Co je Google JAX? Vše, co potřebujete vědět
Google JAX, někdy označovaný jako Just After Execution, představuje framework vyvinutý společností Google s cílem urychlit procesy strojového učení.
Je koncipován jako knihovna pro programovací jazyk Python, která napomáhá rychlejšímu provádění úkolů v oblasti vědeckých výpočtů, transformací funkcí, hlubokého učení, budování neuronových sítí a dalších.
Co je Google JAX?
Základním stavebním kamenem pro výpočty v Pythonu je knihovna NumPy, která poskytuje všechny potřebné funkce, jako jsou agregace, operace s vektory, lineární algebra, manipulace s n-rozměrnými poli a maticemi a mnoho dalších sofistikovaných nástrojů.
Nicméně, co kdybychom mohli ještě více urychlit výpočty realizované pomocí NumPy, zejména při práci s rozsáhlými datovými soubory?
Existuje alternativa, která by fungovala srovnatelně efektivně na různých typech procesorů, jako jsou GPU nebo TPU, bez nutnosti modifikovat kód?
Jak by vypadalo řešení, které by dokázalo provádět komplexní transformace funkcí automaticky a s vyšší efektivitou?
Google JAX je právě taková knihovna, respektive framework, který se snaží toho dosáhnout a možná i překonat. Byl navržen s cílem optimalizovat výkon a zefektivnit provádění úkolů v oblasti strojového učení (ML) a hlubokého učení. Google JAX nabízí transformační funkce, které jej odlišují od ostatních knihoven ML a napomáhají pokročilým vědeckým výpočtům pro hluboké učení a neuronové sítě:
- Automatická diferenciace
- Automatická vektorizace
- Automatická paralelizace
- Just-in-time (JIT) kompilace
Jedinečné vlastnosti Google JAX
Všechny transformace využívají XLA (Accelerated Linear Algebra) pro dosažení vyššího výkonu a optimalizaci využití paměti. XLA je kompilátor specifický pro danou doménu, který optimalizuje lineární algebru a urychluje modely TensorFlow. Aplikace XLA na Python kód nevyžaduje žádné zásadní úpravy kódu!
Podívejme se detailněji na každou z těchto funkcí.
Funkce Google JAX
Google JAX přináší důležité skládací transformační funkce pro zvýšení výkonu a efektivnější realizaci úloh v oblasti hlubokého učení. Například automatická derivace umožňuje získání gradientu funkce a nalezení derivací libovolného řádu. Podobně automatická paralelizace a JIT pro paralelní spouštění více úkolů. Tyto transformace jsou klíčové pro aplikace v robotice, herním průmyslu a vědeckém výzkumu.
Skládací transformační funkce je čistá funkce, která transformuje vstupní data do jiné formy. Jsou nazývány skládací, protože jsou samostatné (tj. tyto funkce nejsou závislé na zbytku programu) a bezstavové (tj. stejný vstup vždy generuje stejný výstup).
Y(x) = T: (f(x))
V této rovnici f(x) reprezentuje původní funkci, na kterou se aplikuje transformace. Y(x) je výsledná funkce po aplikaci transformace.
Například, pokud máme funkci nazvanou 'total_bill_amt' a požadujeme transformovaný výsledek, můžeme použít požadovanou transformaci, například gradient (grad):
grad_total_bill = grad(total_bill_amt)
Transformováním numerických funkcí pomocí funkcí jako grad() můžeme snadno získat jejich deriváty vyšších řádů, které se hojně využívají v optimalizačních algoritmech hlubokého učení, jako je gradientní sestup, což urychluje a zefektivňuje algoritmy. Stejně tak pomocí jit() můžeme kompilovat Python programy just-in-time (líně).
#1. Automatická diferenciace
Python využívá funkci autograd k automatickému odvozování NumPy a nativního Python kódu. JAX používá modifikovanou verzi autogradu (tj. grad) a kombinuje ji s XLA (Accelerated Linear Algebra) pro provádění automatické diferenciace a hledání derivátů libovolného řádu pro GPU (Graphic Processing Units) a TPU (Tensor Processing Units).
