Část II – Typy vektorizačních technik
V tomto článku se zaměříme na vektorizaci, klíčovou techniku v oblasti zpracování přirozeného jazyka (NLP). Detailně si vysvětlíme, proč je vektorizace důležitá, a prozkoumáme různé typy vektorizačních metod.
Již jsme se věnovali základním konceptům předzpracování textu v NLP a jeho čištění. Zabývali jsme se základy NLP, jeho rozmanitými aplikacemi a technikami, jako jsou tokenizace, normalizace, standardizace a čištění textu.
Než se ponoříme do vektorizace, zopakujme si definici tokenizace a objasněme rozdíl mezi tokenizací a vektorizací.
Co je tokenizace?
Tokenizace je proces, při kterém se věty rozdělují na menší celky, nazývané tokeny. Tokeny umožňují počítačům snadněji porozumět textu a efektivně s ním pracovat.
Například věta: „Tento článek je skvělý“
Bude tokenizována jako: ['Tento', 'článek', 'je', 'skvělý'].
Co je to vektorizace?
Jak je známo, modely strojového učení pracují s číselnými daty. Vektorizace představuje proces převodu textových nebo kategoriálních dat do číselných vektorů. Díky převodu dat do číselné formy lze modely trénovat s větší přesností.
Proč je vektorizace nezbytná?
- Tokenizace a vektorizace hrají rozdílnou, avšak zásadní roli v NLP. Tokenizace rozkládá věty na jednotlivé tokeny, zatímco vektorizace je převádí do numerického formátu, srozumitelného pro počítačové modely.
- Vektorizace se neomezuje pouze na převod do numerické podoby; také pomáhá zachytit sémantický význam textu.
- Vektorizace dokáže snížit rozměrnost dat a zvýšit jejich efektivitu, což je zvláště důležité při zpracování velkých datových souborů.
- Řada algoritmů strojového učení, jako například neuronové sítě, vyžaduje numerický vstup. Vektorizace je klíčová pro jejich použití.
V tomto článku si představíme různé techniky vektorizace.
Pytel slov (Bag of Words)
Metoda „Pytel slov“ usnadňuje analýzu velkého množství dokumentů nebo vět tím, že s dokumentem zachází jako s „pytlem“, který obsahuje slova. Tento přístup je užitečný při klasifikaci textu, analýze sentimentu a vyhledávání dokumentů.
Představte si, že pracujete s velkým objemem textu. Metoda pytle slov pomůže reprezentovat textová data vytvořením slovní zásoby unikátních slov z těchto dat. Po vytvoření slovní zásoby se každé slovo zakóduje jako vektor na základě jeho frekvence výskytu v textu.
Vektory jsou tvořeny nezápornými čísly (0, 1, 2…), která odpovídají četnosti slov v dokumentu.
Proces pytle slov se skládá ze tří hlavních kroků:
Krok 1: Tokenizace
Dokumenty se rozdělí na tokeny.
Například: (Věta: „Mám rád pizzu a mám rád hamburgery“)
Krok 2: Vytvoření slovní zásoby
Vytvoří se seznam všech unikátních slov vyskytujících se ve větách.
[“Mám”, “rád”, “pizzu”, “a”, “hamburgery”]
Krok 3: Tvorba vektorů
V tomto kroku se spočítá počet výskytů každého slova ze slovní zásoby a uloží se do řídké matice. Každý řádek této matice reprezentuje větu, jejíž délka (počet sloupců) se rovná velikosti slovní zásoby.
Import CountVectorizer
Pro trénování modelu pytle slov importujeme CountVectorizer.
from sklearn.feature_extraction.text import CountVectorizer
Vytvoření vektorizátoru
Zde vytvoříme model pomocí CountVectorizer a natrénujeme jej na vzorovém textovém dokumentu.
