Jak extrahovat text, odkazy a obrázky ze souborů PDF pomocí Pythonu
Zpracování PDF souborů v Pythonu: Extrakce textu, odkazů a obrázků
Python, díky své flexibilitě, se často používá pro různé úlohy, včetně práce se soubory. Programátoři v Pythonu se tak běžně setkávají s nutností zpracovávat a získávat data z různých formátů souborů, mezi které patří i Portable Document Format, známý jako PDF.
PDF soubory mohou obsahovat různorodý obsah – text, obrázky, odkazy. Při programování v Pythonu se může stát, že potřebujete extrahovat data uložená v PDF dokumentu. Získávání informací z PDF se může zdát náročnější než práce s datovými strukturami, jako jsou seznamy, n-tice nebo slovníky.
Naštěstí existuje řada knihoven, které usnadňují manipulaci s PDF soubory a umožňují extrakci uložených dat. V tomto článku si ukážeme, jak s pomocí těchto knihoven extrahovat text, odkazy a obrázky. Pro lepší pochopení si stáhněte ukázkový PDF soubor a uložte ho do stejného adresáře, ve kterém máte i svůj Python skript.
Extrakce textu s knihovnou PyPDF2
Pro extrakci textu z PDF souborů využijeme knihovnu PyPDF2. Jedná se o bezplatnou open-source knihovnu v Pythonu, kterou lze použít pro sloučení, ořezávání a transformaci PDF stránek. Umožňuje také přidávat do PDF vlastní data, nastavení zobrazení a hesla. A co je nejdůležitější, PyPDF2 umí načítat text z PDF dokumentů.
Pro používání PyPDF2 je nejprve třeba ji nainstalovat pomocí nástroje pip, správce balíčků pro Python. Pip umožňuje instalovat různé Python balíčky do vašeho systému:
1. Zkontrolujte, zda máte nainstalovaný pip spuštěním:
pip --version
Pokud se nezobrazí verze pip, znamená to, že ho nemáte nainstalovaný.
2. Pro instalaci pip si stáhněte instalační skript ze stránky získat pip.
Po kliknutí na odkaz se zobrazí stránka se skriptem. Klikněte pravým tlačítkem a zvolte "Uložit jako", výchozí název souboru je get-pip.py.
Otevřete terminál, přejděte do adresáře, kam jste uložili get-pip.py a spusťte příkaz:
sudo python3 get-pip.py
Tím se nainstaluje pip.
3. Zkontrolujte, zda se pip úspěšně nainstaloval spuštěním:
pip --version
Mělo by se zobrazit číslo verze:

S nainstalovaným pip můžeme začít pracovat s PyPDF2.
1. Nainstalujte PyPDF2 pomocí příkazu v terminálu:
pip install PyPDF2
2. Vytvořte Python soubor a importujte PdfReader z PyPDF2:
from PyPDF2 import PdfReader
Knihovna PyPDF2 poskytuje různé třídy pro práci s PDF soubory. Jednou z nich je PdfReader, kterou lze použít pro otevírání PDF, čtení obsahu a extrahování textu.
3. Pro práci s PDF souborem je třeba ho nejprve otevřít. Vytvořte instanci třídy PdfReader a předejte jí PDF soubor, se kterým chcete pracovat:
reader = PdfReader('games.pdf')
Výše uvedený řádek vytvoří instanci PdfReader a připraví ji pro přístup k obsahu zadaného PDF souboru. Instance je uložena v proměnné reader, která má přístup k metodám a vlastnostem třídy PdfReader.
4. Pro ověření, zda vše funguje správně, vytiskněte počet stránek v PDF:
print(len(reader.pages))
Výstup:
5
5. Pokud má PDF 5 stránek, máme k nim přístup. Číslování stránek začíná od 0, stejně jako indexování v Pythonu. První strana v PDF má číslo 0. Pro načtení první stránky přidejte do kódu:
page1 = reader.pages[0]
Tím se načte první stránka a uloží se do proměnné page1.
