Apache Hive vs Apache Impala: Hlavní rozdíly
Pokud jste začátečník v oblasti analýzy rozsáhlých dat, pravděpodobně jste se setkali s celou řadou nástrojů Apache. Nicméně, takové množství různých řešení může být někdy zmatující a zdrcující.
Tento článek vám pomůže se v této problematice zorientovat a objasní, co přesně jsou Apache Hive a Impala, a jak se od sebe liší!
Apache Hive
Apache Hive představuje SQL rozhraní pro přístup k datům na platformě Apache Hadoop. Umožňuje vám zadávat dotazy, shromažďovat a analyzovat data za použití SQL syntaxe.
Pro data uložená v systému souborů HDFS se využívá schéma přístupu „čtení při dotazu“, díky čemuž s daty můžete pracovat, jako by se jednalo o standardní tabulku nebo relační systém správy databází (DBMS). Dotazy v jazyce HiveQL se transformují do Java kódu pro úlohy MapReduce.
Dotazy v Hive se píší v dotazovacím jazyce HiveQL, který vychází z jazyka SQL, avšak neobsahuje úplnou podporu pro standard SQL-92.
Tento jazyk však umožňuje programátorům použít vlastní dotazy v situacích, kdy je využití funkcí HiveQL neefektivní nebo nevhodné. HiveQL lze rozšířit o uživatelsky definované skalární funkce (UDF), agregace (UDAF) a tabulkové funkce (UDTF).
Jak funguje Apache Hive
Apache Hive převádí programy napsané v jazyce HiveQL (podobném SQL) do jedné či více úloh MapReduce, Apache Tez nebo Apache Spark. Jde o tři různé motory pro spouštění, které lze využít v Hadoopu. Následně Apache Hive uspořádá data do pole v souborovém systému HDFS (Hadoop Distributed File System), aby mohl spouštět úlohy v rámci clusteru a generovat výsledek.
Tabulky v Apache Hive jsou podobné relačním databázím a datové jednotky se organizují od nejvýznamnější po nejpodrobnější. Databáze se skládají z polí rozdělených do oddílů, které se mohou dále dělit na „segmenty“.
Data jsou přístupná pomocí HiveQL. V každé databázi jsou data seřazená a každá tabulka odpovídá adresáři v HDFS.
V rámci architektury Apache Hive je k dispozici několik rozhraní, jako je webové rozhraní, CLI nebo externí klienti.
Server "Apache Hive Thrift" umožňuje externím klientům zadávat příkazy a požadavky do Apache Hive s využitím různých programovacích jazyků. Centrální adresář Apache Hive je "metastore", který obsahuje veškeré informace.
Engine, který umožňuje fungování Hive, se nazývá "driver". Zahrnuje kompilátor a optimalizátor, který určuje nejefektivnější plán provedení.
Zabezpečení je zajištěno Hadoopem. Proto se při vzájemném ověřování totožnosti mezi klientem a serverem spoléhá na Kerberos. Oprávnění pro nově vytvářené soubory v Apache Hive určuje HDFS, což umožňuje autorizaci na úrovni uživatele, skupiny nebo jiným způsobem.
Vlastnosti Hive
- Podpora výpočetních enginů Hadoop i Spark
- Využívá HDFS a funguje jako datový sklad
- Využívá MapReduce a podporuje ETL
- Díky HDFS vykazuje odolnost proti chybám podobnou Hadoopu
Apache Hive: Výhody
Apache Hive je ideální řešení pro dotazování a analýzu dat. Umožňuje získávat kvalitativní poznatky, poskytuje konkurenční výhodu a usnadňuje reagování na tržní požadavky.
Mezi hlavní výhody Apache Hive patří jeho snadná použitelnost spojená s "SQL-friendly" jazykem. Navíc urychluje počáteční nahrávání dat, jelikož data není nutné číst ani číslovat z disku v interním databázovém formátu.
Vzhledem k tomu, že data se ukládají v HDFS, je možné v Apache Hive uchovávat rozsáhlé datové sady o velikosti až stovky petabajtů. Toto řešení je mnohem škálovatelnější než tradiční databáze. Protože se jedná o cloudovou službu, umožňuje Apache Hive uživatelům rychle spouštět virtuální servery v závislosti na kolísání zatížení (tj. úkolů).
Zabezpečení je dalším aspektem, v němž Hive vyniká díky své schopnosti replikovat zátěže, které jsou klíčové pro obnovu v případě problémů. V neposlední řadě má vysokou pracovní kapacitu, neboť zvládne až 100 000 požadavků za hodinu.
Apache Impala
Apache Impala je masivně paralelní SQL dotazovací engine pro interaktivní provádění SQL dotazů nad daty uloženými v Apache Hadoop. Je napsán v jazyce C++ a distribuován pod licencí Apache 2.0.
Impala se také nazývá MPP (Massively Parallel Processing) engine, distribuovaný systém správy databází (DBMS) a dokonce i SQL-on-Hadoop databázový stack.