Rychlá poznámka k TPU, GPU a CPU: CPU, neboli centrální procesorová jednotka, řídí veškeré operace v počítači. GPU je pomocný procesor, který zvyšuje výpočetní výkon a je vhodný pro náročné operace. TPU je výkonná jednotka speciálně vyvinutá pro komplexní úlohy, jako je umělá inteligence a algoritmy hlubokého učení.
Stejně jako autograd, který dokáže rozlišovat pomocí smyček, rekurzí a podmínek, používá JAX funkci grad() pro gradienty v obráceném režimu (zpětné šíření). Dále můžeme funkci odvodit na libovolný řád pomocí grad:
grad(grad(grad(sin θ))) (1.0)
Automatická diferenciace vyššího řádu
Jak již bylo zmíněno, grad je užitečný pro hledání parciálních derivací funkce. Parciální derivaci můžeme využít k výpočtu gradientu sestupu nákladové funkce s ohledem na parametry neuronové sítě v hlubokém učení, s cílem minimalizovat ztráty.
Výpočet parciální derivace
Předpokládejme, že funkce má více proměnných x, y a z. Hledání derivace jedné proměnné při zachování ostatních konstantních se nazývá parciální derivace. Předpokládejme, že máme funkci:
f(x,y,z) = x + 2y + z2
Příklad pro ilustraci parciální derivace
Parciální derivace x bude ∂f/∂x, což nám ukazuje, jak se funkce mění v závislosti na této proměnné, zatímco ostatní zůstávají konstantní. Pokud bychom to dělali ručně, museli bychom napsat program pro diferenciaci, aplikovat jej na každou proměnnou a následně vypočítat sestup gradientu. Pro větší počet proměnných by se to stalo náročným a časově náročným úkolem.
Automatická derivace rozkládá funkci na sadu elementárních operací, jako jsou +, -, *, /, sin, cos, tan, exp atd., a následně použije řetězové pravidlo pro výpočet derivace. Lze to provést v dopředném i zpětném režimu.
To není vše! Všechny tyto výpočty probíhají velmi rychle (zvažte miliony podobných výpočtů a čas, který by to mohlo trvat!). XLA se stará o rychlost a výkon.
#2. Zrychlená lineární algebra
Vezměme si předchozí rovnici. Bez XLA by výpočet probíhal na třech (nebo více) jádrech, kde každé jádro by vykonávalo menší dílčí úlohu. Například:
Jádro k1 –> x * 2y (násobení)
k2 –> x * 2y + z (sčítání)
k3 –> Snížení
Pokud stejný úkol provádí XLA, jediné jádro se postará o všechny mezioperační kroky sloučením operací. Mezivýsledky základních operací jsou streamovány místo ukládání do paměti, čímž se šetří paměť a zvyšuje rychlost.
#3. Kompilace just-in-time
JAX interně využívá kompilátor XLA pro zvýšení rychlosti výpočtů. XLA dokáže urychlit výpočty na CPU, GPU i TPU. To je možné díky provádění kódu JIT. Pro jeho využití je třeba importovat jit:
from jax import jit def my_function(x): …………nějaký kód my_function_jit = jit(my_function)
Dalším způsobem je použití dekorátoru jit nad definicí funkce:
@jit def my_function(x): …………nějaký kód
Tento kód je mnohem rychlejší, protože transformace vrátí zkompilovanou verzi kódu volajícímu, namísto interpretace Pythonu. Je to zvláště užitečné pro vektorové vstupy, jako jsou pole a matice.