6. Pro extrakci textu z první stránky přidejte:
textPage1 = page1.extract_text()
Text z první stránky PDF se extrahuje a uloží do proměnné textPage1. Nyní máte přístup k textu z první stránky přes proměnnou textPage1.
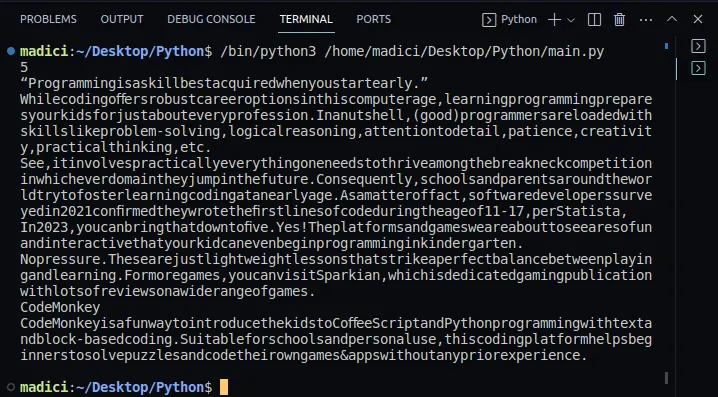
7. Pro potvrzení, že text byl úspěšně extrahován, můžete vypsat proměnnou textPage1. Celý kód, který vypíše text z první stránky, je uveden níže:
# import the PdfReader class from PyPDF2
from PyPDF2 import PdfReader
# create an instance of the PdfReader class
reader = PdfReader('games.pdf')
# get the number of pages available in the pdf file
print(len(reader.pages))
# access the first page in the pdf
page1 = reader.pages[0]
# extract the text in page 1 of the pdf file
textPage1 = page1.extract_text()
# print out the extracted text
print(textPage1)
Výstup:
Extrahování odkazů z PDF s PyMuPDF
Pro extrakci odkazů z PDF souborů použijeme knihovnu PyMuPDF, která slouží pro extrakci, analýzu, konverzi a manipulaci s daty v dokumentech jako PDF. Pro používání PyMuPDF potřebujete Python 3.8 nebo novější. Začneme instalací:
1. Nainstalujte PyMuPDF spuštěním příkazu v terminálu:
pip install PyMuPDF
2. Importujte PyMuPDF do svého Python souboru:
import fitz
3. Pro přístup k PDF, ze kterého chcete extrahovat odkazy, ho musíte nejprve otevřít:
doc = fitz.open("games.pdf")
4. Po otevření souboru PDF vytiskněte počet stran v PDF:
print(doc.page_count)
Výstup:
5
5. Pro extrakci odkazů z PDF musíte načíst stranu, ze které je chcete získat. Pro načtení strany použijte následující řádek, kde předáváte číslo strany do funkce load_page():
page = doc.load_page(0)
Pro extrakci odkazů z první strany předáváme 0 (nula). Číslování stran začíná od nuly, stejně jako v datových strukturách.
6. Extrahujte odkazy ze stránky pomocí:
links = page.get_links()
Všechny odkazy z dané stránky, v našem případě z první, se extrahují a uloží do proměnné links.
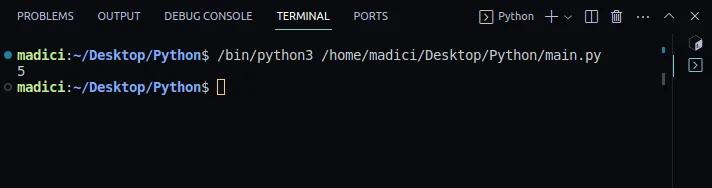
7. Pro zobrazení obsahu proměnné links ji vytiskněte:
print(links)
Výstup:
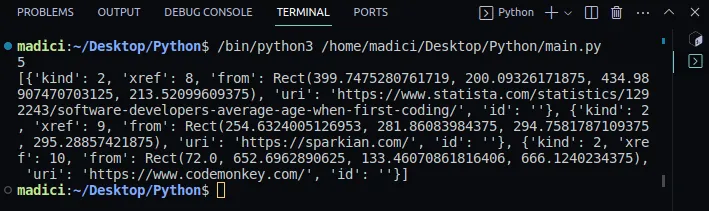
Odkazy v proměnné links jsou uloženy jako seznam slovníků s páry klíč-hodnota. Každý odkaz na stránce je reprezentován slovníkem, přičemž samotný odkaz je uložen pod klíčem "uri".
