

Před lety, když byly on-premise unixové servery s velkými souborovými systémy věcí, společnosti vytvářely rozsáhlá pravidla pro správu složek a strategie pro správu přístupových práv k různým složkám pro různé lidi.
Platforma organizace obvykle slouží různým skupinám uživatelů se zcela odlišnými zájmy, omezeními na úrovni důvěrnosti nebo definicemi obsahu. V případě globálních organizací by to mohlo dokonce znamenat oddělení obsahu na základě umístění, takže v podstatě mezi uživatele z různých zemí.
Další typické příklady mohou zahrnovat:
- oddělení dat mezi vývojovým, testovacím a produkčním prostředím
- prodejní obsah není přístupný širokému publiku
- legislativní obsah specifický pro danou zemi, který nelze zobrazit ani k němu nelze získat přístup z jiné oblasti
- obsah související s projektem, kde mají být „údaje o vedení“ poskytovány pouze omezené skupině lidí atd.
Existuje potenciálně nekonečný seznam takových příkladů. Jde o to, že vždy existuje určitá potřeba zorganizovat přístupová práva k souborům a datům mezi všemi uživateli, kterým platforma poskytuje přístup.
V případě on-premise řešení to byl rutinní úkol. Administrátor souborového systému jen nastavil nějaká pravidla, použil zvolený nástroj a pak byli lidé mapováni do uživatelských skupin a uživatelské skupiny byly mapovány do seznamu složek nebo přípojných bodů, ke kterým budou mít přístup. Zároveň byla úroveň přístupu definována jako přístup pouze pro čtení nebo přístup pro čtení a zápis.
Při pohledu na cloudové platformy AWS je zřejmé, že lidé budou mít podobné požadavky na omezení přístupu k obsahu. Řešení tohoto problému však nyní musí být jiné. Soubory již neodolávají na unixových serverech, ale v cloudu (a potenciálně přístupné nejen celé organizaci, ale dokonce celému světu) a obsah se neukládá do složek, ale do S3 bucketů.

Níže popsaná alternativa k tomuto problému. Je postaven na reálných zkušenostech, které jsem měl při navrhování takových řešení pro konkrétní projekt.
Table of Contents
Jednoduchý, ale rozsáhlý manuální přístup
Jeden způsob, jak tento problém vyřešit bez jakékoli automatizace, je poměrně přímočarý a jednoduchý:
- Vytvořte nový kbelík pro každou odlišnou skupinu lidí.
- Přidělte přístupová práva k bucketu, aby k bucketu S3 měla přístup pouze tato konkrétní skupina.
To je jistě možné, pokud je požadováno velmi jednoduché a rychlé řešení. Existují však určitá omezení, která je třeba si uvědomit.
Ve výchozím nastavení lze pod jedním účtem AWS vytvořit pouze až 100 bucketů S3. Tento limit lze rozšířit na 1 000 odesláním zvýšení limitu služby do tiketu AWS. Pokud tyto limity nejsou něčím, čeho by se váš konkrétní případ implementace obával, pak můžete nechat každého z uživatelů vaší odlišné domény pracovat na samostatném segmentu S3 a volat to denně.
Problémy mohou nastat, pokud existují skupiny lidí s mezifunkčními odpovědnostmi nebo prostě někteří lidé, kteří potřebují přístup k obsahu více domén současně. Například:
- Datoví analytici vyhodnocující obsah dat pro několik různých oblastí, regionů atd.
- Testovací tým sdílel služby sloužící různým vývojovým týmům.
- Hlášení uživatelů, kteří potřebují vytvořit analýzu řídicího panelu nad různými zeměmi ve stejném regionu.
Jak si dokážete představit, tento seznam se může opět rozrůst, jak si jen dokážete představit, a potřeby organizací mohou generovat nejrůznější případy použití.
Čím složitější bude tento seznam, tím složitější bude potřeba orchestrace přístupových práv, aby se všem těmto různým skupinám udělila různá přístupová práva k různým segmentům S3 v organizaci. Budou vyžadovány další nástroje a možná dokonce vyhrazený zdroj (administrátor) bude muset udržovat seznamy přístupových práv a aktualizovat je vždy, když je požadována jakákoli změna (což bude velmi často, zvláště pokud je organizace velká).
Jak tedy dosáhnout stejné věci organizovanějším a automatizovaným způsobem?