# Vzorové textové dokumenty
documents = [
"Toto je první dokument.",
"Tento dokument je druhý dokument.",
"A toto je třetí.",
"Je toto první dokument?",
]
# Vytvoření CountVectorizer
cv = CountVectorizer()
# Fit and Transform X = cv.fit_transform(documents)
Převod na husté pole
V tomto kroku převedeme reprezentaci na husté pole a získáme názvy funkcí (slova).
# Získání názvů funkcí / slov feature_names = cv.get_feature_names_out() # Převod na husté pole X_dense = X.toarray()
Výpis matice termínů a názvů funkcí
# Výpis matice termínů a názvů funkcí
print("Matice termínů dokumentu (DTM):")
print(X_dense)
print("\nNázvy funkcí:")
print(feature_names)
Matice termínů dokumentu (DTM):

Názvy funkcí:

Jak vidíte, vektory jsou tvořeny nezápornými čísly (0, 1, 2…), které reprezentují četnost slov v dokumentu.
Máme čtyři vzorové textové dokumenty, ze kterých jsme identifikovali devět unikátních slov. Tato slova jsou uložena v naší slovní zásobě a mají přiřazené „názvy funkcí“.
Následně model pytle slov kontroluje, zda je v prvním dokumentu přítomno první jedinečné slovo. Pokud ano, přiřadí hodnotu 1, v opačném případě 0.
Jestliže se slovo vyskytne vícekrát (např. dvakrát), přiřadí mu odpovídající hodnotu.
Například ve druhém dokumentu se slovo „dokument“ opakuje dvakrát, takže jeho hodnota v matici bude 2.
Pokud chceme jediné slovo jako funkci, jedná se o reprezentaci Unigram.
n-gramy = unigramy, bigramy, atd.
Existuje mnoho knihoven, které implementují pytel slov, například scikit-learn, Keras, Gensim a další. Jedná se o jednoduchou, ale efektivní metodu pro různé aplikace.
Pytel slov má však určitá omezení:
- Všechna slova mají stejnou váhu, bez ohledu na jejich důležitost. V mnoha případech jsou některá slova významnější než jiná.
- Pytel slov pouze počítá frekvenci výskytu slov v dokumentu. To může vést k přecenění významu běžných slov, jako „a“, „je“, „ten“ apod., která nemají velký informační obsah.
- Delší dokumenty mohou mít více slov a vytvářet větší vektory, což může ztížit srovnávání. Může vzniknout řídká matice, která není optimální pro komplexní NLP projekty.
Pro řešení těchto omezení lze zvolit pokročilejší metody, jednou z nich je TF-IDF. Pojďme si ji podrobněji rozebrat.
TF-IDF
TF-IDF (Term Frequency-Inverse Document Frequency) je numerické vyjádření, které určuje důležitost slov v dokumentu.
Proč je TF-IDF lepší než pytel slov?
Pytel slov zachází se všemi slovy stejně a zabývá se pouze frekvencí unikátních slov. TF-IDF naopak klade důraz na význam slov v dokumentu zohledněním jak frekvence, tak i unikátnosti slov.
Slova, která se opakují příliš často, nebudou přebíjet méně častá, ale významnější slova.
TF (Term Frequency) měří důležitost slova v jedné větě.
IDF (Inverse Document Frequency) měří důležitost slova v celé sbírce dokumentů.
TF = Frekvence slova v dokumentu / Celkový počet slov v daném dokumentu
DF = Počet dokumentů obsahujících slovo w / Celkový počet dokumentů
IDF = log (celkový počet dokumentů / počet dokumentů obsahujících slovo w)
IDF je inverzní k DF. Důvodem je, že čím častější je slovo ve všech dokumentech, tím menší je jeho význam v aktuálním dokumentu.
Konečné skóre TF-IDF: TF-IDF = TF * IDF
TF-IDF pomáhá zjistit, která slova jsou běžná v rámci jednoho dokumentu a zároveň unikátní ve všech dokumentech. Tato slova mohou být užitečná při hledání hlavního tématu dokumentu.
