Jak automatizovat organizaci přístupových práv v rámci AWS S3 Bucket ve 3 jednoduchých krocích
V minulosti, kdy se v podnikových prostředích běžně používaly unixové servery s rozsáhlými souborovými systémy, musely firmy vytvářet detailní pravidla pro organizaci složek a strategie pro řízení přístupových práv k různým adresářům pro rozmanité skupiny uživatelů.
Platforma každé organizace typicky obsluhuje různorodé skupiny uživatelů s odlišnými požadavky, omezeními týkajícími se citlivosti dat nebo specifikacemi obsahu. U globálních společností to může zahrnovat i segregaci obsahu podle lokality, a tedy oddělení dat mezi uživateli z různých zemí.
Další typické příklady zahrnují:
- rozdělení dat mezi vývojová, testovací a produkční prostředí
- omezení přístupu k prodejním materiálům pro širokou veřejnost
- regulace přístupu k obsahu specifickému pro danou zemi, který nesmí být dostupný z jiných regionů
- správa přístupu k projektové dokumentaci, která je určena pouze pro úzký okruh osob, a podobně
Takových situací existuje bezpočet. Zkrátka, vždy je nutné efektivně řídit přístupová práva k souborům a datům pro všechny uživatele, kteří mají k platformě přístup.
V on-premise prostředích to byl běžný úkol. Správce souborového systému nastavil pravidla, použil potřebné nástroje a přiřadil uživatele do skupin. Tyto skupiny pak měly definovaný přístup k určeným složkám nebo diskovým oddílům, a to s právy pouze pro čtení, nebo pro čtení i zápis.
Při přechodu na cloudové platformy, jako je AWS, je zřejmé, že uživatelé mají stejné potřeby v oblasti omezení přístupu k datům. Avšak řešení tohoto problému musí být nyní jiné. Soubory se už nenacházejí na fyzických serverech, ale v cloudu (a potenciálně dostupné nejen pro celou organizaci, ale i globálně). Místo složek se data ukládají do S3 bucketů.
Následující text popisuje alternativní přístup k tomuto problému, který vychází z reálných zkušeností s navrhováním podobných řešení pro konkrétní projekt.
Jednoduchý, avšak značně manuální přístup
Jednou z cest, jak tento problém řešit bez automatizace, je přímočarý postup:
- Vytvořit samostatný bucket pro každou specifickou skupinu uživatelů.
- Nastavit přístupová práva tak, aby k danému S3 bucketu měla přístup pouze vybraná skupina.
Toto řešení je sice jednoduché a rychlé, avšak má svá omezení.
Standardně lze pod jedním AWS účtem vytvořit jen 100 S3 bucketů. Po odeslání požadavku na zvýšení limitu služeb je možné tento počet navýšit až na 1000. Pokud tyto limity nepředstavují pro váš případ implementace překážku, pak může každý uživatel vaší domény pracovat s vlastním S3 bucketem.
Potíže mohou nastat, když existují skupiny uživatelů s překrývajícími se zodpovědnostmi nebo uživatelé, kteří potřebují přistupovat k obsahu z více oblastí zároveň. Například:
- Analytici dat pracující s daty z několika různých oddělení, regionů apod.
- Testovací týmy pracující na projektech různých vývojových týmů.
- Uživatelé vytvářející reporty a dashboardy z dat z různých zemí ve stejném regionu.
Podobné situace se mohou objevovat neustále, protože potřeby organizací jsou různorodé.
Čím komplexnější bude seznam těchto potřeb, tím náročnější bude řízení přístupových práv. Bude nutné udílet různá přístupová práva různým skupinám uživatelů k různým S3 bucketům v organizaci. To si vyžádá dodatečné nástroje a možná i specializovaného administrátora, který bude spravovat seznamy přístupových práv a aktualizovat je při každé změně, což bude zvláště ve velkých organizacích velmi časté.
Jak tedy dosáhnout stejného výsledku organizovaněji a s větší mírou automatizace?
Pokud přístup založený na principu "bucket pro každou doménu" není vhodný, jakékoli jiné řešení povede ke sdílení bucketů mezi více skupinami uživatelů. V takovém případě je třeba implementovat logiku pro přidělování přístupových práv do prostoru, který lze dynamicky měnit či aktualizovat.
