
Matice zmatků je nástroj k vyhodnocení výkonu klasifikačního typu dohlížených algoritmů strojového učení.
Table of Contents
Co je Confusion Matrix?
My, lidé, vnímáme věci jinak – dokonce i pravdu a lež. To, co se mi může zdát 10 cm dlouhá čára, vám může připadat jako 9 cm čára. Ale skutečná hodnota může být 9, 10 nebo něco jiného. To, co odhadujeme, je předpokládaná hodnota!
Jak přemýšlí lidský mozek
Stejně jako náš mozek používá naši vlastní logiku k předpovědi něčeho, stroje používají různé algoritmy (nazývané algoritmy strojového učení), aby dospěly k předpokládané hodnotě otázky. Opět platí, že tyto hodnoty mohou být stejné nebo odlišné od skutečné hodnoty.
V konkurenčním světě bychom rádi věděli, zda je naše předpověď správná nebo ne, abychom porozuměli našemu výkonu. Stejným způsobem můžeme určit výkon algoritmu strojového učení podle toho, kolik předpovědí provedl správně.
Co je tedy algoritmus strojového učení?
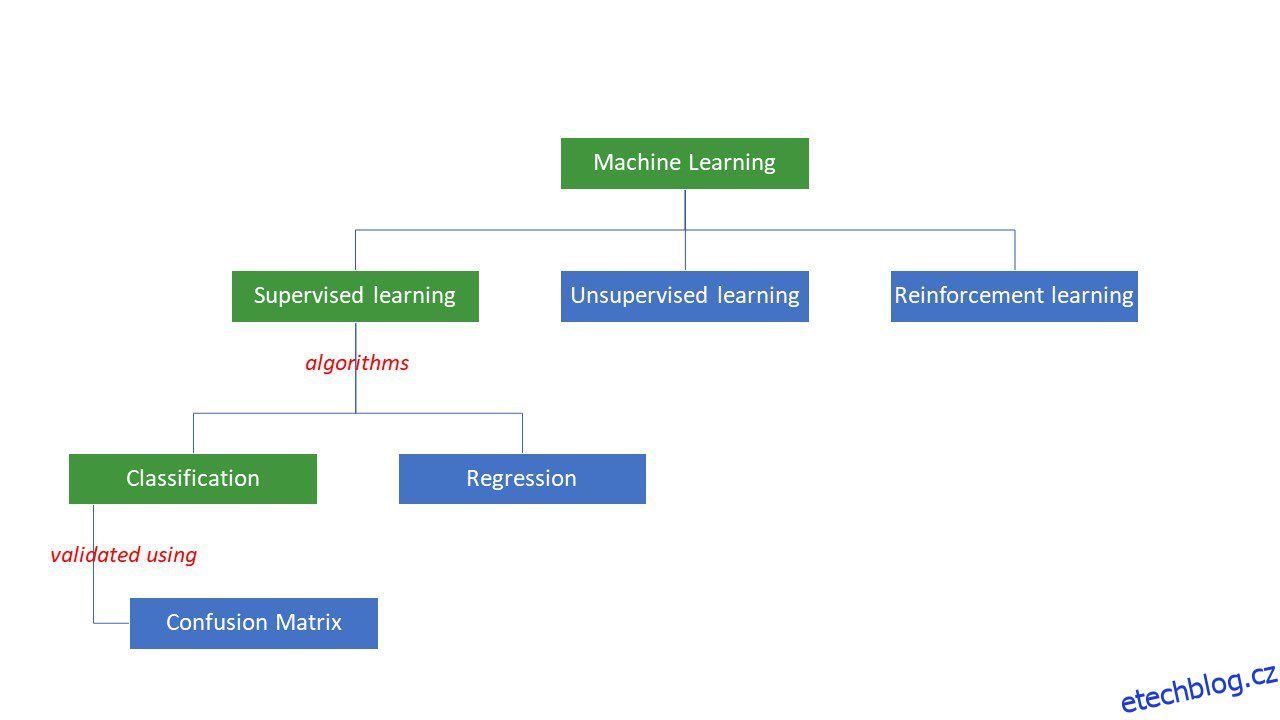
Stroje se snaží dospět k určitým odpovědím na problém aplikací určité logiky nebo sady instrukcí, které se nazývají algoritmy strojového učení. Algoritmy strojového učení jsou tří typů – pod dohledem, bez dozoru nebo zesílené.
 Typy algoritmů strojového učení
Typy algoritmů strojového učení
Nejjednodušší typy algoritmů jsou pod dohledem, kde již známe odpověď, a trénujeme stroje, aby k této odpovědi dospěly, trénováním algoritmu s velkým množstvím dat – stejně jako to, jak by dítě rozlišovalo mezi lidmi různých věkových skupin. dívat se na jejich rysy znovu a znovu.