Totéž platí pro existující funkce Pythonu, například ty z balíčku NumPy. V tomto případě bychom měli importovat jax.numpy jako jnp místo NumPy:
import jax import jax.numpy as jnp x = jnp.array([[1,2,3,4], [5,6,7,8]])
Jakmile to provedete, standardní pole NumPy je nahrazeno základním polem JAX, nazývaným DeviceArray. DeviceArray je líný – hodnoty jsou uchovávány v akcelerátoru, dokud nejsou potřeba. To také znamená, že program JAX nečeká, až se výsledky vrátí volajícímu (Python) programu, takže se jedná o asynchronní odeslání.
#4. Automatická vektorizace (vmap)
V typickém scénáři strojového učení pracujeme s datovými sadami obsahujícími milion nebo více datových bodů. Je pravděpodobné, že budeme provádět určité výpočty nebo manipulace s každým nebo většinou z těchto datových bodů – což je časově a paměťově náročný úkol! Například, pokud chceme získat druhou mocninu každého datového bodu v datové sadě, napadne nás vytvořit smyčku a počítat druhou mocninu jednoho po druhém – hrůza!
Pokud bychom tyto body vytvořili jako vektory, mohli bychom provést všechny výpočty najednou pomocí vektorových nebo maticových manipulací s datovými body za použití oblíbené knihovny NumPy. A co kdyby to váš program dokázal automaticky – chtěli byste něco víc? To je přesně to, co JAX dokáže! Dokáže automaticky vektorizovat všechny vaše datové body, takže s nimi můžete snadno provádět jakékoli operace – vaše algoritmy jsou tak mnohem rychlejší a efektivnější.
JAX používá pro automatickou vektorizaci funkci vmap. Zvažme následující pole:
x = jnp.array([1,2,3,4,5,6,7,8,9,10]) y = jnp.square(x)
Provedením výše uvedeného se metoda druhé mocniny spustí pro každý bod v poli. Ale pokud provedeme následující:
vmap(jnp.square(x))
Metoda druhé mocniny se provede pouze jednou, protože datové body jsou před provedením funkce automaticky vektorizovány pomocí metody vmap a smyčkování je přesunuto níže na základní úroveň operace – výsledkem je maticové násobení namísto skalárního, což přináší lepší výkon.
#5. SPMD programování (pmap)
SPMD – neboli Single Program Multiple Data programování je klíčové v kontextu hlubokého učení – často byste použili stejné funkce na různé sady dat umístěné na více GPU nebo TPU. JAX má funkci nazvanou pmap, která umožňuje paralelní programování na více GPU nebo libovolném akcelerátoru. Stejně jako JIT budou programy využívající pmap kompilovány pomocí XLA a spouštěny současně v různých systémech. Tato automatická paralelizace funguje pro dopředné i zpětné výpočty.
