Jak najít index položky v seznamech Pythonu
Tento návod vám ukáže, jak v Pythonu nalézt pozici (index) konkrétního prvku v seznamu. Prozkoumáme jak tradiční iterace, tak i vestavěnou metodu `index()` seznamu.
Při práci se seznamy v Pythonu je běžné, že potřebujete zjistit, na kterém místě (indexu) se nachází určitá položka. Existují dva hlavní způsoby, jak toho dosáhnout:
- Procházení seznamu a ověřování, zda prvek na dané pozici odpovídá hledané hodnotě.
- Použití přímo vestavěné metody `index()` seznamu.
V tomto tutoriálu se seznámíme s oběma postupy. Pojďme na to! 👩🏽💻
Opakování o seznamech v Pythonu
V Pythonu je seznam uspořádaná kolekce položek. Mohou to být prvky stejného datového typu, nebo i různé. Seznamy jsou měnitelné, to znamená, že je můžeme upravovat přímo, aniž bychom museli vytvářet nový seznam.
Zvažme příklad seznamu ovoce, který obsahuje pět různých druhů.
fruits = ["apple","mango","strawberry","pomegranate","melon"]
Délku jakéhokoli objektu v Pythonu zjistíme pomocí funkce `len()`. Stejně tak můžeme zavolat funkci `len()` s objektem seznamu (např. `fruits`) jako argumentem, abychom získali jeho délku.
len(fruits) # Výstup: 5
V tomto tutoriálu budeme používat seznam ovoce jako náš ukázkový příklad.
Indexování v seznamech Pythonu
V Pythonu se používá indexování od nuly. To znamená, že první prvek v jakékoli iterovatelné struktuře má index 0, druhý prvek má index 1 a tak dále. Pokud má iterovatelná struktura `k` prvků, poslední prvek má index `k - 1`.
V Pythonu můžeme pomocí funkce `range()` generovat posloupnost indexů při procházení iterovatelných struktur.
Poznámka: Při použití `range(k)` získáte indexy 0, 1, 2, ..., (k-1). Takže pokud nastavíme `k` na `len(seznam)`, můžeme získat všechny platné indexy seznamu.
Následující kód to demonstruje:
for i in range(len(fruits)):
print(f"i:{i}, fruit[{i}] is {fruits[i]}")
# Výstup
i:0, fruit[0] is apple
i:1, fruit[1] is mango
i:2, fruit[2] is strawberry
i:3, fruit[3] is pomegranate
i:4, fruit[4] is melon
Nyní, když jsme si zopakovali základy seznamů, se můžeme podívat, jak najít index konkrétního prvku v seznamu.
Hledání indexu prvku iterací pomocí cyklu `for`
Vraťme se k seznamu ovoce z předchozí části. Naučíme se, jak zjistit index konkrétní položky v tomto seznamu pomocí cyklu `for`.
Použití cyklu `for` a funkce `range()`
Stanovme si cíl: hodnotu, kterou hledáme v seznamu.
Pro generování posloupnosti indexů od 0 do `len(ovoce) - 1` můžeme použít cyklus `for` v kombinaci s funkcí `range()`.
- Projdeme seznam `fruits`, přičemž v každém kroku máme přístup k indexu.
- Ověříme, zda prvek na aktuálním indexu `i` odpovídá hledané hodnotě.
- Pokud se prvek rovná hledané hodnotě, vypíšeme zprávu o tom, že byl prvek nalezen na daném indexu `i`.
fruits = ["apple","mango","strawberry","pomegranate","melon"]
target = "mango"
for i in range(len(fruits)):
if fruits[i] == target:
print(f"{target} nalezen na indexu {i}")
# Výstup
mango nalezen na indexu 1
V tomto příkladu se řetězec 'mango' v seznamu `fruits` vyskytuje pouze jednou, a to na indexu 1.
Někdy se však hledaná hodnota může vyskytovat vícekrát, nebo se v seznamu nemusí nacházet vůbec. Abychom zvládli i tyto situace, upravíme předchozí cyklus a umístíme jej do funkce s názvem `find_in_list`.
Porozumění definici funkce
Funkce `find_in_list` přijímá dva parametry:
- `target`: hodnota, kterou hledáme, a
- `py_list`: seznam v Pythonu, ve kterém hledáme.
def find_in_list(target,py_list):
target_indices = []
for i in range(len(fruits)):
if fruits[i] == target:
target_indices.append(i)
if target_indices == []:
print("Hledaný prvek nebyl nalezen!")
else:
print(f"{target} se nachází na indexech {target_indices}")
V těle funkce nejprve vytvoříme prázdný seznam `target_indices`. Potom procházíme seznam a ověřujeme, zda se aktuální prvek shoduje s hledanou hodnotou. Pokud ano, index aktuálního prvku přidáme do seznamu `target_indices` pomocí metody `append()`.