8. Pro získání odkazů z objektů uložených v proměnné links použijeme cyklus for a vypíšeme odkazy pod klíčem uri. Celý kód, který to provede, je níže:
import fitz
# Open the PDF file
doc = fitz.open("games.pdf")
# Print out the number of pages
print(doc.page_count)
# load the first page from the PDF
page = doc.load_page(0)
# extract all links from the page and store it under - links
links = page.get_links()
# print the links object
#print(links)
# print the actual links stored under the key "uri"
for obj in links:
print(obj["uri"])
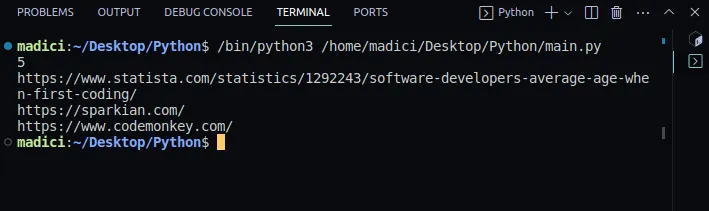
Výstup:
5 https://www.statista.com/statistics/1292243/software-developers-average-age-when-first-coding/ https://sparkian.com/ https://www.codemonkey.com/
9. Pro opětovné použití kódu ho můžeme refaktorovat pomocí definice funkce pro extrakci všech odkazů z PDF a funkce pro tisk nalezených odkazů. Funkce lze volat pro jakékoli PDF a získáte všechny odkazy. Kód je zobrazen níže:
import fitz
# Extract all the links in a PDF document
def extract_link(path_to_pdf):
links = []
doc = fitz.open(path_to_pdf)
for page_num in range(doc.page_count):
page = doc.load_page(page_num)
page_links = page.get_links()
links.extend(page_links)
return links
# print out all the links returned from the PDF document
def print_all_links(links):
for link in links:
print(link["uri"])
# Call the function to extract all the links in a pdf
# all the return links are stored under all_links
all_links = extract_link("games.pdf")
# call the function to print all links in the PDF
print_all_links(all_links)
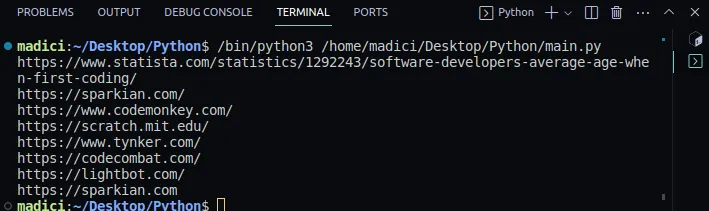
Výstup:
https://www.statista.com/statistics/1292243/software-developers-average-age-when-first-coding/ https://sparkian.com/ https://www.codemonkey.com/ https://scratch.mit.edu/ https://www.tynker.com/ https://codecombat.com/ https://lightbot.com/ https://sparkian.com
Funkce extract_link() přijme PDF soubor, iteruje přes všechny stránky, extrahuje odkazy a vrátí je. Výsledek se uloží do proměnné all_links.
Funkce print_all_links() přijme výsledek funkce extract_link(), prochází seznam a tiskne všechny nalezené odkazy z PDF souboru, který byl předán do funkce extract_link().