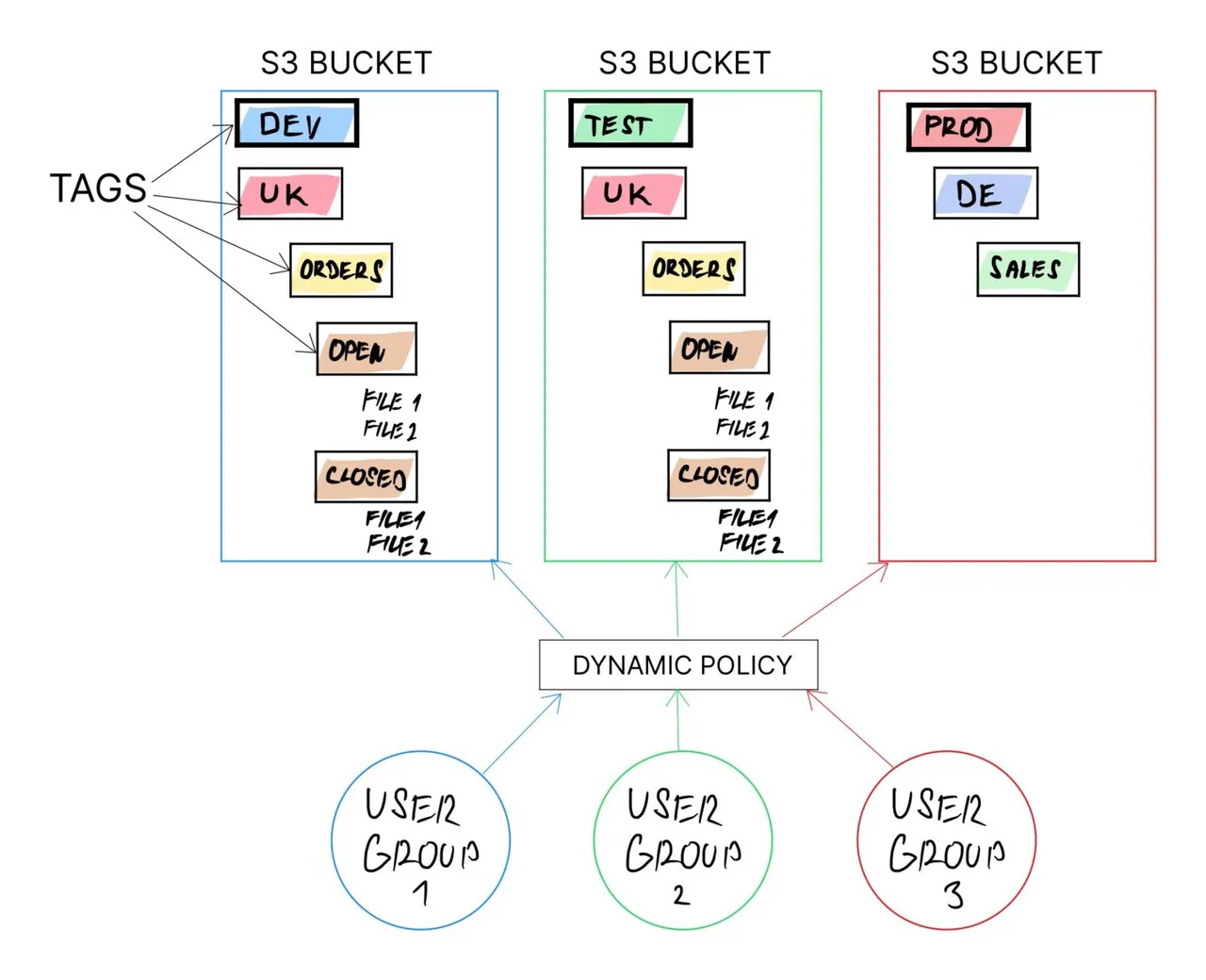
Jedním ze způsobů je využívání značek na S3 bucketech. Doporučuje se používat tagy pro jakýkoli účel (minimálně pro snadnější kategorizaci fakturace). Značku je možné kdykoli v budoucnu změnit u libovolného bucketu.
