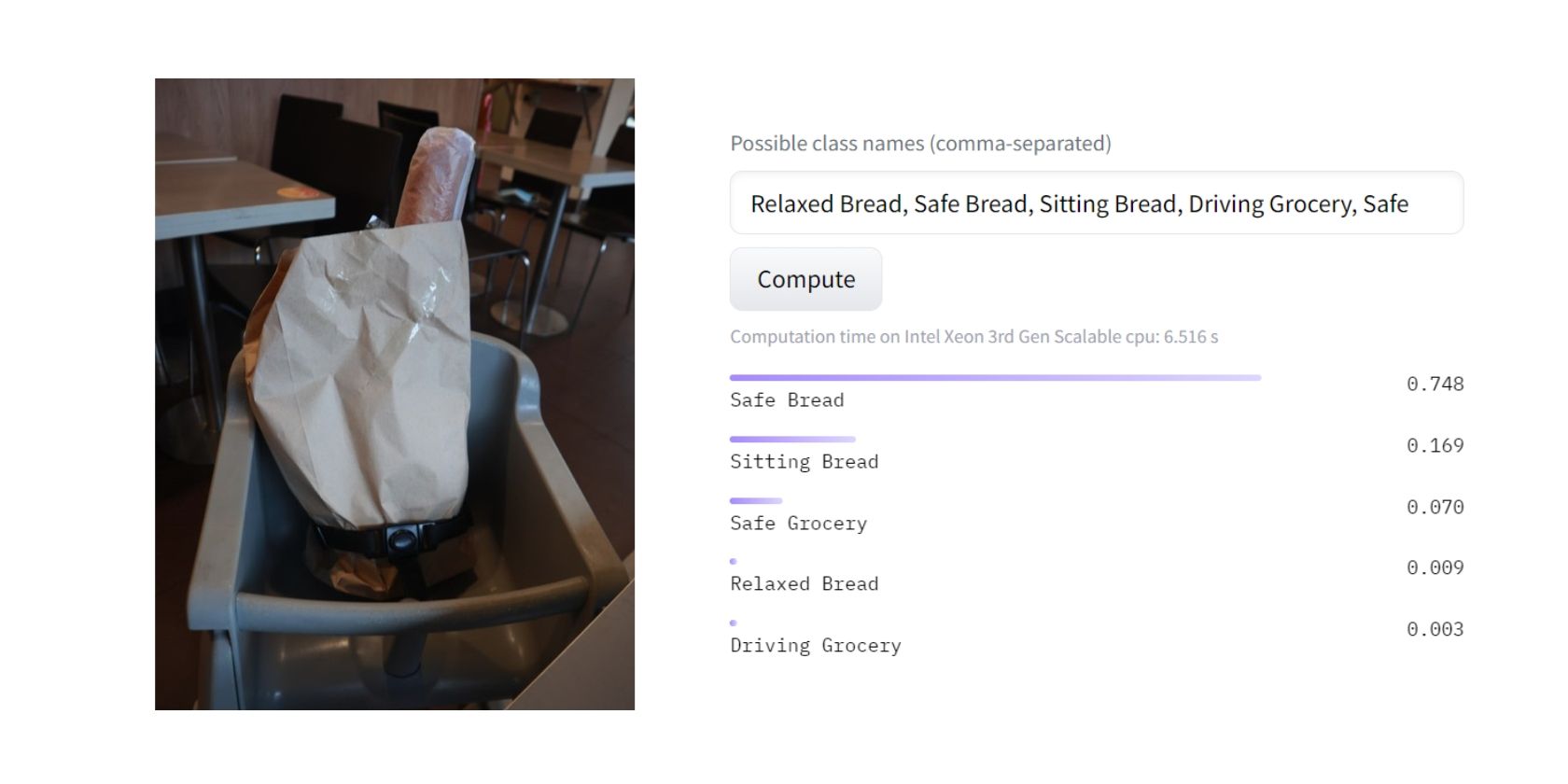
Po zpracování modelu dokázal s přibližně 80% jistotou klasifikovat, že nejvhodnější kategorie pro tento obrázek je „Bezpečný chléb“. Model pravděpodobně usoudil, že židle je zde spíše z bezpečnostních důvodů, než pro sezení, relaxaci nebo nákup.