Například:
Doc1 = „Mám rád strojové učení“
Doc2 = „Mám rád etechblog.cz“
Vypočítáme matici TF-IDF pro tyto dokumenty.
Nejprve si vytvoříme slovní zásobu unikátních slov:
Slovní zásoba = [“Mám”, “rád”, “strojové”, “učení”, “etechblog.cz”]
Máme tedy 5 slov. Vypočítáme TF a IDF pro každé slovo.
TF = Frekvence slova v dokumentu / Celkový počet slov v daném dokumentu
TF:
- Pro „Mám“ = TF pro Doc1: 1/4 = 0,25 a pro Doc2: 1/3 ≈ 0,33
- Pro „rád“: TF pro Doc1: 1/4 = 0,25 a pro Doc2: 1/3 ≈ 0,33
- Pro „strojové“: TF pro Doc1: 1/4 = 0,25 a pro Doc2: 0/3 ≈ 0
- Pro „učení“: TF pro Doc1: 1/4 = 0,25 a pro Doc2: 0/3 ≈ 0
- Pro „etechblog.cz“: TF pro Doc1: 0/4 = 0 a pro Doc2: 1/3 ≈ 0,33
Nyní vypočítáme IDF:
IDF = log (celkový počet dokumentů / počet dokumentů obsahujících slovo w)
IDF:
- Pro „Mám“: IDF je log(2/2) = 0
- Pro „rád“: IDF je log(2/2) = 0
- Pro „strojové“: IDF je log(2/1) = log(2) ≈ 0,69
- Pro „učení“: IDF je log(2/1) = log(2) ≈ 0,69
- Pro „etechblog.cz“: IDF je log(2/1) = log(2) ≈ 0,69
Spočítáme konečné skóre TF-IDF:
- Pro „Mám“: TF-IDF pro Doc1: 0,25 * 0 = 0 a TF-IDF pro Doc2: 0,33 * 0 = 0
- Pro „rád“: TF-IDF pro Doc1: 0,25 * 0 = 0 a TF-IDF pro Doc2: 0,33 * 0 = 0
- Pro „strojové“: TF-IDF pro Doc1: 0,25 * 0,69 ≈ 0,17 a TF-IDF pro Doc2: 0 * 0,69 = 0
- Pro „učení“: TF-IDF pro Doc1: 0,25 * 0,69 ≈ 0,17 a TF-IDF pro Doc2: 0 * 0,69 = 0
- Pro „etechblog.cz“: TF-IDF pro Doc1: 0 * 0,69 = 0 a TF-IDF pro Doc2: 0,33 * 0,69 ≈ 0,23
Matice TF-IDF vypadá takto:
Mám rád strojové učení etechblog.cz
Doc1 0.0 0.0 0.17 0.17 0.0
Doc2 0.0 0.0 0.0 0.0 0.23
Hodnoty v matici TF-IDF ukazují důležitost jednotlivých termínů v daných dokumentech. Vysoké hodnoty značí, že termín je pro daný dokument klíčový, zatímco nízké hodnoty indikují, že termín je méně významný nebo běžný.
TF-IDF se nejčastěji využívá při klasifikaci textu, získávání informací chatboty a sumarizaci textu.
Import TfidfVectorizer
Importujeme TfidfVectorizer ze sklearn.
from sklearn.feature_extraction.text import TfidfVectorizer
Vytvoření vektorizátoru
Model TF-IDF vytvoříme pomocí TfidfVectorizer.
# Vzorové textové dokumenty
text = [
"Toto je první dokument.",
"Tento dokument je druhý dokument.",
"A toto je třetí.",
"Je toto první dokument?",
]
# Vytvoření TfidfVectorizer
cv = TfidfVectorizer()
Vytvoření matice TF-IDF
Natrénujeme model a převedeme matici na husté pole.