Poznámka: V Pythonu `list.append(item)` přidá položku na konec seznamu.
- Pokud se hledaný prvek nenajde, zůstane seznam `target_indices` prázdný a uživateli se zobrazí zpráva o tom, že hledaný prvek v seznamu nebyl nalezen.
- Pokud se hledaný prvek nachází na více indexech, bude seznam `target_indices` obsahovat všechny tyto indexy.
Nyní si předefinujeme seznam `fruits`, jak je ukázáno níže.
Tentokrát hledáme řetězec 'mango', který se v seznamu vyskytuje dvakrát - na indexech 1 a 4.
fruits = ["apple","mango","strawberry","pomegranate","mango","melon"] target = "mango" find_in_list(target,fruits) # Výstup mango se nachází na indexech [1, 4]
Při volání funkce `find_in_list` s parametry `target` a `fruits` vidíme, že se nám vrátí oba indexy, na kterých se 'mango' v seznamu nachází.
target = "turnip" find_in_list(target,fruits) # Výstup Hledaný prvek nebyl nalezen!
Pokud se pokusíme vyhledat řetězec 'turnip' (tuřín), který se v seznamu `fruits` nenachází, zobrazí se nám zpráva o tom, že hledaný prvek nebyl nalezen.
Použití cyklu `for` a funkce `enumerate()`
V Pythonu můžeme použít funkci `enumerate()` pro současný přístup k indexu a prvkům, aniž bychom museli použít funkci `range()`.
Následující kód ukazuje, jak můžeme funkci `enumerate()` použít pro získání indexů a prvků.
fruits = ["apple","mango","strawberry","pomegranate","mango","melon"]
for index,fruit in enumerate(fruits):
print(f"Index {index}: {fruit}")
# Výstup
Index 0: apple
Index 1: mango
Index 2: strawberry
Index 3: pomegranate
Index 4: mango
Index 5: melon
Nyní přepíšeme funkci v Pythonu, abychom nalezli index prvků v seznamu s využitím funkce `enumerate()`.
def find_in_list(target,py_list):
target_indices = []
for index, fruit in enumerate(fruits):
if fruit == target:
target_indices.append(index)
if target_indices == []:
print("Hledaný prvek nebyl nalezen!")
else:
print(f"{target} se nachází na indexech {target_indices}")
Stejně jako v předchozí části můžeme i nyní volat funkci `find_in_list` s platnými argumenty.
Výše uvedenou definici funkce můžeme transformovat do ekvivalentního list comprehension, což uděláme v následující sekci.
Hledání indexu prvku pomocí list comprehension
List comprehension v Pythonu umožňuje vytvářet nové seznamy na základě existujících seznamů s použitím dané podmínky. Obecný zápis je následující:
new_list = [<výstup> for <položka in existující iterovatelná struktura> if <podmínka je splněna>]
Obrázek níže popisuje, jak identifikovat prvky list comprehension. Použitím tohoto schématu můžeme převést funkci `find_in_list` na list comprehension.
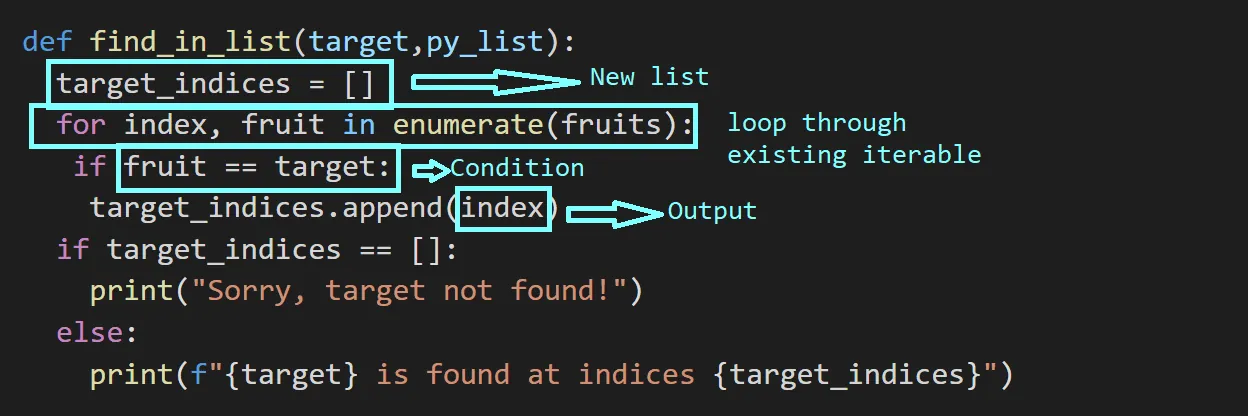
Při použití výše uvedeného schématu můžeme list comprehension pro nalezení indexů definovat takto:
target_indices = [index for index,fruit in enumerate(fruits) if fruit==target]
Jako cvičení si můžete zkusit spustit výše uvedený kód pro několik dalších příkladů.
