Jak používat agregační kanál v MongoDB
Pro provádění složitějších dotazů v rámci MongoDB se doporučuje využívat agregační kanál. Jestliže jste dříve pracovali s MapReduce, zvažte přechod na agregační kanál, který je pro výpočty efektivnější.
Co je agregace v MongoDB a jak funguje?
Agregační kanál představuje vícestupňový postup pro realizaci pokročilých dotazů v MongoDB. Data jsou zpracovávána skrze jednotlivé fáze, které se nazývají trubky (anglicky "pipeline"). Výsledky z jedné fáze se mohou použít jako vstup pro další operace.
Například výstup operace vyhledání můžete přesunout do další fáze, kde data seřadíte, a tak dále, dokud nedosáhnete požadovaného výsledku.
Každá fáze agregačního kanálu obsahuje operátor MongoDB, který vytváří jeden nebo více transformovaných dokumentů. V závislosti na dotazu se může daná fáze v kanálu objevit i několikrát. Například operátory jako $count nebo $sort můžete v agregačním kanálu použít opakovaně.
Fáze agregačního potrubí
Agregační kanál postupně zpracovává data několika fázemi v rámci jediného dotazu. Existuje mnoho fází a jejich detailní popis naleznete v dokumentaci MongoDB.
Dále si definujeme některé z nejpoužívanějších fází.
Fáze $match
Tato fáze slouží k definování specifických podmínek pro filtrování dat před zahájením dalších agregačních kroků. Umožňuje vybrat relevantní data pro další zpracování v agregačním kanálu.
Fáze $group
Fáze $group rozděluje data do různých skupin na základě zadaných kritérií, a to pomocí dvojic klíč–hodnota. Každá skupina je reprezentována klíčem ve výstupním dokumentu.
Jako příklad si vezměme následující data o prodejích:
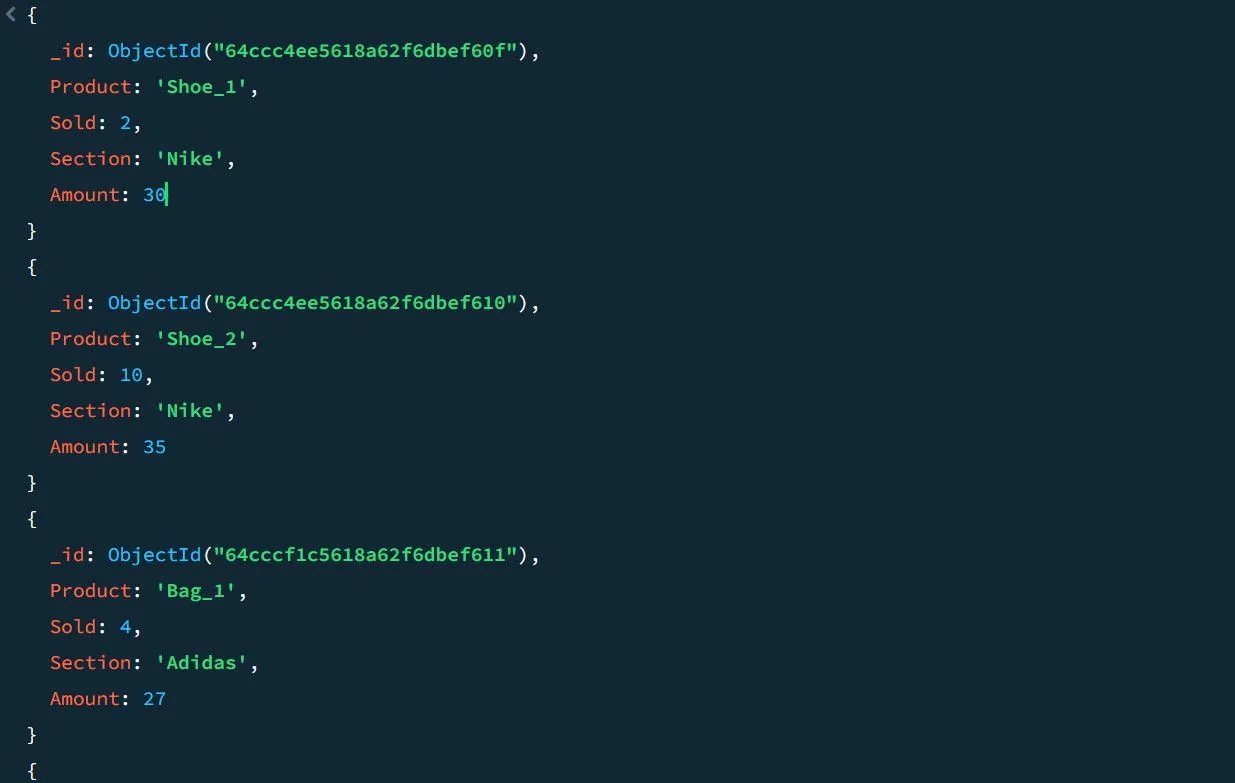
S pomocí agregačního kanálu můžete spočítat celkový počet prodejů a nejvyšší prodeje pro každou sekci produktu:
{
$group: {
_id: $Section,
total_sales_count: {$sum : $Sold},
top_sales: {$max: $Amount},
}
}
Dvojice _id: $Section seskupí výstupní dokumenty na základě sekcí. Zadáním polí total_sales_count a top_sales MongoDB vytvoří nové klíče na základě operace definované agregátorem, což může být $sum, $min, $max nebo $avg.