# Fit a transform pro vytvoření matice TF-IDF X = cv.fit_transform(text)
# Získání názvů funkcí/slov feature_names = cv.get_feature_names_out() # Převod matice TF-IDF na husté pole pro snadnější manipulaci X_dense = X.toarray()
Výpis matice TF-IDF a klíčových slov
# Výpis matice TF-IDF a klíčových slov
print("Matice TF-IDF:")
print(X_dense)
print("\nNázvy funkcí:")
print(feature_names)
Matice TF-IDF:

Jak vidíte, čísla s desetinnou čárkou označují důležitost slov v daných dokumentech.
Slova lze také kombinovat do skupin po 2, 3, 4 atd. pomocí n-gramů.
Existují další parametry, které lze použít: min_df, max_feature, sublinear_tf apod.
Dosud jsme se zabývali základními frekvenčními technikami.
TF-IDF však nemůže poskytnout sémantický význam a kontextové porozumění textu.
Pojďme se seznámit s pokročilejšími technikami, které změnily svět vkládání slov a které jsou lepší pro sémantický význam a kontextové porozumění.
Word2Vec
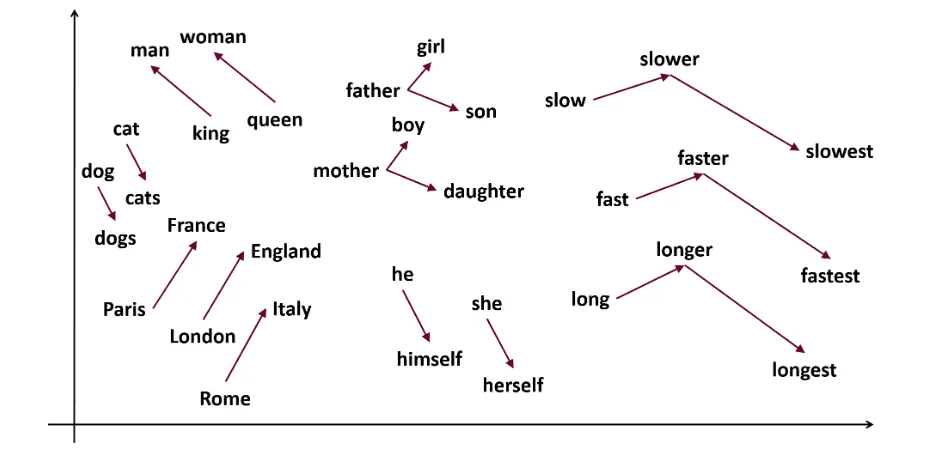
Word2Vec je populární technika vkládání slov v NLP, která pomáhá zachytit sémantickou a syntaktickou podobnost slov. Byla vyvinuta týmem Tomáše Mikolova v Googlu v roce 2013. Word2Vec reprezentuje slova jako spojité vektory ve vícerozměrném prostoru.
Cílem Word2Vec je reprezentovat slova způsobem, který zachycuje jejich sémantický význam. Vektory slov generované Word2Vec jsou umístěny v souvislém vektorovém prostoru.
Příklad – vektory slov „kočka“ a „pes“ by si měly být bližší než vektory slov „kočka“ a „dívka“.
 Zdroj: usna.edu
Zdroj: usna.edu
Word2Vec využívá dvě modelové architektury pro vytváření vkládání slov.
CBOW (Continuous Bag of Words) se snaží předpovědět cílové slovo na základě průměru významů okolních slov. Vezme pevný počet slov (okno) kolem cílového slova, převede je do číselné podoby (vkládání), zprůměruje je a pomocí neuronové sítě předpoví cílové slovo.