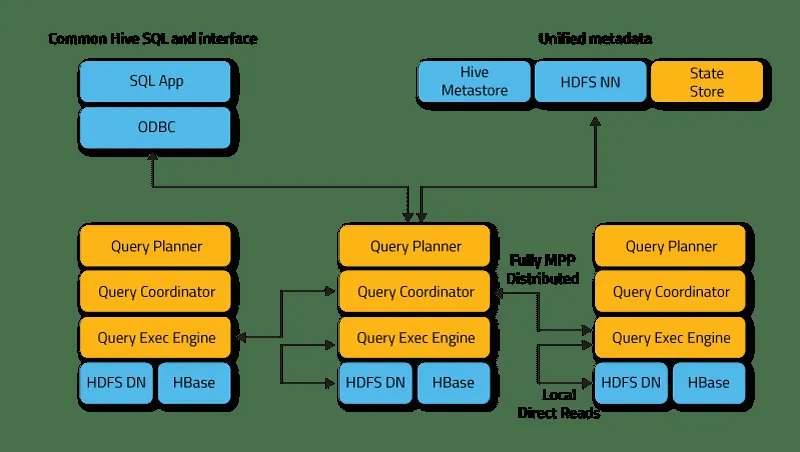
Impala funguje v distribuovaném režimu, kde instance procesů běží na různých uzlech clusteru a přijímají, plánují a koordinují požadavky klientů. V takovém případě je možné paralelní provádění fragmentů SQL dotazu.
Klienti jsou uživatelé a aplikace, které odesílají SQL dotazy nad daty uloženými v Apache Hadoop (HBase a HDFS) nebo Amazon S3. Interakce s Impalou probíhá prostřednictvím webového rozhraní HUE (Hadoop User Experience), ODBC, JDBC a rozhraní příkazové řádky Impala Shell.
Impala infrastrukturně závisí na dalším populárním nástroji SQL-on-Hadoop, Apache Hive, a využívá jeho úložiště metadat. Konkrétně Hive Metastore informuje Impalu o dostupnosti a struktuře databází.
Při vytváření, úpravách a odstraňování objektů schématu nebo nahrávání dat do tabulek pomocí SQL příkazů se odpovídající změny metadat automaticky šíří do všech uzlů Impala prostřednictvím specializované adresářové služby.
Klíčové součásti Impaly jsou následující spustitelné soubory:
- Impalad, neboli Impala démon, je systémová služba, která plánuje a provádí dotazy nad daty v HDFS, HBase a Amazon S3. Na každém uzlu clusteru běží jeden impalad proces.
- Statestore je názvová služba, která sleduje umístění a stav všech instancí impalad v clusteru. Na každém uzlu a hlavním serveru (Name Node) běží jedna instance této systémové služby.
- Katalog je služba koordinace metadat, která šíří změny z Impala DDL a DML příkazů do všech dotčených uzlů Impala. Díky tomu jsou nové tabulky nebo nově načtená data okamžitě viditelná pro libovolný uzel v clusteru. Doporučuje se, aby jedna instance katalogu běžela na stejném hostiteli clusteru jako Statestore démon.
Jak funguje Apache Impala
Impala, podobně jako Apache Hive, využívá deklarativní dotazovací jazyk, Hive Query Language (HiveQL), který je podmnožinou SQL92, místo samotného SQL.
Samotné provedení požadavku v Impale probíhá takto:
Klientská aplikace odešle SQL dotaz připojením k libovolnému impalad přes standardizovaná rozhraní ovladačů ODBC nebo JDBC. Připojený impalad se stává koordinátorem daného požadavku.
SQL dotaz se analyzuje, aby se určily úlohy pro instance impalad v clusteru, a následně se vytvoří optimální plán provedení dotazu.
Impalad přistupuje přímo k HDFS a HBase pomocí lokálních instancí systémových služeb k poskytnutí dat. Na rozdíl od Apache Hive taková přímá interakce významně zkracuje čas provedení dotazu, jelikož se mezivýsledky neukládají.
Následně každý démon vrací data koordinačnímu impalad a posílá výsledky zpět klientovi.
Vlastnosti Impala
- Podpora pro zpracování v paměti v reálném čase
- SQL přátelská
- Podpora úložných systémů, jako je HDFS, Apache HBase a Amazon S3
- Podpora integrace s BI nástroji, jako jsou Pentaho a Tableau
- Využívá syntaxi HiveQL
Apache Impala: Výhody
Impala se vyhýbá možným režijním nákladům při spouštění, protože všechny procesy systémových démonů se spouštějí přímo při startu systému. To výrazně šetří čas potřebný k provedení dotazu. Další zrychlení Impaly spočívá v tom, že tento SQL nástroj pro Hadoop, na rozdíl od Hive, neukládá mezivýsledky a přistupuje přímo k HDFS nebo HBase.
Kromě toho Impala generuje programový kód za běhu, a ne během kompilace, jak to dělá Hive. Vedlejším efektem vysokorychlostního výkonu Impaly je ale nižší spolehlivost.
