Co je posilovací učení?
V současném světě umělé inteligence (AI) je učení posilováním (RL) považováno za jednu z nejvíce fascinujících oblastí výzkumu. Odborníci v oblasti AI a strojového učení (ML) se intenzivně zaměřují na metody RL pro vylepšení inteligentních aplikací a nástrojů, které vyvíjejí.
Základním kamenem všech produktů AI je strojové učení. Vývojáři využívají rozmanité techniky ML k trénování inteligentních aplikací, her a dalších. ML je rozsáhlá a pestrá oblast, kde různé vývojové týmy neustále přicházejí s novými přístupy k tréninku strojů.
Jednou z vysoce efektivních metod ML je hluboké učení, které spočívá v penalizaci nežádoucího chování stroje a naopak, v odměňování žádoucího jednání inteligentního stroje. Odborníci věří, že tato metoda ML umožňuje umělé inteligenci učit se na základě vlastních zkušeností.
Pokud se zajímáte o kariéru v oblasti umělé inteligence a strojového učení, tento obsáhlý průvodce metodami posilování učení pro inteligentní aplikace a stroje by pro vás mohl být užitečný.
Co je to posilování učení ve strojovém učení?
RL se zaměřuje na trénování modelů strojového učení pro počítačové programy. Na základě těchto modelů pak aplikace provádí sérii rozhodnutí. Software se učí dosahovat cílů v potenciálně komplexním a nejistém prostředí. V tomto typu modelu strojového učení se AI nachází v situaci podobné hře.
Aplikace AI využívá metodu pokusů a omylů k nalezení kreativního řešení daného problému. Jakmile se aplikace AI naučí správné modely ML, instruuje stroj, který ovládá, aby provedl úkoly definované programátorem.
Za správné rozhodnutí a splnění úkolu obdrží AI odměnu. Naopak, za nesprávné rozhodnutí čelí sankcím, jako je ztráta bodů za odměnu. Hlavním cílem aplikace AI je nashromáždit co nejvíce bodů odměn pro výhru v dané hře.
Programátor aplikace AI určuje pravidla hry nebo principy odměn a také definuje problém, který má AI vyřešit. Na rozdíl od jiných modelů ML program AI nedostává žádnou nápovědu od programátora softwaru.
Umělá inteligence si musí sama najít způsob, jak vyřešit herní výzvy a získat maximální odměny. Aplikace může využívat metodu pokusů a omylů, náhodné pokusy, superpočítačové schopnosti a sofistikované taktiky myšlenkových procesů k nalezení řešení.
Pro správnou funkci programu AI je nezbytné poskytnout mu výkonnou výpočetní infrastrukturu a propojit jeho myšlenkový systém s různými paralelními a historickými hrami. Díky tomu může umělá inteligence prokázat vysokou úroveň kritické kreativity, kterou si lidé často nedokážou představit.
Známé příklady posilování učení
#1. Porážka nejlepšího lidského hráče Go
AlphaGo AI od DeepMind Technologies, dceřiné společnosti Google, je jedním z hlavních příkladů strojového učení založeného na RL. AI hraje čínskou deskovou hru s názvem Go, která je 3000 let stará a vyžaduje taktiku a strategii.
Programátoři použili metodu RL pro výuku AlphaGo. Odehrála tisíce herních sezení Go s lidmi i sama se sebou. V roce 2016 pak porazila tehdejšího světového hráče Go Lee Se-dola v přímém souboji.
#2. Robotika v reálném světě
Roboty se dlouhodobě využívají ve výrobních linkách, kde jsou úkoly předem naplánovány a opakují se. Avšak vytvoření univerzálního robota pro reálný svět, kde akce nejsou předem dané, představuje velkou výzvu.
Nicméně umělá inteligence, podporovaná učením, může nalézt plynulou, schůdnou a nejkratší cestu mezi dvěma body.