Výborně! S tímto výsledkem bych osobně souhlasil. Ale jak přesně k tomuto výsledku model dospěl? Zde je obecný pohled na to, jak zero-shot learning funguje.
Jak funguje Zero-Shot učení
Zero-shot learning umožňuje předem trénovanému modelu identifikovat nové kategorie bez použití označených dat. V nejzákladnější podobě se zero-shot learning provádí ve třech krocích:
1. Příprava
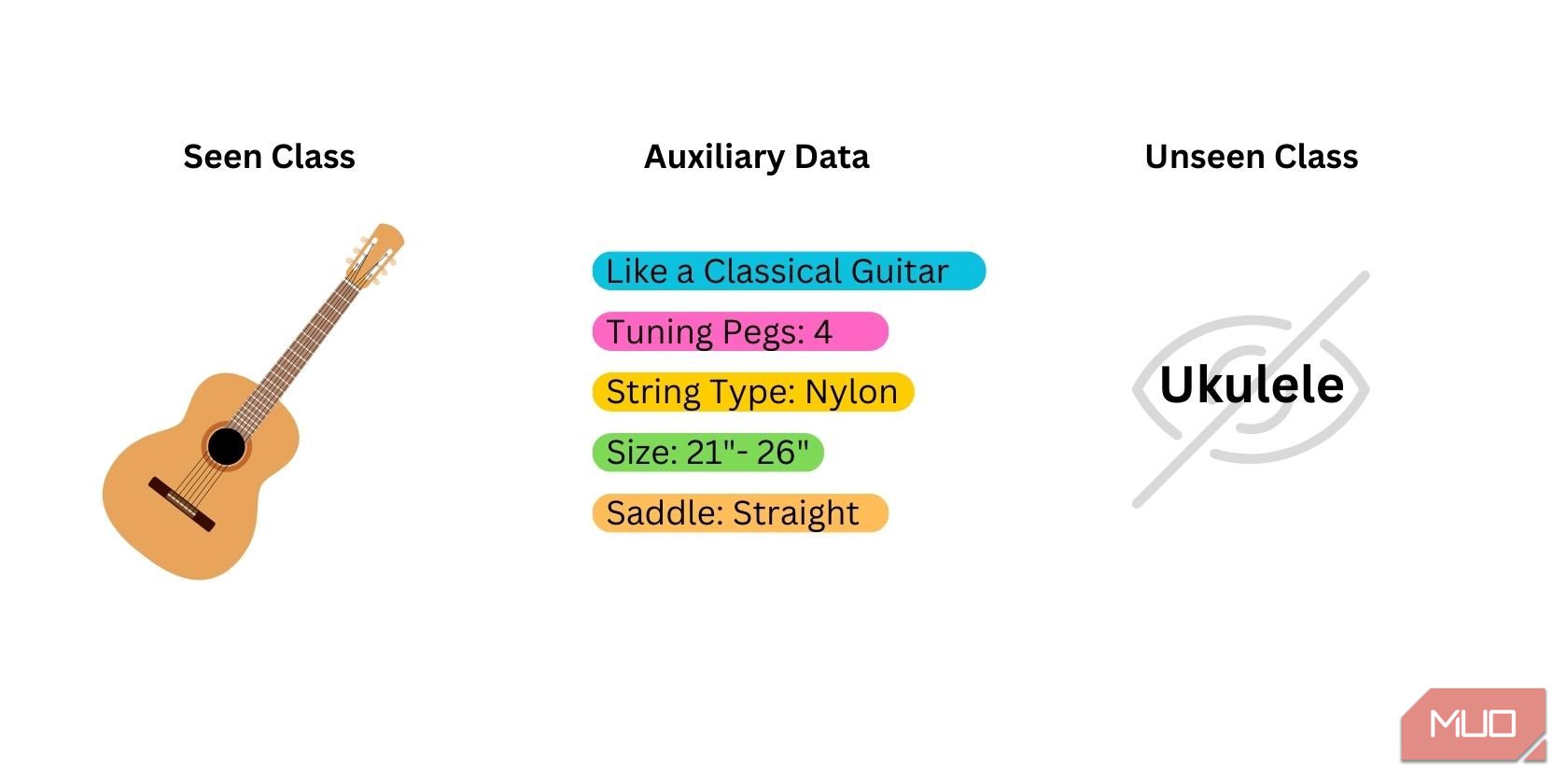
Zero-shot learning začíná přípravou tří typů dat:
- Viděné třídy: Data, která byla použita při trénování předem trénovaného modelu. Model s těmito třídami již disponuje. Nejlepší modely pro zero-shot learning jsou ty, které byly trénovány na kategoriích, které úzce souvisejí s novou kategorií, kterou chcete, aby model identifikoval.