Například, pro predikci cílového slova: „Liška“
Slova věty: „Ta“, „rychlá“, „hnědá“, „skáče“, „přes“ „tu“
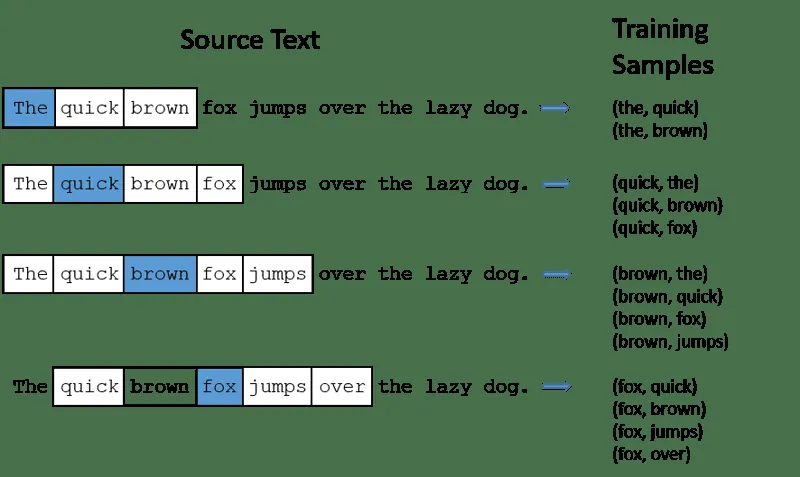
- CBOW má pevnou velikost okna (počet slov) 2 (2 doleva a 2 doprava).
- Slova se převedou na vkládání.
- CBOW průměruje vkládání slov.
- Průměrný vektor se snaží pomocí neuronové sítě předpovědět cílové slovo.
Nyní se podívejme, jak se Skip-gram liší od CBOW.
Skip-gram: Jedná se o model vkládání slov, ale funguje jinak. Místo předpovídání cílového slova, skip-gram předpovídá kontextová slova daná cílovými slovy.
Skip-gramy jsou lepší v zachycování sémantických vztahů mezi slovy.
Příklad: „Král – Muž + Žena = Královna“
Při práci s Word2Vec můžete buď natrénovat vlastní model, nebo použít předtrénovaný. V našem případě použijeme předtrénovaný model.
Import knihovny gensim:
Gensim můžete nainstalovat pomocí pip:
pip install gensim
Tokenizace věty pomocí word_tokenize:
Nejprve převedeme věty na malá písmena. Poté provedeme tokenizaci vět pomocí word_tokenize.
# Import potřebných knihoven
from gensim.models import Word2Vec
from nltk.tokenize import word_tokenize
# Vzorové věty
sentences = [
"Mám rád thora",
"Hulk je důležitým členem Avengers",
"Ironman pomáhá Spidermanovi",
"Spiderman je jedním z populárních členů Avengers",
]
# Tokenizace vět
tokenized_sentences = [word_tokenize(sentence.lower()) for sentence in sentences]
Natrénujeme náš model:
Model natrénujeme poskytnutím tokenizovaných vět. Pro tento trénovací model použijeme okno o velikosti 5, můžete si jej přizpůsobit dle vašich potřeb.
# Natrénování modelu Word2Vec
model = Word2Vec(sentences=tokenized_sentences, vector_size=100, window=5, min_count=1, sg=0)
# Vyhledání podobných slov
similar_words = model.wv.most_similar("avengers")
# Výpis podobných slov
print("Podobná slova ke slovu 'avengers':")
for word, score in similar_words:
print(f"{word}: {score}")
Podobná slova pro "avengers":
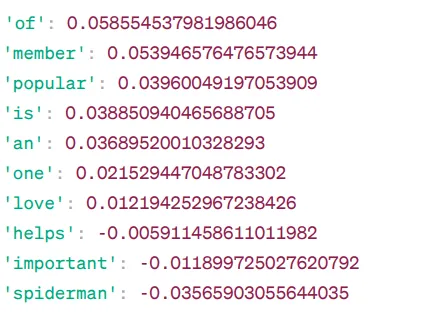
Toto jsou slova, která jsou si podobná slovu „avengers“ na základě modelu Word2Vec, spolu s jejich skóre podobnosti.
