

1. září 2020 NVIDIA odhalila svou novou řadu herních GPU: řadu RTX 3000, založenou na jejich Ampere architektuře. Probereme, co je nového, software poháněný umělou inteligencí, který je s ním dodáván, a všechny detaily, díky kterým je tato generace opravdu úžasná.
Table of Contents
Seznamte se s GPU řady RTX 3000

Hlavním oznámením společnosti NVIDIA byly její zbrusu nové GPU, všechny postavené na zakázkovém 8nm výrobním procesu a všechny přinesly výrazné zrychlení jak v oblasti rasterizace, tak výkonu ray-tracingu.
Na spodním konci sestavy je RTX 3070, který přijde na 499 dolarů. Je to trochu drahé na nejlevnější kartu, kterou NVIDIA představila při prvním oznámení, ale je to absolutní krádež, jakmile zjistíte, že překonává stávající RTX 2080 Ti, špičkovou kartu, která se pravidelně prodává za více než 1400 $. Po oznámení společnosti NVIDIA však prodejní ceny třetích stran klesly, přičemž velký počet z nich byl panicky prodán na eBay pod 600 $.
Od oznámení nejsou k dispozici žádné solidní benchmarky, takže není jasné, zda je karta skutečně objektivně „lepší“ než 2080 Ti, nebo zda NVIDIA trochu překrucuje marketing. Spouštěné benchmarky byly ve 4K a pravděpodobně měly zapnutý RTX, což může způsobit, že mezera bude vypadat větší, než bude v čistě rasterovaných hrách, protože řada 3000 založená na Ampere bude fungovat dvakrát lépe při sledování paprsků než Turing. Ale vzhledem k tomu, že ray tracing je nyní něčím, co výkon příliš neubírá a je podporováno v nejnovější generaci konzolí, je hlavním prodejním argumentem, že běží stejně rychle jako vlajková loď poslední generace za téměř třetinovou cenu.
Není také jasné, zda cena zůstane taková. Návrhy třetích stran pravidelně přidávají k cenovce alespoň 50 USD a s tím, jak vysoká bude pravděpodobně poptávka, nebude překvapením, že se v říjnu 2020 bude prodávat za 600 USD.
Těsně nad tím je RTX 3080 za 699 $, což by mělo být dvakrát rychlejší než RTX 2080 a mělo by být o 25–30 % rychlejší než 3080.
Pak na horním konci je nová vlajková loď RTX 3090, který je komicky obrovský. NVIDIA si je dobře vědoma a označuje to jako „BFGPU“, což společnost říká, že znamená „Big Ferocious GPU“.

NVIDIA nepředvedla žádné přímé metriky výkonu, ale společnost ukázala, že běží 8K hry při 60 FPS, což je vážně působivé. Je pravda, že NVIDIA téměř jistě používá DLSS, aby dosáhla této značky, ale hraní v 8K je hraní v 8K.
Samozřejmě, že nakonec bude 3060 a další varianty více rozpočtových karet, ale ty obvykle přijdou později.
Aby NVIDIA skutečně chladila věci, potřebovala přepracovaný design chladiče. 3080 je dimenzován na 320 wattů, což je poměrně vysoká hodnota, takže NVIDIA se rozhodla pro konstrukci se dvěma ventilátory, ale místo obou ventilátorů vwinf umístěných na spodní straně NVIDIA umístila ventilátor na horní konec, kam obvykle jde zadní deska. Ventilátor směřuje vzduch nahoru k chladiči CPU a horní části skříně.

Soudě podle toho, jak moc může být výkon ovlivněn špatným prouděním vzduchu v pouzdře, to dává dokonalý smysl. Obvodová deska je však kvůli tomu velmi stísněná, což pravděpodobně ovlivní prodejní ceny třetích stran.
DLSS: Softwarová výhoda
Ray tracing není jedinou výhodou těchto nových karet. Opravdu, je to všechno trochu hack – řady RTX 2000 a 3000 nejsou o tolik lepší v provádění skutečného sledování paprsků ve srovnání se staršími generacemi karet. Ray tracing celé scény ve 3D softwaru, jako je Blender, obvykle trvá několik sekund nebo dokonce minut na snímek, takže jeho hrubé vynucení pod 10 milisekund nepřipadá v úvahu.
Samozřejmostí je vyhrazený hardware pro spouštění paprskových výpočtů, nazývaný RT jádra, ale z velké části se NVIDIA rozhodla pro jiný přístup. NVIDIA vylepšila odšumovací algoritmy, které umožňují GPU vykreslit velmi levný jednotlivý průchod, který vypadá hrozně, a nějak – prostřednictvím AI magie – z toho udělat něco, na co se chce hráč podívat. V kombinaci s tradičními technikami založenými na rasterizaci vytváří příjemný zážitek umocněný efekty raytracingu.