Pokud přístup typu bucket-per-domain nefunguje, jakékoli jiné řešení skončí sdílenými buckety pro více skupin uživatelů. V takových případech je nutné vybudovat celou logiku přidělování přístupových práv v nějaké oblasti, kterou lze snadno dynamicky měnit nebo aktualizovat.
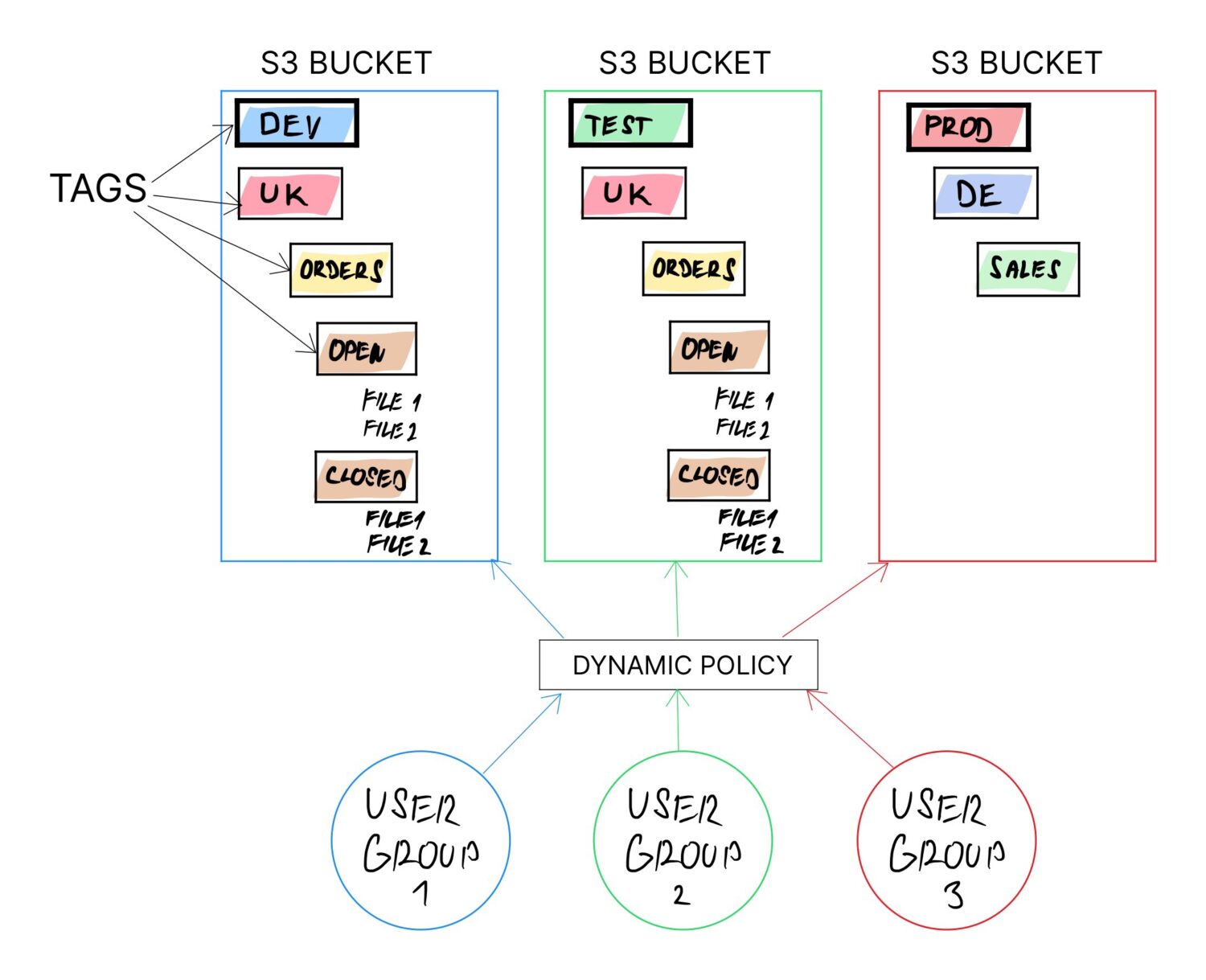
Jedním ze způsobů, jak toho dosáhnout, je použití značek na lopatách S3. Značky se doporučuje používat v každém případě (když pro nic jiného, než pro snadnější kategorizaci fakturace). Štítek však lze kdykoli v budoucnu změnit pro jakýkoli kbelík.