#3. Autonomní vozidla
Výzkumníci autonomních vozidel často využívají metodu RL k trénování svých AI pro:
- Dynamické plánování trasy
- Optimalizaci trajektorie
- Plánování pohybu, například parkování a změna jízdního pruhu
- Optimalizaci ovladačů, (elektronické řídící jednotky) ECU, (mikrokontroléry) MCU atd.
- Učení na základě scénářů na dálnicích
#4. Automatizované chladicí systémy

AI založená na RL může pomoci minimalizovat spotřebu energie chladicích systémů v rozlehlých kancelářských budovách, obchodních centrech, nákupních galeriích a především v datových centrech. AI shromažďuje data z tisíců teplotních senzorů.
Získává také informace o lidských i strojních aktivitách. Z těchto dat dokáže AI předvídat budoucí produkci tepla a podle toho automaticky zapínat a vypínat chladicí systémy, čímž šetří energii.
Jak nastavit model posilování učení
RL model lze nastavit pomocí následujících metod:
#1. Na základě zásad
Tento přístup umožňuje programátorovi AI najít optimální strategii pro dosažení maximálních odměn. Programátor zde nepoužívá funkci hodnoty. Po nastavení metody založené na zásadách se agent posilování učení snaží implementovat zásady tak, aby akce, které provádí v každém kroku, umožnily AI maximalizovat body odměn.
Existují dva hlavní typy zásad:
#1. Deterministické: Zásada může vyvolat stejné akce v jakémkoli daném stavu.
#2. Stochastické: Vyvolané akce jsou definovány pravděpodobností výskytu.
#2. Na základě hodnoty
Přístup založený na hodnotách naproti tomu pomáhá programátorovi nalézt optimální hodnotovou funkci, která představuje maximální hodnotu v rámci dané strategie v každém konkrétním stavu. Po implementaci RL agent očekává dlouhodobý výnos v jednom nebo více stavech v rámci stanovené strategie.
#3. Na základě modelu
V přístupu založeném na modelu vytváří programátor AI virtuální model prostředí. Agent RL se pak pohybuje v tomto prostředí a učí se z něj.
Druhy posilování učení
#1. Pozitivní posilování učení (PRL)
Pozitivní učení znamená přidávání prvků, které zvyšují pravděpodobnost opakování očekávaného chování. Tato metoda učení má pozitivní dopad na chování agenta RL a posiluje určité chování vaší AI.
PRL by mělo připravit AI na dlouhodobé přizpůsobování se změnám. Příliš mnoho pozitivního učení však může vést k přetížení stavů, což může snížit efektivitu AI.
#2. Negativní posilování učení (NRL)
Když algoritmus RL pomáhá AI vyhnout se negativnímu chování nebo ho zastavit, AI se učí a zlepšuje své budoucí akce. Tento proces se nazývá negativní učení, které dává AI omezenou inteligenci pro splnění specifických požadavků na chování.
Případy použití posilování učení v reálném životě
#1. Vývojáři eCommerce řešení vytvářejí personalizované nástroje pro doporučování produktů nebo služeb. API tohoto nástroje můžete integrovat do svého webu pro online nákupy. AI se pak učí od jednotlivých uživatelů a navrhuje jim na míru šité zboží a služby.
#2. Videohry s otevřeným světem nabízejí neomezené možnosti. Nicméně v pozadí herního kódu je AI program, který se učí z interakcí hráčů a upravuje kód hry tak, aby se přizpůsobil neznámým situacím.
#3. Platformy pro obchodování s akciemi a investiční platformy založené na AI používají model RL k učení se z pohybů akcií a globálních indexů. Na základě toho formulují pravděpodobnostní model, který navrhuje akcie pro investování nebo obchodování.
#4. Online videotéky, jako je YouTube, Metacafe, Dailymotion atd., používají AI roboty trénované na modelu RL k doporučování personalizovaných videí svým uživatelům.