Aby to však bylo rychlé, NVIDIA přidala procesorová jádra specifická pro AI nazývaná jádra Tensor. Ty zpracovávají veškerou matematiku potřebnou ke spuštění modelů strojového učení a dělají to velmi rychle. Jsou celkem herní měnič pro AI v prostoru cloudového serveru, protože AI je široce používána mnoha společnostmi.
Kromě odšumování se hlavní využití jader Tensor pro hráče nazývá DLSS, neboli hluboké učení super vzorkování. Vezme nekvalitní rám a upscaluje jej na plně nativní kvalitu. To v podstatě znamená, že můžete hrát se snímkovými frekvencemi na úrovni 1080p a přitom se dívat na obraz 4K.
To také dost pomáhá s výkonem ray-tracingu –benchmarky z PCMag ukažte RTX 2080 Super running Control v ultra kvalitě se všemi nastaveními sledování paprsku na maximum. Ve 4K se potýká pouze s 19 FPS, ale se zapnutým DLSS dostane mnohem lepších 54 FPS. DLSS je bezplatný výkon pro NVIDIA, který umožňují jádra Tensor na Turing a Ampere. Každá hra, která to podporuje a je omezena na GPU, může zaznamenat výrazné zrychlení pouze díky softwaru.
DLSS není novinkou a bylo oznámeno jako funkce, když byla před dvěma lety uvedena řada RTX 2000. V té době jej podporovalo jen velmi málo her, protože vyžadovalo, aby NVIDIA trénovala a ladila model strojového učení pro každou jednotlivou hru.
Za tu dobu jej však NVIDIA zcela přepsala a novou verzi nazvala DLSS 2.0. Je to API pro všeobecné použití, což znamená, že jej může implementovat každý vývojář a většina hlavních verzí jej již využívá. Spíše než na jednom snímku přebírá pohybová vektorová data z předchozího snímku, podobně jako TAA. Výsledek je mnohem ostřejší než DLSS 1.0 a v některých případech skutečně vypadá lépe a ostřeji než dokonce i nativní rozlišení, takže není moc důvodů jej nezapínat.
Má to jeden háček – při úplném přepínání scén, jako u cutscén, musí DLSS 2.0 vykreslit úplně první snímek v 50% kvalitě, zatímco čeká na data pohybového vektoru. To může mít za následek nepatrný pokles kvality na několik milisekund. Ale 99 % všeho, na co se podíváte, bude vykresleno správně a většina lidí si toho v praxi nevšimne.
Ampere Architecture: Postaveno pro AI
Ampér je rychlý. Vážně rychlé, zvláště při výpočtech AI. Jádro RT je 1,7x rychlejší než Turing a nové jádro Tensor je 2,7x rychlejší než Turing. Kombinace těchto dvou je skutečným generačním skokem ve výkonu raytracingu.