Supervidované ML algoritmy jsou dvojího typu – klasifikační a regresní.
Klasifikační algoritmy klasifikují nebo třídí data na základě určité sady kritérií. Pokud například chcete, aby váš algoritmus seskupoval zákazníky na základě jejich preferencí v jídle – ty, kteří mají rádi pizzu, a ty, kteří nemají rádi pizzu, použijete klasifikační algoritmus, jako je rozhodovací strom, náhodný les, naivní Bayes nebo SVM (Support Vektorový stroj).
Který z těchto algoritmů by odvedl nejlepší práci? Proč byste měli zvolit jeden algoritmus před druhým?
Zadejte matoucí matici….
Matice zmatků je matice nebo tabulka, která poskytuje informace o tom, jak přesný je klasifikační algoritmus při klasifikaci datové sady. No, ten název nemá lidi zmást, ale příliš mnoho nesprávných předpovědí pravděpodobně znamená, že algoritmus byl zmatený😉!
Matice zmatků je tedy metodou hodnocení výkonu klasifikačního algoritmu.
Jak?
Řekněme, že jste použili různé algoritmy na náš dříve zmíněný binární problém: klasifikujte (segregujte) lidi podle toho, zda mají nebo nemají rádi pizzu. K vyhodnocení algoritmu, který má hodnoty nejbližší správné odpovědi, byste použili matici zmatků. Pro problém binární klasifikace (jako/nelíbí se mi, pravda/nepravda, 1/0) poskytuje matoucí matice čtyři hodnoty mřížky, konkrétně:
- Skutečně pozitivní (TP)
- Skutečně negativní (TN)
- Falešně pozitivní (FP)
- Falešně negativní (FN)
Jaké jsou čtyři mřížky ve zmatkové matici?
Čtyři hodnoty určené pomocí matoucí matice tvoří mřížky matice.
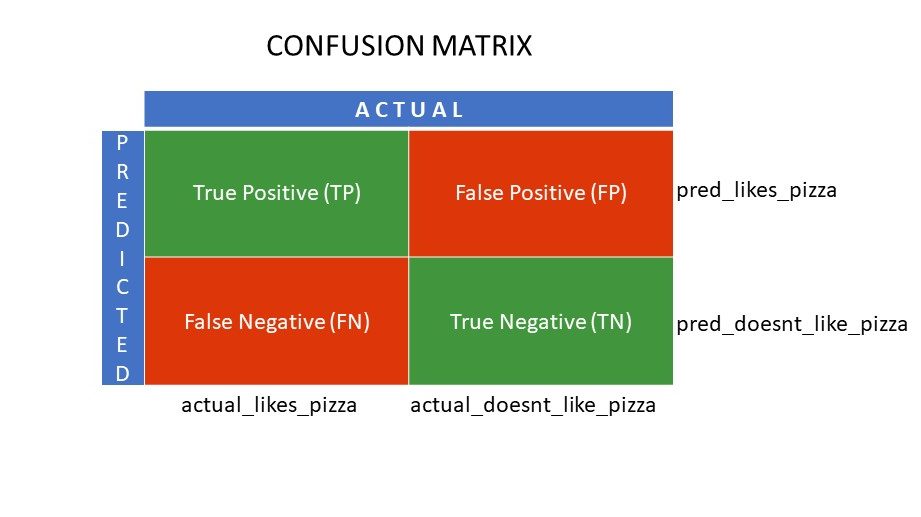 Mřížky matoucí matice
Mřížky matoucí matice
True Positive (TP) a True Negative (TN) jsou hodnoty správně předpovězené klasifikačním algoritmem,
- TP představuje ty, kteří mají rádi pizzu, a model je klasifikoval správně,
- TN představuje ty, kteří nemají rádi pizzu, a model je zařadil správně,
Falešně pozitivní (FP) a Falešně negativní (FN) jsou hodnoty, které klasifikátor chybně předpovídá,
- FP představuje ty, kteří nemají rádi pizzu (negativní), ale klasifikátor předpověděl, že mají rádi pizzu (chybně pozitivní). FP se také nazývá chyba typu I.
- FN představuje ty, kteří mají rádi pizzu (pozitivní), ale klasifikátor předpověděl, že ne (chybně negativní). FN se také nazývá chyba typu II.
Abychom tomuto konceptu lépe porozuměli, vezměme si scénář ze skutečného života.
Řekněme, že máte soubor dat 400 lidí, kteří podstoupili test Covid. Nyní máte výsledky různých algoritmů, které určovaly počet Covid pozitivních a Covid negativních lidí.
Zde jsou dvě matoucí matice pro srovnání:
Když se podíváte na oba, můžete být v pokušení říci, že 1. algoritmus je přesnější. Ale abychom získali konkrétní výsledek, potřebujeme nějaké metriky, které dokážou měřit přesnost, přesnost a mnoho dalších hodnot, které dokazují, který algoritmus je lepší.