Model vypočítává skóre podobnosti (většinou kosinovou podobnost) mezi vektory slov „avengers“ a jinými slovy ve slovníku. Skóre podobnosti udává, jak úzce spolu souvisí dvě slova ve vektorovém prostoru.
Příklad:
Zde má slovo „pomáhá“ kosinovou podobnost -0.005911458611011982 se slovem „avengers“. Záporná hodnota indikuje, že by se mohla navzájem lišit.
Hodnoty kosinové podobnosti se pohybují od -1 do 1, kde:
- 1 označuje, že dva vektory jsou identické a mají pozitivní podobnost.
- Hodnoty blízké 1 označují vysokou pozitivní podobnost.
- Hodnoty blízké 0 znamenají, že vektory spolu úzce nesouvisí.
- Hodnoty blízké -1 znamenají vysokou nepodobnost.
- -1 znamená, že vektory jsou zcela opačné a mají dokonalou negativní podobnost.
Navštivte tento odkaz, pokud chcete lépe porozumět modelům Word2Vec a vizuální reprezentaci toho, jak fungují. Je to skvělý nástroj k vidění CBOW a skip-gram v akci.
Stejně jako Word2Vec existuje GloVe. GloVe dokáže vytvořit vkládání, které vyžaduje méně paměti ve srovnání s Word2Vec. Pojďme si o GloVe povědět více.
GloVe
Globální vektory pro reprezentaci slov (GloVe) jsou technikou podobnou Word2Vec. Používá se k reprezentaci slov jako vektorů v spojitém prostoru. Koncept GloVe je stejný jako u Word2Vec: vytváří kontextová vkládání slov, přičemž bere v úvahu výborný výkon Word2Vec.
Proč potřebujeme GloVe?
Word2Vec je metoda založená na oknech, která pro porozumění slovům používá blízká slova. To znamená, že sémantický význam cílového slova je ovlivněn pouze okolními slovy ve větách, což je neefektivní využití statistiky.
GloVe naopak zachycuje globální i lokální statistiky, které souvisejí s vkládáním slov.
Kdy použít GloVe?
GloVe použijte, pokud chcete vkládání slov, které zachycuje širší sémantické vztahy a globální asociace slov.
GloVe je lepší než jiné modely v úlohách rozpoznávání pojmenovaných entit, analogií slov a podobnosti slov.
Nejprve musíme nainstalovat Gensim:
pip install gensim
Krok 1: Importujeme důležité knihovny
# Import požadovaných knihoven import numpy as np import matplotlib.pyplot as plt from sklearn.manifold import TSNE import gensim.downloader as api
Krok 2: Importujeme model GloVe
import gensim.downloader as api
glove_model = api.load('glove-wiki-gigaword-300')
Krok 3: Načteme vektorovou reprezentaci slova „roztomilý“
glove_model["cute"]
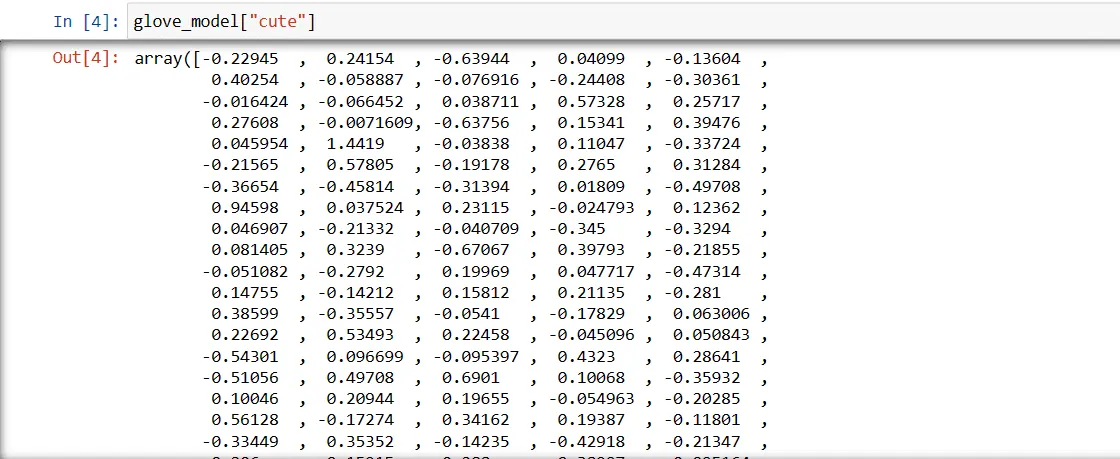
Tyto hodnoty zachycují význam slova a jeho vztah k jiným slovům. Kladné hodnoty značí pozitivní asociace s určitými koncepty, zatímco záporné hodnoty označují negativní asociace.