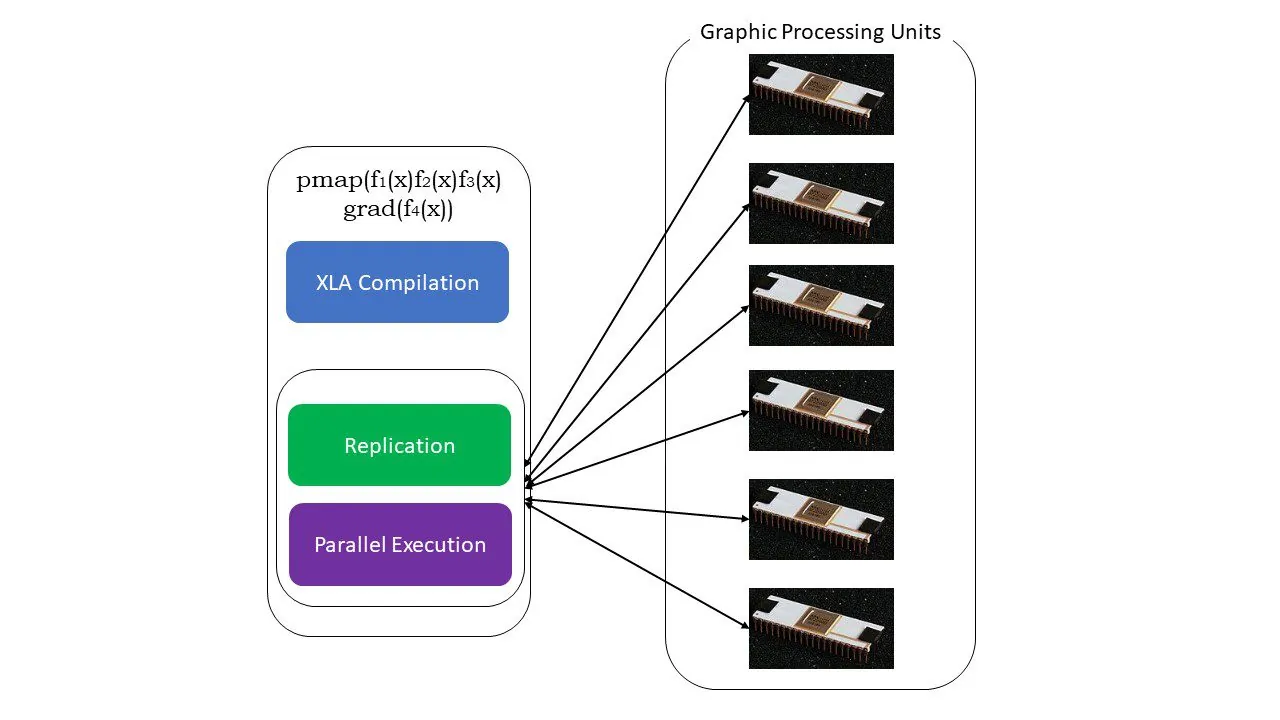 Jak funguje pmap
Jak funguje pmap
Můžeme také použít více transformací najednou v libovolném pořadí na libovolnou funkci, například:
pmap(vmap(jit(grad (f(x)))))
Vícenásobné skládací transformace
Omezení Google JAX
Vývojáři Google JAX vynaložili úsilí na urychlení algoritmů hlubokého učení a zároveň představili všechny tyto skvělé transformace. Vědecké výpočetní funkce a balíčky jsou na úrovni NumPy, takže se nemusíte obávat složité křivky učení. Nicméně, JAX má následující omezení:
- Google JAX je stále v rané fázi vývoje, a přestože jeho hlavním účelem je optimalizace výkonu, nenabízí výrazné výhody pro výpočetní procesory. Zdá se, že NumPy funguje lépe a použití JAX může pouze zvýšit režii.
- JAX je stále ve fázi výzkumu nebo v rané fázi vývoje a potřebuje další doladění, aby dosáhl infrastrukturních standardů frameworků, jako je TensorFlow, které jsou zavedenější a mají více předdefinovaných modelů, open source projektů a výukových materiálů.
- V současné době JAX nepodporuje operační systém Windows – pro jeho použití byste potřebovali virtuální stroj.
- JAX funguje pouze s čistými funkcemi – tedy s funkcemi, které nemají žádné vedlejší efekty. Pro funkce s vedlejšími efekty nemusí být JAX vhodnou volbou.
Jak nainstalovat JAX ve vašem prostředí Pythonu
Pokud máte ve svém systému nastavený Python a chcete spustit JAX na místním počítači (CPU), použijte následující příkazy:
pip install --upgrade pip pip install --upgrade "jax[cpu]"
Pokud chcete spustit Google JAX na GPU nebo TPU, postupujte podle pokynů uvedených na stránce GitHub JAX. Pro nastavení Pythonu navštivte oficiální stránku stahování Pythonu.
Závěr
Google JAX je vynikající nástroj pro psaní efektivních algoritmů hlubokého učení, robotiky a výzkumu. Navzdory svým omezením je široce používán s dalšími frameworky, jako je Haiku, Flax a dalšími. Výhody JAX oceníte zejména při spouštění programů a porovnání časových rozdílů při provádění kódu s JAX a bez něj. Můžete začít čtením oficiální dokumentace Google JAX, která je poměrně obsáhlá.