Metriky využívající konfuzní matici a jejich význam
Hlavní metriky, které nám pomáhají rozhodnout, zda klasifikátor provedl správné předpovědi, jsou:
#1. Vyvolání/citlivost
Recall nebo Sensitivity nebo True Positive Rate (TPR) nebo Probability of Detection je poměr správných pozitivních předpovědí (TP) k celkovým pozitivním (tj. TP a FN).
R = TP/(TP + FN)
Recall je míra správných pozitivních výsledků vrácených z počtu správných pozitivních výsledků, které mohly být vytvořeny. Vyšší hodnota Recall znamená, že je méně falešných negativů, což je dobré pro algoritmus. Pokud je důležité znát falešné negativy, použijte funkci Vyvolat. Pokud má například člověk více blokád v srdci a model ukazuje, že je naprosto v pořádku, mohlo by to být fatální.
#2. Přesnost
Přesnost je míra správných pozitivních výsledků ze všech předpokládaných pozitivních výsledků, včetně pravdivých i falešných pozitivních výsledků.
Pr = TP/(TP + FP)
Přesnost je docela důležitá, když jsou falešná pozitiva příliš důležitá na to, aby byla ignorována. Například když člověk nemá cukrovku, ale model to ukazuje a lékař mu předepíše určité léky. To může vést k závažným vedlejším účinkům.
#3. Specifičnost
Specificita nebo True Negative Rate (TNR) jsou správné negativní výsledky zjištěné ze všech výsledků, které mohly být negativní.
S = TN/(TN + FP)
Je to míra toho, jak dobře váš klasifikátor identifikuje záporné hodnoty.
#4. Přesnost
Přesnost je počet správných předpovědí z celkového počtu předpovědí. Pokud jste tedy správně našli 20 kladných a 10 záporných hodnot ze vzorku 50, přesnost vašeho modelu bude 30/50.
Přesnost A = (TP + TN)/(TP + TN + FP + FN)
#5. Prevalence
Prevalence je mírou počtu pozitivních výsledků získaných ze všech výsledků.
P = (TP + FN)/(TP + TN + FP + FN)
#6. F skóre
Někdy je obtížné porovnávat dva klasifikátory (modely) pouze pomocí Precision a Recall, které jsou pouze aritmetickými prostředky kombinace čtyř mřížek. V takových případech můžeme použít skóre F nebo skóre F1, což je harmonický průměr – který je přesnější, protože se příliš neliší pro extrémně vysoké hodnoty. Vyšší F skóre (max 1) znamená lepší model.
F skóre = 2*přesnost*vyvolání/ (vyvolání + přesnost)
Když je životně důležité postarat se o falešné i falešné negativy, je skóre F1 dobrou metrikou. Například ti, kteří nejsou covid pozitivní (ale algoritmus to ukázal), nemusí být zbytečně izolováni. Stejným způsobem je třeba izolovat ty, které jsou pozitivní na Covid (ale algoritmus řekl, že nejsou).
#7. ROC křivky
Parametry jako přesnost a přesnost jsou dobré metriky, pokud jsou data vyvážená. U nevyvážené datové sady nemusí vysoká přesnost nutně znamenat, že klasifikátor je účinný. Například 90 ze 100 studentů v dávce umí španělsky. Nyní, i když váš algoritmus říká, že všech 100 umí španělsky, jeho přesnost bude 90 %, což může poskytnout špatný obrázek o modelu. V případech nevyvážených datových souborů jsou metriky jako ROC efektivnějšími určovateli.
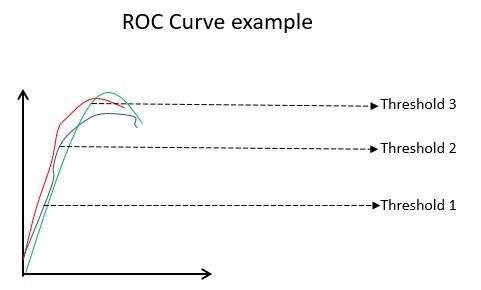 Příklad ROC křivky
Příklad ROC křivky
Křivka ROC (Receiver Operating Characteristic) vizuálně zobrazuje výkon binárního klasifikačního modelu při různých prahových hodnotách klasifikace. Je to graf TPR (True Positive Rate) proti FPR (False Positive Rate), který se vypočítá jako (1-Specificity) při různých prahových hodnotách. Hodnota, která je v grafu nejblíže 45 stupňům (vlevo nahoře), je nejpřesnější prahovou hodnotou. Pokud je práh příliš vysoký, nebudeme mít mnoho falešně pozitivních výsledků, ale dostaneme více falešně negativních výsledků a naopak.