V modelu GloVe každý rozměr ve vektoru slova představuje určitý aspekt významu nebo kontextu slova.
Záporné a kladné hodnoty v těchto rozměrech přispívají k tomu, jak sémanticky „roztomilý“ souvisí s ostatními slovy ve slovníku modelu.
Hodnoty se mohou u různých modelů lišit. Zkusme najít nějaká podobná slova ke slovu „chlapec“.
Top 10 podobných slov, které se nejvíce podobají slovu „chlapec“ podle modelu:
# Najít podobné slovo
glove_model.most_similar("boy")
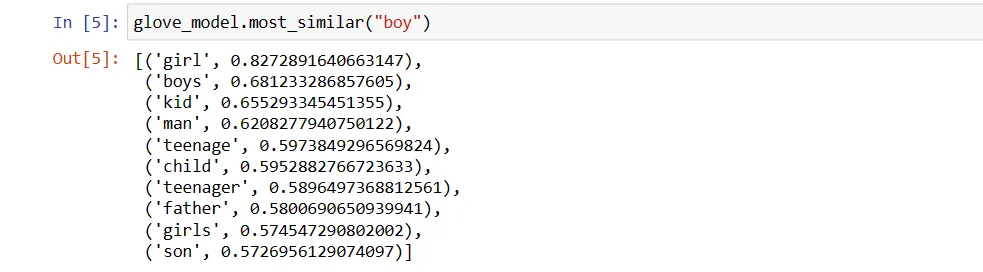
Jak vidíte, nejpodobnější slovo k „chlapec“ je „dívka“.
Nyní se pokusíme zjistit, jak přesně model získá sémantický význam z poskytnutých slov.
glove_model.most_similar(positive=['boy', 'queen'], negative=['girl'], topn=1)

Náš model je schopen nalézt dokonalý vztah mezi slovy.
Definice seznamu slov:
Nyní se pokusíme pochopit sémantický význam nebo vztah mezi slovy pomocí grafu. Definujeme seznam slov, která chceme zobrazit.
# Definujeme seznam slov, která chceme vizualizovat vocab = ["boy", "girl", "man", "woman", "king", "queen", "banana", "apple", "mango", "cow", "coconut", "orange", "cat", "dog"]
Vytvoření matice vkládání:
Vytvoříme kód pro vytvoření matice vkládání.
# Kód pro vytvoření matice vkládání
EMBEDDING_DIM = glove_model.vectors.shape[1]
word_index = {word: index for index, word in enumerate(vocab)}
num_words = len(vocab)
embedding_matrix = np.zeros((num_words, EMBEDDING_DIM))
for word, i in word_index.items():
embedding_vector = glove_model[word]
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
Definujeme funkci pro vizualizaci t-SNE:
Z tohoto kódu definujeme funkci pro náš vizualizační graf.
def tsne_plot(embedding_matrix, words):
tsne_model = TSNE(perplexity=3, n_components=2, init="pca", random_state=42)
coordinates = tsne_model.fit_transform(embedding_matrix)
x, y = coordinates[:, 0], coordinates[:, 1]
plt.figure(figsize=(14, 8))
for i, word in enumerate(words