- Neviděné/nové třídy: Data, která nikdy nebyla použita při trénování modelu. Tato data musíte připravit sami, protože je nelze získat z modelu.
- Sémantická/pomocná data: Další data, která mohou modelu pomoci identifikovat novou kategorii. Může se jednat o slova, fráze, vložená slova nebo názvy kategorií.
2. Sémantické mapování
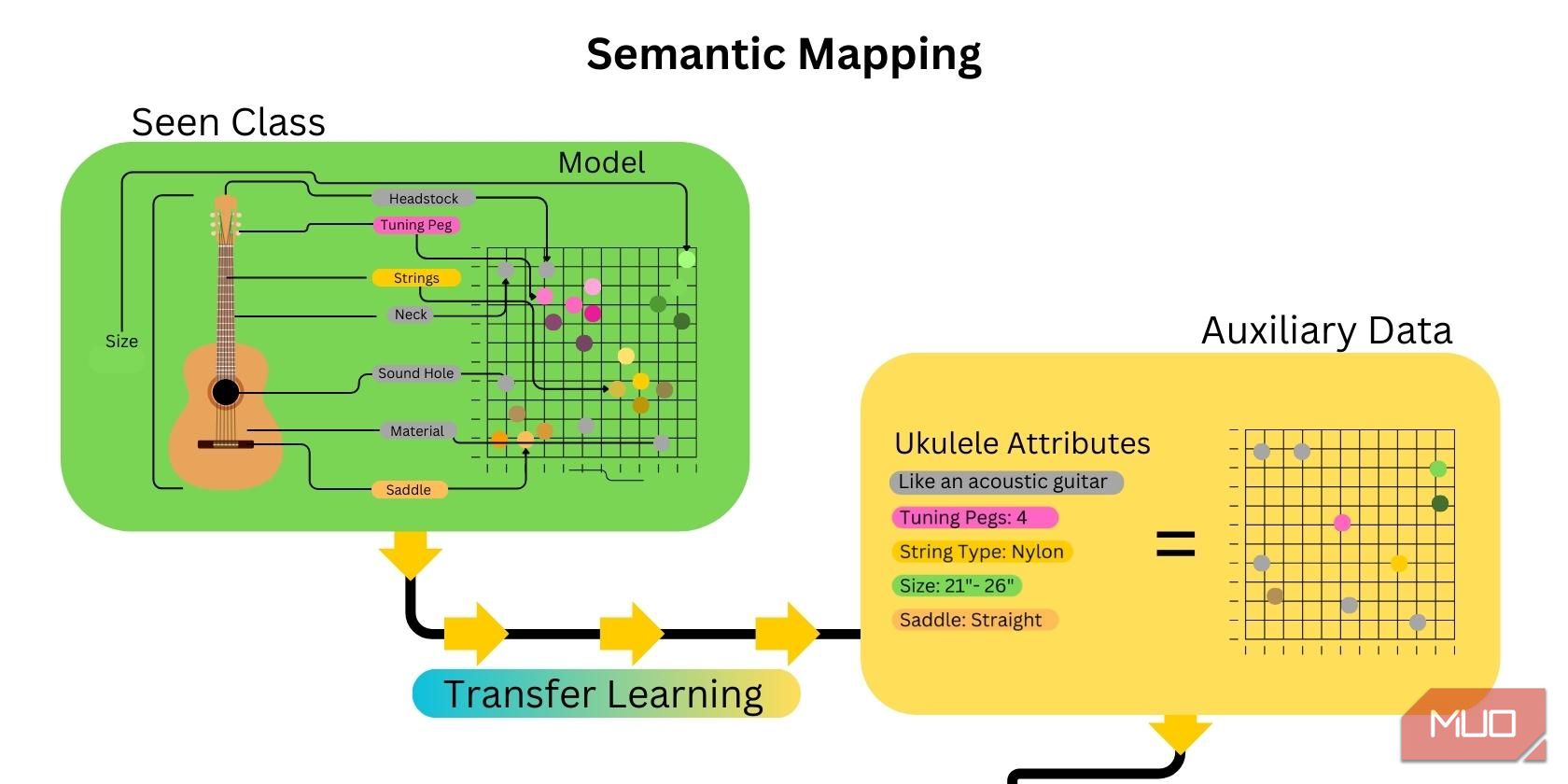
Dalším krokem je mapování charakteristik neviditelné kategorie. Provádí se vytvořením vložení slov a vytvořením sémantické mapy, která propojuje atributy nebo charakteristiky neviditelné kategorie s dodanými pomocnými daty. Transfer learning v AI tento proces výrazně urychluje, protože mnoho atributů souvisejících s neviditelnou kategorií již bylo namapováno.
3. Odvozování
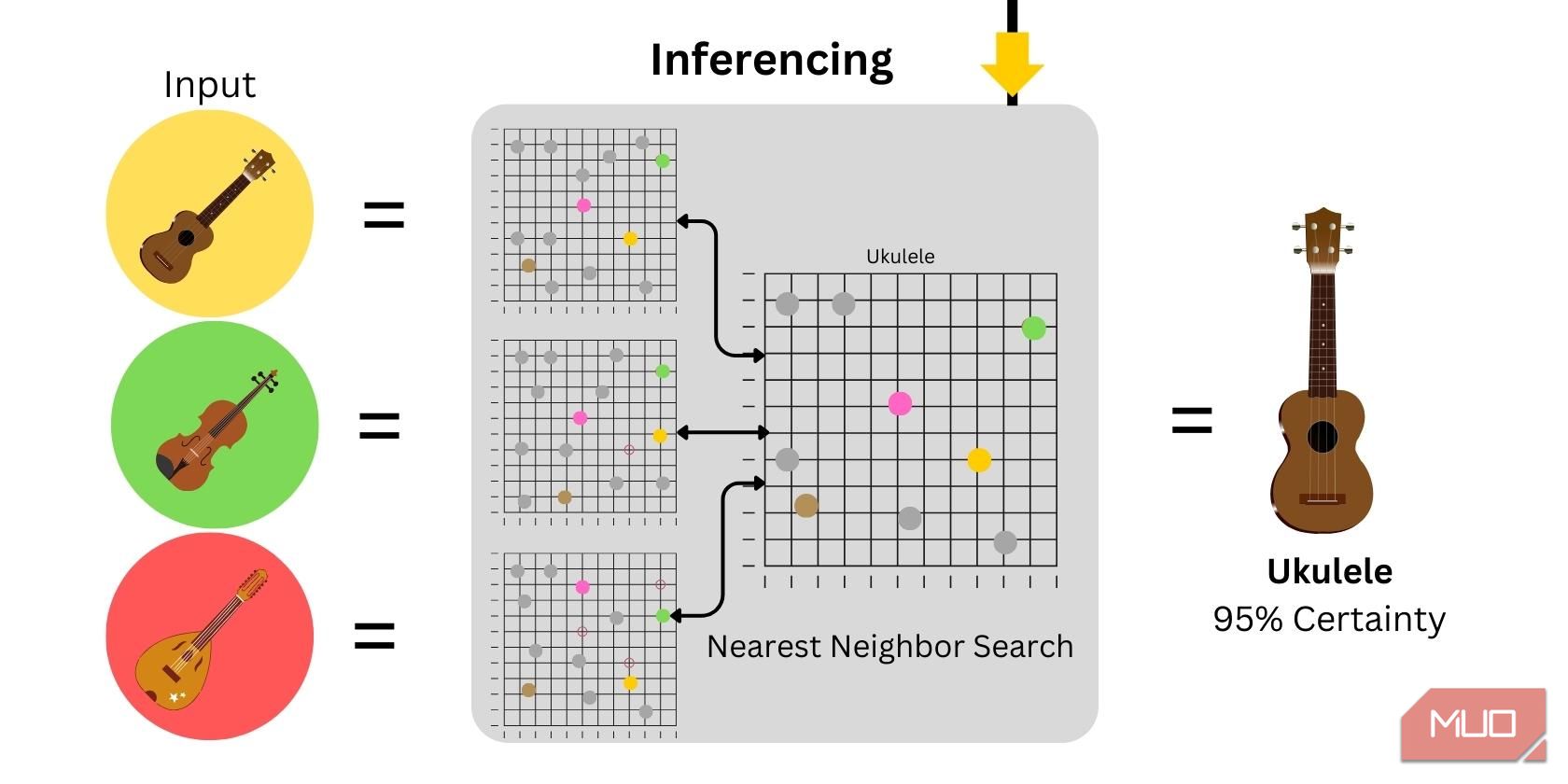
Odvozování spočívá v použití modelu k vytvoření predikcí nebo výstupů. Při klasifikaci obrazu se generují vložení slov na základě vstupního obrazu a následně se porovnávají s pomocnými daty. Úroveň jistoty závisí na podobnosti mezi vstupními daty a poskytnutými pomocnými daty.