Extrahování obrázků z PDF pomocí PyMuPDF
Pro extrakci obrázků z PDF budeme nadále používat knihovnu PyMuPDF. Pro extrahování obrázků ze souboru PDF proveďte následující kroky:
1. Importujte knihovny PyMuPDF, io a PIL. Knihovna Python Imaging Library (PIL) poskytuje nástroje, které usnadňují tvorbu a ukládání obrázků. io poskytuje třídy pro manipulaci s binárními daty.
import fitz from io import BytesIO from PIL import Image
2. Otevřete soubor PDF, ze kterého chcete extrahovat obrázky:
doc = fitz.open("games.pdf")
3. Načtěte stranu, ze které chcete extrahovat obrázky:
page = doc.load_page(0)
4. PyMuPDF identifikuje obrázky v PDF pomocí křížového referenčního čísla (xref), což je celé číslo. Každý obrázek v PDF má jedinečnou externí referenci. Pro extrahování obrázku je třeba nejdříve získat xref číslo. Pro získání xref čísel obrázků použijeme funkci get_images() takto:
image_xref = page.get_images() print(image_xref)
Výstup:
[(7, 0, 699, 407, 8, 'DeviceRGB', '', 'X7', 'FlateDecode')]
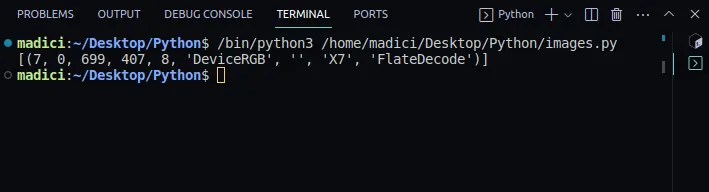
get_images() vrací seznam n-tic s informacemi o obrázku. Protože máme na první straně pouze jeden obrázek, je tu pouze jedna n-tice. První prvek v n-tici představuje externí referenci obrázku. Xref obrázku na první straně je 7.
5. Pro získání hodnoty xref obrázku ze seznamu n-tic použijeme kód:
# get xref value of the image xref_value = image_xref[0][0] print(xref_value)
Výstup:
[(7, 0, 699, 407, 8, 'DeviceRGB', '', 'X7', 'FlateDecode')] 7
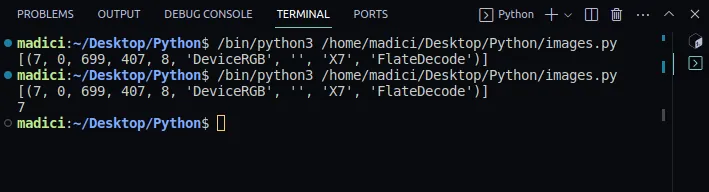
6. Máme xref, které identifikuje obrázek, takže ho můžeme extrahovat pomocí funkce extract_image():
img_dictionary = doc.extract_image(xref_value)
Tato funkce nevrací skutečný obrázek, ale slovník s binárními daty obrázku a metadaty.
7. Ve slovníku z funkce extract_image() zkontrolujte příponu extrahovaného obrázku. Přípona je uložena pod klíčem "ext":
# get file extenstion img_extension = img_dictionary["ext"] print(img_extension)
Výstup:
png
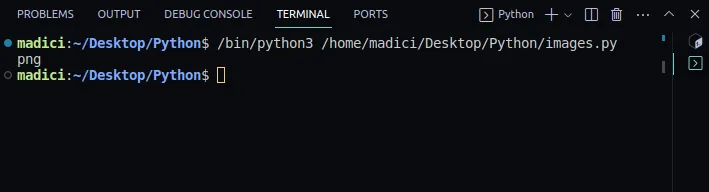
8. Extrahujte binární soubory obrázků ze slovníku uloženého v proměnné img_dictionary. Binární soubory jsou uloženy pod klíčem "image":
# get the actual image binary data img_binary = img_dictionary["image"]
9. Vytvořte objekt BytesIO a inicializujte ho s binárními daty obrázku. Tím se vytvoří objekt podobný souboru, který lze zpracovat s knihovnami jako PIL pro uložení obrázku.