Pokud je celá logika postavena na značkách bucket a zbytek je konfigurace závislá na hodnotách značek, dynamická vlastnost je zajištěna, protože je možné předefinovat účel bucketu pouze aktualizací hodnot značek.
Jaké značky použít, aby to fungovalo?
To závisí na vašem konkrétním případu použití. Například:
- Může být potřeba oddělit segmenty podle typu prostředí. V takovém případě by jeden z názvů tagů měl být něco jako „ENV“ a s možnými hodnotami „DEV“, „TEST“, „PROD“ atd.
- Možná chcete oddělit tým podle země. V takovém případě bude další značka „ZEMĚ“ a bude mít hodnotu nějakého názvu země.
- Nebo můžete chtít oddělit uživatele na základě funkčního oddělení, ke kterému patří, jako jsou obchodní analytici, uživatelé datových skladů, datoví vědci atd. Vytvoříte tedy značku s názvem „USER_TYPE“ a příslušnou hodnotou.
- Další možností může být, že chcete explicitně definovat pevnou strukturu složek pro konkrétní skupiny uživatelů, které musí používat (aby si nevytvářeli vlastní změť složek a časem se tam neztratili). Můžete to udělat opět pomocí značek, kde můžete zadat několik pracovních adresářů jako: „data/import“, „data/processed“, „data/error“ atd.
V ideálním případě chcete definovat značky tak, aby je bylo možné logicky kombinovat a vytvořit z nich celou strukturu složek v kbelíku.
Můžete například zkombinovat následující značky z příkladů výše a vytvořit tak vyhrazenou strukturu složek pro různé typy uživatelů z různých zemí s předdefinovanými složkami pro import, u kterých se očekává, že je budou používat:
- /
/ / /
Pouhou změnou hodnoty
To umožní použití stejného segmentu pro mnoho různých uživatelů. Buckety nepodporují složky explicitně, ale podporují „štítky“. Tyto štítky nakonec fungují jako podsložky, protože uživatelé potřebují projít řadou štítků, aby dosáhli svých dat (stejně jako by to udělali s podsložkami).
Po definování značek v nějaké použitelné formě je dalším krokem vytvoření zásad segmentu S3, které by značky používaly.
Pokud zásady používají názvy značek, vytváříte něco, co se nazývá „dynamické zásady“. To v podstatě znamená, že se vaše zásada bude chovat odlišně pro segmenty s různými hodnotami značek, na které zásada odkazuje ve formuláři nebo zástupných symbolech.
Tento krok samozřejmě zahrnuje určité vlastní kódování dynamických zásad, ale tento krok můžete zjednodušit pomocí nástroje editoru zásad Amazon AWS, který vás celým procesem provede.
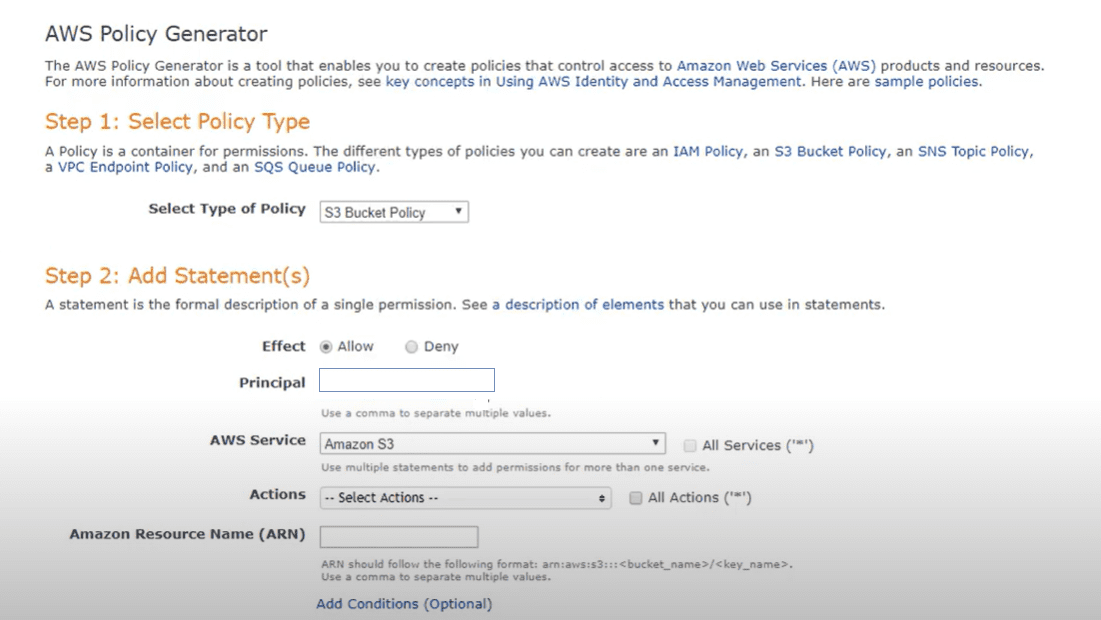
V samotné politice budete chtít zakódovat konkrétní přístupová práva, která se mají na bucket aplikovat, a úroveň přístupu těchto práv (čtení, zápis). Logika bude číst značky na bucketech a vytvoří strukturu složek v bucketu (vytváření štítků na základě značek). Na základě konkrétních hodnot tagů budou vytvořeny podsložky a na řádku budou přidělena požadovaná přístupová práva.