Jak Zero-Shot Learning zlepšuje AI
Zero-shot learning zlepšuje modely umělé inteligence tím, že řeší několik problémů spojených se strojovým učením, včetně:
- Vylepšené zobecnění: Snížení závislosti na označených datech umožňuje trénovat modely na větších datových souborech, což zlepšuje schopnost zobecňování a činí model robustnějším a spolehlivějším. Díky tomu, že modely získávají více zkušeností a schopnosti zobecňovat, se dokonce může stát, že se naučí spíše zdravému rozumu než typickému způsobu analýzy informací.
- Škálovatelnost: Modely je možné neustále trénovat a získávat tak nové znalosti prostřednictvím transfer learningu. Společnosti i nezávislí výzkumníci tak mohou neustále vylepšovat své modely tak, aby byly v budoucnu efektivnější.
- Snížené riziko přetrénování: K přetrénování může dojít, když je model trénován na malém datovém souboru, který neobsahuje dostatečnou rozmanitost, aby reprezentoval všechny potenciální vstupy. Trénink modelu s využitím zero-shot learningu snižuje riziko přetrénování tím, že model se učí lépe chápat témata v kontextu.
- Ekonomická efektivita: Poskytování velkého množství označených dat může být časově i finančně náročné. S využitím zero-shot learningu lze trénovat robustní model s menším množstvím času a označených dat.
S vývojem umělé inteligence budou techniky jako zero-shot learning nabývat na významu.
Budoucnost Zero-Shot učení
Zero-shot learning se stává nepostradatelnou součástí strojového učení. Umožňuje modelům rozpoznávat a klasifikovat nové kategorie bez explicitního tréninku. S neustálým vývojem v oblasti modelové architektury, přístupů založených na atributech a multimodální integrace, může zero-shot learning výrazně přispět k adaptabilitě modelů při řešení komplexních problémů v robotice, zdravotnictví a počítačovém vidění.