# create a BytesIO object to work with the image bytes image_io = BytesIO(img_binary)
10. Otevřete a analyzujte data obrázku uložená v objektu image_io s pomocí knihovny PIL. To je důležité, protože to umožní knihovně PIL rozpoznat formát obrázku (v tomto případě PNG). Po zjištění formátu PIL vytvoří objekt obrázku, který je možné manipulovat metodami knihovny jako je save(), pro uložení obrázku na disk.
# open the image using Pillow image = Image.open(image_io)
11. Zadejte cestu, kam chcete obrázek uložit:
output_path = "image_1.png"
Protože cesta obsahuje pouze název a příponu souboru, extrahovaný obrázek bude uložen do stejného adresáře jako váš Python skript. Obrázek bude uložen jako image_1.png. Přípona PNG musí odpovídat původnímu formátu obrázku.
12. Uložte obrázek a uzavřete objekt BytesIO:
# save the image image.save(output_path) # Close the BytesIO object image_io.close()
Celý kód pro extrakci obrázku z PDF je zobrazen níže:
import fitz
from io import BytesIO
from PIL import Image
doc = fitz.open("games.pdf")
page = doc.load_page(0)
# get a cross reference(xref) to the image
image_xref = page.get_images()
# get the actual xref value of the image
xref_value = image_xref[0][0]
# extract the image
img_dictionary = doc.extract_image(xref_value)
# get file extenstion
img_extension = img_dictionary["ext"]
# get the actual image binary data
img_binary = img_dictionary["image"]
# create a BytesIO object to work with the image bytes
image_io = BytesIO(img_binary)
# open the image using PIL library
image = Image.open(image_io)
#specify the path where you want to save the image
output_path = "image_1.png"
# save the image
image.save(output_path)
# Close the BytesIO object
image_io.close()
Po spuštění skriptu a návratu do adresáře, kde máte Python soubor, byste měli vidět extrahovaný obrázek image_1.png, jak je uvedeno níže:
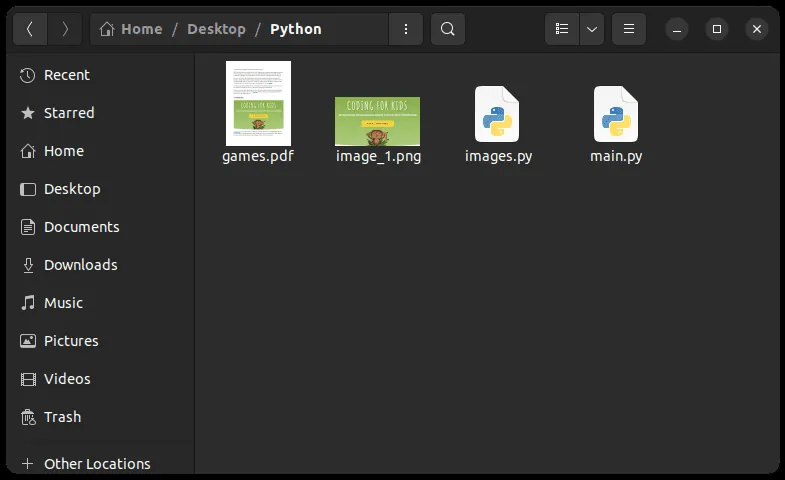
Závěr
Pro další procvičení extrahování textů, odkazů a obrázků z PDF zkuste refaktorovat kód tak, aby byl znovu použitelný, jak je ukázáno v příkladu s odkazy. Stačí potom předat pouze PDF soubor a Python skript extrahuje všechny odkazy, obrázky nebo text v celém PDF. Přejeme příjemné kódování!
Můžete se také podívat na některá nejlepší PDF API pro vaše obchodní potřeby.