Pokud je celá logika založena na značkách bucketů a zbytek konfigurace je závislý na hodnotách tagů, je zajištěna dynamika řešení, neboť je možné redefinovat účel bucketu pouhou aktualizací hodnot značek.
Jaké značky použít, aby to fungovalo?
To záleží na konkrétních potřebách. Například:
- Možná budete potřebovat oddělit buckety podle typu prostředí. V tom případě by se jedna ze značek mohla jmenovat "ENV" a mít hodnoty jako "DEV", "TEST", "PROD" atd.
- Můžete chtít rozdělit týmy podle země. V takovém případě bude další značka "COUNTRY" a bude mít hodnotu odpovídající názvu dané země.
- Případně můžete chtít oddělit uživatele podle jejich funkčního zařazení, jako jsou obchodní analytici, uživatelé datových skladů, datoví specialisté apod. Vytvoříte tedy značku s názvem "USER_TYPE" a odpovídající hodnotou.
- Další možností je definovat pevně danou strukturu složek pro určité skupiny uživatelů. Můžete tak zabránit vytváření chaotické struktury složek. I to lze dosáhnout pomocí tagů, kde můžete definovat několik pracovních adresářů, jako například: "data/import", "data/processed", "data/error" atd.
Ideální je definovat tagy tak, aby je bylo možné logicky kombinovat a vytvořit z nich strukturu složek v bucketu.
Můžete například kombinovat následující značky z příkladů uvedených výše a vytvořit vyhrazenou strukturu složek pro různé typy uživatelů z různých zemí s předdefinovanými složkami pro import dat:
- /
/ / /
Pouhou změnou hodnoty
Tímto způsobem můžete používat jeden bucket pro mnoho různých uživatelů. Buckety sice explicitně nepodporují složky, ale podporují "štíky". Tyto štítky ve skutečnosti fungují jako podsložky, neboť uživatelé musí projít řadou štítků, aby se dostali k svým datům, stejně jako by to dělali s podsložkami.
Jakmile definujete značky v použitelné formě, dalším krokem je vytvoření zásad pro S3 bucket, které budou tyto tagy využívat.
Pokud zásady používají názvy značek, vytváříte "dynamické zásady". To znamená, že se zásada bude chovat odlišně pro buckety s různými hodnotami značek, na které zásada odkazuje.
Tento krok vyžaduje vlastní kódování dynamických zásad. Můžete však využít nástroj editoru zásad Amazon AWS, který vás celým procesem provede.
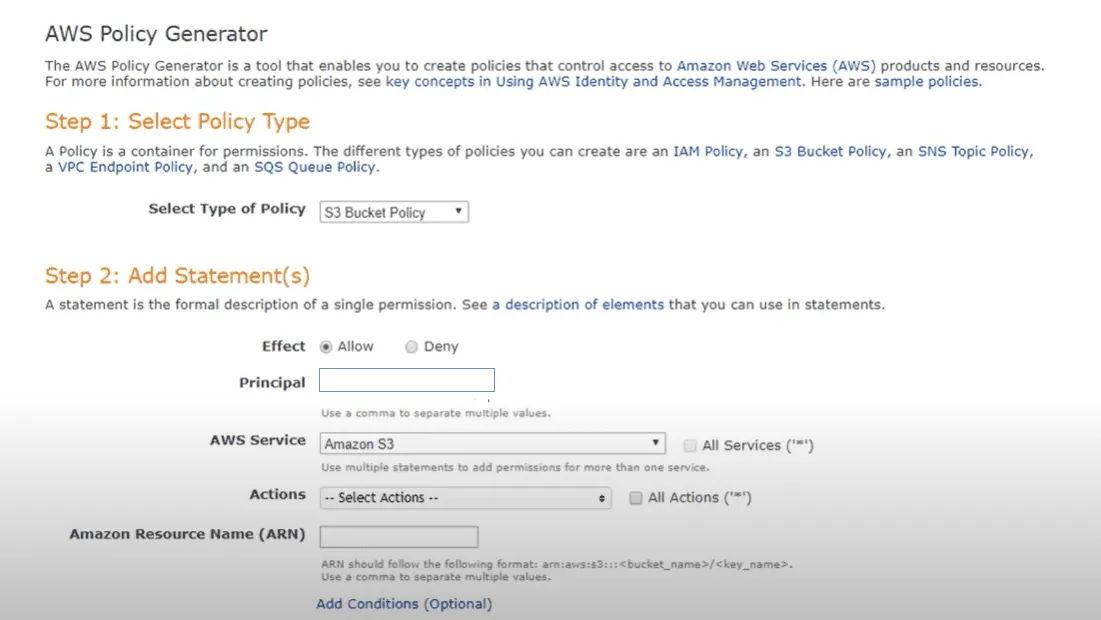
V samotné politice je potřeba nastavit specifická přístupová práva pro daný bucket a jejich úroveň (čtení, zápis). Logika bude číst tagy na bucketech a vytvářet strukturu složek v bucketu (vytváření štítků na základě tagů). Na základě hodnot tagů budou vytvořeny podsložky a budou jim přidělena potřebná přístupová práva.