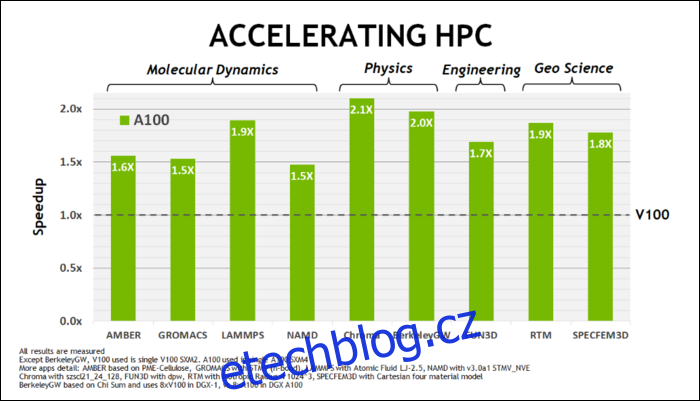
Začátkem tohoto května, NVIDIA vydala Ampere A100 GPU, GPU datového centra navržené pro běh AI. S ním podrobně popsali mnohé z toho, co dělá Ampere mnohem rychlejším. Pro datová centra a vysoce výkonné výpočetní úlohy je Ampere obecně asi 1,7x rychlejší než Turing. Pro trénink AI je to až 6x rychlejší.
S Ampere používá NVIDIA nový formát čísel navržený tak, aby v některých pracovních zátěžích nahradil průmyslový standard „Floating-Point 32“ nebo FP32. Pod kapotou každé číslo, které váš počítač zpracuje, zabírá předem definovaný počet bitů v paměti, ať už je to 8 bitů, 16 bitů, 32, 64 nebo dokonce větší. Čísla, která jsou větší, se hůře zpracovávají, takže pokud můžete použít menší velikost, budete mít méně na křupání.
FP32 ukládá 32bitové dekadické číslo a používá 8 bitů pro rozsah čísla (jak velký nebo malý může být) a 23 bitů pro přesnost. NVIDIA tvrdí, že těchto 23 přesných bitů není pro mnoho úloh s umělou inteligencí zcela nezbytných a že z pouhých 10 z nich můžete získat podobné výsledky a mnohem lepší výkon. Snížení velikosti na pouhých 19 bitů namísto 32 znamená velký rozdíl v mnoha výpočtech.
Tento nový formát se nazývá Tensor Float 32 a jádra Tensor v A100 jsou optimalizována tak, aby zvládla podivně velký formát. To je, kromě úbytků kostek a zvýšení počtu jader, způsob, jakým dosahují obrovského 6násobného zrychlení ve výcviku AI.

Kromě nového číselného formátu zaznamenává Ampere výrazné zrychlení výkonu ve specifických výpočtech, jako jsou FP32 a FP64. Ty se pro laika přímo nepřekládají na více FPS, ale jsou součástí toho, co dělá to téměř třikrát rychlejší celkově při operacích Tensor.

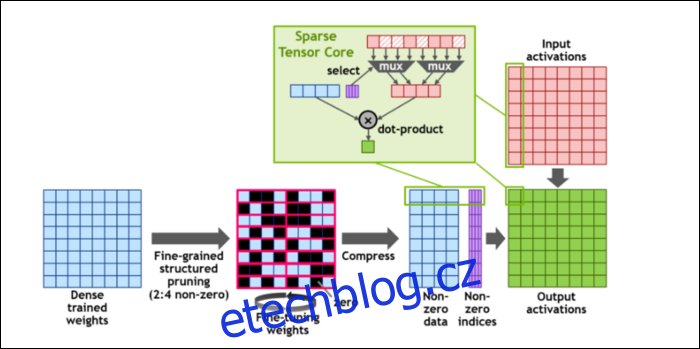
Poté, aby výpočty ještě více urychlili, zavedli koncept jemnozrnná strukturovaná řídkost, což je velmi efektní slovo pro docela jednoduchý koncept. Neuronové sítě pracují s velkými seznamy čísel, nazývaných váhy, které ovlivňují konečný výstup. Čím více čísel křoupat, tím pomaleji to bude.
Ne všechna tato čísla jsou však skutečně užitečná. Některé z nich jsou doslova jen nulové a lze je v podstatě vyhodit, což vede k masivnímu zrychlení, když můžete schoulit více čísel současně. Sparity v podstatě komprimuje čísla, což vyžaduje méně úsilí na provádění výpočtů. Nové „Sparse Tensor Core“ je vytvořeno pro práci s komprimovanými daty.
Navzdory změnám NVIDIA říká, že by to nemělo znatelně ovlivnit přesnost trénovaných modelů.
Pro výpočty Sparse INT8, jeden z nejmenších číselných formátů, je špičkový výkon jediného GPU A100 více než 1,25 PetaFLOPs, což je neuvěřitelně vysoké číslo. Samozřejmě, že je to jen při drcení jednoho konkrétního druhu čísla, ale přesto je to působivé.