Obecně platí, že při vykreslování křivky ROC pro různé modely se za lepší model považuje ten, který má největší oblast pod křivkou (AUC).
Vypočítejme všechny metrické hodnoty pro naše matoucí matice klasifikátoru I a klasifikátoru II:
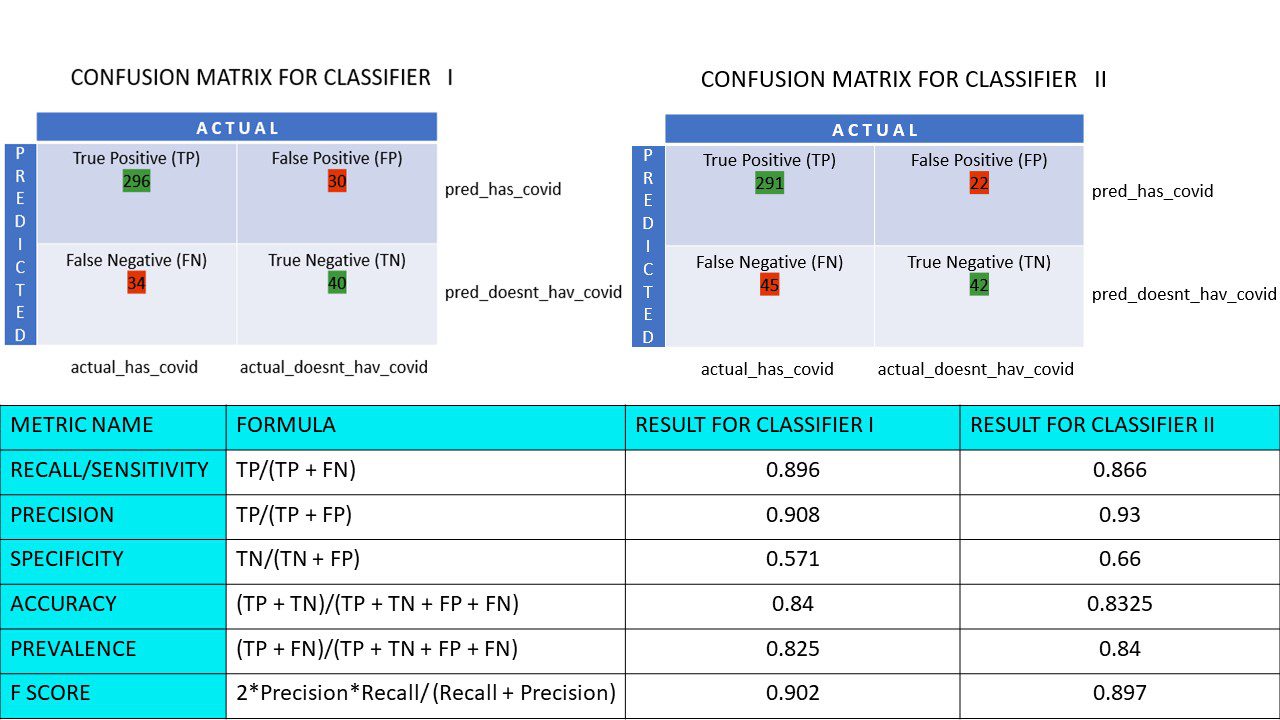 Porovnání metrik pro klasifikátory 1 a 2 průzkumu pizzy
Porovnání metrik pro klasifikátory 1 a 2 průzkumu pizzy
Vidíme, že přesnost je vyšší v klasifikátoru II, zatímco přesnost je mírně vyšší v klasifikátoru I. Na základě daného problému mohou osoby s rozhodovací pravomocí vybrat klasifikátory I nebo II.
N x N matoucí matice
Dosud jsme viděli matoucí matici pro binární klasifikátory. Co kdyby bylo více kategorií než jen ano/ne nebo líbí se/nelíbí. Například pokud váš algoritmus měl třídit obrázky červené, zelené a modré barvy. Tento typ klasifikace se nazývá vícetřídní klasifikace. O velikosti matice rozhoduje také počet výstupních proměnných. Takže v tomto případě bude matoucí matice 3×3.
 Matice zmatků pro vícetřídní klasifikátor
Matice zmatků pro vícetřídní klasifikátor
souhrn
Matice zmatků je skvělý systém hodnocení, protože poskytuje podrobné informace o výkonu klasifikačního algoritmu. Funguje dobře pro binární i vícetřídní klasifikátory, kde je třeba se starat o více než 2 parametry. Je snadné vizualizovat matoucí matici a pomocí matoucí matice můžeme generovat všechny ostatní metriky výkonu, jako je F skóre, přesnost, ROC a přesnost.
Můžete se také podívat na to, jak vybrat algoritmy ML pro regresní problémy.