Hledání indexu prvku pomocí metody `index()`
Pro nalezení indexu prvku v seznamu Python můžeme použít také vestavěnou metodu `.index()`. Obecný zápis je následující:
list.index(value,start,end)
Rozbor výše uvedené metody:
- `value`: hledaná hodnota
- `start` a `end`: nepovinné poziční argumenty. Tyto argumenty nám umožňují prohledávat index prvku v daném podrozsahu seznamu, začínajícím indexem `start` a končícím indexem `end - 1`.
Poznámka: Metoda `.index()` vrací pouze index prvního výskytu hledané hodnoty v seznamu. I když hledáme index položky v daném rozsahu, metoda vrátí index pouze prvního výskytu.
Vraťme se k našemu příkladu, abychom si ukázali, jak metoda `.index()` funguje.
fruits = ["apple","mango","strawberry","pomegranate","mango","melon"] target = "mango" fruits.index(target) 1
I když se v seznamu `fruits` vyskytují dvě slova "mango", je nám vrácen pouze index prvního výskytu.
Pokud chceme získat index druhého výskytu slova "mango", můžeme prohledávat jen část seznamu, počínaje indexem 2 a konče indexem 5, jak ukazuje následující příklad:
fruits.index(target,2,5) 4
Jak zpracovat `ValueError` v Pythonu
Podívejme se, co se stane, pokud se pokusíme najít index položky, která se v seznamu nenachází, například 'carrot' (mrkev).
target = "carrot"
fruits.index(target)
# Výstup
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-17-81bd454e44f7> in <module>()
1 target = "carrot"
2
----> 3 fruits.index(target)
ValueError: 'carrot' není v seznamu
Jak je vidět na výstupu, vyvolá se výjimka `ValueError`. V Pythonu můžeme tuto výjimku ošetřit pomocí bloků `try` a `except`.
Obecný zápis použití `try-except` je následující:
try: # proveď tento kód except <TypChyby>: # proveď tento kód pro ošetření výjimky <TypChyby>
Pomocí bloků `try-except` můžeme ošetřit výjimku `ValueError`.
target = "carrot"
try:
fruits.index(target)
except ValueError:
print(f"Hledaný prvek {target} nebyl v seznamu nalezen")
# Výstup
Hledaný prvek carrot nebyl v seznamu nalezen
Výše uvedený kód dělá následující:
- Pokud se hledaný prvek v seznamu nachází, vrátí jeho index.
- Pokud se hledaný prvek v seznamu nenachází, ošetří výjimku `ValueError` a vypíše chybovou zprávu.
Shrnutí
Zde je shrnutí různých metod, které jsme se naučili pro nalezení indexu prvku v seznamu v Pythonu.
- K získání prvků a jejich indexů můžeme použít cyklus `for` s funkcí `range()`. Poté ověříme, zda prvky na daných indexech odpovídají hledané hodnotě.
- Pro současný přístup k prvku a jeho indexu můžeme použít funkci `enumerate()`.
- Obě výše uvedené metody lze použít v list comprehension.
- Pro nalezení indexu prvku v seznamu můžeme použít vestavěnou metodu `.index()`.
- `list.index(value)` vrátí index prvního výskytu hledané hodnoty v seznamu. Pokud se hledaná hodnota v seznamu nenachází, vyvolá se výjimka `ValueError`.
- Můžeme prohledávat jen určitou část seznamu pomocí `list.index(value, start, end)`, kde hledáme výskyt hodnoty v podrozsahu seznamu `[start:end-1]`.
Dále se můžete naučit jak seřadit slovník v Pythonu podle klíče nebo hodnoty. Šťastné programování v Pythonu!