Posilování učení vs. učení s dohledem
Posilování učení se zaměřuje na trénink AI agenta k postupnému rozhodování. Ve zkratce, výstup AI je závislý na aktuálním stavu vstupu. Podobně, další vstup do RL algoritmu je odvislý od výstupu minulých vstupů.

Robotický stroj s umělou inteligencí, který hraje šachovou partii proti lidskému šachistovi, je příkladem modelu strojového učení RL.
Naopak, v učení s dohledem programátor trénuje AI agenta k rozhodování na základě vstupů zadaných na začátku nebo z jakéhokoli jiného iniciálního vstupu. AI pro autonomní řízení vozidla, která rozpoznává okolní objekty, je typickým příkladem učení s dohledem.
Posilování učení vs. učení bez dohledu
Zatím jste se dozvěděli, že metoda RL nutí AI agenta učit se na základě principů modelu strojového učení. AI obvykle provádí kroky, které jí přinesou maximální odměnu. RL pomáhá AI zlepšovat se prostřednictvím metody pokusů a omylů.
Na druhou stranu, v učení bez dohledu programátor předkládá AI software neoznačená data. Instruktor ML také neříká AI nic o struktuře dat nebo o tom, co má v datech hledat. Algoritmus se učí různá rozhodnutí tím, že kategorizuje své vlastní pozorování na základě neznámých datových sad.
Kurzy posilování učení
Nyní, když jste se seznámili se základy, zde jsou online kurzy, které vám pomohou proniknout do pokročilého posilování učení. Získáte také certifikát, který můžete prezentovat na LinkedIn nebo jiných sociálních sítích:
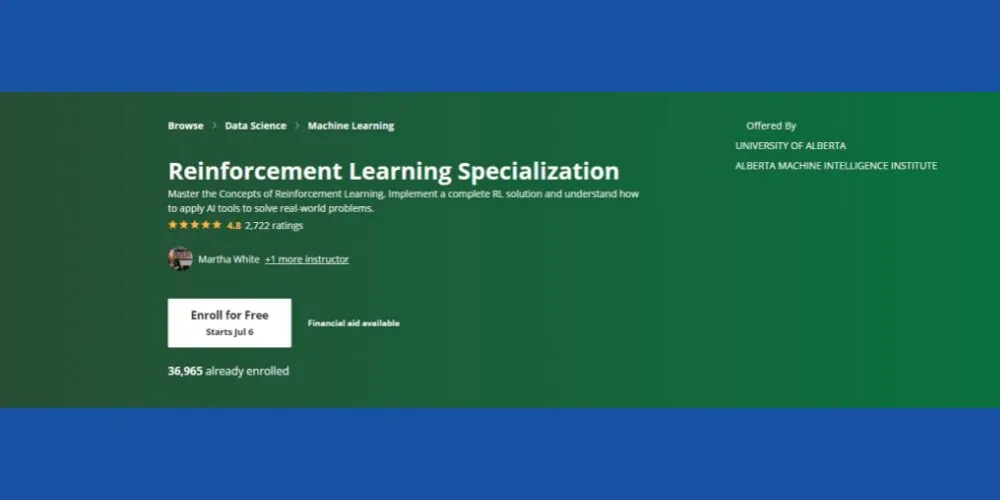
Specializace posilování učení: Coursera
Chcete se seznámit se základními koncepty posilování učení v kontextu ML? Můžete vyzkoušet kurz Coursera RL, který je dostupný online a nabízí možnost samostudia s certifikací. Kurz bude pro vás vhodný, pokud máte následující dovednosti:
- Znalost programování v Pythonu
- Základní statistické pojmy
- Schopnost převést pseudokódy a algoritmy na kódy Pythonu
- Dva až tři roky zkušeností s vývojem softwaru
- Studenti druhého ročníku oboru informatiky jsou také způsobilí
Kurz má hodnocení 4,8 hvězdiček a už se do něj zapsalo více než 36 000 studentů v různých časových obdobích. Kurz navíc nabízí finanční podporu za předpokladu, že uchazeč splní určitá kritéria způsobilosti Coursera.