Konkrétně, pokud během provádění SQL dotazu selže datový uzel, instance Impaly se restartuje. Zatímco Hive nadále udržuje připojení ke zdroji dat a tím zajišťuje odolnost vůči chybám.
Mezi další výhody Impaly patří vestavěná podpora zabezpečeného síťového autentizačního protokolu Kerberos, stanovení priorit a možnost spravovat frontu požadavků, stejně jako podpora populárních formátů pro Big Data, jako jsou LZO, Avro, RCFile, Parquet a Sequence.
Hive vs Impala: Podobnosti
Hive i Impala jsou volně distribuovány pod licencí Apache Software Foundation a oba se jedná o SQL nástroje pro práci s daty uloženými v clusteru Hadoop. Kromě toho oba využívají distribuovaný souborový systém HDFS.
Impala a Hive implementují různé úlohy se společným zaměřením na SQL zpracování rozsáhlých dat uložených v clusteru Apache Hadoop. Impala poskytuje rozhraní podobné SQL, které umožňuje číst a zapisovat do Hive tabulek, což zajišťuje snadnou výměnu dat.
Zároveň Impala umožňuje provádět SQL operace nad Hadoopem poměrně rychle a efektivně, což umožňuje použití tohoto DBMS ve výzkumných projektech v oblasti analýzy rozsáhlých dat. Kdykoli je to možné, Impala spolupracuje se stávající infrastrukturou Apache Hive, která se již využívá pro provádění dlouhodobých dávkových SQL dotazů.
Impala také ukládá definice svých tabulek v metastoru, tradiční databázi MySQL nebo PostgreSQL, tedy na stejném místě, kde Hive ukládá podobná data. To umožňuje Impale přistupovat k Hive tabulkám, za předpokladu, že všechny sloupce využívají datové typy, formáty souborů a kompresní kodeky, které Impala podporuje.
Hive vs Impala: Rozdíly

Programovací jazyk
Hive je naprogramován v Javě, zatímco Impala je napsána v C++. Nicméně, Impala využívá i některé Hive UDF založené na Javě.
Případy použití
Datoví inženýři využívají Hive v procesech ETL (Extract, Transform, Load), například pro dlouhodobé dávkové úlohy nad rozsáhlými soubory dat, například v cestovních agregátorech a letištních informačních systémech. Impala se naopak primárně využívá pro analytiky a datové vědce, a to především v úlohách, jako je business intelligence.
Výkon
Impala provádí SQL dotazy v reálném čase, zatímco Hive se vyznačuje pomalejší rychlostí zpracování dat. U jednoduchých SQL dotazů může Impala běžet 6-69krát rychleji než Hive. Nicméně, Hive lépe zpracovává složité dotazy.
Latence/propustnost
Propustnost Hive je výrazně vyšší než u Impaly. Funkce LLAP (Live Long and Process), která umožňuje ukládání dotazů do mezipaměti v paměti, poskytuje Hive dobrý výkon na nízké úrovni.
LLAP zahrnuje dlouhodobé systémové služby (démony), které umožňují přímou interakci s datovými uzly HDFS a nahrazují strukturu dotazů DAG (Directed acyclic graph), která je běžně používána v Big Data computingu.
Odolnost proti chybám
Hive je systém odolný vůči chybám, který uchovává všechny mezivýsledky. To má pozitivní vliv na škálovatelnost, ale vede ke snížení rychlosti zpracování dat. Impala se naopak nedá označit jako platforma odolná vůči chybám, protože je více vázána na paměť.
Převod kódu
Hive generuje výrazy dotazů v době kompilace, zatímco Impala je generuje za běhu. Hive se potýká s problémem "studeného startu" při prvním spuštění aplikace. Dotazy se převádí pomalu kvůli nutnosti vytvořit spojení se zdrojem dat.
Impala nemá takovýto režijní náklad při spouštění. Potřebné systémové služby (démony) pro zpracování SQL dotazů se spouštějí při startu systému, což urychluje práci.
Podpora úložišť
Impala podporuje formáty LZO, Avro a Parquet, zatímco Hive pracuje s prostým textem a ORC. Nicméně, oba podporují formáty RCFIle a Sequence.
| Apache Hive | Apache Impala | |
| Jazyk | Java | C++ |
| Případy použití | Data Engineering | Analýza a analytika |
| Výkon | Vysoký pro jednoduché dotazy | Poměrně nízká |
| Latence | Větší latence díky ukládání do mezipaměti | Méně latentní |
| Odolnost proti chybám | Tolerantnější díky MapReduce | Méně tolerantní díky MPC |
| Převod kódu | Pomalý kvůli studenému startu | Probíhá za běhu |
| Podpora formátů | Text, ORC, RCFIle a Sequence | LZO, Avro, Parquet, RCFIle a Sequence |
Závěrečná slova
Hive a Impala si navzájem nekonkurují, ale spíše se efektivně doplňují. I když mezi nimi existují značné rozdíly, existuje také poměrně mnoho společného a výběr jednoho z nich závisí na datech a konkrétních požadavcích projektu.
Můžete se také podívat na přímé srovnání mezi Hadoopem a Sparkem.
.