Pěkná věc na takové dynamické politice je, že můžete vytvořit pouze jednu dynamickou politiku a poté přiřadit stejnou dynamickou politiku mnoha segmentům. Tato zásada se bude chovat odlišně pro segmenty s různými hodnotami značek, ale vždy bude odpovídat vašim očekáváním pro segment s takovými hodnotami značek.
Je to opravdu efektivní způsob, jak spravovat přidělování přístupových práv organizovaným, centralizovaným způsobem pro velký počet segmentů, kde se očekává, že každý segment bude dodržovat určité struktury šablon, které jsou předem dohodnuty a budou používány vašimi uživateli v rámci celou organizaci.
Automatizujte připojování nových entit
Po definování dynamických zásad a jejich přiřazení ke stávajícím segmentům mohou uživatelé začít používat stejné segmenty bez rizika, že uživatelé z různých skupin nebudou mít přístup k obsahu (uloženému ve stejném segmentu) umístěného ve struktuře složek, kde nemají přístup.
Pro některé skupiny uživatelů s širším přístupem bude také snadné získat data, protože budou všechna uložena ve stejném segmentu.
Posledním krokem je co nejjednodušší přihlášení nových uživatelů, nových bucketů a dokonce i nových značek. To vede k dalšímu vlastnímu kódování, které však nemusí být přehnaně složité, za předpokladu, že váš proces onboardingu má velmi jasná pravidla, která lze zapouzdřit jednoduchou, přímočarou logikou algoritmu (přinejmenším můžete tímto způsobem prokázat, že vaše proces má určitou logiku a není prováděn příliš chaotickým způsobem).
To může být stejně jednoduché jako vytvoření skriptu spustitelného příkazem AWS CLI s parametry potřebnými k úspěšnému začlenění nové entity do platformy. Může to být dokonce řada skriptů CLI, spustitelných v určitém konkrétním pořadí, jako například:
- create_new_bucket(
, , , , ..) - create_new_tag(
, , ) - update_existing_tag(
, , ) - create_user_group(
, , ) - atd.
Chápeš pointu. 😃
Tip pro profesionály 👨💻
Pokud chcete, existuje jeden Pro Tip, který lze snadno použít na výše uvedené.
Dynamické zásady lze využít nejen pro přidělování přístupových práv pro umístění složek, ale také pro automatické přidělování servisních práv pro skupiny a skupiny uživatelů!
Vše, co by bylo potřeba, je rozšířit seznam značek na buckety a poté přidat dynamická přístupová práva pro použití konkrétních služeb pro konkrétní skupiny uživatelů.
Může například existovat určitá skupina uživatelů, která také potřebuje přístup ke konkrétnímu serveru databázového clusteru. Toho lze nepochybně dosáhnout dynamickými politikami využívajícími skupinové úkoly, zejména pokud jsou přístupy ke službám řízeny přístupem založeným na rolích. Stačí přidat do kódu dynamické politiky část, která bude zpracovávat značky týkající se specifikace databázového clusteru a přímo přidělovat přístupová práva k tomuto konkrétnímu clusteru DB a skupině uživatelů.
Tímto způsobem bude registrace nové skupiny uživatelů proveditelná pouze pomocí této jediné dynamické zásady. Jelikož je navíc dynamická, lze stejnou zásadu znovu použít pro přihlášení mnoha různých skupin uživatelů (očekává se, že se budou řídit stejnou šablonou, ale ne nutně stejnými službami).
Můžete se také podívat na tyto příkazy AWS S3 pro správu bucketů a dat.