Fáze $skip
Fáze $skip umožňuje přeskočit definovaný počet dokumentů ve výstupu. Běžně se používá až po fázi seskupení. Pokud například očekáváte dva výstupní dokumenty, ale jeden přeskočíte, agregace vytiskne pouze druhý dokument.
Pro přidání fáze $skip vložte tuto operaci do agregačního kanálu:
...,
{
$skip: 1
},
Fáze $sort
Fáze řazení ($sort) umožňuje seřadit data vzestupně nebo sestupně. Například můžeme data z předchozího dotazu seřadit sestupně a zjistit, která sekce má nejvyšší prodeje.
Přidejte operátor $sort do předchozího dotazu:
...,
{
$sort: {top_sales: -1}
},
Fáze $limit
Operace limit ($limit) snižuje počet výstupních dokumentů z agregačního kanálu. Například s pomocí $limit získáme sekci s nejvyšším prodejem z předchozí fáze:
...,
{
$sort: {top_sales: -1}
},
{"$limit": 1}
Výše uvedené vrátí pouze první dokument, tedy sekci s nejvyšším prodejem, která se nachází na začátku seřazeného výstupu.
Fáze $project
Fáze $project umožňuje upravit strukturu výstupního dokumentu dle požadavků. Můžete určit, která pole mají být zahrnuta do výstupu a upravit jejich názvy.
Ukázkový výstup bez fáze $project vypadá takto:
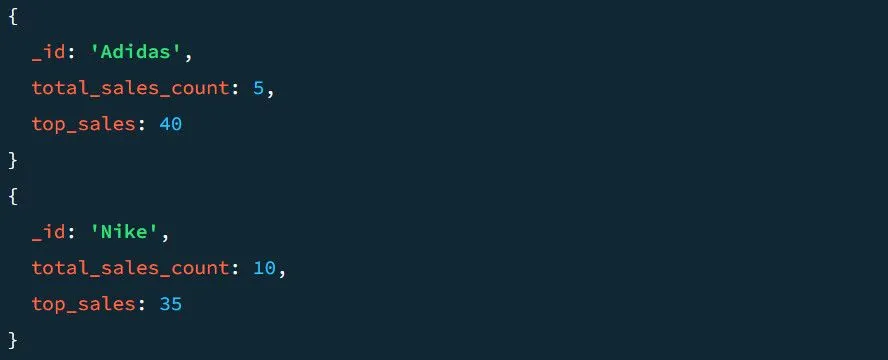
Podívejme se, jak to vypadá s fází $project. Pro přidání projektu $project do kanálu:
...,
{
"$project": {
"_id": 0,
"Section": "$_id",
"TotalSold": "$total_sales_count",
"TopSale": "$top_sales",
}
}
Vzhledem k tomu, že data byla dříve seskupena dle sekcí produktu, uvedený příklad zahrnuje každou sekci produktu ve výstupním dokumentu. Zároveň zajišťuje, že agregovaný počet prodejů a nejvyšší prodeje jsou ve výstupu označeny jako TotalSold a TopSale.