Výhodou dynamické politiky je, že můžete vytvořit pouze jednu politiku a následně ji přiřadit k mnoha bucketům. Tato zásada se bude chovat odlišně pro buckety s různými hodnotami tagů, ale vždy bude odpovídat vašim očekáváním pro bucket s danými hodnotami tagů.
Je to velmi efektivní způsob, jak spravovat přidělování přístupových práv organizovaně a centralizovaně pro velké množství bucketů, u kterých se očekává, že budou dodržovat určité šablony, které byly předem dohodnuty a budou využívány vašimi uživateli v rámci celé organizace.
Automatizace nástupu nových subjektů
Po definování dynamických politik a jejich přiřazení k existujícím bucketům mohou uživatelé začít buckety používat bez obav, že by uživatelé z jiných skupin měli přístup k obsahu, který je uložen ve stejném bucketu, avšak ve složkách, ke kterým nemají mít přístup.
Pro některé skupiny uživatelů s širšími právy bude také snadné získávat data, neboť budou uložena ve stejném bucketu.
Posledním krokem je co nejvíce zjednodušit proces nástupu nových uživatelů, nových bucketů, i nových značek. To vyžaduje dodatečné kódování. Avšak za předpokladu, že váš onboarding proces má jasná pravidla, která lze zahrnout do algoritmu s přímočarou logikou, nemusí to být příliš složité.
Může jít o vytvoření skriptu spustitelného přes AWS CLI s parametry potřebnými pro úspěšné začlenění nového subjektu do platformy. Může to být i série CLI skriptů, které se spouštějí v určitém pořadí, například:
- create_new_bucket(
, , , , ..) - create_new_tag(
, , ) - update_existing_tag(
, , ) - create_user_group(
, , ) - atd.
Pointu chápete. 😃
Tip pro profesionály 👨💻
Pokud chcete, můžete na výše uvedené snadno aplikovat ještě jeden Pro Tip.
Dynamické zásady lze využít nejen pro přidělování přístupových práv k adresářům, ale také pro automatické přidělování přístupových práv ke službám pro skupiny a skupiny uživatelů!
Stačí jen rozšířit seznam značek na bucketech a poté přidat dynamická přístupová práva pro používání specifických služeb pro specifické skupiny uživatelů.
Například může existovat skupina uživatelů, která potřebuje přístup k serveru databázového clusteru. To lze dosáhnout dynamickými politikami, které využívají role a přiřazování do skupin. Stačí do kódu dynamické politiky přidat sekci, která zpracuje značky týkající se specifikace databázového clusteru a přímo přidělí přístupová práva k danému clusteru databáze a skupině uživatelů.
Tímto způsobem bude registrace nové skupiny uživatelů proveditelná pomocí této jediné dynamické politiky. A protože je dynamická, lze stejnou politiku znovu použít pro registrace mnoha různých skupin uživatelů (očekává se, že budou dodržovat stejnou šablonu, ale ne nutně stejné služby).
Můžete se také podívat na tyto AWS S3 příkazy pro správu bucketů a dat.