Kurz je poskytován univerzitou Alberta Machine Intelligence Institute University of Alberta (bez přidělení kreditů). V roli lektorů zde působí uznávaní profesoři v oblasti informatiky. Po absolvování kurzu získáte certifikát Coursera.
Posilování učení AI v Pythonu: Udemy
Pokud se pohybujete na finančním trhu nebo v digitálním marketingu a chcete vytvářet inteligentní softwarové balíčky pro tyto oblasti, měli byste zvážit tento kurz RL na Udemy. Kromě základních principů RL vás školicí obsah naučí, jak vyvíjet RL řešení pro online reklamu a obchodování s akciemi.

Mezi významná témata, která kurz pokrývá, patří:
- Přehled RL na vysoké úrovni
- Dynamické programování
- Monet Carlo
- Aproximační metody
- Projekt obchodování s akciemi pomocí RL
Kurz absolvovalo dosud přes 42 tisíc studentů. Tento online zdroj výuky má aktuálně 4,6 hvězdičkové hodnocení, což je velmi působivé. Kurz se navíc snaží oslovit globální studentskou komunitu, neboť učební obsah je dostupný ve francouzštině, angličtině, španělštině, němčině, italštině a portugalštině.
Hluboké posilování učení v Pythonu: Udemy
Pokud máte zájem a základní znalosti hlubokého učení a AI, můžete vyzkoušet tento pokročilý RL kurz v Pythonu od Udemy. S hodnocením 4,6 hvězdiček od studentů jde o další oblíbený kurz pro výuku RL v kontextu AI/ML.

Kurz má 12 sekcí a zahrnuje následující důležitá témata:
- OpenAI Gym a základní techniky RL
- TD Lambda
- A3C
- Základy Theano
- Základy Tensorflow
- Programování v Pythonu pro začátečníky
Celý kurz zabere 10 hodin a 40 minut studia a zahrnuje také 79 odborných přednášek.
Expert na hluboké posilování: Udacity
Chcete se učit pokročilé strojové učení od světových lídrů v oblasti AI/ML, jako jsou Nvidia Deep Learning Institute a Unity? Udacity vám umožní splnit si tento sen. Podívejte se na tento kurz hlubokého posilování učení, díky kterému se stanete odborníkem na ML.

Nicméně je nezbytné mít pokročilé znalosti Pythonu, středně pokročilé znalosti statistiky, teorie pravděpodobnosti a umět pracovat s TensorFlow, PyTorch a Keras.
Dokončení kurzu vyžaduje intenzivní studium po dobu až 4 měsíců. V průběhu kurzu se naučíte důležité algoritmy RL, jako jsou Deep Deterministic Policy Gradients (DDPG), Deep Q-Networks (DQN) atd.
Závěrečné poznámky
Posilování učení je dalším krokem ve vývoji AI. Agentury pro vývoj umělé inteligence a IT společnosti do tohoto sektoru investují s cílem vyvinout spolehlivé a důvěryhodné metodologie pro školení umělé inteligence.
I když RL učinilo velký pokrok, stále existuje mnoho oblastí pro další rozvoj. Například samostatní agenti RL mezi sebou nesdílejí informace. Pokud tedy trénujete aplikaci pro řízení automobilu, proces učení se zpomalí, protože agenti RL, kteří provádějí detekci objektů, odkazy na silnice atd., nesdílejí data.
Existují příležitosti, kde můžete uplatnit svou kreativitu a odborné znalosti v oblasti ML. Zápis do online kurzů vám pomůže prohloubit znalosti pokročilých metod RL a jejich uplatnění v reálných projektech.
Dalším souvisejícím tématem pro vaše studium jsou rozdíly mezi umělou inteligencí, strojovým učením a hlubokým učením.