Výsledný výstup je ve srovnání s předchozím mnohem přehlednější:

Fáze $unwind
Fáze $unwind rozloží pole v dokumentu na samostatné dokumenty. Například mějme následující data o objednávkách:
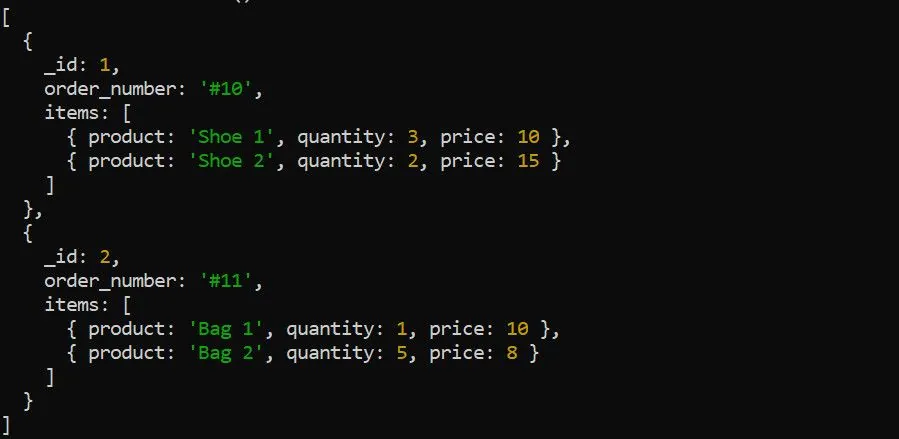
Použijte fázi $unwind pro rozložení pole položek před aplikací dalších agregačních fází. Rozložení pole položek má smysl například v situaci, kdy chcete spočítat celkový příjem pro každý produkt:
db.Orders.aggregate([
{
"$unwind": "$items"
},
{
"$group": {
"_id": "$items.product",
"total_revenue": { "$sum": { "$multiply": ["$items.quantity", "$items.price"] } }
}
},
{
"$sort": { "total_revenue": -1 }
},
{
"$project": {
"_id": 0,
"Product": "$_id",
"TotalRevenue": "$total_revenue",
}
}
])
Zde je výsledek výše uvedeného agregačního dotazu:

Jak vytvořit agregační kanál v MongoDB
Ačkoli agregační kanál zahrnuje několik operací, výše uvedené fáze vám poskytnou základní představu o jejich použití v rámci kanálu, včetně jednoduchého dotazu pro každou z nich.
Na základě dřívějších dat o prodejích si ukažme některé z uvedených fází v jednom celku, abychom získali širší pohled na agregační kanál:
db.sales.aggregate([
{
"$match": {
"Sold": { "$gte": 5 }
}
},
{
"$group": {
"_id": "$Section",
"total_sales_count": { "$sum": "$Sold" },
"top_sales": { "$max": "$Amount" },
}
},
{
"$sort": { "top_sales": -1 }
},
{"$skip": 0},
{
"$project": {
"_id": 0,
"Section": "$_id",
"TotalSold": "$total_sales_count",
"TopSale": "$top_sales",
}
}
])
Konečný výstup bude vypadat podobně jako dříve:
Agregační kanál vs. MapReduce
Až do ukončení podpory v MongoDB 5.0 byl tradičním způsobem agregace dat v MongoDB MapReduce. Přestože má MapReduce širší uplatnění i mimo MongoDB, je méně efektivní než agregační kanál a vyžaduje skriptování třetích stran pro samostatné psaní mapovacích a redukčních funkcí.
Agregační kanál je naproti tomu specifický pouze pro MongoDB. Poskytuje ovšem přehlednější a efektivnější způsob provádění složitých dotazů. Kromě jednoduchosti a škálovatelnosti dotazů umožňují jednotlivé fáze kanálu lepší přizpůsobení výstupu.
Mezi agregačním kanálem a MapReduce je mnoho dalších rozdílů. Uvidíte je při přechodu z MapReduce na agregační kanál.
Zefektivněte dotazy na velká data v MongoDB
Pokud chcete provádět hloubkové výpočty na komplexních datech v MongoDB, měl by být váš dotaz maximálně efektivní. Agregační kanál je ideální pro pokročilé dotazování. Místo manipulace s daty v samostatných operacích, které často snižují výkon, vám agregace umožňuje sloučit všechny operace do jednoho výkonného kanálu a provést je najednou.
Ačkoli je agregační kanál efektivnější než MapReduce, můžete agregaci zrychlit a zefektivnit indexováním dat. Tím se omezí množství dat, které MongoDB musí prohledávat během každé fáze agregace.
